Software Development
Good Programs
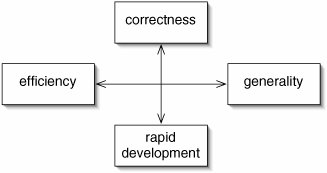
What are the features of a good computer program? It is essential that the program be correct, doing what it is supposed to do and containing no bugs. The program should be efficient, using no more time or memory than is necessary. The program should be general-purpose, so that we don't have to start from scratch the next time we build a similar program. Finally, all other things being equal, the program should be rapidly developed. While there are some changes which will further one of these goals at no cost, it is often necessary to make tradeoffs, as suggested by Figure 1-1.
Figure 1-1. There are often tradeoffs between the features of a good computer program.
We would like all of our programs to be perfectly correct. In some applications, such as medical equipment, aircraft navigation, and nuclear power plant control, lives may literally depend on the correctness of software. In others, such as games and web browsers, the occasional crash may be merely an annoyance. The best way to ensure correctness is to precisely specify how the program is supposed to behave and then thoroughly test the program to verify that it does so. Unfortunately, this can take a prohibitive amount of time. Practical concerns often lead to the release of buggy software.
Much of this book concerns choosing data structures and algorithms to make programs more efficient. A data structure is a way of organizing information (numbers, text, pictures, and so on) in a computer. An algorithm is a step-by-step process for doing something, written either in plain English or in a programming language. (We study algorithms rather than programs because, while programming languages change every few years, good algorithms stay around for decades or even millennia.)
Data structures and algorithms are intimately intertwined. A data structure may support efficient algorithms for some operations (such as checking whether some item is present) but not for others (such as removing an item). Conversely, a fast algorithm may require that data be stored in a particular way. To make the best choices, we would like to know as much as possible about how our program will be used. What kinds of data are we likely to encounter? Which operations will be most common? Some of the most efficient data structures and algorithms are limited to specific tasks, so choosing them makes our programs less general-purpose.
If a program is to be used very heavily, it may be worth spending some time to optimize it, that is, fine-tune it to maximize efficiency given the expected data, the hardware on which it will run, and so on. This trades development time and generality for efficiency.
Once we have a certain amount of programming experience, we realize that we are writing roughly the same programs over and over again. We can save development time by cutting and pasting code from previous programs. Sometimes the new program requires changes to the code. To minimize the time we spend changing our old code, we try to write general-purpose components. For example, rather than writing a method to sort an array of five numbers, we write a method which can sort an array of any length, containing any values of any comparable type (numbers, letters, strings, and so on). This general-purpose code tends to be less efficient than code written for a specific use. It can also take a little more time to make sure it is correct. On the other hand, once it is written and thoroughly documented we never need to think about its inner workings againit is a trusty power tool that we can bring out whenever we need it. Established programming languages like Java have huge, general-purpose libraries for graphics, file handling, networking, and so on.
Development time is a precious resource to employers (who must pay their programmers) and students (who are notorious for procrastination). As you have probably learned by now from bitter experience, most development time is spent debugging. The way to reduce debugging time is to invest time in design and testing. The urge to sit down and start writing code is powerful, even for experienced programmers, but a hastily thrown together program will invariably turn on its creator.
While development time may seem irrelevant to the final programwho cares how long the Mona Lisa took to paint?many of the techniques for reducing development time also reduce the time needed for program maintenance by making our programs more correct and general-purpose.
Encapsulation
It is difficult to write correct, efficient, general-purpose programs in a reasonable amount of time because computer programs are among the most complex things people have ever constructed. Computer scientists have put a great deal of thought into dealing with this complexity. The approach used by the Java programming language is object-oriented programming. Object-oriented programming is characterized by three principles:
- Encapsulation is the division of a program into distinct components which have limited interaction. A method is an example of an encapsulated component: other methods interact with it only through the arguments they pass to it and the value it returns. Each component can be tested separately, improving correctness, and components can be recombined into new programs, improving generality and development speed. This chapter focuses on encapsulation.
