Hash Functions
Hash functions are used for several cryptographic applications. They can be used for secure password verification or storage and are also a base component for data authentication.
Hashing is a one-way function of input data, which produces fixed-length output data, the digest. The digest uniquely identifies the input data and is cryptographically very strong, that is, it is impossible to recover input data from its digest, and if the input data changes just a little, the digest (fingerprint) changes substantially (avalanche effect). Therefore, high-volume data can be identified by its (shorter) digest. For this reason, the digest is called a fingerprint of the data. Given only a digest, it is not computationally feasible to regenerate the data that was used to compute the digest.
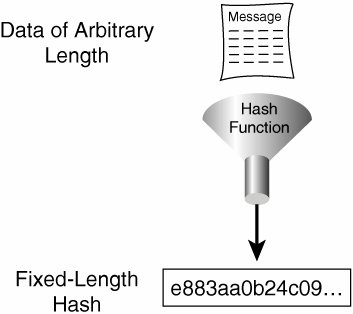
Figure 24-4 illustrates how hashing is performed. Data of arbitrary length is input to the hash function, and the result of the hash function is the fixed-length hash (digest, fingerprint). Hashing is similar to the calculation of cyclic redundancy check (CRC) checksums, except that it is much stronger from a cryptographic point of view. With CRC, given a CRC value, it is easy to generate data with the same CRC. However, with hash functions, this is not computationally feasible for an attacker.
Figure 24-4. Hashing Process
The two best-known hashing functions are these:
- Message Digest 5 (MD5), with 128-bit digests
- Secure Hash Algorithm 1 (SHA-1), with 160-bit digests
There is considerable evidence that MD5 might not be as strong as originally envisioned and that collisions (different inputs resulting in the same fingerprint) are more likely to occur than designed for. Therefore, MD5 should be avoided as an algorithm of choice and SHA-1 should be used instead.
NIST developed SHA, the algorithm specified in the Secure Hash Standard. SHA-1 is a revision to SHA that was published in 1994; the revision corrected an unpublished flaw in SHA. Its design is very similar to the MD4 family of hash functions developed by Rivest. The algorithm takes a message of no less than 264 bits in length and produces a 160-bit message digest. The algorithm is slightly slower than MD5, but the larger message digest makes it more secure against brute-force collision and inversion attacks.
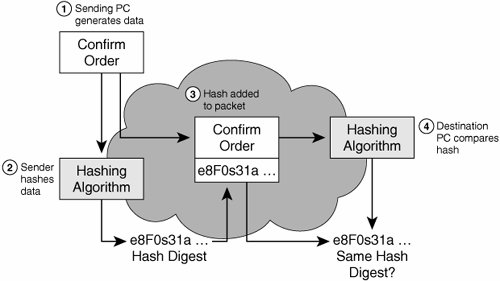
Figure 24-5 illustrates hashing in action. The sender wants to ensure that the message will not be altered on its way to the receiver. The sender uses the message as the input to a hashing algorithm and computes its fixed-length digest or fingerprint. This fingerprint is then attached to the message (the message and the hash are cleartext) and sent to the receiver. The receiver removes the fingerprint from the message and uses the message as input to the same hashing algorithm. If the hash computed by the receiver is equal to the one attached to the message, the message has not been altered during transit.
Figure 24-5. Hashing Example
Be aware that there is no security added to the message in this example. When the message traverses the network, a potential attacker could intercept the message, change it, recalculate the hash, and append the newly recalculated fingerprint to the message (a man-in-the-middle interception attack). Hashing only prevents the message from being changed accidentally (that is, by a communication error). There is nothing unique to the sender in the hashing procedure; therefore, anyone can compute a hash for any data, as long as they know the correct hash algorithm.
Thus, hash functions are helpful to ensure that data was not changed accidentally but cannot ensure that data was not deliberately changed. For the latter, you need to employ hash functions in the context of Hash-based Message Authentication Code (HMAC). They will extend hashes by adding a secure component.
HMAC uses existing hash functions, but with the significant difference of adding an additional secret key as the input to the hash function when calculating the digest (fingerprint). Only the sender and the receiver share the secret key, and the output of the hash function now depends on the input data and the secret key. Therefore, only parties who have access to that secret key can compute or verify the digest of an HMAC function. This defeats man-in-the-middle attacks and also provides authentication of data origin. If only two parties share a secret HMAC key and use HMAC functions for authentication, the receiver of a properly constructed HMAC digest with a message can be sure that the other party was the originator of the message because that other party is the only other entity possessing the secret key. However, because both parties know the key, HMAC does not provide nonrepudiation. For the latter, every entity would need its own secret key instead of having a secret key shared between two parties.
