Understanding the Role of Keys in Database Design
So far, this chapter has presented quite a few ERDs. Many of them depict relationships, but so far there's been no discussion of exactly how a relationship between two entities is created and maintained. The answer is simple: We create fields in each entity called keys, which allow instances of one entity to be associated with instances of another. You might relate orders to customers, for example, by using a customer's Social Security number as a key. Each order would then contain the Social Security number of the related customer as one of its attributes. The following sections explore the concept of keys in more detail.
Keys That Determine Uniqueness
One of the crucial tenets of relational database theory is that it has to be possible to identify any database row, anywhere, without ambiguity. Put differently, every row in every table should have a unique identifier. If I have a record in a table of orders, I want to be able to ask it "What customer do you tie to?" and get an unambiguous answer. I need a simple answer: "Customer 400." End of story. The number 400, as it appears in the customer table, is a unique identifier.
A piece of data that is capable of uniquely identifying a database row is known as a primary key. A primary key is an attribute the values of which are (and always will be) unique for every single row in the database. It's a unique identifier, like a Social Security number, an ISBN number for a book, or a library card catalog number.
We recommend that every database table you design have a primary key, without exception. Some database systems force you to create a primary key for each new table. FileMaker Pro doesn't, but we strongly recommend that you do so anyway. There's very little to lose and a great deal to gain by following this practice.
The discussions in this chapter assume that every table you design, without exception, has a primary key.
Keys That Refer to Other Tables
Keys are essential to specifying relationships between tables. Going back to the example of customers and orders, the relationship between these entities is one-to-many: One customer may have many orders.
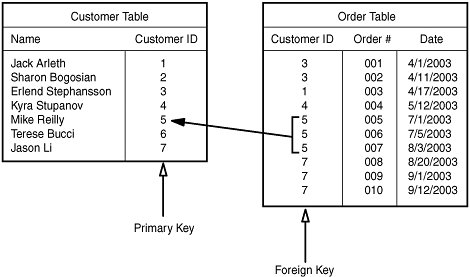
If you've followed the rule about always having a primary key, your Customer entity has a primary key, which you might call Customer ID. Now, each unique customer may have many related orders. To forge that relationship, each record in the Order table needs to store the Customer ID (the primary key) of the related customer. This value, when it's stored in the Order table, is known as a foreign key. The reason for the term is simple: The value in the Order table refers to a primary key value from a different ("foreign") table.
Figure 5.13 demonstrates how primary and foreign keys work together to create relationships between database tables. In a one-to-many relationship, the "many" side of the relationship always needs to contain a foreign key that points back to the "one" side. The child record thus "knows" who its parent is.
Figure 5.13. A one-to-many relationship between customers and orders, showing primary and foreign keys.
|
FileMaker Pro has several built-in capabilities that help you add strong key structures to your FileMaker databases. For some ideas on how best to define key fields in FileMaker Pro, see "Working with Keys and Match Fields," p. 162. |
Many to Many Relationships Solving the Puzzle |
Part I: Getting Started with FileMaker 8
FileMaker Overview
- FileMaker Overview
- FileMaker and Its Marketplace
- Introduction to Database Software
- FileMaker Deployment Options
- Whats New in FileMaker Pro 8
Using FileMaker Pro
- Getting Started
- Working in FileMaker Pro
- Troubleshooting
- FileMaker Extra: Becoming a FileMaker Pro Power User
Defining and Working with Fields
- Defining and Working with Fields
- Working Under the Hood
- Working with Fields
- Working with Field Types
- Assigning Field Options
- Troubleshooting
- FileMaker Extra: Indexing in FileMaker
Working with Layouts
- Working with Layouts
- Whats a Layout?
