Using Objects
B Trees
It is sometimes necessary to store a set of data so large that it cannot fit in memory. This section introduces B-trees (B for balanced), which are commonly used in database programs. A B-tree is similar to a red-black tree (Section 14.4), but it goes to great lengths to minimize the number of disk accesses needed to find, insert, or delete an element.
A typical B-tree is shown in Figure 17-34.
Figure 17-34. A B-tree.
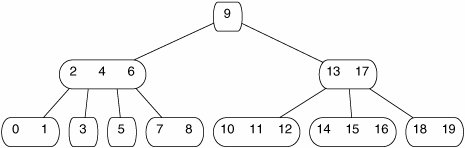
A B-tree is defined as follows:
- A node can hold more than one element. There are upper and lower limits on the number of elements, to be explained shortly.
- The number of children that an internal node has is always one more than the number of elements it has.
- The children are interlaced with the elements. All of the elements in the subtree rooted at a child are greater than the element to the left of that child and less than the element to the right.
- All of the leaves are on the same level. This ensures that the tree is balanced.
The limit on node sizes depends on a constant m. In Figure 17-34, m is 2. No internal node has more than 2m children. No internal node (except possibly the root) has fewer than m children. The number of elements in a node (other than the root) is between m 1 and 2m 1. We define the size of a node to be one more than the number of elements it has. For an internal node, the size is the number of children. A node of size m is called minimal. A node of size 2m is called full.
We use m = 2 in our diagrams so that they'll fit on the page. In practice, m is much larger, perhaps 200. This is because it is not much more expensive to read (or write) a bunch of data than a single element. We'd like a node to be as large as possible, but still small enough that we can read it in one disk access.
Having large nodes also makes the tree extremely shallow. This reduces the number of nodes examined in a search, which in turn reduces the number of disk accesses. The number of elements on each level increases exponentially with depth (Figure 17-35). If m = 200, then level 2 alone could contain nearly 64 million elementsand we can find any of them in only three disk accesses! This fabulous performance justifies the complicated coding required for B-trees.
|
Level |
Minimum # of elements |
Maximum # of elements |
|---|---|---|
|
0 |
1 |
2m 1 |
|
1 |
2(m 1) |
2m(2m 1) |
|
2 |
2m(m 1) |
4m2(2m 1) |
|
d |
2md1(m 1) |
(2m)d(2m 1) |
Each of the Set operations (search, insertion, and deletion) is accomplished in one downward pass through the tree. In the worst case, therefore, each operation makes a number of disk accesses proportional to the height of the tree. The height of a B-tree is proportional to logm n. When m is large, the tree is very short.
Search
Searching a B-tree is much like searching a binary search tree. We first examine the root to see if the element in question is there; if not, we descend to the appropriate child. This continues until either we find the target or we try to descend from a leaf (in which case we give up).
Insertion
As with a red-black tree, we have to do some acrobatics when inserting an element into a B-tree to make sure we still have a B-tree when we're done. Specifically, every node has to have an acceptable number of elements, and all of the leaves have to be at the same level.
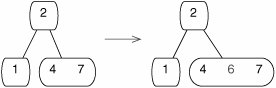
In the simplest case, the tree consists of a single nonfull node. We just insert the new element in the right place (Figure 17-36).
Figure 17-36. When a B-tree consists of a single nonfull node (left), a new element can be inserted directly into this node.

In general, the root is not a leaf, so we have to descend to another node (Figure 17-37).
Figure 17-37. Inserting 6 in a B-tree. The target is not present in the root, we have to descend to a leaf.
What if we now want to insert 5? It belongs in the right leaf, but there's no room. In this case, we first split the leaf into two nodes, moving the middle element up into the parent (Figure 17-38). A full node has exactly enough elements to remove one and leave enough elements to make two minimal nodes.
Figure 17-38. Inserting 5 into a B-tree. The right leaf is full, so we have to split it (middle) before we can insert the target.
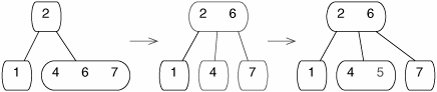
Notice that the parent node gains an element as a result of the splitting. To make sure that this does not cause a further overflow, we always split a full node before descending into it to insert. If the root splits, the tree becomes taller. Binary search trees, in contrast, become taller by adding new leaves.
