Collecting Software Engineering Data
The challenge of collecting software engineering data is to make sure that the collected data can provide useful information for project, process, and quality management and, at the same time, that the data collection process will not be a burden on development teams . Therefore, it is important to consider carefully what data to collect. The data must be based on well-defined metrics and models, which are used to drive improvements. Therefore, the goals of the data collection should be established and the questions of interest should be defined before any data is collected. Data classification schemes to be used and the level of precision must be carefully specified. The collection form or template and data fields should be pretested. The amount of data to be collected and the number of metrics to be used need not be overwhelming. It is more important that the information extracted from the data be focused, accurate, and useful than that it be plentiful. Without being metrics driven, overcollection of data could be wasteful . Overcollection of data is quite common when people start to measure software without an a priori specification of purpose, objectives, profound versus trivial issues, and metrics and models.
Gathering software engineering data can be expensive, especially if it is done as part of a research program, For example, the NASA Software Engineering Laboratory spent about 15% of their development costs on gathering and processing data on hundreds of metrics for a number of projects (Shooman, 1983). For large commercial development organizations, the relative cost of data gathering and processing should be much lower because of economy of scale and fewer metrics. However, the cost of data collection will never be insignificant. Nonetheless, data collection and analysis, which yields intelligence about the project and the development process, is vital for business success. Indeed, in many organizations, a tracking and data collection system is often an integral part of the software configuration or the project management system, without which the chance of success of large and complex projects will be reduced.
Basili and Weiss (1984) propose a data collection methodology that could be applicable anywhere . The schema consists of six steps with considerable feedback and iteration occurring at several places:
- Establish the goal of the data collection.
- Develop a list of questions of interest.
- Establish data categories.
- Design and test data collection forms.
- Collect and validate data.
- Analyze data.
The importance of the validation element of a data collection system or a development tracking system cannot be overemphasized.
In their study of NASA's Software Engineering Laboratory projects, Basili and Weiss (1984) found that software data are error-prone and that special validation provisions are generally needed. Validation should be performed concurrently with software development and data collection, based on interviews with those people supplying the data. In cases where data collection is part of the configuration control process and automated tools are available, data validation routines (e.g., consistency check, range limits, conditional entries, etc.) should be an integral part of the tools. Furthermore, training, clear guidelines and instructions, and an understanding of how the data are used by people who enter or collect the data enhance data accuracy significantly.
The actual collection process can take several basic formats such as reporting forms, interviews, and automatic collection using the computer system. For data collection to be efficient and effective, it should be merged with the configuration management or change control system. This is the case in most large development organizations. For example, at IBM Rochester the change control system covers the entire development process, and online tools are used for plan change control, development items and changes, integration, and change control after integration (defect fixes). The tools capture data pertinent to schedule, resource, and project status, as well as quality indicators. In general, change control is more prevalent after the code is integrated. This is one of the reasons that in many organizations defect data are usually available for the testing phases but not for the design and coding phases.
With regard to defect data, testing defects are generally more reliable than inspection defects. During testing, a "bug" exists when a test case cannot execute or when the test results deviate from the expected outcome. During inspections, the determination of a defect is based on the judgment of the inspectors. Therefore, it is important to have a clear definition of an inspection defect. The following is an example of such a definition:
Inspection defect: A problem found during the inspection process which, if not fixed, would cause one or more of the following to occur:
- A defect condition in a later inspection phase
- A defect condition during testing
- A field defect
- Nonconformance to requirements and specifications
- Nonconformance to established standards such as performance, national language translation, and usability
For example, misspelled words are not counted as defects, but would be if they were found on a screen that customers use. Using nested IF-THEN-ELSE structures instead of a SELECT statement would not be counted as a defect unless some standard or performance reason dictated otherwise .