- Creating and Managing Layouts
- Working with Parts
- Working with Objects on a Layout
- Working with the Tab Control Object
- Working with Fields
- Portals
- Troubleshooting
- FileMaker Extra: Designing Cross-PlatformFriendly Layouts
Part II: Developing Solutions with FileMaker
Relational Database Design
- Relational Database Design
- Understanding Database Design
- Database Analysis
- Working with Entities and Attributes
- Understanding Relationships
- Relationship Optionality
- Understanding the Role of Keys in Database Design
- Many-to-Many Relationships: Solving the Puzzle
- The Basics of Process Analysis
- FileMaker Extra: Complex Many-to-Many Relationships
Working with Multiple Tables
- Working with Multiple Tables
- Multitable Systems in FileMaker Pro
- Creating a One-to-Many Relationship in FileMaker
- Working with Keys and Match Fields
- Understanding Table Context
- Working with Related Data
- Creating a Many-to-Many Relationship
- Relational Integrity
- Rapid Multitable Development
- Troubleshooting
- FileMaker Extra: Building a Three-Way Join
Working with Relationships
- Working with Relationships
- Relationships Graphs and ERDs
- Relationships as Queries
- Creating Self-Relationships
- Creating Ranged Relationships
- Creating Cross-Product Relationships
- Working with Data from Distant Tables
- Working with Multiple Files
- How and When to Use Multiple Files
- Troubleshooting
- FileMaker Extra: Managing the Relationships Graph
Getting Started with Calculations
- Getting Started with Calculations
- Understanding How and Where Calculations Are Used
- Exploring the Calculation Dialog Box
- Essential Functions
- Using Conditional Functions
- Aggregate Functions
- Learning About the Environment
- Troubleshooting
- FileMaker Extra: Tips for Becoming a Calculation Master
Getting Started with Scripting
- Getting Started with Scripting
- Scripts in FileMaker Pro
- Creating Scripts
- Common Scripting Topics
- Triggering Scripts
- Working with Buttons on Layouts
- Troubleshooting
- FileMaker Extra: Creating a Script Library
Getting Started with Reporting
- Getting Started with Reporting
- Deriving Meaning from Data
- Working with Lists of Data
- Summarized Reports
- Delivering Reports
- Troubleshooting
- FileMaker Extra: Incorporating Reports into the Workflow
Part III: Developer Techniques
Developing for Multiuser Deployment
- Developing for Multiuser Deployment
- Developing for Multiple Users
- Sessions in FileMaker Pro
- Concurrency
- Audit Trails in FileMaker Pro
- Launch Files
- Troubleshooting
- FileMaker Extra: Development with a Team
Implementing Security
- Approaching Security
- User-Level Internal Security
- File-Level Access Security
- Troubleshooting
- FileMaker Extra: Working with Multiple Files
Advanced Interface Techniques
- Advanced Interface Techniques
- User Interfaces in FileMaker Pro
- Navigation
- Multiwindow Interfaces
- Working with Custom Menus
- Showing/Hiding Layout Elements
- Dedicated Find Layouts
- Data Presentation
- Working with Table View
- Troubleshooting
- FileMaker Extra: User Interface Heuristics
Advanced Calculation Techniques
- Advanced Calculation Techniques
- Whats an Advanced Calculation Technique?
- Logical Functions
- Text Formatting Functions
- Array Functions
- The Filter-ing Functions
- Custom Functions
- GetNthRecord
- Troubleshooting
- FileMaker Extra: Creating a Custom Function Library
Advanced Scripting Techniques
- Advanced Scripting Techniques
- What Is Advanced Scripting?
- Script Parameters and Script Results
- Script Variables
- Window Management Techniques
- Go to Related Record
- Troubleshooting
- FileMaker Extra: Recursive Scripts
Advanced Portal Techniques
- Advanced Portal Techniques
- Portals in FileMaker Pro
- Portal Basics
- New Record Only Relationships
- Horizontal Portals
- Using Portals to Create Calendars
- Selection Portals
- Filtered Portals
- Dynamic Portal Sorting
- Troubleshooting
- FileMaker Extra: Portals and Record Locking
Debugging and Troubleshooting
- Debugging and Troubleshooting
- What Is Troubleshooting?
