When to Stop Testing
The ballerina stood on point, her toes curled like shrimp, not deep-fried shrimp because, as brittle as they are, they would have cracked under the pressure, but tender ebi-kind-of-shrimp, pink and luscious as a Tokyo sunset, wondering if her lover was in the Ginza, wooing the geisha with eyes reminiscent of roe, which she liked better than ebi anyway.
— Brian Tacang
The Banana Principle
In his classic book An Introduction to General Systems Thinking, Gerald Weinberg introduces us to the "Banana Principle." A little boy comes home from school and his mother asks, "What did you learn in school today?" The boy responds, "Today we learned how to spell 'banana' but we didn't learn when to stop." In this book we have learned how to design effective and efficient test cases, but how do we know when to stop? How do we know we have done enough testing?
When to Stop
In The Complete Guide to Software Testing, Bill Hetzel wrote regarding system testing, "Testing ends when we have measured system capabilities and corrected enough of the problems to have confidence that we are ready to run the acceptance test." The phrases "corrected enough" and "have confidence," while certainly correct, are vague.
Regarding stopping, Boris Beizer has written, "There is no single, valid, rational criterion for stopping. Furthermore, given any set of applicable criteria, how exactly each is weighted depends very much upon the product, the environment, the culture and the attitude to risk." Again, not much help in knowing when to stop testing.

Even though Beizer says there is no single criterion for stopping, many organizations have chosen one anyway. The five basic criteria often used to decide when to stop testing are:
- You have met previously defined coverage goals
- The defect discovery rate has dropped below a previously defined threshold
- The marginal cost of finding the "next" defect exceeds the expected loss from that defect
- The project team reaches consensus that it is appropriate to release the product
- The boss says, "Ship it!"
Coverage Goals
Coverage is a measure of how much has been tested compared with how much is available to test. Coverage can be defined at the code level with metrics such as statement coverage, branch coverage, and path coverage. At the integration level, coverage can be defined in terms of APIs tested or API/parameter combinations tested. At the system level, coverage can be defined in terms of functions tested, use cases (or user stories) tested, or use case scenarios (main path plus all the exception paths) tested. Once enough test cases have been executed to meet the previously defined coverage goals, we are, by definition, finished testing. For example, we could define a project's stopping criteria as:
- 100% statement coverage
- 90% use case scenario coverage
When this number of tests pass, we are finished testing. (Of course, there are many other combinations of factors that could be used as stopping criteria.) Not all testers approve of this approach. Glenford Myers believes that this method is highly counterproductive. He believes that because human beings are very goal oriented, this criterion could subconsciously encourage testers to write test cases that have a low probability of detecting defects but do meet the coverage criteria. He believes that more specific criteria such as a set of tests that cover all boundary values, state-transition events, decision table rules, etc. are superior.
Defect Discovery Rate
Another approach is to use the defect discovery rate as the criteria for stopping. Each week (or other short period of time) we count the number of defects discovered. Typically, the number of defects found each week resembles the curve in Figure 16-1. Once the discovery rate is less than a certain previously selected threshold, we are finished testing. For example, if we had set the threshold at three defects/week, we would stop testing after week 18.
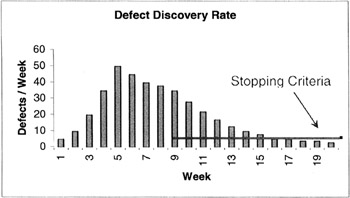
Figure 16-1: Defect Discovery Rate
While this approach appeals to our intuition, we should consider what other situations would produce a curve like this—creation of additional, but less effective test cases; testers on vacation; "killer" defects that still exist in the software but that hide very well. This is one reason why Beizer suggests not depending on only one stopping criterion.
Marginal Cost
In manufacturing, we define "marginal cost" as the cost associated with one additional unit of production. If we're making 1,000 donuts, what is the additional cost of making one more? Not very much. In manufacturing, the marginal cost typically decreases as the number of units made increases. In software testing, however, just the opposite occurs. Finding the first few defects is relatively simple and inexpensive. Finding each additional defect becomes more and more time consuming and costly because these defects are very adept at hiding from our test cases. Thus the cost of finding the "next" defect increases. At some point the cost of finding that defect exceeds the loss our organization would incur if we shipped the product with that defect. Clearly, it is (past) time to stop testing.
