Software Quality Engineering Modeling
Software quality engineering, in particular software quality modeling, is a relatively new field for research and application. In this book we discuss four types of software quality models: reliability and projection models, quality management models, complexity metrics and models, and customer-oriented metrics, measurements, and models. A list of the models follows .
- Reliability and projection models
- Rayleigh model
- Exponential model
- Weibull distribution with different shape parameters
- Reliability growth models that were developed specifically for software
- The polynomial regression models for defect arrivals and backlog projections
- Quality management models
- The Rayleigh model framework for quality management The phase-based defect removal model and defect removal effectiveness
- The code integration pattern metric or heuristic model
- The defect arrival (PTR) nonparametric (heuristic) model
- The polynomial regression models for defect arrivals and backlog projections
- Use of reliability models to set targets for the current project
- The models for spreading the total projected field defects over time for maintenance planning (heuristic or using the reliability models)
- Statistical models on customer satisfaction analysis
- The effort/outcome model for establishing in-process metrics and for assessing in-process quality status
- Other tools, metrics, and techniques
- Complexity metrics and models
- Analysis and statistical models linking complexity metrics, syntactic constructs, structure metrics, and other variables to quality
- Analysis and statistical models linking the object-oriented design and complexity metrics to quality and managerial variables
- Customer-oriented metrics, measurements, and models
- System availability and outage metrics
- Methods and models to measure and analyze customer satisfaction
There is a tremendous amount of literature on customer satisfaction. The scope of customer satisfaction research and analysis goes beyond the discipline of software engineering. Therefore, in the following discussions, we confine our attention to the first three types of model.
Of the first three types of model, reliability and projection models are more advanced than the other two. Quality management models are perhaps still in their early maturity phase. It is safe to say that in spite of a good deal of progress in the past decade , none of the three types of models has reached the mature stage. The need for improvement will surely intensify in the future as software plays an increasingly critical role in modern society and quality has been brought to the center of the development process. Software projects need to be developed in a much more effective way with much better quality.
Note that the three types of model are developed and studied by different groups of professionals. Software reliability models are developed by reliability experts who were trained in mathematics, statistics, and operations research; complexity models and metrics are studied by computer scientists. The different origins explain why the former tends to take a black-box approach (monitoring and describing the behavior of the software from an external viewpoint) and the latter tends to take a white-box approach (looking into the internal relationships revolving around the central issue of complexity). Quality management models emerged from the practical needs of managing software development projects and draw on principles and knowledge in the field of quality engineering (traditionally being practiced in manufacturing and production operations). For software quality engineering to become mature, an interdisciplinary effort to combine and merge the various approaches is needed. A systematic body of knowledge in software quality engineering should encompass seamless links among the internal structure of design and implementation, the external behavior of the software system, and the logistics and management of the development project.
From the standpoint of the software industry, perhaps the most urgent challenge is to bridge the gap between state of the art and state of practice. On the one hand, better training in software engineering in general, and metrics and models in particular, needs to be incorporated into the curriculum for computer science and software engineering. Some universities and colleges are taking the lead in this regard; however, much more needs to be done and at a faster pace. Developers need not become experts in measurement theory, failure analysis, or other statistical techniques. However, they need to understand the quality principles, the impact of various development practices on the software's quality and reliability, and the findings accumulated over the years in terms of effective software engineering. Now that software is playing a more and more significant role in all institutions of our society, such training is very important. Indeed, the impact of poor software quality has been the subject of news headlines.
On the other hand, this gap poses a challenge for academicians and researchers in metrics and modeling. Many models, especially the reliability models, are expressed in sophisticated mathematical notations and formulas that are difficult to understand. To facilitate practices by the software industry, models, concepts, and algorithms for implementation need to be communicated to the software community (managers, software engineers , designers, testers, quality professionals) in their language. The model assumptions need to be clarified; the robustness of the model needs to be investigated and presented when some assumptions are not met; and much more applied research using industry data needs to be done.
With regard to the state of the art in reliability models, it appears that the fault count models give more satisfactory results than the time between failures models. In addition, the fault count models are usually used for commercial projects where the estimation precision required is not as stringent. In contrast, for safety-critical systems, precise and accurate predictions of the time of the next software failure is necessary. Thus, the time between failures software reliability models are largely unsuccessful . Furthermore, the validity of reliability models depends on the size of the software. The models are suitable for large-size software; small- size software may make some models nonsensical . For small projects, sometimes it is better to use simple methods such as the test effectiveness example (simple ratio method) discussed in the previous section, or a simple regression model.
A common feature of the existing software reliability models is the probability assumption. Researchers have challenged this assumption in software reliability (Cai et al., 1991). For the probability assumption to hold, three conditions must be satisfied: (1) The event is defined precisely, (2) a large number of samples is available, and (3) sample data must be repetitive in the probability sense. Cai and associates (1991) observed that software reliability behavior is fuzzy in nature and cannot be precisely defined: Reliability is workload dependent; test case execution and applications of various testing strategies are time variant; software complexity is defined in a number of ways; human intervention in the testing/debugging process is extremely complex; failure data are sometimes hard to specify; and so forth.
Furthermore, software is unique; a software debugging process is never replicated. Therefore, Cai and associates contend that the probability assumption is not met and that is why software reliability models are largely unsuccessful. They strongly advise that fuzzy software reliability models, based on fuzzy set methodologies, be developed and used. Hopefully, this line of reasoning will shed light on the research of software reliability models.
