Analyzing Satisfaction Data
The five-point satisfaction scale (very satisfied, satisfied, neutral, dissatisfied, and very dissatisfied) is often used in customer satisfaction surveys. The data are usually summarized in terms of percent satisfied. In presentation, run charts or bar charts to show the trend of percent satisfied are often used. We recommend that confidence intervals be formed for the data points so that the margins of error of the sample estimates can be observed immediately (Figure 14.3).
Figure 14.3. Quarterly Trend of Percent Satisfied with a Hypothetical Product
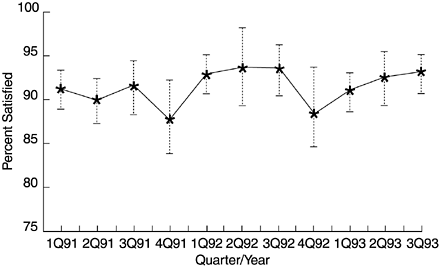
Traditionally, the 95% confidence level is used for forming confidence intervals and the 5% probability ( p value) is used for significance testing. This p value means that if the true difference is not significant, the chance we wrongly conclude that the difference is significant is 5%. Therefore, if a difference is statistically significant at the 5% level, it is indeed very significant. When analyzing customer satisfaction, it is not necessary to stick to the traditional significance level. If the purpose is to be more sensitive in detecting changes in customers' satisfaction levels, or to trigger actions when a significant difference is observed, then the 5% level is not sensitive enough. Based on our experience, a p value as high as 20%, or a confidence level of 80%, is still reasonablesensitive enough to detect a substantial difference, yet not giving false alarms when the difference is trivial.
Although percent satisfied is perhaps the most used metric, some companies, such as IBM, choose to monitor the inverse, the percent nonsatisfied. Nonsatisfied includes the neutral, dissatisfied, and very dissatisfied in the five-point scale. The rationale to use percent nonsatisfied is to focus on areas that need improvement. This is especially the case when the value of percent satisfied is quite high. Figure 12.3 in Chapter 12 shows an example of IBM Rochester's percent nonsatisfied in terms of CUPRIMDA (capability, usability, performance, reliability, installability , maintainability, documentation/information, and availability) categories and overall satisfaction.
14.2.1 Specific Attributes and Overall Satisfaction
The major advantage of monitoring customer satisfaction with specific attributes of the software, in addition to overall satisfaction, is that such data provide specific information for improvement. The profile of customer satisfaction with those attributes (e.g., CUPRIMDA) indicates the areas of strength and weakness of the software product. One easy mistake in customer satisfaction analysis, however, is to equate the areas of weakness with the priority of improvement, and to increase investment to improve those areas. For instance, if a product has low satisfaction with documentation (D) and high satisfaction with reliability (R), that does not mean that there is no need to continually improve the product's reliability and that the first priority of the development team is to improve documentation. Reliability may be the very reason the customers decide to buy this product and that customers may expect even further improvement. On the other hand, customers may not like the product's documentation but may find it tolerable given other considerations. To answer the question on priority of improvement, therefore, the subject must be looked at in the broader context of overall customer satisfaction with the product. Specifically, the correlations of the satisfaction levels of specific attributes with overall satisfaction need to be examined. After all, it is the overall satisfaction level that the software developer aims to maximize; it is the overall satisfaction level that affects the customer's purchase decision.
Here we describe an example of analyzing the relationship between satisfaction level with specific attributes and overall satisfaction for a hypothetical product. For this product, data are available on the UPRIMD parameters and on availability (A). The purpose of the analysis is to determine the priority for improvement by assessing the extent to which each of the UPRIMD-A parameters affects overall customer satisfaction. The sample size for this analysis is 3,658. Satisfaction is measured by the five-point scale ranging from very dissatisfied (1) to very satisfied (5).