Not every system should use this criterion. Systems that require high reliability such as weapons systems, medical devices, industrial controls, and other safety-critical systems may require additional testing because of their risk and subsequent loss should a failure occur.
Team Consensus
Based on various factors including technical, financial, political, and just "gut feelings," the project team (managers, developers, testers, marketing, sales, quality assurance, etc.) decide that the benefits of delivering the software now outweigh the potential liabilities and reach consensus that the product should be released.
Ship It!
For many of us, this will be the only strategy we will ever personally experience. It's often very disheartening for testers, especially after many arduous hours of testing, and with a sure knowledge that many defects are still hiding in the software, to be told "Ship it!" What testers must remember is that there may be very reasonable and logical reasons for shipping the product before we, as testers, think it is ready. In today's fast-paced market economy, often the "first to market" wins a substantial market share. Even if the product is less than perfect, it may still satisfy the needs of many users and bring significant profits to our organization; profits that might be lost if we delayed shipment.
Some of the criteria that should be considered in making this decision are the complexity of the product itself, the complexity of the technologies used to implement it and our skills and experience in using those technologies, the organization's culture and the importance of risk aversion in our organization, and the environment within which the system will operate including the financial and legal exposure we have if the system fails.
As a tester, you may be frustrated by the "Ship It" decision. Remember, our role as testers is to inform management of the risks of shipping the product. The role of your organization's marketing and sales groups should be to inform management of the benefits of shipping the product. With this information, both positive and negative, project managers can make informed, rational decisions.
Some Concluding Advice
Lesson 185 in Lessons Learned in Software Testing states:
- "Because testing is an information gathering process, you can stop when you've gathered enough information. You could stop after you've found every bug, but it would take infinite testing to know that you've found every bug, so that won't work. Instead, you should stop when you reasonably believe that the probability is low that the product still has important undiscovered problems.
- "Several factors are involved in deciding that testing is good enough (low enough chance of undiscovered significant bugs):
- You are aware of the kinds of problems that would be important to find, if they existed.
- You are aware of how different parts of the product could exhibit important problems.
- You have examined the product to a degree and in a manner commensurate with these risks.
- Your test strategy was reasonably diversified to guard against tunnel vision.
- You used every resource available for testing.
- You met every testing process standard that your clients would expect you to meet.
- You expressed your test strategy, test results, and quality assessments as clearly as you could."
Summary
- Regarding stopping, Boris Beizer has written, "There is no single, valid, rational criterion for stopping. Furthermore, given any set of applicable criteria, how exactly each is weighted depends very much upon the product, the environment, the culture and the attitude to risk."
- The five basic criteria often used to decide when to stop testing are:
- You have met previously defined coverage goals
- The defect discovery rate has dropped below a previously defined threshold
- The marginal cost of finding the "next" defect exceeds the expected loss from that defect
- The project team reaches consensus that it is appropriate to release the product
- The boss says, "Ship it!"
References
Hetzel, Bill (1998). The Complete Guide to Software Testing (Second Edition). John Wiley & Sons.
Kaner, Cem,James Bach, and Bret Pettichord (2002). Lessons Learned in Software Testing: A Context-Driven Approach. John Wiley & Sons.
Myers, Glenford (1979). The Art of Software Testing. John Wiley & Sons.
Weinberg, Gerald M. (1975). An Introduction to General Systems Thinking. John Wiley & Sons.
Preface
Section I - Black Box Testing Techniques
- Section I - Black Box Testing Techniques
- Equivalence Class Testing
- Boundary Value Testing
- Decision Table Testing
- Pairwise Testing
- State-Transition Testing
- Domain Analysis Testing
- Use Case Testing
Section II - White Box Testing Techniques
Section III - Testing Paradigms
Section IV - Supporting Technologies
Section V - Some Final Thoughts
EAN: 2147483647
Pages: 161