Another technology that could be valuable in quality modeling and projection is the reemerging neural network computing technology. Based loosely on biological neural networks, a neural network computer system consists of many simple processors and many adaptive connections between the processors. Through inputs and outputs, the network learns mapping of inputs to outputs by performing mathematical functions and adjusting weight values. Once trained, the network can produce good outputs given new inputs. Different from expert systems, which are expertise based (i.e., from a set of inference rules), neural networks are data based. Neural network systems can be thought of as pattern recognition machines, which are especially useful where fuzzy logic is important. In the past decade, applications of neural networks have begun in areas such as diagnosis, forecasting, inventory control, risk analysis, process control, scheduling, and so forth. Several neural network program products are also available in the commercial market.
For software quality and reliability, neural networks could be used to link various in-process indicators to the field performance of the final product. As such, neural networks can be regarded as machines for automatic empirical modeling. However, as mentioned, to use this approach, large samples with good quality data must be available. Therefore, it seems that until measurements become engrained in practice, the software industry may not be able to take good advantage of this technology. When neural network systems are in use, quality engineers or process experts must also retain intellectual control of the models produced by the networks, discern spurious relationships from the genuine ones, interpret the results, and, based on the results, plan for improvements.
In the meantime, for a software development organization to choose its models, the criteria for model evaluation discussed in Chapters 7 through 12 can serve as guidelines. Moreover, experience indicates that it is of utmost importance to establish the empirical validity of the models based on historical data relative to the organization and its development process. Once the empirical validity of the models is established, the chance for satisfactory results is significantly enhanced. At times, calibration of the model or the projection may be needed. Furthermore, it is good practice to use more than one model. For reliability assessment, cross-model reliability can be examined. In fact, research in reliability growth models indicates that combining the results of individual models may give more accurate predictions (Lyu and Nikora, 1992). For quality management, the multiple-model approach can increase the likelihood of achieving the criteria of timeliness of indication, scope of coverage, and capability.
Empirical validity may become the common ground to bridge the different modeling approaches and a promising path for the advancement of software quality engineering modeling. Empirical validity refers to situations in which the predictive validity and the capability ( usefulness ) of the model is supported by empirical data of the organization, or the models are based on theoretical underpinnings and empirical relationships derived from the organization's history. Good models ought to have theoretical backings and at the same time should be relevant to actual experience. Many of the quality management models we discussed are substantiated by empirical validity, and some of them were developed based on our experience with commercial projects. For complexity and design metrics, the relationships are based on empirical statistical models (e.g., multiple regressions). There is also a recognition that the direction of complexity metrics research (including the object-oriented metrics) is to conduct more empirical validation studies, and to correlate these metrics to the managerial variables (e.g., quality improvement, productivity, project management).
In software reliability modeling, it is long recognized that some models sometimes give good results, some are almost universally awful , and none can be trusted to be accurate at all times. I contend that the reason behind this phenomenon is empirical validity, or the lack of it. Note that empirical validity may vary across organizations, processes, and types of software. It is therefore important for an organization to pick and choose the right models to use. Recent software reliability research on the Bayesian approach (Fenton and Neil, 1999; Neil et al., 2000) and on improving reliability prediction by incorporating information from a similar project (Xie et al., 1999; Xie and Hong, 1998) indicates that empirical validity is receiving attention among software reliability researchers.
Finally, in our discussions of the quality management models, there is the Rayleigh model, or a discrete phase-based model as the overall framework of the entire development process. Within this framework, we discussed specific models and metrics to cover the major phases of development. Our objective is to build links among these models and metrics so the project's quality can be engineered from the early stages. Because not all of these models are "parametric," we again rely on the heuristic linkages. Figure 19.1 shows an example of the linkages among the code integration pattern, the test plan S curve, and the testing defect arrival model. Based on the empirical relationships observed among the several patterns, once the planned code integration pattern is available, which is early in the development cycle, we would be able to determine the position of the test S curve and the testing defect arrival model in the time line in terms of number of weeks prior to product ship. An early outlook of the quality of the project can then be derived: the higher the inter-secting point between the projected defect arrival curve and the vertical line at product ship, the worse the quality of the project will be, and vice versa. Then the team can engineer improvement actions throughout the development cycle to improve the quality outlook. When the project progresses along the development cycle and more information becomes available, the models and their linkages can be updated periodically. For examples:
Figure 19.1. Linkages Among Several Models and Metrics for Early Quality Planning
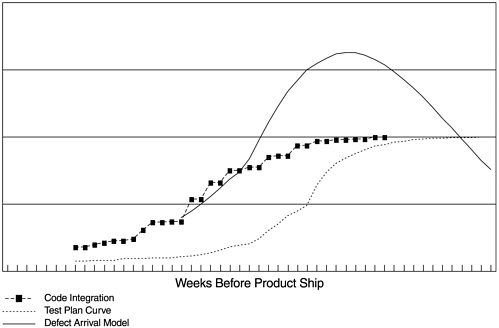
- When design and code development are being completed, their quality can be assessed via the design reviews/code inspections in-process metrics or data from the inspection scoring checklist. If the quality of the design and code is assessed to be better than the baseline project, then the area under the projected testing defect arrival curve can be adjusted to be smaller, and vice versa.
- When the actual code integration takes place over time, the pattern may shift and so may the testing pattern and the defect arrival pattern.
- The actual test progress status again will affect the defect arrival pattern.
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
- ERP Systems Impact on Organizations
- ERP System Acquisition: A Process Model and Results From an Austrian Survey
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Healthcare Information: From Administrative to Practice Databases