To achieve the objectives, we attempted two statistical approaches: least-squares multiple regression and logistic regression. In both approaches overall customer satisfaction is the dependent variable, and satisfaction levels with UPRIMD-A are the independent variables . The purpose is to assess the correlations between each specific attribute and overall satisfaction simultaneously . For the ordinary regression approach, we use the original five-point scale. The scale is an ordinal variable and data obtained from it represent a truncated continuous distribution. Sensitivity research in the literature, however, indicates that if the sample size is large (such as in our case), violation of the interval scale and the assumption of Gaussian distribution results in very small bias. In other words, the use of ordinary regression is quite robust for the ordinal scale with large samples.
For the logistic regression approach, we classified the five-point scale into a dichotomous variable: very satisfied and satisfied (4 and 5) versus nonsatisfied (1, 2, and 3). Categories 4 and 5 were recoded as 1 and categories 1, 2, and 3 were recoded as 0. The dependent variable, therefore, is the odds ratio of satisfied and very satisfied versus nonsatisfied. The odds ratio is a measurement of association that has been widely used for categorical data analysis. In our application it approximates how much more likely customers will be positive in overall satisfaction if they were satisfied with specific UPRIMD-A parameters versus if they were not. For instance, let customers who were satisfied with the performance of the system form a group and those not satisfied with the performance form another group. Then an odds ratio of 2 indicates that the overall satisfaction occurs twice as often among the first group of customers (satisfied with the performance of the system) than the second group . The logistic model in our analysis, therefore, is as follows :
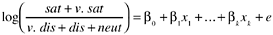
The correlation matrix, means, and standard deviations are shown in Table 14.1. Two types of means are shown: the five-point scale and the 01 scale. Means for the latter reflect the percent satisfaction level (e.g., overall satisfaction is 85.5% and satisfaction with reliability is 93.8%). Among the parameters, availability and reliability have the highest satisfaction levels, whereas documentation and installability have the lowest .
Table 14.1. Correlation Matrix, Means, and Standard Deviations
|
Overall |
U |
P |
R |
I |
M |
D |
A |
|
|---|---|---|---|---|---|---|---|---|
|
Overall |
||||||||
|
Uusability |
.61 |
|||||||
|
Pperformance |
.43 |
.46 |
||||||
|
Rreliability |
.63 |
.56 |
.42 |
|||||
|
Iinstallability |
.51 |
.57 |
.39 |
.47 |
||||
|
Mmaintainability |
.40 |
.39 |
.31 |
.40 |
.38 |
|||
|
Ddocumentation |
.45 |
.51 |
.34 |
.44 |
.45 |
.35 |
||
|
Aavailability |
.39 |
.39 |
.52 |
.46 |
.32 |
.28 |
.31 |
|
|
Mean |
4.20 |
4.18 |
4.35 |
4.41 |
3.98 |
4.15 |
3.97 |
4.57 |
|
Standard Deviation |
.75 |
.78 |
.75 |
.66 |
.90 |
.82 |
.89 |
.64 |
|
% SAT |
85.50 |
84.10 |
91.10 |
93.80 |
75.30 |
82.90 |
73.30 |
94.50 |
As expected, there is moderate correlation among the UPRIMD-A parameters. Usability with reliability, installability, and documentation, and performance with availability are the more notable ones. In relation to overall satisfaction, reliability, usability, and installability have the highest correlations.
Results of the multiple regression analysis are summarized in Table 14.2. As indicated by the p values, all parameters are significant at the 0.0001 level except the availability parameter. The total variation of overall customer satisfaction explained by the seven parameters is 52.6%. In terms of relative importance, reliability, usability, and installability are the highest, as indicated by the t value. This finding is consistent with what we observed from the simple correlation coefficients in Table 14.1. Reliability being the most significant variable implies that although customers are quite satisfied with the software's reliability (93.8%), reliability is still the most determining factor for achieving overall customer satisfaction. In other words, further reliability improvement is still demanded. For usability and installability, the current low and moderate levels of satisfaction, together with the significance finding, really pinpoint the need for drastic improvement.
More interesting observations can be made on documentation and availability. Although being the lowest satisfied parameter, intriguingly, documentation's influence on overall satisfaction is not strong. This may be because customers have become more tolerant with documentation problems. Indeed, data from software systems within and outside IBM often indicate that documentation/information usually receive the lowest ratings among specific dimensions of a software product. This does not mean that one doesn't have to improve documentation; it means that documentation is not as sensitive as other variables when measuring its effects on the overall satisfaction of the software. Nonetheless, it still is a significant variable and should be improved.
