Message Digests, MACs, and HMACs
Overview
It is one thing to encrypt a message for transmission to another party; it is something different again to make sure it arrived unchanged.
This chapter looks at methods for authenticating messages and verifying that they have not been tampered with. You can do this by creating message digests and message authentication codes (MACs) using the MessageDigest class and the Mac class, respectively. You will also see that you can use message digests, also known as cryptographic hashes , as the basis for MAC creation by using Hash MACs (HMACs).
Finally, you will look at how digests can be used as the sources of pseudorandom data. You will also look at linking message digests with Java I/O streams and learn how to get a final value from the digest or take a snapshot of it.
By the end of this chapter you should
- Understand why message digests and MACs are used, as well as how to create them
- Understand what makes message digests and MACs different and where they can be applied
- Understand how digests are used as the basis of other functions for PBE and masking
- Be able to use the stream support available for message digests in Java
Finally, you should also have some understanding of the security issues associated with these two methods.

Getting Started
This chapter uses message digests and MACs in conjunction with encrypted messages. To simplify the examples, you need to take advantage of the following utility class, which has some helper methods in it that incorporate some of the facilities you read about in the last chapter. Type it in or download it from the book's Web site. Once you have it compiled, read on.
package chapter3; import java.security.NoSuchAlgorithmException; import java.security.NoSuchProviderException; import java.security.SecureRandom; import javax.crypto.KeyGenerator; import javax.crypto.SecretKey; import javax.crypto.spec.IvParameterSpec; /** * General utilities for the third chapter examples. */ public class Utils extends chapter2.Utils { /** * Create a key for use with AES. * * @param bitLength * @param random * @return a SecretKey of
requested
bitLength * @throws NoSuchAlgorithmException * @throws NoSuchProviderException */ public static SecretKey createKeyForAES(int bitLength, SecureRandom random) throws NoSuchAlgorithmException, NoSuchProviderException { KeyGenerator generator = KeyGenerator.getInstance("AES", "BC"); generator.init(256, random); return generator.generateKey(); } /** * Create an IV suitable for using with AES in CTR mode. *
* The IV will be composed of 4 bytes of message number, * 4 bytes of random data, and a counter of 8 bytes. * * @param messageNumber the number of the message. * @param random a source of randomness * @return an initialised IvParameterSpec */ public static IvParameterSpec createCtrIvForAES(int messageNumber, SecureRandom random) { byte[] ivBytes = new byte[16]; // initially randomize random.nextBytes(ivBytes); // set the message number bytes ivBytes[0] = (byte)(messageNumber ‰« 24); ivBytes[1] = (byte)(messageNumber ‰« 16); ivBytes[2] = (byte)(messageNumber ‰« 8); ivBytes[3] = (byte)(messageNumber ‰« 0); // set the counter bytes to 1 for (int i = 0; i != 7; i++) { ivBytes[8 + i] = 0; } ivBytes[15] = 1; return new IvParameterSpec(ivBytes); } /** * Convert a byte array of 8 bit characters into a String. * * @param bytes the array containing the characters * @param length the number of bytes to process * @return a String representation of bytes */ public static String toString(byte[] bytes, int length) { char[] chars = new char[length]; for (int i = 0; i != chars.length; i++) { chars[i] = (char)(bytes[i] & 0xff); } return new String(chars); } /** * Convert a byte array of 8 bit characters into a String. * * @param bytes the array containing the characters * @param length the number of bytes to process * @return a String representation of bytes */ public static String toString(byte[] bytes) { return toString(bytes, bytes.length); } /** * Convert the passed in String to a byte array by * taking the bottom 8 bits of each character it contains. * * @param string the string to be converted * @return a byte array representation */ public static byte[] toByteArray(String string) { byte[] bytes = new byte[string.length()]; char[] chars = string.toCharArray(); for (int i = 0; i != chars.length; i++) { bytes[i] = (byte)chars[i]; } return bytes; } }
One point about the helper class that's worth discussing: There are two functions in the helper class that might seem unnecessary, the toByteArray() and toString() methods. It is true that the String object in Java has a method called getBytes() and a constructor that takes a byte array that seems to do the same thing. If you look at the JavaDoc for String , you should notice that it mentions that string-tobyte conversion and byte-to-string conversion is affected by the default charset your JVM is using. Most JVMs ship using a default charset that causes String.getBytes() and the String byte constructor to behave like the methods detailed in the utility class. Not all do, though, and while you could have specified the charset explicitly, say, using String.getBytes( UTF8 ) , not all JVMs support all the charset names either. So, at least for these purposes, the most robust way of dealing with string-to-byte array conversion and back is to do it the long way.
| Important |
It is important to remember about the properties of charsets. Programmers often make the mistake of assuming that String.getBytes() will return 2 bytes a character and the String byte array constructors will create a String that has one character for each 2 bytes in the byte array. This is rarely, if ever, what happens, so attempting to pass encrypted messages around by simply creating String objects and converting back to byte arrays using String.getBytes() will normally result in corrupted data. |
The Problem of Tampering
So you are happily encrypting messages using a symmetric cipher, and chances are, anyone trying to interfere with your messages will have probably given up trying to guess the secret keys that have been used. At this point a potential attacker will start to explore the next avenue, which is tampering with the ciphertext and trying to fool the receiver.
