Data Flow Testing
Holly had reached the age and level of maturity to comprehend the emotional nuances of Thomas Wolfe's assertion "you can't go home again," but in her case it was even more poignant because there was no home to return to: her parents had separated, sold the house, euthanized Bowser, and disowned Holly for dropping out of high school to marry that 43-year-old manager of Trailer Town in Idaho—and even their trailer wasn't a place she could call home because it was only a summer sublet.
— Eileen Ostrow Feldman
Introduction
Almost every programmer has made this type of mistake:
main() {
int x;
if (x==42){ ...}
}
The mistake is referencing the value of a variable without first assigning a value to it. Naive developers unconsciously assume that the language compiler or run-time system will set all variables to zero, blanks, TRUE, 42, or whatever they require later in the program. A simple C program that illustrates this defect is:
#include
main() {
int x;
printf ("%d",x);
}
The value printed will be whatever value was "left over" in the memory location to which x has been assigned, not necessarily what the programmer wanted or expected.
Data flow testing is a powerful tool to detect just such errors. Rapps and Weyuker, popularizers of this approach, wrote, "It is our belief that, just as one would not feel confident about a program without executing every statement in it as part of some test, one should not feel confident about a program without having seen the effect of using the value produced by each and every computation."
| Key Point |
Data flow testing is a powerful tool to detect improper use of data values due to coding errors. |
Technique
Variables that contain data values have a defined life cycle. They are created, they are used, and they are killed (destroyed). In some programming languages (FORTRAN and BASIC, for example) creation and destruction are automatic. A variable is created the first time it is assigned a value and destroyed when the program exits.
In other languages (like C, C++, and Java) the creation is formal. Variables are declared by statements such as:
int x; // x is created as an integer string y; // y is created as a string
These declarations generally occur within a block of code beginning with an opening brace { and ending with a closing brace }. Variables defined within a block are created when their definitions are executed and are automatically destroyed at the end of a block. This is called the "scope" of the variable. For example:
{ // begin outer block
int x; // x is defined as an integer within this outer block
...; // x can be accessed here
{ // begin inner block
int y; // y is defined within this inner block
...; // both x and y can be accessed here
} // y is automatically destroyed at the end of
// this block
...; // x can still be accessed, but y is gone
} // x is automatically destroyed
Variables can be used in computation (a=b+1). They can also be used in conditionals (if (a>42)). In both uses it is equally important that the variable has been assigned a value before it is used.
Three possibilities exist for the first occurrence of a variable through a program path:
|
1. |
~d |
the variable does not exist (indicated by the ~), then it is defined (d) |
|
2. |
~u |
the variable does not exist, then it is used (u) |
|
3. |
~k |
the variable does not exist, then it is killed or destroyed (k) |
The first is correct. The variable does not exist and then it is defined. The second is incorrect. A variable must not be used before it is defined. The third is probably incorrect. Destroying a variable before it is created is indicative of a programming error.
Now consider the following time-sequenced pairs of defined (d), used (u), and killed (k):
|
dd |
Defined and defined again—not invalid but suspicious. Probably a programming error. |
|
du |
Defined and used—perfectly correct. The normal case. |
|
dk |
Defined and then killed—not invalid but probably a programming error. |
|
ud |
Used and defined—acceptable. |
|
uu |
Used and used again—acceptable. |
|
uk |
Used and killed—acceptable. |
|
kd |
Killed and defined—acceptable. A variable is killed and then redefined. |
|
ku |
Killed and used—a serious defect. Using a variable that does not exist or is undefined is always an error. |
|
kk |
Killed and killed—probably a programming error. |
| Key Point |
Examine time-sequenced pairs of defined, used, and killed variable references. |
A data flow graph is similar to a control flow graph in that it shows the processing flow through a module. In addition, it details the definition, use, and destruction of each of the module's variables. We will construct these diagrams and verify that the define-use-kill patterns are appropriate. First, we will perform a static test of the diagram. By "static" we mean we examine the diagram (formally through inspections or informally through look-sees). Second, we perform dynamic tests on the module. By "dynamic" we mean we construct and execute test cases. Let's begin with the static testing.
