Product Quality Metrics
As discussed in Chapter 1, the de facto definition of software quality consists of two levels: intrinsic product quality and customer satisfaction. The metrics we discuss here cover both levels:
- Mean time to failure
- Defect density
- Customer problems
- Customer satisfaction.
Intrinsic product quality is usually measured by the number of " bugs " (functional defects) in the software or by how long the software can run before encountering a "crash." In operational definitions, the two metrics are defect density (rate) and mean time to failure (MTTF). The MTTF metric is most often used with safety-critical systems such as the airline traffic control systems, avionics , and weapons. For instance, the U.S. government mandates that its air traffic control system cannot be unavailable for more than three seconds per year. In civilian airliners, the probability of certain catastrophic failures must be no worse than 10 -9 per hour (Littlewood and Strigini, 1992). The defect density metric, in contrast, is used in many commercial software systems.
The two metrics are correlated but are different enough to merit close attention. First, one measures the time between failures, the other measures the defects relative to the software size (lines of code, function points, etc.). Second, although it is difficult to separate defects and failures in actual measurements and data tracking, failures and defects (or faults) have different meanings. According to the IEEE/ American National Standards Institute (ANSI) standard (982.2):
- An error is a human mistake that results in incorrect software.
- The resulting fault is an accidental condition that causes a unit of the system to fail to function as required.
- A defect is an anomaly in a product.
- A failure occurs when a functional unit of a software- related system can no longer perform its required function or cannot perform it within specified limits.
From these definitions, the difference between a fault and a defect is unclear. For practical purposes, there is no difference between the two terms. Indeed, in many development organizations the two terms are used synonymously. In this book we also use the two terms interchangeably.
Simply put, when an error occurs during the development process, a fault or a defect is injected in the software. In operational mode, failures are caused by faults or defects, or failures are materializations of faults. Sometimes a fault causes more than one failure situation and, on the other hand, some faults do not materialize until the software has been executed for a long time with some particular scenarios. Therefore, defect and failure do not have a one-to-one correspondence.
Third, the defects that cause higher failure rates are usually discovered and removed early. The probability of failure associated with a latent defect is called its size, or "bug size." For special-purpose software systems such as the air traffic control systems or the space shuttle control systems, the operations profile and scenarios are better defined and, therefore, the time to failure metric is appropriate. For general-purpose computer systems or commercial-use software, for which there is no typical user profile of the software, the MTTF metric is more difficult to implement and may not be representative of all customers.
Fourth, gathering data about time between failures is very expensive. It requires recording the occurrence time of each software failure. It is sometimes quite difficult to record the time for all the failures observed during testing or operation. To be useful, time between failures data also requires a high degree of accuracy. This is perhaps the reason the MTTF metric is not widely used by commercial developers.
Finally, the defect rate metric (or the volume of defects) has another appeal to commercial software development organizations. The defect rate of a product or the expected number of defects over a certain time period is important for cost and resource estimates of the maintenance phase of the software life cycle.
Regardless of their differences and similarities, MTTF and defect density are the two key metrics for intrinsic product quality. Accordingly, there are two main types of software reliability growth models ”the time between failures models and the defect count (defect rate) models. We discuss the two types of models and provide several examples of each type in Chapter 8.
4.1.1 The Defect Density Metric
Although seemingly straightforward, comparing the defect rates of software products involves many issues. In this section we try to articulate the major points. To define a rate, we first have to operationalize the numerator and the denominator, and specify the time frame. As discussed in Chapter 3, the general concept of defect rate is the number of defects over the opportunities for error (OFE) during a specific time frame. We have just discussed the definitions of software defect and failure. Because failures are defects materialized, we can use the number of unique causes of observed failures to approximate the number of defects in the software. The denominator is the size of the software, usually expressed in thousand lines of code (KLOC) or in the number of function points. In terms of time frames , various operational definitions are used for the life of product (LOP), ranging from one year to many years after the software product's release to the general market. In our experience with operating systems, usually more than 95% of the defects are found within four years of the software's release. For application software, most defects are normally found within two years of its release.