Deletion
Removing an element from a leaf is trivial (Figure 17-39).
Figure 17-39. Deleting 2 from a leaf.

What if the leaf is minimal? This isn't a problem, because we always make sure a node is nonminimal before descending into it to delete. The root is an exception, because it is allowed to have fewer elements than other nodes.
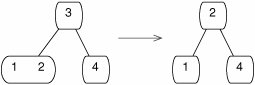
Splicing an element out of an internal node is not so simple. Our first approach is similar to the deletion algorithm for binary search trees: we remove either the inorder successor or the inorder predecessor of the target and copy it into the target's old location (Figure 17-40).
Figure 17-40. Deleting 3 from a B-tree. The target is present in an internal node, so we replace it with (in this case) its inorder predecessor.
Sometimes it is not possible to remove a predecessor or successor, because they are both in minimal nodes. In this case, we have to merge the two children (Figure 17-41). Merging is like splitting in reverse.
Figure 17-41. Deleting 2 from a B-tree. It cannot be replaced by a predecessor or successor, so its children are merged.
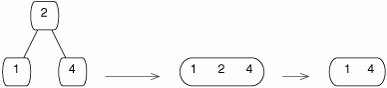
When two siblings are merged, their parent loses an element. The elements from the two minimal siblings, plus one element from their parent, just barely fit into a full node. If (as in Figure 17-41) the root loses its last element, the tree becomes shorter.
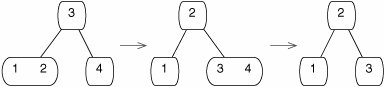
There are still more cases to handle. If the target is not present in the current node, we have to descend to a child. If that child is minimal, we have to make it larger before descending. If the child has a nonminimal sibling, we can enlarge the child with a rotation (Figure 17-42), which is similar to the rotations used in red-black trees (Section 14.4).
Figure 17-42. Deleting 4 from a B-tree. The node containing the target is minimal, so we can't descend into it (left). We make it larger by performing a right rotation, moving 2 up into the parent and 3 down into the right child (middle). Now we can descend into the node and delete 4 (right).
If the child has no nonminimal siblings, we can't rotate in another element. In this case, we merge the child with one of its siblings.
Implementation
We now provide a working implementation of B-trees storing ints. This code demonstrates the key ideas and complexities of B-trees. A professional implementation would store more general objects, such as employee records.
We begin with the BTreeNode class. Each node has elements and (unless it is a leaf) children. In any other data structure, we would have references to child objects. We don't want to do that here, because we want each BTreeNode stored in a separate file. We keep an id number for each node. The node with id 37, for example, is stored in the file b37.node. Each node knows its own id and the ids of its children.
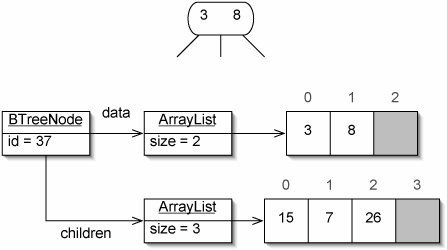
In our representation, each BTreeNode contains an int id and two ArrayLists, data and children (Figure 17-43). In a leaf, children is null.
Figure 17-43. A B-tree node (top) is represented by an instance of the BTreeNode class (bottom). This node has size 3. Note the indices of the arrays.
(This item is displayed on page 499 in the print version)
Before we get to the code for the BTreeNode class, we have to address the question of how we will generate these id numbers. It seems clear that we want a counter that keeps track of the next available id. Whenever we get a new id, we increment the counter. If this counter is a variable in a method, we'll get the same id every time we run the method, which is no good. A nonstatic field isn't much better, because each instance will generate its own sequence of ids. A static field almost does the trick, but it will start from scratch every time we start the program, causing us to overwrite files we saved previously.
The only way we can make this work is to save the counter in a file. This way, when the program starts, it can read the value of the counter from the file and pick up where we left off. The class IdGenerator (Figure 17-44) uses a tiny file id to store this single int. The constant BTree.DIR specifies the directory where all of the files will live.