Try It Out: Tampering with an Encrypted Stream
Look at the following example. Unlike previous examples, it is divided into three steps: the encryption step, a tampering step, and the decryption step. In the following case, it is assumed the attacker has some knowledge of the message format, and that you are using a streaming mode, which makes the XOR-based tampering easier to do.
package chapter3; import java.security.Key; import java.security.SecureRandom; import javax.crypto.Cipher; import javax.crypto.spec.IvParameterSpec; /** * Tampered message, plain encryption, AES in CTR mode */ public class TamperedExample { public static void main(String[] args) throws Exception { SecureRandom random = new SecureRandom(); IvParameterSpec ivSpec = Utils.createCtrIvForAES(1, random); Key key = Utils.createKeyForAES(256, random); Cipher cipher = Cipher.getInstance("AES/CTR/NoPadding", "BC"); String input = "Transfer 0000100 to AC 1234-5678"; System.out.println("input : " + input); // encryption step cipher.init(Cipher.ENCRYPT_MODE, key, ivSpec); byte[] cipherText = cipher.doFinal(Utils.toByteArray(input)); // tampering step cipherText[9] ^= '0' ^ '9'; // decryption step cipher.init(Cipher.DECRYPT_MODE, key, ivSpec); byte[] plainText = cipher.doFinal(cipherText); System.out.println("plain : " + Utils.toString(plainText)); } }
When you run the example, you should see the following output:
input : Transfer 0000100 to AC 1234-5678 plain : Transfer 9000100 to AC 1234-5678
How It Works
The cipher mode you are using is based not only on the use of the cipher but on encrypting the data by XORing the data with the output of the cipher. This allows you to reset some bits in the ciphertext knowing that the same bits will be changed in the plaintext when the ciphertext is decrypted.
Admittedly, the example is somewhat contrived, but it is designed to make the following point loudly: Given that an attacker has some knowledge of the structure of the message it is possible for the hacker to get up to all sorts of mischief. In this case, assuming the request represents an instruction for payment to the attacker's account, you can see that the amount in the decrypted message is considerably larger than the amount in the original message. Not so good!
This does not mean that you should avoid either streaming modes or stream ciphers like the plague. Using a different mode would increase the difficulty level of this style of attack, but even then, in less contrived situations the problem remains that you need to provide the receiver of the message with some way of verifying that the decrypted plaintext the receiver has generated is what you sent. To do this, you need some way of providing the receiver with a verification code that will allow the receiver to determine if the message has been tampered with. The basis of these codes is symmetric ciphers and message digests .
Let's look at message digests first.
Message Digests
Message digests compute a cryptographic hash, or secure checksum, for a particular message. They are of interest because of two properties that they have. Depending on the message size and the type of digest being used, the chances of generating the same message are extremely small. Second, changing a bit in an input message for which a digest has been computed will lead to an unpredictable change in the bits making up the new digest if the calculation is done again. This property of uniqueness and the lack of predictability make message digests a very useful part of any cryptographic toolbox.
Naturally, this also means that, like ciphers, message digest algorithms can come under a variety of attacks. In terms of what a successful attack constitutes , people trying to break digest algorithms look for two things: (1) the ease with which digests can be made to produce collisions ”the same result for different inputs ”with any data and (2) easy ways to produce collisions with minor changes to the input data. When this can be done, the digest algorithm has become little better, if at all, than a CRC.
I mention this specifically because, as this book was being written, some new weaknesses have been discovered in the very widely used algorithm SHA-1. Although they are not cause for immediate alarm, they do indicate that it is time to start migrating to some of the newer algorithms, and that researchers are becoming better at analyzing and attacking these algorithms. In the past, message digests have not been studied as well as ciphers, and this is changing, so you can probably expect some changes in the future.
Anyway, you will notice that SHA-1 is quite widely used in this book, as well as some of the newer algorithms, such as SHA-256. SHA-1 is used either because the algorithm being used requires it or because there are few implementations that support the use of other digests in that context. The principles are still the same, regardless of the digest being used, so the lessons can still be learned. Nonetheless, if you are planning on implementing a newer application, you should look at using the newer algorithms such as SHA-256 and SHA-512 where possible.
Try It Out: Using a Message Digest
The following example makes use of a message digest, in this case the NIST function SHA-1 described in FIPS PUB 180-1, in order to allow you to detect the tampering that was performed on the ciphertext when the decrypted, plaintext message is created. Note that the main change is simply the addition of the computed digest to the message payload before encryption and then the addition of a verification step when the message payload has been decrypted.
package chapter3;
import java.security.Key;
import java.security.MessageDigest;
import java.security.SecureRandom;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
/**
* Tampered message, encryption with digest, AES in CTR mode
*/
public class TamperedWithDigestExample
{
public static void main(String[] args) throws Exception
{
SecureRandom random = new SecureRandom();
IvParameterSpec ivSpec = Utils.createCtrIvForAES(1, random);
Key key = Utils.createKeyForAES(256, random);
Cipher cipher = Cipher.getInstance("AES/CTR/NoPadding", "BC");
String input = "Transfer 0000100 to AC 1234-5678";
MessageDigest hash = MessageDigest.getInstance("SHA-1", "BC");
System.out.println("input : " + input);
// encryption step
cipher.init(Cipher.ENCRYPT_MODE, key, ivSpec);
byte[] cipherText = new byte[cipher.getOutputSize(
input.length() + hash.getDigestLength())];
int ctLength = cipher.update(Utils.toByteArray(input), 0, input.length(),
cipherText, 0);
hash.update(Utils.toByteArray(input));
ctLength += cipher.doFinal(hash.digest(), 0, hash.getDigestLength(),
cipherText, ctLength);
// tampering step
cipherText[9] ^= '0' ^ '9';
// decryption step
cipher.init(Cipher.DECRYPT_MODE, key, ivSpec);
byte[] plainText = cipher.doFinal(cipherText, 0, ctLength);
int messageLength = plainText.length - hash.getDigestLength();
hash.update(plainText, 0, messageLength);
byte[] messageHash = new byte[hash.getDigestLength()];
System.arraycopy(plainText, messageLength, messageHash,
0, messageHash.length);
System.out.println("plain : " + Utils.toString(plainText, messageLength)
+ " verified: " + MessageDigest.isEqual(hash.digest(), messageHash));
}
}
Running the previous program, you should see the following output.
input : Transfer 0000100 to AC 1234-5678 plain : Transfer 9000100 to AC 1234-5678 verified: false
This time, you can see there is something wrong with the decrypted ciphertext.