- Staying Out of Trouble
- Planning for Trouble
- Troubleshooting Scripts and Calculations
- Troubleshooting in Specific Areas: Performance, Context, Connectivity, and Globals
- File Maintenance and Recovery
- FileMaker Extra: Other Tools of the Trade
Converting Systems from Previous Versions of FileMaker Pro
- Converting Systems from Previous Versions of FileMaker Pro
- Migration Choices
- Converting Files
- Pre-Conversion Tasks
- Post-Conversion Tasks
- Troubleshooting
- FileMaker Extra: Converting Web-Enabled Databases
Part IV: Data Integration and Publishing
Importing Data into FileMaker Pro
- Importing Data into FileMaker Pro
- Working with External Data
- Flat-File Data Sources
- Importing Multiple Files from a Folder
- Importing Photos from a Digital Camera
- Importing from an ODBC Data Source
- Importing from an XML Data Source
- Using a Script to Import Data
- Troubleshooting
- FileMaker Extra: Exploiting the FileMaker-to-FileMaker Import
Exporting Data from FileMaker
- Exporting Data from FileMaker
- Getting Out What You Put In
- The Basic Mechanics of Exporting
- Export File Formats
- Formatting Exported Data
- Exporting Related Fields
- Exporting Grouped Data
- Exporting to Fixed-Width Formats
- Working with Large Fields and Container Fields
- Scripted Exports
- Accessing FileMaker Data Using ODBC and JDBC
- Using FileMaker Pro as an ODBC Client
- Troubleshooting
- FileMaker Extra: Accessing FileMaker Data via JDBC
Instant Web Publishing
- Instant Web Publishing
- An Overview of Instant Web Publishing
- Enabling and Configuring IWP
- Designing for IWP Deployment
- Using an IWP Solution
- Troubleshooting
- FileMaker Extra: Building Your Own Next and Previous Page Buttons
FileMaker and Web Services
- FileMaker and Web Services
- About Web Services
- FileMaker and XML
- Transforming XML
- XML Import: Understanding Web Services
- Working with Web Services
- Troubleshooting
- FileMaker Extra: Write Your Own Web Services
Custom Web Publishing
- Custom Web Publishing
- About Custom Web Publishing
- Custom Web Publishing Versus Instant Web Publishing
- Custom Web Publishing Versus XML Export
- Getting Your Databases Ready for Custom Web Publishing
- Publishing FileMaker Data as XML
- Using XSLT with Custom Web Publishing
- Building Web Applications with XSLT-CWP
- Other Custom Web Publishing Commands and Parameters
- About the FileMaker XSLT Extensions
- Troubleshooting
- FileMaker Extra: About the Custom Web Publishing Tools
Part V: Deploying a FileMaker Solution
Deploying and Extending FileMaker
- Deploying and Extending FileMaker
- FileMaker Deployment Options
- Single User
- Peer-to-Peer Hosting
- FileMaker Server
- Web Publishing
- ODBC/JDBC
- Citrix/Terminal Services
- Runtime Solutions
- Deploying to Handheld Devices
- Customized Deployment Options
- Troubleshooting
- FileMaker Extra: The Limits of Customization
FileMaker Server and Server Advanced
- FileMaker Server and Server Advanced
- About FileMaker Server
- Installing FileMaker Server
- Running FileMaker Server
- Using the Server Administration Tool
- Configuring and Administering FileMaker Server Using the SAT
- Managing Clients
- Managing Databases
- Administration from the Command Line
- Working with External Services
- Automatically Updating Plug-ins
- Scheduled Tasks
- Monitoring FileMaker Server
- Troubleshooting
- FileMaker Extra: Best Practices Checklist
FileMaker Mobile
- FileMaker Mobile
- FileMaker Mobile 8 Overview
- Using FileMaker Mobile on Your Handheld Device
- Troubleshooting
- FileMaker Extra: Publishing Related Data
Documenting Your FileMaker Solutions
- Documenting Your FileMaker Solutions
- Why Is Documentation Important?
- Developing Naming Conventions
- Using Comments Effectively
- Documenting the Relationships Graph
- Using the Database Design Report
- Using Third-Party Documentation Tools
- Putting the Finishing Touches on Your Documentation
- Final Thoughts on Documentation
- FileMaker Extra: Soliant Development Standards
EAN: 2147483647
Pages: 296