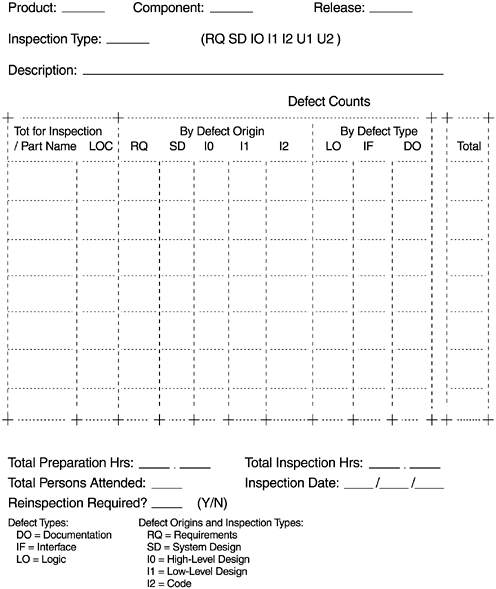
Figure 4.7 is an example of an inspection summary form. The form records the total number of inspection defects and the LOC estimate for each part (module), as well as defect data classified by defect origin and defect type. The following guideline pertains to the defect type classification by development phase:
Figure 4.7. An Inspection Summary Form
Interface defect: An interface defect is a defect in the way two separate pieces of logic communicate. These are errors in communication between:
- Components
- Products
- Modules and subroutines of a component
- User interface (e.g., messages, panels)
Examples of interface defects per development phase follow.
High-Level Design (I0)
Use of wrong parameter
Inconsistent use of function keys on user interface (e.g., screen)
Incorrect message used
Presentation of information on screen not usable
Low-Level Design (I1)
Missing required parameters (e.g., missing parameter on module)
Wrong parameters (e.g., specified incorrect parameter on module)
Intermodule interfaces: input not there, input in wrong order
Intramodule interfaces: passing values/data to subroutines
Incorrect use of common data structures
Misusing data passed to code
Code (I2)
Passing wrong values for parameters on macros, application program interfaces (APIs), modules
Setting up a common control block/area used by another piece of code incorrectly
Not issuing correct exception to caller of code
Logic defect: A logic defect is one that would cause incorrect results in the function to be performed by the logic. High-level categories of this type of defect are as follows :
Function: capability not implemented or implemented incorrectly
Assignment: initialization
Checking: validate data/values before use
Timing: management of shared/real-time resources
Data Structures: static and dynamic definition of data
Examples of logic defects per development phase follow.
High-Level Design (I0)
Invalid or incorrect screen flow
High-level flow through component missing or incorrect in the review package
Function missing from macros you are implementing
Using a wrong macro to do a function that will not work (e.g., using XXXMSG to receive a message from a program message queue, instead of YYYMSG).
Missing requirements
Missing parameter/field on command/in database structure/on screen you are implementing
Wrong value on keyword (e.g., macro, command)
Wrong keyword (e.g., macro, command)
Low-Level Design (I1)
Logic does not implement I0 design
Missing or excessive function
Values in common structure not set
Propagation of authority and adoption of authority (lack of or too much)
Lack of code page conversion
Incorrect initialization
Not handling abnormal termination (conditions, cleanup, exit routines)
Lack of normal termination cleanup
Performance: too much processing in loop that could be moved outside of loop
Code (I2)
Code does not implement I1 design
Lack of initialization
Variables initialized incorrectly
Missing exception monitors
Exception monitors in wrong order
Exception monitors not active
Exception monitors active at the wrong time
Exception monitors set up wrong
Truncating of double-byte character set data incorrectly (e.g., truncating before shift in character)
Incorrect code page conversion
Lack of code page conversion
Not handling exceptions/return codes correctly
Documentation defect: A documentation defect is a defect in the description of the function (e.g., prologue of macro) that causes someone to do something wrong based on this information. For example, if a macro prologue contained an incorrect description of a parameter that caused the user of this macro to use the parameter incorrectly, this would be a documentation defect against the macro.
Examples of documentation defects per development phase follow.
High-Level Design (I0)
Incorrect information in prologue (e.g., macro)
Misspelling on user interface (e.g., screen)
Wrong wording (e.g., messages, command prompt text)
Using restricted words on user interface
Wording in messages, definition of command parameters is technically incorrect
Low-Level Design (I1)
Wrong information in prologue (e.g., macros, program, etc.)
Missing definition of inputs and outputs of module, subroutines, etc.
Insufficient documentation of logic (comments tell what but not why)
Code (I2)
Information in prologue not correct or missing
Wrong wording in messages
Second-level text of message technically incorrect
Insufficient documentation of logic (comments tell what but not why)
Incorrect documentation of logic
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