How It Works
The process used here is outlined in Figure 3-1. This time around, the message digest calculates a cryptographic hash of the plaintext as it should be. The hash is then appended to the message before encryption as an extra level of protection. On decryption, the hash is recomputed from the resulting plaintext. Because the plaintext has decrypted to a different value from before, the hash computation leads to a different value. The value does not match the expected one appended to the message, and you can therefore tell that tampering has occurred.
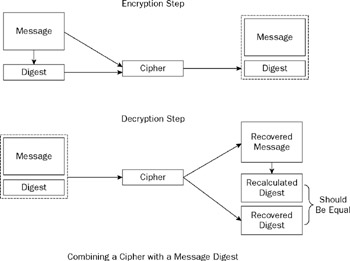
Figure 3-1
Although the fact that you can now tell that tampering is taking place is an improvement, you will see soon that you are not quite there yet. That being said, it would be worth pausing briefly to take a look at the new class that was introduced.
The MessageDigest Class
The java.security.MessageDigest class provides a general object to represent a variety of message digests. Like the KeyGenerator class, it uses the getInstance() factory pattern, and MessageDigest.getInstance() behaves exactly as other getInstance() methods in the JCA in the manner in which it follows precedence rules and finds algorithm implementations.
MessageDigest.update()
The update() method is used to feed data into the digest. There is no return value because the input data is just progressively mixed in to the digest function.
How much data you can feed safely into a hash function varies with the function you are using, and as a general rule the number of bits of security you get with a given digest function increases with the digest size. SHA-1, for example, produces a 160-bit digest, will handle 2 64 bits and, in the light of recent results, is believed to offer 69 bits of security. SHA-512 (detailed in FIPS PUB 180-2), on the other hand, produces a 512-bit digest, will handle messages up to 2 128 bits, and offers 256 bits of security.
MessageDigest.digest()
This closes off the progressive calculation and returns the final digest value. There are a couple of ways of using the digest() method: It will either return the byte array or will write the digest to a byte array that has the space required for the digest available. The space required for a digest is given by MessageDigest.getDigestSize() .
MessageDigest.isEqual()
This is a static helper method that compares the two byte arrays passed to it and returns true if they are equal, false otherwise . These days, you would probably just use java.util.Arrays.equals() , but in this case, because you are trying to keep this flexible with regard to which JDK you are using, you should stick with MessageDigest.isEqual() .
Tampering with the Digest
Previously, you assumed that the attacker was familiar with only part of the message. The attacker knew where the digits were and replaced the leading 0 with a 9, thus substantially changing the quantity the message was talking about. The example responded by introducing a message digest, which allowed you to spot the change. Now it is the attacker's turn to respond to you.
Still in a streaming mode, imagine the attacker is familiar with the entire contents of the message but cannot determine the key. This means the attacker cannot decrypt the message, but in this case knowing the contents of the message and the format of it means that the attacker does not have to.
Try It Out: Tampering with a Digest in an Encrypted Stream
Look at the following example; it is almost identical to the example that introduced the use of the message digest. The major differences are that not only are the message contents being altered, but the message digest tacked on to the end of the message is altered as well.
package chapter3;
import java.security.Key;
import java.security.MessageDigest;
import java.security.SecureRandom;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
/**
* Tampered message, encryption with digest, AES in CTR mode
*/
public class TamperedDigestExample
{
public static void main(
String[] args)
throws Exception
{
SecureRandom random = new SecureRandom();
IvParameterSpec ivSpec = Utils.createCtrIvForAES(1, random);
Key key = Utils.createKeyForAES(256, random);
Cipher cipher = Cipher.getInstance("AES/CTR/NoPadding", "BC");
String input = "Transfer 0000100 to AC 1234-5678";
MessageDigest hash = MessageDigest.getInstance("SHA-1", "BC");
System.out.println("input : " + input);
// encryption step
cipher.init(Cipher.ENCRYPT_MODE, key, ivSpec);
byte[] cipherText = new byte[cipher.getOutputSize(
input.length() + hash.getDigestLength())];
int ctLength = cipher.update(Utils.toByteArray(input), 0, input.length(),
cipherText, 0);
hash.update(Utils.toByteArray(input));
ctLength += cipher.doFinal(hash.digest(), 0, hash.getDigestLength(),
cipherText, ctLength);
// tampering step
cipherText[9] ^= '0' ^ '9';
// replace digest
byte[] originalHash = hash.digest(Utils.toByteArray(input));
byte[] tamperedHash = hash.digest(
Utils.toByteArray("Transfer 9000100 to AC 1234-5678"));
for (int i = ctLength - hash.getDigestLength(), j = 0;
i != ctLength; i++, j++)
{
cipherText[i] ^= originalHash[j] ^ tamperedHash[j];
}
// decryption step
cipher.init(Cipher.DECRYPT_MODE, key, ivSpec);
byte[] plainText = cipher.doFinal(cipherText, 0, ctLength);
int messageLength = plainText.length - hash.getDigestLength();
hash.update(plainText, 0, messageLength);
byte[] messageHash = new byte[hash.getDigestLength()];
System.arraycopy(plainText, messageLength, messageHash,
0, messageHash.length);
System.out.println("plain : " + Utils.toString(plainText, messageLength)
+ " verified: " + MessageDigest.isEqual(hash.digest(), messageHash));
}
}
Try running the example; you should see the following output:
input : Transfer 0000100 to AC 1234-5678 plain : Transfer 9000100 to AC 1234-5678 verified: true
Unfortunately, the verified: true that appears at the end of the second line indicates that, using the current verification regime , your receiver could be fooled into thinking that what they decrypted is the message you sent.