Figure 17-44. Every time we invoke IdGenerator.nextId(), we get a new id number, even if we have restarted our program since the last time we invoked it.
1 import java.io.*;
2
3 /** Generates unique id numbers, even across multiple sessions. */
4 public class IdGenerator {
5
6 /** File in which the next available id is stored. */
7 public static final File FILE = new File(BTree.DIR + "id");
8
9 /** Return the next available id number. */
10 public static int nextId() {
11 try {
12 int result;
13 if (FILE.exists()) {
14 ObjectInputStream in
15 = new ObjectInputStream(new FileInputStream(FILE));
16 result = in.readInt();
17 } else {
18 result = 0;
19 }
20 ObjectOutputStream out
21 = new ObjectOutputStream(new FileOutputStream(FILE));
22 out.writeInt(result + 1); 23 out.close(); 24 return result; 25 } catch (IOException e) { 26 e.printStackTrace(); 27 System.exit(1); 28 return 0; 29 } 30 } 31 32 } |
Now we can get started on the BTreeNode class (Figure 17-45). Since we'll be writing BTreeNodes to disk, the class implements Serializable. The constant HALF_MAX is the number m mentioned previously. There is no field for size; the size of a node is computed by invoking size() on data and adding one (line 32).
Figure 17-45. Beginning of the BTreeNode class. We use the version of ArrayList from java.util because we need its constructor accepting a capacity (lines 24 and 26) and one of its add() methods (used later in this section).
| 1 import java.io.*; 2 3 /** Node in a BTree. */ 4 public class BTreeNode implements Serializable { 5 6 /** Minimum number of children. Max is twice this. */ 7 public static final int HALF_MAX = 2; 8 9 /** Items stored in this node. */ 10 private java.util.ArrayList data; 11 12 /** Ids of children of this node. */ 13 private java.util.ArrayList children; 14 15 /** Number identifying this node. */ 16 private int id; 17 18 /** 19 * The new node has no data or children yet. The argument 20 * leaf specifies whether it is a leaf. 21 */ 22 public BTreeNode(boolean leaf) { 23 this.id = IdGenerator.nextId(); 24 data = new java.util.ArrayList((HALF_MAX * 2) - 1); 25 if (!leaf) { 26 children = new java.util.ArrayList(HALF_MAX * 2); 27 } 28 } 29 30 /** Return one plus the number of items in this node. */ 31 public int size() { 32 return data.size() + 1; 33 } 34 35 } |
The methods for reading and writing BTreeNodes to disk are given in Figure 17-46. Because they involve the disk, these methods (and any others that invoke them) are extremely expensive. If any exception occurs, we catch it and crash, because it's almost certainly an IOException about which we can't do anything.
Figure 17-46. BTreeNode methods for disk access.
1 /** Delete the file containing this node from the disk. */
2 public void deleteFromDisk() {
3 try {
4 File file = new File(BTree.DIR + "b" + id + ".node");
5 file.delete();
6 } catch (Exception e) {
7 e.printStackTrace();
8 System.exit(1);
9 }
10 }
11
12 /** Read from disk and return the node with the specified id. */
13 public static BTreeNode readFromDisk(int id) {
14 try {
15 ObjectInputStream in
16 = new ObjectInputStream
17 (new FileInputStream(BTree.DIR + "b" + id + ".node"));
18 return (BTreeNode)(in.readObject());
19 } catch (Exception e) {
20 e.printStackTrace();
21 System.exit(1);
22 return null;
23 }
24 }
25
26 /** Write this node to disk. */ 27 public void writeToDisk() { 28 try { 29 ObjectOutputStream out 30 = new ObjectOutputStream 31 (new FileOutputStream(BTree.DIR + "b" + id + ".node")); 32 out.writeObject(this); 33 out.close(); 34 } catch (Exception e) { 35 e.printStackTrace(); 36 System.exit(1); 37 } 38 } |
Some additional convenience methods are given in Figure 17-47.
Figure 17-47. More methods from the BTreeNode class.
1 /**
2 * Read the ith child of this node from the disk and return it.
3 * If this node is a leaf, return null.