HMAC functions are generally fast and are often applied in these situations:
- To provide a fast proof of message authenticity and integrity among parties sharing the secret key, such as with IPsec packets or routing protocol authentication
- To generate one-time (and one-way) responses to challenges in authentication protocols (such as PPP Challenge Handshake Authentication Protocol [CHAP], Microsoft NT Domain, and Extensible Authentication Protocol-MD5 [EAP-MD5])
- To provide proof of integrity of bulk data, such as with file-integrity checkers (for example, Tripwire), or with document signing (digitally signed contracts, Public Key Infrastructure [PKI] certificates)
Some well-known HMAC functions are as follows:
- Keyed MD5, based on the MD5 hashing algorithm, which should be avoided
- Keyed SHA-1, based on the SHA-1 hashing algorithm, which is recommended
Cisco IP telephony uses SHA-1 HMAC for protecting signaling traffic and media exchange.
Part I: Cisco CallManager Fundamentals
Introduction to Cisco Unified Communications and Cisco Unified CallManager
Cisco Unified CallManager Clustering and Deployment Options
- Cisco Unified CallManager Clustering and Deployment Options
- The Two Sides of the Cisco Unified CallManager Cluster
- Cluster Redundancy Designs
- Call-Processing Deployment Models
- Summary
- Review Questions
Cisco Unified CallManager Installation and Upgrades
- Cisco Unified CallManager Installation and Upgrades
- Cisco Unified CallManager 4.x Clean Installation Process
- Upgrading Prior Cisco Unified CallManager Versions
- Summary
- Review Questions
Part II: IPT Devices and Users
Cisco IP Phones and Other User Devices
Configuring Cisco Unified CallManager to Support IP Phones
- Configuring Cisco Unified CallManager to Support IP Phones
- Configuring Intracluster IP Phone Communication
- IP Phone Configuration
- Case Study: Device Pool Design
- Summary
- Review Questions
Cisco IP Telephony Users
- Cisco IP Telephony Users
- Cisco CallManager User Database
- Cisco CallManager User Configuration
- User Logon and Device Configuration
- Summary
- Review Questions
Cisco Bulk Administration Tool
- Cisco Bulk Administration Tool
- The Cisco Bulk Administration Tool
- Using the Tool for Auto-Registered Phone Support
- Summary
- Review Questions
Part III: IPT Network Integration and Route Plan
Cisco Catalyst Switches
- Cisco Catalyst Switches
- Catalyst Switch Role in IP Telephony
- Powering the Cisco IP Phone
- Data and Voice VLANs
- Configuring Class of Service
- Summary
- Review Questions
Configuring Cisco Gateways and Trunks
- Configuring Cisco Gateways and Trunks
- Cisco Gateway Concepts
- Configuring Access Gateways
- Cisco Trunk Concepts
- Configuring Intercluster Trunks
- SIP and Cisco CallManager
- Summary
- Review Questions
Cisco Unified CallManager Route Plan Basics
- Cisco Unified CallManager Route Plan Basics
- External Call Routing
- Route Plan Configuration Process
- Summary
- Review Questions
Cisco Unified CallManager Advanced Route Plans
- Cisco Unified CallManager Advanced Route Plans
- Route Filters
- Discard Digit Instructions
- Transformation Masks
- Translation Patterns
- Route Plan Report
- Summary
- Review Questions
Configuring Hunt Groups and Call Coverage
- Configuring Hunt Groups and Call Coverage
- Call Distribution Components
- Configuring Line Groups, Hunt Lists, and Hunt Pilots
- Summary
- Review Questions
Implementing Telephony Call Restrictions and Control
- Implementing Telephony Call Restrictions and Control
- Class of Service Overview
- Partitions and Calling Search Spaces Overview
- Time-of-Day Routing Overview
- Configuring Time-of-Day Routing
- Time-of-Day Routing Usage Scenario
- Summary
- Review Questions
Implementing Multiple-Site Deployments
- Implementing Multiple-Site Deployments
- Call Admission Control
- Survivable Remote Site Telephony
- Summary
- Review Questions
Part IV: VoIP Features
Media Resources
- Media Resources
- Introduction to Media Resources
- Conference Bridge Resources
- Media Termination Point Resources
- Annunciator Resources
- Transcoder Resources
- Music on Hold Resources
- Media Resource Management
- Summary
- Review Questions
Configuring User Features, Part 1
- Configuring User Features, Part 1
- Basic IP Phone Features
- Softkey Templates
- Enhanced IP Phone Features
- Barge and Privacy
- IP Phone Services
- Summary
- Review Questions
Configuring User Features, Part 2
- Configuring User Features, Part 2
- Cisco CallManager Extension Mobility
- Client Matter Codes and Forced Authentication Codes
- Call Display Restrictions
- Malicious Call Identification
- Multilevel Precedence and Preemption
- Summary
- Review Questions