How It Works
As with the previous Try It Out ("Tampering with an Encrypted Stream"), you have taken advantage of the fact the cipher is using XOR. This time around, the attacker has had to show more knowledge about the internals of the message structure so that they could compute the expected hash. This has allowed the attacker to zero out the one that was inserted originally and replace it with a new one, making the tampered stream appear as though it is internally consistent.
Note that the way the message digest is being altered demonstrates a big difference between a cryptographic hash and a normal checksum like CRC-32. The attacker has to be able to compute the full digest that the message already contains in addition to computing what the new digest value is meant to be. The reason is that, unlike CRC-32, the attacker cannot predict how a bit change in the message will affect the digest. This is a useful property that you are not taking full advantage of yet, but soon will.
However, there is still a problem, and although you would be forgiven for thinking otherwise , the problem is not with the choice of cipher and mode, but is more to do with how the digest function is being used.
MACs Based on Digests the HMAC
The next example introduces the Mac class. In the following case, Mac.getInstance() is being used to produce a HMAC (a hash MAC), a message authentication code based on a cryptographic message digest, as detailed in RFC 2104. What makes a HMAC different from a regular message digest calculation is that it incorporates a secret key as well as some "under the hood" data into the calculation of the final hash. This reduces the problem of changing the HMAC used in the message to the problem of guessing the HMAC key as well as knowing the message contents.
Try It Out: Using a HMAC
Look at the example; you will see that the substitution of MessageDigest with a Mac is relatively straightforward.
package chapter3;
import java.security.Key;
import java.security.MessageDigest;
import java.security.SecureRandom;
import javax.crypto.Cipher;
import javax.crypto.Mac;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
/**
* Tampered message with HMac, encryption with AES in CTR mode
*/
public class TamperedWithHMacExample
{
public static void main(String[] args) throws Exception
{
SecureRandom random = new SecureRandom();
IvParameterSpec ivSpec = Utils.createCtrIvForAES(1, random);
Key key = Utils.createKeyForAES(256, random);
Cipher cipher = Cipher.getInstance("AES/CTR/NoPadding", "BC");
String input = "Transfer 0000100 to AC 1234-5678";
Mac hMac = Mac.getInstance("HmacSHA1", "BC");
Key hMacKey = new SecretKeySpec(key.getEncoded(), "HmacSHA1");
System.out.println("input : " + input);
// encryption step
cipher.init(Cipher.ENCRYPT_MODE, key, ivSpec);
byte[] cipherText = new byte[cipher.getOutputSize(
input.length() + hMac.getMacLength())];
int ctLength = cipher.update(Utils.toByteArray(input), 0, input.length(),
cipherText, 0);
hMac.init(hMacKey);
hMac.update(Utils.toByteArray(input));
ctLength += cipher.doFinal(hMac.doFinal(), 0, hMac.getMacLength(),
cipherText, ctLength);
// tampering step
cipherText[9] ^= '0' ^ '9';
// replace digest
// ?
// decryption step
cipher.init(Cipher.DECRYPT_MODE, key, ivSpec);
byte[] plainText = cipher.doFinal(cipherText, 0, ctLength);
int messageLength = plainText.length - hMac.getMacLength();
hMac.init(hMacKey);
hMac.update(plainText, 0, messageLength);
byte[] messageHash = new byte[hMac.getMacLength()];
System.arraycopy(plainText, messageLength, messageHash,
0, messageHash.length);
System.out.println("plain : " + Utils.toString(plainText, messageLength)
+ " verified: " + MessageDigest.isEqual(hMac.doFinal(), messageHash));
}
}
Running this example yields the following output:
input : Transfer 0000100 to AC 1234-5678 plain : Transfer 9000100 to AC 1234-5678 verified: false
Apart from the fact that you are picking up the tampering again, you will also notice in the example that the step replacing the digest has been removed.
How It Works
By looking at Figure 3-2, you can see how the process you are now using is different from that used with a straight message digest. The reason the tampering is now "fool-proof" is the underlying assumption that the attacker does not know the secret key. Because the secret key is also being used for the HMAC, the attacker has no way of performing the replacement. The attacker can neither calculate the expected value after the change nor calculate the HMAC value that was in the original message; hence, the ? in the code ”there isn't any code that can fill the spot. After all, if the attacker did know the secret key, it would be unnecessary to even bother with trying to tamper with the encrypted stream.
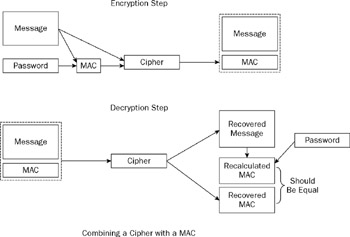
Figure 3-2
Another thing you will notice in the example is that the key being used for the HMAC is the same as the one being used for encryption. For the purposes of this example this is okay; it reduces the amount of code. In general you should avoid doing this. By having a different key for the HMAC object, you are at least safe in the knowledge that if an attacker does succeed in recovering the encryption key for the message, the attacker still has to recover another key before they can try to produce a message that your receiver will regard as authentic .