Static Data Flow Testing
The following control flow diagram has been annotated with define-use-kill information for each of the variables used in the module.
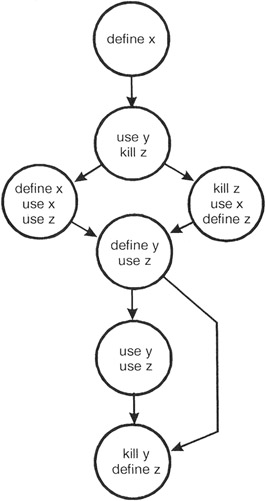
Figure 11-1: The control flow diagram annotated with define-use-kill information for each of the module's variables.
For each variable within the module we will examine define-use-kill patterns along the control flow paths. Consider variable x as we traverse the left and then the right path:
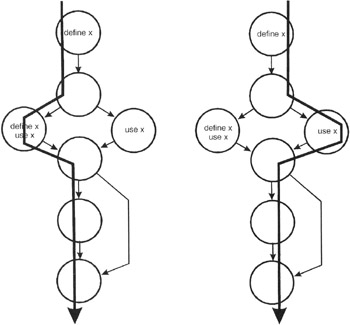
Figure 11-2: The control flow diagram annotated with define-use-kill information for the x variable.
The define-use-kill patterns for x (taken in pairs as we follow the paths) are:
|
~define |
correct, the normal case |
|
define-define |
suspicious, perhaps a programming error |
|
define-use |
correct, the normal case |
Now for variable y. Note that the first branch in the module has no impact on the y variable.
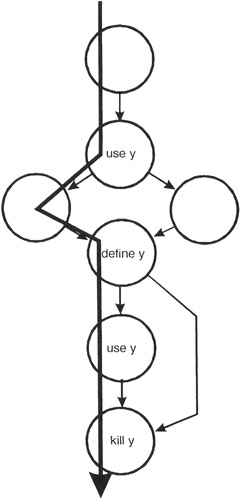
Figure 11-3: The control flow diagram annotated with define-use-kill information for the y variable.
The define-use-kill patterns for y (taken in pairs as we follow the paths) are:
|
~use |
major blunder |
|
use-define |
acceptable |
|
define-use |
correct, the normal case |
|
use-kill |
acceptable |
|
define-kill |
probable programming error |
Now for variable z.
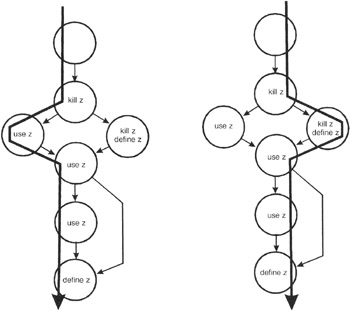
Figure 11-4: The control flow diagram annotated with define-use-kill information for the z variable.
The define-use-kill patterns (taken in pairs as we follow the paths) are:
|
~kill |
programming error |
|
kill-use |
major blunder |
|
use-use |
correct, the normal case |
|
use-define |
acceptable |
|
kill-kill |
probably a programming error |
|
kill-define |
acceptable |
|
define-use |
correct, the normal case |
In performing a static analysis on this data flow model the following problems have been discovered:
x: define-define y: ~use y: define-kill z: ~kill z: kill-use z: kill-kill
Unfortunately, while static testing can detect many data flow errors, it cannot find them all. Consider the following situations:
- Arrays are collections of data elements that share the same name and type. For example
int stuff[100];
defines an array named stuff consisting of 100 integer elements. In C, C++, and Java the individual elements are named stuff[0], stuff[1], stuff[2], etc. Arrays are defined and destroyed as a unit but specific elements of the array are used individually. Often programmers refer to stuff[j] where j changes dynamically as the program executes. In the general case, static analysis cannot determine whether the define-use-kill rules have been followed properly unless each element is considered individually.