- Polymorphism is the ability of the same word or symbol to mean different things in different contexts. For example, in Java, the symbol + means one thing (addition) when dealing with numbers, but means something else (concatenation) when dealing with Strings. Polymorphism greatly improves generality, which in turn improves correctness and development speed. Polymorphism is discussed in Chapter 2.
- Inheritance is the ability to specify that a program is similar to another program, delineating only the differences. To draw an example from nature, a platypus is pretty much like any other mammal, except that it lays eggs. Inheritance makes code reuse easier, improving correctness, generality, and development speed. Inheritance is the subject of Chapter 3.
None of these features directly improves efficiency. Indeed, there may be some loss of efficiency. The consensus among object-oriented programmers is that this price is well worth paying. The trouble with software today is not that it runs too slowly, but that it is buggy and takes too long to develop.
The first principle of object-oriented programming, encapsulation, is analogous to division of labor in an organization. A grocery store, for example, might have one person in charge of stocking the shelves and another in charge of purchasing. When the stocker notices that the store's supply of rutabagas is running low, she only needs to notify the purchaser, who then orders more. The stocker doesn't have to know how much rutabagas cost or where they come from. The purchaser doesn't have to know which aisle they are displayed on. Both jobs are made easier through encapsulation.
Encapsulation makes it easier to rapidly develop correct programs because a programmer only has to consider a few things when writing any one component of the program. This is particularly important in projects involving several programmers: once the programmers have agreed on how the components will interact, each is free to do whatever he wants within his component.
Generality is improved, both because components can be reused in their entirety and because understanding one component does not require one to understand the entire program. In fact, very large programs would be effectively impossible to write, debug, and maintain without encapsulation.
The relation between encapsulation and efficiency is less clear. Encapsulation prevents certain efficiency improvements which depend on understanding several parts of a program. Suppose the purchaser in the grocery store always has new merchandise delivered to the back of the store. It might be more efficient to park the rutabaga truck in front if rutabagas are displayed near the entrance, but the purchaser isn't aware of this detail. On the other hand, by simplifying individual program components, encapsulation can give a programmer freedom to make improvements within a component. If the stocker had to think about purchasing, running the cash register, and so on, then she might not have time to learn to balance five crates of rutabagas on a handtruck.
We have already seen encapsulation in at least one sense. By dividing a class into methods, we can concentrate on one method at a time. Any variables declared inside a method are visible only inside that method. When we invoke another method, we only need to know the information in the method signature (what arguments it expects and what it returns) and associated documentation. We don't have to know what happens inside the method.
We don't merely have the option to ignore the innards of a method. We actually cannot access variables declared inside a method from outside that method. This is in keeping with the principle of information hiding: the workings of a component should not be visible from the outside. Information hiding enforces encapsulation. Continuing the grocery store analogy, we don't give the stocker access to the bank account and we don't give the purchaser the keys to the forklift.
Information hiding may seem counterintuitive. Isn't it better for everyone to have as much information as possible? Experience has shown that the answer is "no." If someone can see the inner workings of a component, they may be tempted to take shortcuts in the name of efficiency. With access to the bank account, the stocker may reason, "The purchaser is on vacation this week. I'll just order more rutabagas myself." If she does not follow proper accounting procedures, or does not realize that the purchaser has already ordered more rutabagas as part of the regular monthly vegetable order, she could cause problems. We shudder to think what might happen if the purchaser got behind the wheel of the forklift.
The Software Development Cycle
Software engineering is the study of how to develop correct, efficient, general-purpose programs in a reasonable amount of time. There is a vast body of literature, techniques, jargon, and competing philosophies about software engineering. Much of it is devoted to the largest, most challenging programs, which are written by teams of dozens of programmers working for years. These elaborate techniques are not appropriate for the relatively small programs we will write in this book. On the other hand, our programs are now sufficiently sophisticated that some examination of the software development process is in order. If we just sit down and start writing code, we will likely get into trouble.
We can think of the process of writing a program in terms of the software development cycle (Figure 1-2). We divide the process into three major phases: design, implementation, and testing. (Many software engineers divide the process into more phases.)