There are other ways of gaining this effect as well. You might also include a random IV in-line with the message data and create the effect of a HMAC by just using a digest. As long as the IV is secured along with the message content, an attacker will still be at a loss when it comes to trying to fiddle the digest. Of course, if the message is for long- term use, as soon as the message encryption key is compromised, a fake message can be generated. However, there are plenty of situations where messages might be generated and then thrown away after a single use where this method of keying the digest would be appropriate.
As for the Mac class introduced in the example, as you will see, it is basically like a MessageDigest but with an init() method.
The Mac Class
The javax.crypto.Mac class provides a general object to represent a variety of MAC algorithms. Like the MessageDigest class, it uses the getInstance() factory pattern, and Mac.getInstance() behaves exactly as other getInstance() methods in the JCE and JCA in the manner in which it follows precedence rules and finds algorithm implementations .
The JCA specifies a naming convention for HMAC objects: Hmac Digest . It also specifies a naming convention for MACs based on password-based encryption (PBE), which is PBEwith Mac , where Mac is the full name of the MAC being used. For example, a HMAC based on SHA-256 being used with PBE would be created using the following:
Mac hMac = Mac.getInstance("PBEwithHmacSHA256");
Mac.init()
The init() method has two versions, one that just takes a key, which was used previously, and another that takes a key and an AlgorithmParameterSpec object.
In the case of a HMAC, the key should be at least the length of the MAC being produced. With MACs based on symmetric ciphers, which you will look at next, the key can be a suitable key for the cipher that the MAC algorithm is based on.
The second init() method is used because some MAC algorithms, like a cipher, can take parameters that affect the MAC calculation. MACs based on CBC mode ciphers can take initialization vectors to help hide key reuse with the same message, such as
mac.init(macKey, new IvParameterSpec(ivBytes));
You will take a closer look at MACs based on symmetric ciphers in the next section.
Mac.update()
As with the MessageDigest class, the update() method is used to feed data into the MAC. Again, depending on the size of the final MAC that is produced, you need to be careful that you are not expecting the particular MAC algorithm to deal with too much data. Feeding too much data into a Mac.update() will reduce the overall security you get from the MAC produced when you call Mac.doFinal() .
Mac.doFinal()
Mac.doFinal() simply produces the final MAC that is the result of the call to Mac.init() and Mac.update() and then resets the Mac object back to the state it was in when the last Mac.init() was called. You can treat it the same way as MessageDigest.digest() .
MACs Based on Symmetric Ciphers
Another, older method for calculating MACs is to use a symmetric cipher. NIST is in the process of reissuing standards for these in SP 800-38b, but algorithms for MAC calculation using DES were first published in FIPS PUB 81.
Try It Out: Using a Cipher-Based MAC
The following example shows you how to use DES in a MAC mode, via the Mac object.
package chapter3;
import java.security.Key;
import java.security.MessageDigest;
import java.security.SecureRandom;
import javax.crypto.Cipher;
import javax.crypto.Mac;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
/**
* Message without tampering with MAC (DES), encryption AES in CTR mode
*/
public class CipherMacExample
{
public static void main(String[] args) throws Exception
{
SecureRandom random = new SecureRandom();
IvParameterSpec ivSpec = Utils.createCtrIvForAES(1, random);
Key key = Utils.createKeyForAES(256, random);
Cipher cipher = Cipher.getInstance("AES/CTR/NoPadding", "BC");
String input = "Transfer 0000100 to AC 1234-5678";
Mac mac = Mac.getInstance("DES", "BC");
byte[] macKeyBytes = new byte[] {
0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08 };
Key macKey = new SecretKeySpec(macKeyBytes, "DES");
System.out.println("input : " + input);
// encryption step
cipher.init(Cipher.ENCRYPT_MODE, key, ivSpec);
byte[] cipherText = new byte[cipher.getOutputSize(
input.length() + mac.getMacLength())];
int ctLength = cipher.update(Utils.toByteArray(input), 0, input.length(),
cipherText, 0);
mac.init(macKey);
mac.update(Utils.toByteArray(input));
ctLength += cipher.doFinal(mac.doFinal(), 0, mac.getMacLength(),
cipherText, ctLength);
// decryption step
cipher.init(Cipher.DECRYPT_MODE, key, ivSpec);
byte[] plainText = cipher.doFinal(cipherText, 0, ctLength);
int messageLength = plainText.length - mac.getMacLength();
mac.init(macKey);
mac.update(plainText, 0, messageLength);
byte[] messageHash = new byte[mac.getMacLength()];
System.arraycopy(plainText, messageLength, messageHash,
0, messageHash.length);
System.out.println("plain : " + Utils.toString(plainText, messageLength)
+ " verified: " + MessageDigest.isEqual(mac.doFinal(), messageHash));
}
}
In this case, because there is no tampering, running the example demonstrates that the message will verify correctly, so you should see the following output:
input : Transfer 0000100 to AC 1234-5678 plain : Transfer 0000100 to AC 1234-5678 verified: true
How It Works
MACs based on ciphers do essentially the same job as MACs based on cryptographic hashes, so the principle that applies here is the same as before ”a secret key is required to compute the MAC correctly and if you do not know the secret key, you can't compute the MAC again.