Lines of Code
The lines of code (LOC) metric is anything but simple. The major problem comes from the ambiguity of the operational definition, the actual counting. In the early days of Assembler programming, in which one physical line was the same as one instruction, the LOC definition was clear. With the availability of high-level languages the one-to-one correspondence broke down. Differences between physical lines and instruction statements (or logical lines of code) and differences among languages contribute to the huge variations in counting LOCs. Even within the same language, the methods and algorithms used by different counting tools can cause significant differences in the final counts. Jones (1986) describes several variations:
- Count only executable lines.
- Count executable lines plus data definitions.
- Count executable lines, data definitions, and comments.
- Count executable lines, data definitions, comments, and job control language.
- Count lines as physical lines on an input screen.
- Count lines as terminated by logical delimiters.
To illustrate the variations in LOC count practices, let us look at a few examples by authors of software metrics. In Boehm's well-known book Software Engineering Economics (1981), the LOC counting method counts lines as physical lines and includes executable lines, data definitions, and comments. In Software Engineering Metrics and Models by Conte et al. (1986), LOC is defined as follows :
A line of code is any line of program text that is not a comment or blank line, regardless of the number of statements or fragments of statements on the line. This specifically includes all lines containing program headers, declarations, and executable and non-executable statements. (p. 35)
Thus their method is to count physical lines including prologues and data definitions (declarations) but not comments. In Programming Productivity by Jones (1986), the source instruction (or logical lines of code) method is used. The method used by IBM Rochester is also to count source instructions including executable lines and data definitions but excluding comments and program prologues.
The resultant differences in program size between counting physical lines and counting instruction statements are difficult to assess. It is not even known which method will result in a larger number. In some languages such as BASIC, PASCAL, and C, several instruction statements can be entered on one physical line. On the other hand, instruction statements and data declarations might span several physical lines, especially when the programming style aims for easy maintenance, which is not necessarily done by the original code owner. Languages that have a fixed column format such as FORTRAN may have the physical-lines-to-source-instructions ratio closest to one. According to Jones (1992), the difference between counts of physical lines and counts including instruction statements can be as large as 500%; and the average difference is about 200%, with logical statements outnumbering physical lines. In contrast, for COBOL the difference is about 200% in the opposite direction, with physical lines outnumbering instruction statements.
There are strengths and weaknesses of physical LOC and logical LOC (Jones, 2000). In general, logical statements are a somewhat more rational choice for quality data. When any data on size of program products and their quality are presented, the method for LOC counting should be described. At the minimum, in any publication of quality when LOC data is involved, the author should state whether the LOC counting method is based on physical LOC or logical LOC.
Furthermore, as discussed in Chapter 3, some companies may use the straight LOC count (whatever LOC counting method is used) as the denominator for calculating defect rate, whereas others may use the normalized count (normalized to Assembler-equivalent LOC based on some conversion ratios) for the denominator. Therefore, industrywide standards should include the conversion ratios from high-level language to Assembler. So far, very little research on this topic has been published. The conversion ratios published by Jones (1986) are the most well known in the industry. As more and more high-level languages become available for software development, more research will be needed in this area.
When straight LOC count data is used, size and defect rate comparisons across languages are often invalid. Extreme caution should be exercised when comparing the defect rates of two products if the operational definitions (counting) of LOC, defects, and time frame are not identical. Indeed, we do not recommend such comparisons. We recommend comparison against one's own history for the sake of measuring improvement over time.
Note: The LOC discussions in this section are in the context of defect rate calculation. For productivity studies, the problems with using LOC are more severe. A basic problem is that the amount of LOC in a softare program is negatively correlated with design efficiency. The purpose of software is to provide certain functionality for solving some specific problems or to perform certain tasks . Efficient design provides the functionality with lower implementation effort and fewer LOCs. Therefore, using LOC data to measure software productivity is like using the weight of an airplane to measure its speed and capability. In addition to the level of languages issue, LOC data do not reflect noncoding work such as the creation of requirements, specifications, and user manuals. The LOC results are so misleading in productivity studies that Jones states "using lines of code for productivity studies involving multiple languages and full life cycle activities should be viewed as professional malpractice" (2000, p. 72). For detailed discussions of LOC and function point metrics, see Jones's work (1986, 1992, 1994, 1997, 2000).