Figure 1-2. The software development cycle.
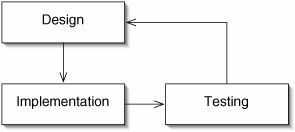
In the design phase, we decide what the program is going to look like. This includes problem specification, the task of stating precisely what a program is supposed to do. In a programming class, the problem specification is often given as the assignment. In real life, problem specification involves working with the end user (for example, the customer, employer, or scientific community) to decide what the program should do.
The design phase also includes breaking the program down into components. What are the major components of the program? What is each component supposed to do? How do the components interact? It is a good idea to write a comment for each component at this point, so that we have a very clear understanding of what the component does. Commenting first also avoids the danger that we'll put off commenting until our program has become hopelessly complicated.
The implementation phase is the writing of code. This is where we move from a description of a program to a (hopefully) working program. Many students erroneously believe that this is the only phase in which actual programming is occurring, so the other two phases are unimportant. In fact, the more time spent on the other two phases, the less is needed in implementation. If we rush to the keyboard to start coding, we may end up having to throw away some of our work because it doesn't fit in with the rest of the program or doesn't meet the problem specification.
In the testing phase, we run our program and verify that it does what it is supposed to do. After a long session of programming, it is tempting to believe that our program is correct if it compiles and runs on one test case. We must be careful to test our program thoroughly. For example, when testing a method to search for some item in an array, we should consider cases where the target is the first element of the array, where it is somewhere in the middle, where it is the last element, and where it is not present at all.
The French poet Paul Valéry wrote, "A poem is never finished, only abandoned." The same can be said of computer programs. There is some point when the software is released, but there is often maintenance to be performed: changes to make, new features to add, bugs to fix. This maintenance is just more iterations of the software development cycle. This is why the cycle has no point labeled "end" or "finished." In a programming course, assignments are often completely abandoned after they are handed in, but general-purpose components may need some maintenance if they are to be reused in future assignments.
Some software engineers argue that there should be, in effect, only one iteration of the cycle: the entire program should be designed in exquisite detail, then implemented, then tested. Proponents of this top-down approach argue that, by making all design decisions up front, we avoid wasting time implementing components that won't fit into the final program.
Other software engineers advocate many iterations: design some simple component, implement it, test it, expand the design very slightly, and so on. Proponents of this bottom-up approach argue that this allows us to start testing before we have accumulated a huge body of code. Furthermore, because we put off our design decisions, we avoid wasting time redesigning the program if we discover that, for example, we misunderstood the problem specification.
In practice, most software development falls between these two extremes. In this chapter, we will lean toward the bottom-up end of the spectrum. When we are first learning to program, we don't yet have the experience to envision the structure of an entire program. We are also likely to make a lot of coding errors, so we should test early and often.
Encapsulation allows us to break up the software development cycle (Figure 1-3).
Figure 1-3. The construction of each encapsulated component (shaded) involves one or more iterations of the software development cycle. The initial design phase involves breaking the program into components, each of which can be developed separately. These components are combined in the implementation phase.
(This item is displayed on page 9 in the print version)
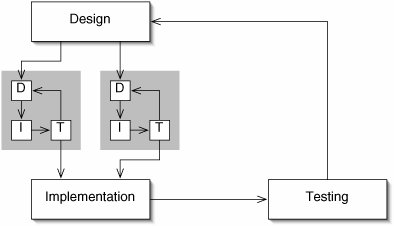
Once we divide the program into encapsulated components, we can work on each one separately. In a project with several programmers, multiple components can be developed at the same time. Even if we are working alone, the ability to concentrate on a single component makes it much easier to rapidly develop correct, efficient, general-purpose code. Once the components are "complete," we integrate them in a high-level implementation phase and then test the entire system.