4 */
5 public BTreeNode getChild(int index) {
6 if (isLeaf()) {
7 return null;
8 } else {
9 return readFromDisk(children.get(index));
10 }
11 }
12
13 /** Return the id of this node. */
14 public int getId() {
15 return id;
16 }
17
18 /** Return true if this node is full. */
19 public boolean isFull() {
20 return size() == HALF_MAX * 2;
21 }
22
23 /** Return true if this node is minimal. */
24 public boolean isMinimal() {
25 return size() == HALF_MAX;
26 }
27
28 /** Make this node a leaf if value is true, not a leaf otherwise. */ 29 public void setLeaf(boolean value) { 30 if (value) { 31 children = null; 32 } else { 33 children = new java.util.ArrayList(HALF_MAX * 2); 34 } 35 } |
We will need more methods in BTreeNode, but let's look at the BTree class (Figure 17-48). A BTree has only one field: the id of the root node. The BTree object is stored in the file btree. Our implementation supports only a single B-tree at any one time, although it could be easily modified to store each tree in a different directory.
Figure 17-48. Easy parts of the BTree class.
1 import java.io.*;
2
3 /** BTree storing many ints on disk. */
4 public class BTree implements Serializable {
5
6 /** Directory where files are stored. */
7 public static final String DIR
8 = BTree.class.getProtectionDomain().getCodeSource()
9 .getLocation().getFile() + File.separator;
10
11 /** Id number of the root node. */
12 private int rootId;
13
14 /** A new BTree is initially empty. */
15 public BTree() {
16 BTreeNode root = new BTreeNode(true);
17 rootId = root.getId();
18 root.writeToDisk();
19 writeToDisk();
20 }
21
22 /** Read a previously saved BTree from disk. */
23 public static BTree readFromDisk() {
24 try {
25 ObjectInputStream in
26 = new ObjectInputStream
27 (new FileInputStream(DIR + "btree"));
28 return (BTree)(in.readObject()); 29 } catch (Exception e) { 30 e.printStackTrace(); 31 System.exit(1); 32 return null; 33 } 34 } 35 36 /** Write this BTree to disk. */ 37 public void writeToDisk() { 38 try { 39 ObjectOutputStream out 40 = new ObjectOutputStream 41 (new FileOutputStream(DIR + "btree")); 42 out.writeObject(this); 43 out.close(); 44 } catch (Exception e) { 45 e.printStackTrace(); 46 System.exit(1); 47 } 48 } 49 50 } |
There are two parts to searching. We have to be able to find an element within a node, and we have to be able to find an element within an entire tree.
To search for an element within a node, we use the indexOf() method from the BTreeNode class (Figure 17-49). If target is present in the node, indexOf() returns its index in the node's data ArrayList. If not, indexOf() returns a noninteger indicating which subtree to search next. For example, if target belongs in subtree 1, indexOf() returns 1.5.
Figure 17-49. The indexOf() method from the BTreeNode class returns a double.
1 /**
2 * Return the index of target in this node if present. Otherwise,
3 * return the index of the child that would contain target,
4 * plus 0.5.
5 */
6 public double indexOf(int target) {
7 for (int i = 0; i < data.size(); i++) {
8 if (data.get(i) == target) {
9 return i;
10 }
11 if (data.get(i) > target) { 12 return i + 0.5; 13 } 14 } 15 return size() - 0.5; 16 } |
To search the entire tree, we use the contains() method in the BTree class (Figure 17-50), which invokes indexOf(). On line 6, the result d is converted to an int i. If d is an integer, i is the index of target in data. Otherwise, i is the index of the child to which we want to descend.
Figure 17-50. The contains() method from the BTree class.
1 /** Return true if this BTree contains target. */
2 public boolean contains(int target) {
3 BTreeNode node = BTreeNode.readFromDisk(rootId);
4 while (node != null) {
5 double d = node.indexOf(target);
6 int i = (int)d;
7 if (i == d) {
8 return true;
9 } else {
10 node = node.getChild(i);
11 }
12 }
13 return false;
14 }
|
For insertion, we begin with the add() method from the BTree class (Figure 17-51).
Figure 17-51. The add() method from the BTree class.