When a software product is released to the market for the first time, and when a certain LOC count method is specified, it is relatively easy to state its quality level ( projected or actual). For example, statements such as the following can be made: "This product has a total of 50 KLOC; the latent defect rate for this product during the next four years is 2.0 defects per KLOC." However, when enhancements are made and subsequent versions of the product are released, the situation becomes more complicated. One needs to measure the quality of the entire product as well as the portion of the product that is new. The latter is the measurement of true development quality ”the defect rate of the new and changed code. Although the defect rate for the entire product will improve from release to release due to aging, the defect rate of the new and changed code will not improve unless there is real improvement in the development process. To calculate defect rate for the new and changed code, the following must be available:
- LOC count: The entire software product as well as the new and changed code of the release must be available.
- Defect tracking: Defects must be tracked to the release origin ”the portion of the code that contains the defects and at what release the portion was added, changed, or enhanced. When calculating the defect rate of the entire product, all defects are used; when calculating the defect rate for the new and changed code, only defects of the release origin of the new and changed code are included.
These tasks are enabled by the practice of change flagging. Specifically, when a new function is added or an enhancement is made to an existing function, the new and changed lines of code are flagged with a specific identification (ID) number through the use of comments. The ID is linked to the requirements number, which is usually described briefly in the module's prologue. Therefore, any changes in the program modules can be linked to a certain requirement. This linkage procedure is part of the software configuration management mechanism and is usually practiced by organizations that have an established process. If the change-flagging IDs and requirements IDs are further linked to the release number of the product, the LOC counting tools can use the linkages to count the new and changed code in new releases. The change-flagging practice is also important to the developers who deal with problem determination and maintenance. When a defect is reported and the fault zone determined, the developer can determine in which function or enhancement pertaining to what requirements at what release origin the defect was injected.
The new and changed LOC counts can also be obtained via the delta-library method. By comparing program modules in the original library with the new versions in the current release library, the LOC count tools can determine the amount of new and changed code for the new release. This method does not involve the change-flagging method. However, change flagging remains very important for maintenance. In many software development environments, tools for automatic change flagging are also available.
Example: Lines of Code Defect Rates
At IBM Rochester, lines of code data is based on instruction statements (logical LOC) and includes executable code and data definitions but excludes comments. LOC counts are obtained for the total product and for the new and changed code of the new release. Because the LOC count is based on source instructions, the two size metrics are called shipped source instructions ( SSI ) and new and changed source instructions ( CSI ), respectively. The relationship between the SSI count and the CSI count can be expressed with the following formula:

Defects after the release of the product are tracked. Defects can be field defects, which are found by customers, or internal defects, which are found internally. The several postrelease defect rate metrics per thousand SSI (KSSI) or per thousand CSI (KCSI) are:
(1) Total defects per KSSI (a measure of code quality of the total product)
(2) Field defects per KSSI (a measure of defect rate in the field)
(3) Release-origin defects (field and internal) per KCSI (a measure of development quality)
(4) Release-origin field defects per KCSI (a measure of development quality per defects found by customers)
Metric (1) measures the total release code quality, and metric (3) measures the quality of the new and changed code. For the initial release where the entire product is new, the two metrics are the same. Thereafter, metric (1) is affected by aging and the improvement (or deterioration) of metric (3). Metrics (1) and (3) are process measures; their field counterparts, metrics (2) and (4) represent the customer's perspective. Given an estimated defect rate (KCSI or KSSI), software developers can minimize the impact to customers by finding and fixing the defects before customers encounter them.
Customer's Perspective
The defect rate metrics measure code quality per unit. It is useful to drive quality improvement from the development team's point of view. Good practice in software quality engineering, however, also needs to consider the customer's perspective. Assume that we are to set the defect rate goal for release-to-release improvement of one product. From the customer's point of view, the defect rate is not as relevant as the total number of defects that might affect their business. Therefore, a good defect rate target should lead to a release-to-release reduction in the total number of defects, regardless of size. If a new release is larger than its predecessors, it means the defect rate goal for the new and changed code has to be significantly better than that of the previous release in order to reduce the total number of defects.