There are a variety of reasons why you might want to use a MAC based on a symmetric cipher, rather than using one based on a cryptographic hash. You, or perhaps the recipient of your messages, may have access to only one algorithm, the one used for encryption. A hash-based MAC might simply be too big. On the other hand, hash-based MACs, because they are larger, are less likely to have clashes for a given size of message. A MAC that is too small might turn out to be useless, as a variety of easy-to-generate messages might compute to the same MAC value, resulting in a collision. If there are enough of these collisions present, the usefulness of the MAC is reduced because being able to confirm a MAC tells you at best that the message is one of a set of possible messages, rather than, as you hope, the specific message that was sent.
It is really one of those situations where it depends on which issues are important and what the risks might be. Having said that, the general rule is that a bigger MAC value is a more secure one.
Digests in Pseudorandom Functions
You actually saw one example of the use of a digest as a source function for a pseudorandom function in Chapter 2, when you were reading about password-based encryption. In that case, the digest was used to mix the bits of the password and the salt together using some more general function and produce a string of bytes suitable for using as a key.
As you will see, digests can be used as the source functions for mask functions as well. The purpose of a mask function is to produce a pseudorandom byte (or octet if you want to be explicit) array that can then be XORed with the data you want to mask. The reason for masking is to prevent any patterns that might exist in the masked data from being visible.
You will look at some examples of PBE key generation functions and mask generation functions here so you can get a more general idea of how these are constructed , but the main thing to remember is that the functions take advantage of the fact that the changes in the output of an ideal digest function cannot be predicted by knowing any of the changes in its input.
PBE Key Generation
Two of the PKCS documents deal with password-based encryption. The first one is PKCS #5, which provides two schemes; the second is PKCS #12, which provides the basis for the scheme the PBE example was using in Chapter 2. All of them are based on the use of message digests. If you look at all three schemes, you will realize that they follow something of an evolutionary trail, and the best place to start is the beginning. Therefore, for the purposes of this book, I will just cover PKCS #5 Scheme 1, because it captures the basics of using a password, salt, and iteration count.
Try It Out: Implementing PKCS #5 Scheme 1
If you recall the discussion in Chapter 2 on the components of the PBEKeySpec and the PBEParameterSpec , the password is fed into a function that's based on a message digest and then mixed in some fashion together with the salt and the iteration count.
PKCS #5 Scheme 1 is such a function and provides a simple method for generation of keys up to 160 bits. Although it has been superseded by PKCS #5 Scheme 2 and the method detailed in PKCS #12, it is a good example of how a PBE key generation function can be put together. The algorithm used is simply
Hash( password salt ) iterationCount
where Hash() is the message digest, password is an ASCII string that has been converted into a byte array, salt is a array of random bytes, and iterationCount is the iteration count value. The resulting array of bytes is referred to as the derived key and is then used for creating the encryption key and other things, such as an IV, if required.
It is fairly easy to express this in code, as you can see in the following sample implementation.
package chapter3; import java.security.MessageDigest; /** * A basic implementation of PKCS #5 Scheme 1. */ public class PKCS5Scheme1 { private MessageDigest digest; public PKCS5Scheme1( MessageDigest digest) { this.digest = digest; } public byte[] generateDerivedKey( char[] password, byte[] salt, int iterationCount) { for (int i = 0; i != password.length; i++) { digest.update((byte)password[i]); } digest.update(salt); byte[] digestBytes = digest.digest(); for (int i = 1; i < iterationCount; i++) { digest.update(digestBytes); digestBytes = digest.digest(); } return digestBytes; } }
Having come up with a sample implementation, let's confirm that it works. You can do this by testing your implementation against the one used under the covers in the provider. You just need a PBE algorithm that uses PKCS #5 Scheme 1. One of these is PBEWithSHA1AndDES, which produces a key based on PKCS #5 Scheme 1 and then uses DES in CBC mode with PKCS #5 padding for doing the encryption.
Try running the following test for the PKCS5Scheme1 class; it uses PBEWithSHA1AndDES to do the encryption and then uses the new home-grown implementation with DES in CBC mode to do the decryption.
package chapter3; import java.security.MessageDigest; import javax.crypto.*; import javax.crypto.spec.*; /** * Basic test of the PKCS #5 Scheme 1 implementation. */ public class PKCS5Scheme1Test { public static void main( String[] args) throws Exception { char[] password = "hello".toCharArray(); byte[] salt = new byte[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 }; byte[] input = new byte[] { 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f }; int iterationCount = 100; System.out.println("input : " + Utils.toHex(input)); // encryption step using regular PBE Cipher cipher = Cipher.getInstance("PBEWithSHA1AndDES","BC"); SecretKeyFactory fact = SecretKeyFactory.getInstance( "PBEWithSHA1AndDES", "BC"); PBEKeySpec pbeKeySpec = new PBEKeySpec( password, salt, iterationCount); cipher.init(Cipher.ENCRYPT_MODE, fact.generateSecret(pbeKeySpec)); byte[] enc = cipher.doFinal(input); System.out.println("encrypt: " + Utils.toHex(enc)); // decryption step - using the local implementation cipher = Cipher.getInstance("DES/CBC/PKCS5Padding"); PKCS5Scheme1 pkcs5s1 = new PKCS5Scheme1( MessageDigest.getInstance("SHA-1", "BC")); byte[] derivedKey = pkcs5s1.generateDerivedKey( password, salt, iterationCount); cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(derivedKey, 0, 8, "DES"), new IvParameterSpec(derivedKey, 8, 8)); byte[] dec = cipher.doFinal(enc); System.out.println("decrypt: " + Utils.toHex(dec)); } }
Running the test class should produce the following output:
input : 0a0b0c0d0e0f encrypt: af1c264c0946104d decrypt: 0a0b0c0d0e0f
If you see this result, it means the home-grown implementation is producing the correct derived key, which allows you to initialize the decryption cipher correctly.