Table 14.2. Results of Multiple Regression Analysis
|
Variable |
Regression Coefficient (Beta) |
t value |
Significance Level ( p Value) |
|---|---|---|---|
|
Rreliability |
.391 |
21.4 |
.0001 |
|
Uusability |
.247 |
15.2 |
.0001 |
|
Iinstallability |
.091 |
7.0 |
.0001 |
|
Pperformance |
.070 |
4.6 |
.0001 |
|
Mmaintainability |
.067 |
5.4 |
.0001 |
|
Ddocumentation |
.056 |
4.5 |
.0001 |
|
Aavailability |
.022 |
1.2 |
.22 (not significant) |
Availability is the least significant factor. On the other hand, it has the highest satisfaction level (94.5%, average 4.57 in the five-point scale).
Results of the logistic regression model are shown in Table 14.3. The most striking observation is that the significance of availability in affecting customer satisfaction is in vivid contrast to findings from the ordinary regression analysis, as just discussed. Now availability ranks third, after reliability and usability, in affecting overall satisfaction. The difference observed from the two models lies in the difference in the scaling of the dependent and independent variables in the two approaches. Combining the two findings, we interpret the data as follows:
- Availability is not very important in influencing the average shift in overall customer satisfaction from one level to the next (from dissatisfied to neutral, from neural to satisfied, etc.).
- However, availability is very important in affecting whether customers are satisfied versus nonsatisfied.
- Therefore, availability is a sensitive factor in customer satisfaction and should be improved despite its level of high satisfaction.
Because the dependent variable of the logistic regression model (satisfied versus nonsatisfied) is more appropriate for our purpose, we use the results of the logistic model for the rest of our example.
The odds ratios indicate the relative importance of the UPRIMD-A variables in the logistics model. That all ratios are greater than 1 means that each UPRIMD-A variable has a positive impact on overall satisfaction, the dependent variables. Among them, reliability has the largest odds ratio, 14.4. So the likelihood of overall satisfaction is much higher for customers who are satisfied with reliability than for those who aren't. On the other hand, documentation has the lowest odds ratio, 1.4. This indicates that the impact of documentation on overall satisfaction is not very strong, but there is still a positive effect.
Table 14.3. Results of Logistic Regression Analysis
|
Variable |
Regression Coefficient (Beta) |
Chi Square |
Significance Level ( p Value) |
Odds Ratio |
|---|---|---|---|---|
|
Rreliability |
1.216 |
138.6 |
<.0001 |
11.4 |
|
Uusability |
.701 |
88.4 |
<.0001 |
4.1 |
|
Aavailability |
.481 |
16.6 |
<.0001 |
2.6 |
|
Iinstallability |
.410 |
33.2 |
<.0001 |
2.3 |
|
Mmaintainability |
.376 |
26.2 |
<.0001 |
2.1 |
|
Pperformance |
.321 |
14.3 |
.0002 |
1.9 |
|
Ddocumentation |
.164 |
5.3 |
.02 |
1.4 |
Table 14.4 presents the probabilities for customers being satisfied depending on whether or not they are satisfied with the UPRIMD-A parameters. These conditional probabilities are derived from the earlier logistic regression model. When customers are satisfied with all seven parameters, chances are they are 96.32% satisfied with the overall software product. From row 2 through row 8, we show the probabilities that customers will be satisfied with the software when they are not satisfied with one of the seven UPRIMD-A parameters, one at a time. The drop in probabilities in row 2 through row 8 compared with row 1 indicates how important that particular parameter is to indicate whether customers are satisfied. Reliability (row 6), usability (row 8), and availability (row 2), in that order, again, are the most sensitive parameters. Data in rows 9 through 16 show the reverse view of rows 1 through 8: the probabilities that customers will be satisfied with the software when they are satisfied with one of the seven parameters, one at a time. This exercise, in fact, is a confirmation of the odds ratios in Table 14.3.