1 /** Add target to this BTree and write modified nodes to disk. */
2 public void add(int target) {
3 BTreeNode root = BTreeNode.readFromDisk(rootId);
4 if (root.isFull()) {
5 BTreeNode parent = new BTreeNode(root);
6 rootId = parent.getId();
7 writeToDisk();
8 parent.add(target);
9 } else {
10 root.add(target);
11 }
12 }
|
If the root is full, add() invokes a second constructor for BTreeNode, which splits the root and returns the new parent (Figure 17-52). Recall that the statement this(false), on line 6, invokes the constructor from Figure 17-45.
Figure 17-52. A second constructor for the BTreeNode class.
1 /**
2 * Create a new node that has two children, each containing
3 * half of the items from child. Write the children to disk.
4 */
5 public BTreeNode(BTreeNode child) {
6 this(false);
7 children.add(child.getId());
8 splitChild(0, child);
9 }
|
We now look at our first complicated method, add() from BTreeNode (Figure 17-53). This method descends to the proper node and adds target locally to that node. On lines 34 and 36, addToLocally() invokes a version of the add() method from the java.util.ArrayList class that inserts an element at a particular location, shifting all subsequent elements to the right.
Figure 17-53. The add() and addLocally() methods from BTreeNode.
1 /**
2 * Add target to the subtree rooted at this node. Write nodes
3 * to disk as necessary.
4 */
5 public void add(int target) {
6 BTreeNode node = this;
7 while (!(node.isLeaf())) {
8 double d = node.indexOf(target);
9 int i = (int)d
10 if (i == d) {
11 return;
12 } else {
13 BTreeNode child = node.getChild(i);
14 if (child.isFull()) {
15 node.splitChild(i, child);
16 } else {
17 node.writeToDisk();
18 node = child;
19 }
20 }
21 }
22 node.addLocally(target);
23 node.writeToDisk();
24 }
25
26 /** 27 * Add target to this node, which is assumed not to be full. 28 * Make room for an extra child to the right of target. 29 */ 30 protected void addLocally(int target) { 31 double d = indexOf(target); 32 int i = (int)d; // Because d might be negative 33 if (i != d) { 34 data.add(i, target); 35 if (!isLeaf()) { 36 children.add(i + 1, 0); 37 } 38 } 39 } |
Splitting a child is handled by the splitChild() method (Figure 17-54). On line 7, this method removes the middle element from child (shifting all subsequent elements to the left) and adds it to the parent.
Figure 17-54. The splitChild() and createRightSibling() methods from BTreeNode.
1 /**
2 * Split child, which is the full ith child of this node, into
3 * two minimal nodes, moving the middle item up into this node.
4 */
5 protected void splitChild(int i, BTreeNode child) {
6 BTreeNode sibling = child.createRightSibling();
7 addLocally(child.data.remove(HALF_MAX - 1));
8 child.writeToDisk();
9 children.set(i + 1, sibling.getId());
10 }
11
12 /**
13 * Create and return a new node which will be a right sibling
14 * of this one. Half of the items and children in this node are
15 * copied to the new one.
16 */
17 protected BTreeNode createRightSibling() {
18 BTreeNode sibling = new BTreeNode(isLeaf());
19 for (int i = HALF_MAX; i < (HALF_MAX * 2) - 1; i++) {
20 sibling.data.add(data.remove(HALF_MAX));
21 }
22 if (!isLeaf()) { 23 for (int i = HALF_MAX; i < HALF_MAX * 2; i++) { 24 sibling.children.add(children.remove(HALF_MAX)); 25 } 26 } 27 sibling.writeToDisk(); 28 return sibling; 29 } |
The two loops on lines 1921 and 2325 of createRightSibling() are not as efficient as they could be. Since each invocation of remove() on an ArrayList takes linear time, the total time for each of these lists is quadratic. This is not too big a problem, because it is quadratic in the size of a node (which is limited to 2 * HALF_MAX) rather than the number of elements in the B-tree. More importantly, this work is all being done in memory, so it is dwarfed by the cost of a disk access. A professional implementation would probably improve the efficiency of this method at the expense of code clarity.
Finally, we turn to the really nasty part: deletion. The remove() method from BTree (Figure 17-55) seems innocent enough.