How It Works
The trick here is to know not only the means by which the PBE key is being generated but also which mode and padding is associated with the algorithm as well. The PKCS5Scheme1 class provides you with a correct implementation of the mixing function that uses the password, salt, and iteration count to produce a PBE key. By combining that with the correctly configured DES cipher, you are able to decrypt the output of the PBE cipher created with the provider.
Note that because the example uses DES in CBC mode, you also needed an IV and derivedKey is used as the source of this as well. Therefore, the example uses 16 of the 20 bytes generated: the first 8 for the DES key and the next 8 for the IV.
Mask Generation
As well as being used as a source function for key and IV generation in password-based encryption, message digests can also be used to generate pseudorandom streams of bytes to mask data that needs to be obfuscated . One such mask function can be found in PKCS #1 V2.1. The function name is MGF1.
The function is an interesting one to consider, because it is also very simple. The algorithm is simply, given T , which is initially an empty byte array; seed , which is a byte array containing a seed for the function; and the length of the message digest you are using as hLen , you can generate a mask in a byte array of maskLength length as follows :
- For counter from to Ceiling ( maskLength/hLen ) ˆ’ 1 , do T = T – Hash ( seed – ItoOSP ( counter )).
- Output the leading maskLen octets of T as the octet string mask .
The Ceiling() function is defined as Ceiling ( x/y ) and will return the smallest integer larger than or equal to the real number resulting from dividing x by y.Hash() is the function performed by the message digest you are using, and ItoOSP() is a function that converts an integer into a byte array, high byte first.
Try It Out: Implementing MGF1
Here is a sample implementation with a simple main() that generates a 20-byte mask. Try running it!
package chapter3; import java.security.MessageDigest; /** * mask generator function, as described in PKCS1v2. */ public class MGF1 { private MessageDigest digest; /** * Create a version of MGF1 for the given digest. * * @param digest digest to use as the basis of the function. */ public MGF1( MessageDigest digest) { this.digest = digest; } /** * int to octet string. */ private void ItoOSP( int i, byte[] sp) { sp[0] = (byte)(i >>> 24); sp[1] = (byte)(i >>> 16); sp[2] = (byte)(i >>> 8); sp[3] = (byte)(i >>> 0); } /** * Generate the mask. * * @param seed source of input bytes for initial digest state * @param length length of mask to generate * * @return a byte array containing a MGF1 generated mask */ public byte[] generateMask( byte[] seed, int length) { byte[] mask = new byte[length]; byte[] C = new byte[4]; int counter = 0; int hLen = digest.getDigestLength(); while (counter < (length / hLen)) { ItoOSP(counter, C); digest.update(seed); digest.update(C); System.arraycopy(digest.digest(), 0, mask, counter * hLen, hLen); counter++; } if ((counter * hLen) < length) { ItoOSP(counter, C); digest.update(seed); digest.update(C); System.arraycopy(digest.digest(), 0, mask, counter * hLen, mask.length - (counter * hLen)); } return mask; } public static void main(String[] args) throws Exception { MGF1 mgf1 = new MGF1(MessageDigest.getInstance("SHA-1", "BC")); byte[] source = new byte[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; System.out.println(Utils.toHex(mgf1.generateMask(source, 20))); } }
Running the class should produce the following 20 bytes of output:
e0a63d7c8c4d81cd1c0567bfab6c22ed2022977f
How It Works
The mask function can generate a stream of bytes suitable for obfuscation and masking of data from the seed, counter, and the message digest because of the property that an ideal message digest is supposed to have ”namely, changes in the input to one lead to unpredictable changes to the output. The chances of different inputs leading to the same output is extremely small, providing the amount of data is not in excess of what the digest can handle. What constitutes too much data varies for a given digest, but if you look at PKCS #1 V2.1, you will see that MGF1 is restricted to generating masks of no more than 2 32 bytes in size , as the digest it was initially designed for is SHA-1.
MGF1 is an interesting function to investigate; try a few different values and think about how it could be used. It is an interesting aspect of cryptography that you will often see similar techniques showing up in a variety of places, and in some respects, the process going on in MGF1 is very similar to the one you saw in CTR mode in Chapter 2. In Chapter 4, you will see MGF1 used with both techniques for RSA encryption and the generation of some types of RSA signatures.
There is still one aspect of use that I need to cover with message digests: Just as Java has I/O stream classes based on the Cipher class, there are also Java I/O stream classes based on MessageDigest .
Doing Digest Based I O
The JCA contains two classes for doing I/O involving message digests: java.security.DigestInputStream and java.security.DigestOutputStream . As with the cipher stream classes, you can use them anywhere you would use an InputStream or an OutputStream .
These stream classes are also a case where the usual factory pattern seen elsewhere in the JCA is not used. Instances of both DigestInputStream and DigestOutputStream are created using constructors, which take an InputStream , or OutputStream , to wrap, and a MessageDigest object to do the processing.