- In complex control flows it is possible that a certain path can never be executed. In this case an improper define-use-kill combination might exist but will never be executed and so is not truly improper.
- In systems that process interrupts, some of the define-use-kill actions may occur at the interrupt level while other define-use-kill actions occur at the main processing level. In addition, if the system uses multiple levels of execution priorities, static analysis of the myriad of possible interactions is simply too difficult to perform manually.
For this reason, we now turn to dynamic data flow testing.
Dynamic Data Flow Testing
Because data flow testing is based on a module's control flow, it assumes that the control flow is basically correct. The data flow testing process is to choose enough test cases so that:
- Every "define" is traced to each of its "uses"
- Every "use" is traced from its corresponding "define"
To do this, enumerate the paths through the module. This is done using the same approach as in control flow testing: Begin at the module's entry point, take the leftmost path through the module to its exit. Return to the beginning and vary the first branching condition. Follow that path to the exit. Return to the beginning and vary the second branching condition, then the third, and so on until all the paths are listed. Then, for every variable, create at least one test case to cover every define-use pair.
Applicability and Limitations
Data flow testing builds on and expands control flow testing techniques. As with control flow testing, it should be used for all modules of code that cannot be tested sufficiently through reviews and inspections. Its limitations are that the tester must have sufficient programming skill to understand the code, its control flow, and its variables. Like control flow testing, data flow testing can be very time consuming because of all the modules, paths, and variables that comprise a system.
Summary
- A common programming mistake is referencing the value of a variable without first assigning a value to it.
- A data flow graph is similar to a control flow graph in that it shows the processing flow through a module. In addition, it details the definition, use, and destruction of each of the module's variables. We will use these diagrams to verify that the define-use-kill patterns are appropriate.
- Enumerate the paths through the module. Then, for every variable, create at least one test case to cover every define-use pair.
Practice
- The following module of code computes n! (n factorial) given a value for n. Create data flow test cases covering each variable in this module. Remember, a single test case can cover a number of variables.
int factorial (int n) { int answer, counter; answer = 1; counter = 1; loop: if (counter > n) return answer; answer = answer * counter; counter = counter + 1; goto loop; } - Diagram the control flow paths and derive the data flow test cases for the following module:
int module( int selector) { int foo, bar; switch selector { case SELECT-1: foo = calc_foo_method_1(); break; case SELECT-2: foo = calc_foo_method_2(); break; case SELECT-3: foo = calc_foo_method_3(); break; } switch foo { case FOO-1: bar = calc_bar_method_1(); break; case FOO-2: bar = calc_bar_method_2(); break; } return foo/bar; }Do you have any concerns with this code? How would you deal with them?
References
Beizer, Boris (1990). Software Testing Techniques. Van Nostrand Reinhold.
Binder, Robert V. (2000). Testing Object-Oriented Systems: Models, Patterns, and Tools. Addison-Wesley.
Marick, Brian (1995). The Craft of Software Testing: Subsystem Testing Including Object-Based and Object-Oriented Testing. Prentice-Hall.
Rapps, Sandra and Elaine J. Weyuker. "Data Flow Analysis Techniques for Test Data Selection." Sixth International Conference on Software Engineering, Tokyo, Japan, September 13–16, 1982.
Preface
Section I - Black Box Testing Techniques
- Section I - Black Box Testing Techniques
- Equivalence Class Testing
- Boundary Value Testing
- Decision Table Testing
- Pairwise Testing
- State-Transition Testing
- Domain Analysis Testing
- Use Case Testing
Section II - White Box Testing Techniques
Section III - Testing Paradigms
Section IV - Supporting Technologies
Section V - Some Final Thoughts
EAN: 2147483647
Pages: 161