Figure 17-55. The remove() method from BTree.
1 /** Remove target from this BTree. */
2 public void remove(int target) {
3 BTreeNode root = BTreeNode.readFromDisk(rootId);
4 root.remove(target);
5 if ((root.size() == 1) && (!(root.isLeaf()))) {
6 BTreeNode child = root.getChild(0);
7 root.deleteFromDisk();
8 rootId = child.getId();
9 writeToDisk();
10 }
11 }
|
This invokes the remove() method from BTreeNode (Figure 17-56). There are three possibilities here: this is a leaf (lines 812), target is present but this is not a leaf (lines 1314), or target belongs in a subtree (lines 1516). The first case is trivial; we just have to remove target from data. The other two cases are somewhat hairier, so they are delegated to other methods.
We have to make sure every node is nonminimal before we descend into it. This is accomplished with rotation and merging. These operations are complicated, because there are so many special cases. To find a sibling from which we can rotate an element, we have to examine the left and right siblings; if they are both minimal, we have to merge. Worse yet, the leftmost child has no left sibling and the rightmost child has no right sibling, so we need special code to avoid ArrayIndexOutOfBoundsExceptions in these cases.
Figure 17-56. The remove() method from BTreeNode.
1 /**
2 * Remove target from the subtree rooted at this node.
3 * Write any modified nodes to disk.
4 */
5 public void remove(int target) {
6 double d = indexOf(target);
7 int i = (int)d
8 if (isLeaf()) {
9 if (i == d) {
10 data.remove(i);
11 writeToDisk();
12 }
13 } else if (i == d) {
14 removeFromInternalNode(i, target);
15 } else {
16 removeFromChild(i, target);
17 }
18 }
|
We first address removeFromInternalNode() (Figure 17-57). As in a binary search tree, our plan is to replace target with its inorder predecessor or successor. We'd like to take something from a subtree with a nonminimal root, which might be to the left or to the right of target. If both of the children next to target are minimal, we have to merge them.
Figure 17-57. The removeFromInternalNode() and mergeChildren() methods from BTreeNode.
1 /**
2 * Remove the ith item (target) from this node.
3 * Write any modified nodes to disk.
4 */
5 protected void removeFromInternalNode(int i, int target) {
6 BTreeNode child = getChild(i);
7 BTreeNode sibling = getChild(i + 1);
8 if (!(child.isMinimal())) {
9 data.set(i, child.removeRightmost());
10 writeToDisk();
11 } else if (!(sibling.isMinimal())) {
12 data.set(i, sibling.removeLeftmost());
13 writeToDisk();
14 } else {
15 mergeChildren(i, child, sibling);
16 writeToDisk();
17 child.remove(target); 18 } 19 } 20 21 /** 22 * Merge this node's ith and (i+1)th children (child and sibling, 23 * both minimal), moving the ith item down from this node. 24 * Delete sibling from disk. 25 */ 26 protected void mergeChildren(int i, BTreeNode child, 27 BTreeNode sibling) { 28 child.data.add(data.remove(i)); 29 children.remove(i + 1); 30 if (!(child.isLeaf())) { 31 child.children.add(sibling.children.remove(0)); 32 } 33 for (int j = 0; j < HALF_MAX - 1; j++) { 34 child.data.add(sibling.data.remove(0)); 35 if (!(child.isLeaf())) { 36 child.children.add(sibling.children.remove(0)); 37 } 38 } 39 sibling.deleteFromDisk(); 40 } |
Removing the leftmost element in a subtree sounds easy enough, so the length of the method (Figure 17-58) may be surprising. The problem is that we might encounter a minimal node on the way down. If so, we make it larger by rotating in an element from its sibling (line 14) or, if the sibling is also minimal, merging it with its sibling (line 12).
Figure 17-58. The removeLeftmost() and rotateLeft() methods from BTreeNode.
1 /**
2 * Remove and return the leftmost element in the leftmost descendant
3 * of this node. Write any modified nodes to disk.