Look at the following example, which uses DigestInputStream and DigestOutputStream :
package chapter3;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.security.DigestInputStream;
import java.security.DigestOutputStream;
import java.security.MessageDigest;
/**
* Basic IO example using SHA1
*/
public class DigestIOExample
{
public static void main(
String[] args)
throws Exception
{
byte[] input = new byte[] {
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07,
0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f,
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06 };;
MessageDigest hash = MessageDigest.getInstance("SHA1");
System.out.println("input : " + Utils.toHex(input));
// input pass
ByteArrayInputStream bIn = new ByteArrayInputStream(input);
DigestInputStream dIn = new DigestInputStream(bIn, hash);
ByteArrayOutputStream bOut = new ByteArrayOutputStream();
int ch;
while ((ch = dIn.read()) >= 0)
{
bOut.write(ch);
}
byte[] newInput = bOut.toByteArray();
System.out.println("in digest : "
+ Utils.toHex(dIn.getMessageDigest().digest()));
// output pass
bOut = new ByteArrayOutputStream();
DigestOutputStream dOut = new DigestOutputStream(bOut, hash);
dOut.write(newInput);
dOut.close();
System.out.println("out digest: "
+ Utils.toHex(dOut.getMessageDigest().digest()));
}
}
Running the example, you should find that the digest produced on reading the input is the same as that produced on writing the reconstructed input. As a SHA-1 calculation on the same input should always lead to the same result, you should see the following output:
input : 000102030405060708090a0b0c0d0e0f00010203040506 in digest : 864ea9ee65d6f86847ba302ded2da77ad6c64722 out digest: 864ea9ee65d6f86847ba302ded2da77ad6c64722
One difference between the digest stream classes and the cipher stream classes is that, unlike a cipher, you can retrieve the state of the digest at any time via the getMessageDigest() method. Of course, if you do it in the manner used in the example, you will reset the message digest as a result of calling MessageDigest.digest().MessageDigest objects are also cloneable, so if you wanted to take a sample of the current digest, but allow the digest to continue accumulating changes in the input, you could have instead written:
System.out.println("out digest: "
+ Utils.toHex(((MessageDigest)dOut.getMessageDigest().clone()).digest()));
This way, the MessageDigest object associated with the stream would not have been reset, allowing further writes to the stream to be accumulated on top of all the writes previously done, rather than having the digest start calculating from scratch.
Summary
In this chapter, you looked at methods for calculating cryptographic hashes, or message digests, on data using the MessageDigest class for the purpose of being able to tell if the data has been tampered with. You have also seen how secret keys can be incorporated into integrity testing using the Mac class.
Over the course of the chapter, you learned the following:
- Message digests are useful because it is not possible to predict the changes that will occur in the value of a calculated digest from the changes in the input to the digest calculation.
- In situations where a message digest is not enough, it is necessary to use a MAC, as it incorporates a secret key as well as the input data you are trying to protect.
- MACs can be based on symmetric ciphers or message digests.
- Digests can be used for PBE key generation and as a source of pseudorandom data.
- How to use the support for in- lining message digest calculation using the JCA classes that allow the mixing of message digests with input streams and output streams.
The shortcomings of the techniques you have looked at here are that, as with messages encrypted using symmetric key cryptography, MAC protection is meaningful only when the receiver of the message the MAC is for has access to the secret key. The question then becomes how you send the receiver the secret key, or is there another way of authenticating a message that does not require sending a secret key. You will find the answers to this in the next chapter, when you look at asymmetric key cryptography.
Exercises
|
1. |
Why are message digests and MACs a necessary part of sending a message using encryption? |
|
|
2. |
You have been asked to implement a protocol that does not require encryption of the messages used in it, but it does require that the messages be tamperproof. How can you solve this problem while still allowing messages to be sent without encryption? What extra piece of information is now required when two parties want to communicate? |
|
|
3. |
What is the primary limitation of the use of a MAC or message digest? |
|
|
4. |
What is wrong with the following code? cipher.init(Cipher.ENCRYPT_MODE, key); String encrypted = new String(cipher.doFinal(input)); cipher.init(Cipher.DECRYPT_MODE, key); byte[] decrypted = cipher.doFinal(encrypted.getBytes()); |
|
Answers
|
1. |
Why are message digests and MACs a necessary part of sending a message using encryption? Encryption does not necessarily prevent an attacker from tampering with a message. |
|
2. |
You have been asked to implement a protocol that does not require encryption of the messages used in it, but it does require that the messages be tamperproof. How can you solve this problem while still allowing messages to be sent without encryption? What extra piece of information is now required when two parties want to communicate? Use a MAC based on either a message digest or a cipher, whichever is mos convenient while being appropriate to the security needs of the data. The use of a MAC now means that two parties who want to communicate must be aware of the key material used to initialize the MAC. |
|
3. |
What is the primary limitation of the use of a MAC or message digest? The primary limitation of a MAC or message digest is the amount of data that it is safe to feed into it. The data limitation exists because, beyond a certain size , the likelihood of different data computing to the same digest or MAC value becomes too high. |
|
4. |
What is wrong with the following code? cipher.init(Cipher.ENCRYPT_MODE, key); String encrypted = new String(cipher.doFinal(input)); cipher.init(Cipher.DECRYPT_MODE, key); byte[] decrypted = cipher.doFinal(encrypted.getBytes()); What kind of String is created from new String(cipher.doFinal(input)) and what bytes are returned by encrypted.getBytes() is dependent on the default charset used by your Java runtime and will almost always mean that encrypted.getBytes() will not produce the same byte array that came out of cipher.doFinal(input) . |
Introduction
- The JCA and the JCE
- Symmetric Key Cryptography
- Message Digests, MACs, and HMACs
- Asymmetric Key Cryptography
- Object Description in Cryptography Using ASN.1
- Distinguished Names and Certificates
- Certificate Revocation and Path Validation
- Key and Certificate Management Using Keystores
- CMS and S/MIME
- SSL and TLS
- Appendix A Solutions to Exercises
- Appendix B Algorithms Provided by the Bouncy Castle Provider
- Appendix C Using the Bouncy Castle API for Elliptic Curve
EAN: 2147483647
Pages: 145