Consider the following hypothetical example:
Initial Release of Product Y
KCSI = KSSI = 50 KLOC
Defects/KCSI = 2.0
Total number of defects = 2.0 x 50 = 100
Second Release
KCSI = 20
KSSI = 50 + 20 (new and changed lines of code) - 4 ( assuming 20% are changed
lines of code ) = 66
Defect/KCSI = 1.8 (assuming 10% improvement over the first release)
Total number of additional defects = 1.8 x 20 = 36
Third Release
KCSI = 30
KSSI = 66 + 30 (new and changed lines of code) - 6 (assuming the same % (20%)
of changed lines of code) = 90
Targeted number of additional defects (no more than previous release) = 36
Defect rate target for the new and changed lines of code: 36/30 = 1.2 defects/KCSI
or lower
From the initial release to the second release the defect rate improved by 10%. However, customers experienced a 64% reduction [(100 - 36)/100] in the number of defects because the second release is smaller. The size factor works against the third release because it is much larger than the second release. Its defect rate has to be one-third (1.2/1.8) better than that of the second release for the number of new defects not to exceed that of the second release. Of course, sometimes the difference between the two defect rate targets is very large and the new defect rate target is deemed not achievable. In those situations, other actions should be planned to improve the quality of the base code or to reduce the volume of postrelease field defects (i.e., by finding them internally).
Function Points
Counting lines of code is but one way to measure size. Another one is the function point . Both are surrogate indicators of the opportunities for error (OFE) in the defect density metrics. In recent years the function point has been gaining acceptance in application development in terms of both productivity (e.g., function points per person-year) and quality (e.g., defects per function point). In this section we provide a concise summary of the subject.
A function can be defined as a collection of executable statements that performs a certain task, together with declarations of the formal parameters and local variables manipulated by those statements (Conte et al., 1986). The ultimate measure of software productivity is the number of functions a development team can produce given a certain amount of resource, regardless of the size of the software in lines of code. The defect rate metric, ideally , is indexed to the number of functions a software provides. If defects per unit of functions is low, then the software should have better quality even though the defects per KLOC value could be higher ”when the functions were implemented by fewer lines of code. However, measuring functions is theoretically promising but realistically very difficult.
The function point metric, originated by Albrecht and his colleagues at IBM in the mid-1970s, however, is something of a misnomer because the technique does not measure functions explicitly (Albrecht, 1979). It does address some of the problems associated with LOC counts in size and productivity measures, especially the differences in LOC counts that result because different levels of languages are used. It is a weighted total of five major components that comprise an application:
- Number of external inputs (e.g., transaction types) x 4
- Number of external outputs (e.g., report types) x 5
- Number of logical internal files (files as the user might conceive them, not physical files) x 10
- Number of external interface files (files accessed by the application but not maintained by it) x 7
- Number of external inquiries (types of online inquiries supported) x 4
These are the average weighting factors. There are also low and high weighting factors, depending on the complexity assessment of the application in terms of the five components (Kemerer and Porter, 1992; Sprouls, 1990):
- External input: low complexity, 3; high complexity, 6
- External output: low complexity, 4; high complexity, 7
- Logical internal file: low complexity, 7; high complexity, 15
- External interface file: low complexity, 5; high complexity, 10
- External inquiry: low complexity, 3; high complexity, 6
The complexity classification of each component is based on a set of standards that define complexity in terms of objective guidelines. For instance, for the external output component, if the number of data element types is 20 or more and the number of file types referenced is 2 or more, then complexity is high. If the number of data element types is 5 or fewer and the number of file types referenced is 2 or 3, then complexity is low.
With the weighting factors, the first step is to calculate the function counts (FCs) based on the following formula:
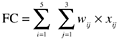
where w ij are the weighting factors of the five components by complexity level (low, average, high) and x ij are the numbers of each component in the application.
The second step involves a scale from 0 to 5 to assess the impact of 14 general system characteristics in terms of their likely effect on the application. The 14 characteristics are:
- Data communications
- Distributed functions
- Performance
- Heavily used configuration
- Transaction rate
- Online data entry
- End-user efficiency
- Online update
- Complex processing
- Reusability
- Installation ease
- Operational ease
- Multiple sites
- Facilitation of change
The scores (ranging from 0 to 5) for these characteristics are then summed, based on the following formula, to arrive at the value adjustment factor (VAF)
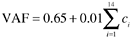
where c i is the score for general system characteristic i . Finally, the number of function points is obtained by multiplying function counts and the value adjustment factor:
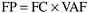
This equation is a simplified description of the calculation of function points. One should consult the fully documented methods, such as the International Function Point User's Group Standard (IFPUG, 1999), for a complete treatment.