4 */
5 protected int removeLeftmost() {
6 BTreeNode node = this;
7 while (!(node.isLeaf())) {
8 BTreeNode child = node.getChild(0);
9 if (child.isMinimal()) {
10 BTreeNode sibling = node.getChild(1);
11 if (sibling.isMinimal()) {
12 node.mergeChildren(0, child, sibling); 13 } else { 14 node.rotateLeft(0, child, sibling); 15 } 16 } 17 node.writeToDisk(); 18 return child.removeLeftmost(); 19 } 20 int result = node.data.remove(0); 21 node.writeToDisk(); 22 return result; 23 } 24 25 /** 26 * Child is the ith child of this node, sibling the (i+1)th. 27 * Move one item from sibling up into this node, one from this 28 * node down into child. Pass one child from sibling to node. 29 * Write sibling to disk. 30 */ 31 protected void rotateLeft(int i, BTreeNode child, 32 BTreeNode sibling) { 33 child.data.add(data.get(i)); 34 if (!(child.isLeaf())) { 35 child.children.add(sibling.children.remove(0)); 36 } 37 data.set(i, sibling.data.remove(0)); 38 sibling.writeToDisk(); 39 } |
Removing the rightmost element involves the same issues (Figure 17-59).
Figure 17-59. The removeRightmost() and rotateRight() methods from BTreeNode.
1 /**
2 * Remove and return the rightmost element in the rightmost
3 * descendant of this node. Write any modified nodes to disk.
4 */
5 protected int removeRightmost() {
6 BTreeNode node = this;
7 while (!(node.isLeaf())) {
8 BTreeNode child = node.getChild(size() - 1);
9 if (child.isMinimal()) {
10 BTreeNode sibling = node.getChild(size() - 2);
11 if (sibling.isMinimal()) { 12 node.mergeChildren(size() - 2, sibling, child); 13 child = sibling; 14 } else { 15 node.rotateRight(size() - 2, sibling, child); 16 } 17 } 18 node.writeToDisk(); 19 return child.removeRightmost(); 20 } 21 int result = node.data.remove(size() - 2); 22 node.writeToDisk(); 23 return result; 24 } 25 26 /** 27 * Sibling is the ith child of this node, child the (i+1)th. 28 * Move one item from sibling up into this node, one from this 29 * node down into child. Pass one child from sibling to node. 30 * Write sibling to disk. 31 */ 32 protected void rotateRight(int i, BTreeNode sibling, 33 BTreeNode child) { 34 child.data.add(0, data.get(i)); 35 if (!(child.isLeaf())) { 36 child.children.add(0, 37 sibling.children.remove(sibling.size() - 1)); 38 } 39 data.set(i, sibling.data.remove(sibling.size() - 2)); 40 sibling.writeToDisk(); 41 } |
Good news: now that we've laid all the groundwork for rotation and merging, only the removeFromChild() method (Figure 17-60) remains. This one is so long because we have to handle the special cases where target belongs in the first child, the last child, or one in between. In any case, we might be able to rotate an element in from a sibling, or we might have to merge.
It goes without saying that B-trees are difficult to implement and debug. Their ability to find any element in a database of billions with a handful of disk accesses justifies this effort.
Figure 17-60. The removeFromChild() method from BTreeNode.
1 /**
2 * Remove target from the subtree rooted at child i of this node.
3 * Write any modified nodes to disk.