Exercises
| 1.1 |
What have you done in the past to make one of your programs more correct? More efficient? More general-purpose? More rapidly developed? |
| 1.2 |
Discuss the extent to which your college education has consisted of encapsulated courses. |
| 1.3 |
Discuss whether a top-down or a bottom-up approach to software development is more likely to produce a correct program. Which is likely to produce a more efficient program? More general-purpose? More rapidly developed? Which approach do you prefer? |
| 1.4 |
Discuss whether assertions (Appendix A) should be considered part of design, part of implementation, or part of testing. |
| 1.5 |
Where do comments fit into the development cycle? How do they affect correctness, efficiency, generality, and development speed? |
Part I: Object-Oriented Programming
Encapsulation
- Encapsulation
- Software Development
- Classes and Objects
- Using Objects
- Summary
- Vocabulary
- Problems
- Projects
Polymorphism
Inheritance
- Inheritance
- Extending a Class
- The Object Class
- Packages and Access Levels
- Summary
- Vocabulary
- Problems
- Projects
Part II: Linear Structures
Stacks and Queues
- Stacks and Queues
- The Stack Interface
- The Call Stack
- Exceptions
- The Queue Interface
- Summary
- Vocabulary
- Problems
- Projects
Array-Based Structures
- Array-Based Structures
- Shrinking and Stretching Arrays
- Implementing Stacks and Queues
- The List Interface
- Iterators
- The Java Collections Framework: A First Look
- Summary
- Vocabulary
- Problems
- Projects
Linked Structures
- Linked Structures
- List Nodes
- Stacks and Queues
- The LinkedList Class
- The Java Collections Framework Revisited
- Summary
- Vocabulary
- Problems
- Projects
Part III: Algorithms
Analysis of Algorithms
- Analysis of Algorithms
- Timing
- Asymptotic Notation
- Counting Steps
- Best, Worst, and Average Case
- Amortized Analysis
- Summary
- Vocabulary
- Problems
- Projects
Searching and Sorting
- Searching and Sorting
- Linear Search
- Binary Search
- Insertion Sort
- The Comparable Interface
- Sorting Linked Lists
- Summary
- Vocabulary
- Problems
- Projects
Recursion
- Recursion
- Thinking Recursively
- Analyzing Recursive Algorithms
- Merge Sort
- Quicksort
- Avoiding Recursion
- Summary
- Vocabulary
- Problems
- Projects
Part IV: Trees and Sets
Trees
Sets
- Sets
- The Set Interface
- Ordered Lists
- Binary Search Trees
- Hash Tables
- The Java Collections Framework Again
- Summary
- Vocabulary
- Problems
- Projects
Part V: Advanced Topics
Advanced Linear Structures
- Advanced Linear Structures
- Bit Vectors
- Sparse Arrays
- Contiguous Representation of Multidimensional Arrays
- Advanced Searching and Sorting
- Summary
- Vocabulary
- Problems
- Projects
Strings
Advanced Trees
- Advanced Trees
- Heaps
- Disjoint Set Clusters
- Digital Search Trees
- Red-Black Trees
- Summary
- Vocabulary
- Problems
- Projects
Graphs
- Graphs
- Terminology
- Representation
- Graph Traversal
- Topological Sorting
- Shortest Paths
- Minimum Spanning Trees
- Summary
- Vocabulary
- Problems
- Projects
Memory Management
Out to the Disk
- Out to the Disk
- Interacting with Files
- Compression
- External Sorting
- B-Trees
- Summary
- Vocabulary
- Problems
- Projects
Part VI: Appendices
A. Review of Java
- A. Review of Java
- A.1. The First Program
- A.2. Variables and Types
- A.3. Loops
- A.4. Interacting with the User
- A.5. Branching
- A.6. Methods and Breaking Out
- A.7. Constants
- A.8. Operators
- A.9. Debugging
- A.10. Coding Conventions
B. Unified Modeling Language
C. Summation Formulae
- C. Summation Formulae
- C.1. Sum Notation
- C.2. Sum of Constants
- C.3. Sum of First n Integers
- C.4. Sums of Halves and Doubles
- C.5. Upper Limit on Sum of a Function
- C.6. Constant Factors
D. Further Reading
Index
EAN: 2147483647
Pages: 216