Table 14.4. Conditional Probabilities
|
Row |
P(Y=1/X) |
U |
P |
R |
I |
M |
D |
A |
Frequency |
|---|---|---|---|---|---|---|---|---|---|
|
1 |
.9632 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1632 |
|
2 |
.9187 |
1 |
1 |
1 |
1 |
1 |
1 |
14 |
|
|
3 |
.9552 |
1 |
1 |
1 |
1 |
1 |
1 |
267 |
|
|
4 |
.9331 |
1 |
1 |
1 |
1 |
1 |
1 |
155 |
|
|
5 |
.9287 |
1 |
1 |
1 |
1 |
1 |
1 |
212 |
|
|
6 |
.7223 |
1 |
1 |
1 |
1 |
1 |
1 |
12 |
|
|
7 |
.9397 |
1 |
1 |
1 |
1 |
1 |
1 |
42 |
|
|
8 |
.8792 |
1 |
1 |
1 |
1 |
1 |
1 |
47 |
|
|
9 |
.0189 |
20 |
|||||||
|
10 |
.0480 |
1 |
8 |
||||||
|
11 |
.0260 |
1 |
2 |
||||||
|
12 |
.0392 |
1 |
9 |
||||||
|
13 |
.0132 |
1 |
1 |
||||||
|
14 |
.1796 |
1 |
12 |
||||||
|
15 |
.0353 |
1 |
4 |
||||||
|
16 |
1 |
1 |
|||||||
|
Y = 1: satisfied, Y = 0: nonsatisfied; X: the UPRIMDA vector |
|||||||||
By now we have a good understanding of how important each UPRIMD-A variable is in terms of affecting overall customer satisfaction in the example. Now let us come back to the initial question of how to determine the priority of improvement among the specific quality attributes. We propose the following method:
- Determine the order of significance of each quality attribute on overall satisfaction by statistical modeling (such as the regression model and the logistic model in the example).
- Plot the coefficient of each attribute from the model ( Y -axis) against its satisfaction level ( X -axis).
- Use the plot to determine priority by
- going from top to bottom, and
- going from left to right, if the coefficients of importance have the same values.
To illustrate this method based on our example, Figure 14.4 plots the estimated logistic regression coefficients against the satisfaction level of the variable. The Y -axis represents the beta values and the X -axis represents the satisfaction level. From the plot, the order of priority for improvement is very clear: reliability, usability, availability, installability, maintainability, performance, and documentation. As this example illustrates, it is useful to use multiple methods (including scales ) to analyze customer satisfaction dataso as to understand better the relationships hidden beneath the data. This is exemplified by our seemingly contradictory findings on availability from ordinary regression and logistic regression models.
Figure 14.4. Logistic Regression Coefficients versus Satisfaction Level
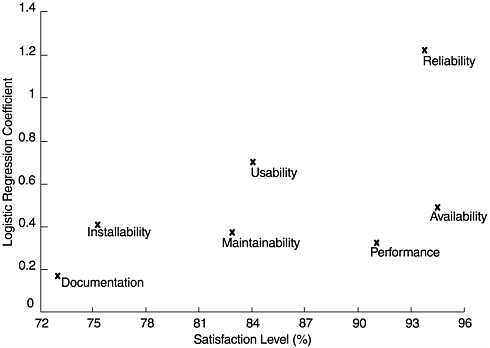
Our example focuses on the relationships between specific quality attributes and overall customer satisfaction. There are many other meaningful questions that our example does not address. For example, what are the relationships among the specific quality attributes (e.g., CUPRIMDA) in a cause-and-effect manner? What variables other than specific quality attributes, affect overall customer satisfaction? For instance, in our regression analysis, the R 2 is 52.8%. What are the factors that may explain the rest of the variations in overall satisfaction? Given the current level of overall customer satisfaction, what does it take to improve one percentage point (in terms of CUPRIMD-A and other factors)?
To seek answers to such questions, apparently a multitude of techniques is needed for analysis. Regardless of the analysis to be performed, it is always beneficial to consider issues in measurement theory, such as those discussed in Chapter 3, whenever possible.
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