4 */
5 protected void removeFromChild(int i, int target) {
6 BTreeNode child = getChild(i);
7 if (child.isMinimal()) {
8 if (i == 0) { // Target in first child
9 BTreeNode sibling = getChild(1);
10 if (sibling.isMinimal()) {
11 mergeChildren(i, child, sibling);
12 } else {
13 rotateLeft(i, child, sibling);
14 }
15 } else if (i == size() - 1) { // Target in last child
16 BTreeNode sibling = getChild(i - 1);
17 if (sibling.isMinimal()) {
18 mergeChildren(i - 1, sibling, child);
19 child = sibling;
20 } else {
21 rotateRight(i - 1, sibling, child);
22 }
23 } else { // Target in middle child
24 BTreeNode rightSibling = getChild(i + 1);
25 BTreeNode leftSibling = getChild(i - 1);
26 if (!(rightSibling.isMinimal())) {
27 rotateLeft(i, child, rightSibling);
28 } else if (!(leftSibling.isMinimal())) {
29 rotateRight(i - 1, leftSibling, child);
30 } else {
31 mergeChildren(i, child, rightSibling);
32 }
33 }
34 }
35 writeToDisk();
36 child.remove(target);
37 }
|
Exercises
| 17.11 |
Are the nodes of a B-tree always, sometimes, or never full when the root is split? |
| 17.12 |
Explain why 1 is not a legitimate value for HALF_MAX. |
| 17.13 |
Draw a UML instance diagram of an empty BTree. |
| 17.14 |
Write an isEmpty() method for the BTree class. |
| 17.15 |
Modify indexOf() (Figure 17-49) to use binary search rather than linear search. |
| 17.16 |
Write a useful toString() method for the BTree class. |
Part I: Object-Oriented Programming
Encapsulation
Polymorphism
Inheritance
- Inheritance
- Extending a Class
- The Object Class
- Packages and Access Levels
- Summary
- Vocabulary
- Problems
- Projects
Part II: Linear Structures
Stacks and Queues
- Stacks and Queues
- The Stack Interface
- The Call Stack
- Exceptions
- The Queue Interface
- Summary
- Vocabulary
- Problems
- Projects
Array-Based Structures
- Array-Based Structures
- Shrinking and Stretching Arrays
- Implementing Stacks and Queues
- The List Interface
- Iterators
- The Java Collections Framework: A First Look
- Summary
- Vocabulary
- Problems
- Projects
Linked Structures
- Linked Structures
- List Nodes
- Stacks and Queues
- The LinkedList Class
- The Java Collections Framework Revisited
- Summary
- Vocabulary
- Problems
- Projects
Part III: Algorithms
Analysis of Algorithms
- Analysis of Algorithms
- Timing
- Asymptotic Notation
- Counting Steps
- Best, Worst, and Average Case
- Amortized Analysis
- Summary
- Vocabulary
- Problems
- Projects
Searching and Sorting
- Searching and Sorting
- Linear Search
- Binary Search
- Insertion Sort
- The Comparable Interface
- Sorting Linked Lists
- Summary
- Vocabulary
- Problems
- Projects
Recursion
- Recursion
- Thinking Recursively
- Analyzing Recursive Algorithms
- Merge Sort
- Quicksort
- Avoiding Recursion
- Summary
- Vocabulary
- Problems
- Projects
Part IV: Trees and Sets
Trees
Sets
- Sets
- The Set Interface
- Ordered Lists
- Binary Search Trees
- Hash Tables
- The Java Collections Framework Again
- Summary
- Vocabulary
- Problems
- Projects
Part V: Advanced Topics
Advanced Linear Structures
- Advanced Linear Structures
- Bit Vectors
- Sparse Arrays
- Contiguous Representation of Multidimensional Arrays
- Advanced Searching and Sorting
- Summary
- Vocabulary
- Problems
- Projects
Strings
Advanced Trees
- Advanced Trees
- Heaps
- Disjoint Set Clusters
- Digital Search Trees
- Red-Black Trees
- Summary
- Vocabulary
- Problems
- Projects
Graphs
- Graphs
- Terminology
- Representation
- Graph Traversal
- Topological Sorting
- Shortest Paths
- Minimum Spanning Trees
- Summary
- Vocabulary
- Problems
- Projects
Memory Management
Out to the Disk
- Out to the Disk
- Interacting with Files
- Compression
- External Sorting
- B-Trees
- Summary
- Vocabulary
- Problems
- Projects
Part VI: Appendices
A. Review of Java
- A. Review of Java
- A.1. The First Program
- A.2. Variables and Types
- A.3. Loops
- A.4. Interacting with the User
- A.5. Branching
- A.6. Methods and Breaking Out
- A.7. Constants
- A.8. Operators
- A.9. Debugging
- A.10. Coding Conventions
B. Unified Modeling Language
C. Summation Formulae
- C. Summation Formulae
- C.1. Sum Notation
- C.2. Sum of Constants
- C.3. Sum of First n Integers
- C.4. Sums of Halves and Doubles
- C.5. Upper Limit on Sum of a Function
- C.6. Constant Factors
D. Further Reading
Index
EAN: 2147483647
Pages: 216