Configuring Cisco Unified CallManager Attendant Console
- Configuring Cisco Unified CallManager Attendant Console
- Introduction to Cisco CallManager Attendant Console
- Call Routing and Call Queuing
- Server and Administration Configuration
- Cisco Attendant Console Features
- Summary
- Review Questions
Configuring Cisco IP Manager Assistant
- Configuring Cisco IP Manager Assistant
- Cisco IP Manager Assistant Overview
- Cisco IP Manager Assistant Architecture
- Configuring Cisco IPMA for Shared-Line Support
- Summary
- Review Questions
Part V: IPT Security
Securing the Windows Operating System
- Securing the Windows Operating System
- Threats Targeting the Operating System
- Security and Hot Fix Policy
- Operating System Hardening
- Antivirus Protection
- Cisco Security Agent
- Administrator Password Policy
- Common Windows Exploits
- Security Taboos
- Summary
- Review Questions
Securing Cisco Unified CallManager Administration
- Securing Cisco Unified CallManager Administration
- Threats Targeting Remote Administration
- Securing CallManager Communications Using HTTPS
- Multilevel Administration
- Summary
- Review Questions
Preventing Toll Fraud
- Preventing Toll Fraud
- Toll Fraud Exploits
- Preventing Call Forward and Voice-Mail Toll Fraud Using Calling Search Spaces
- Blocking Commonly Exploited Area Codes
- Using Time-of-Day Routing
- Using FAC and CMC
- Restricting External Transfers
- Dropping Conference Calls
- Summary
- Review Questions
Hardening the IP Phone
Understanding Cryptographic Fundamentals
- Understanding Cryptographic Fundamentals
- What Is Cryptography?
- Symmetric Encryption
- Asymmetric Encryption
- Hash Functions
- Digital Signatures
- Summary
- Review Questions
Understanding the Public Key Infrastructure
- Understanding the Public Key Infrastructure
- The Need for a PKI
- PKI as a Trusted Third-Party Protocol
- PKI Entities
- PKI Enrollment
- PKI Revocation and Key Storage
- PKI Example
- Summary
- Review Questions
Understanding Cisco IP Telephony Authentication and Encryption Fundamentals
- Understanding Cisco IP Telephony Authentication and Encryption Fundamentals
- Threats Targeting the IP Telephony System
- How CallManager Protects Against Threats
- PKI Topologies in Cisco IP Telephony
- PKI Enrollment in Cisco IP Telephony
- Keys and Certificate Storage in Cisco IP Telephony
- Authentication and Integrity
- Encryption
- Summary
- Review Questions
Configuring Cisco IP Telephony Authentication and Encryption
- Configuring Cisco IP Telephony Authentication and Encryption
- Authentication and Encryption Configuration Overview
- Enabling Services Required for Security
- Using the CTL Client
- Working with Locally Significant Certificates
- Configuring the Device Security Mode
- Negotiating Device Security Mode
- Generating a CAPF Report
- Summary
- Review Questions
Part VI: IP Video
Introducing IP Video Telephony
- Introducing IP Video Telephony
- IP Video Telephony Solution Components
- Video Call Concepts
- Video Protocols Supported in Cisco CallManager
- Bandwidth Management
- Call Admission Control Within a Cluster
- Call Admission Control Between Clusters
- Summary
- Review Questions
Configuring Cisco VT Advantage
- Configuring Cisco VT Advantage
- Cisco VT Advantage Overview
- How Calls Work with Cisco VT Advantage
- Configuring Cisco CallManager for Video
- Configuring Cisco IP Phones for Cisco VT Advantage
- Installing Cisco VT Advantage on a Client
- Summary
- Review Questions
Part VII: IPT Management
Introducing Database Tools and Cisco Unified CallManager Serviceability
- Introducing Database Tools and Cisco Unified CallManager Serviceability
- Database Management Tools
- Cisco CallManager Serviceability Overview
- Tools Overview
- Summary
- Review Questions
Monitoring Performance
- Monitoring Performance
- Performance Counters
- Microsoft Event Viewer
- Microsoft Performance Monitor
- Real-Time Monitoring Tool Overview
- Summary
- Review Questions
Configuring Alarms and Traces
- Configuring Alarms and Traces
- Alarm Overview
- Alarm Configuration
- Trace Configuration
- Trace Analysis
- Trace Collection
- Bulk Trace Analysis
- Additional Trace Tools
- Summary
- Review Questions
Configuring CAR
- Configuring CAR
- CAR Overview
- CAR Configuration
- Report Scheduling
- System Database Configuration
- User Report Configuration
- Summary
- Review Questions
Using Additional Management and Monitoring Tools
- Using Additional Management and Monitoring Tools
- Remote Management Tools
- Dependency Records
- Password Changer Tool
- Cisco Dialed Number Analyzer
- Quality Report Tool
- Summary
- Review Questions
Part VIII: Appendix
Appendix A. Answers to Review Questions
Index
EAN: 2147483647
Pages: 329