Over the years the function point metric has gained acceptance as a key productivity measure in the application world. In 1986 the IFPUG was established. The IFPUG counting practices committee is the de facto standards organization for function point counting methods (Jones, 1992, 2000). Classes and seminars on function points counting and applications are offered frequently by consulting firms and at software conferences. In application contract work, the function point is often used to measure the amount of work, and quality is expressed as defects per function point. In systems and real-time software, however, the function point has been slow to gain acceptance. This is perhaps due to the incorrect impression that function points work only for information systems (Jones, 2000), the inertia of the LOC-related practices, and the effort required for function points counting. Intriguingly, similar observations can be made about function point use in academic research.
There are also issues related to the function point metric. Fundamentally, the meaning of function point and the derivation algorithm and its rationale may need more research and more theoretical groundwork . There are also many variations in counting function points in the industry and several major methods other than the IFPUG standard. In 1983, Symons presented a function point variant that he termed the Mark II function point (Symons, 1991). According to Jones (2000), the Mark II function point is now widely used in the United Kingdom and to a lesser degree in Hong Kong and Canada. Some of the minor function point variants include feature points, 3D function points, and full function points. In all, based on the comprehensive software benchmark work by Jones (2000), the set of function point variants now include at least 25 functional metrics. Function point counting can be time-consuming and expensive, and accurate counting requires certified function point specialists. Nonetheless, function point metrics are apparently more robust than LOC-based data with regard to comparisons across organizations, especially studies involving multiple languages and those for productivity evaluation.
Example: Function Point Defect Rates
In 2000, based on a large body of empirical studies, Jones published the book Software Assessments, Benchmarks, and Best Practices . All metrics used throughout the book are based on function points. According to his study (1997), the average number of software defects in the U.S. is approximately 5 per function point during the entire software life cycle. This number represents the total number of defects found and measured from early software requirements throughout the life cycle of the software, including the defects reported by users in the field. Jones also estimates the defect removal efficiency of software organizations by level of the capability maturity model (CMM) developed by the Software Engineering Institute (SEI). By applying the defect removal efficiency to the overall defect rate per function point, the following defect rates for the delivered software were estimated. The time frames for these defect rates were not specified, but it appears that these defect rates are for the maintenance life of the software. The estimated defect rates per function point are as follows:
- SEI CMM Level 1: 0.75
- SEI CMM Level 2: 0.44
- SEI CMM Level 3: 0.27
- SEI CMM Level 4: 0.14
- SEI CMM Level 5: 0.05
4.1.2 Customer Problems Metric
Another product quality metric used by major developers in the software industry measures the problems customers encounter when using the product. For the defect rate metric, the numerator is the number of valid defects. However, from the customers' standpoint, all problems they encounter while using the software product, not just the valid defects, are problems with the software. Problems that are not valid defects may be usability problems, unclear documentation or information, duplicates of valid defects (defects that were reported by other customers and fixes were available but the current customers did not know of them), or even user errors. These so-called non-defect-oriented problems, together with the defect problems, constitute the total problem space of the software from the customers' perspective.
The problems metric is usually expressed in terms of problems per user month (PUM):

where
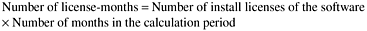
PUM is usually calculated for each month after the software is released to the market, and also for monthly averages by year. Note that the denominator is the number of license-months instead of thousand lines of code or function point, and the numerator is all problems customers encountered . Basically, this metric relates problems to usage. Approaches to achieve a low PUM include:
- Improve the development process and reduce the product defects.
- Reduce the non-defect-oriented problems by improving all aspects of the products (such as usability, documentation), customer education, and support.
- Increase the sale (the number of installed licenses) of the product.
The first two approaches reduce the numerator of the PUM metric, and the third increases the denominator. The result of any of these courses of action will be that the PUM metric has a lower value. All three approaches make good sense for quality improvement and business goals for any organization. The PUM metric, therefore, is a good metric. The only minor drawback is that when the business is in excellent condition and the number of software licenses is rapidly increasing, the PUM metric will look extraordinarily good (low value) and, hence, the need to continue to reduce the number of customers' problems (the numerator of the metric) may be undermined. Therefore, the total number of customer problems should also be monitored and aggressive year-to-year or release-to-release improvement goals set as the number of installed licenses increases . However, unlike valid code defects, customer problems are not totally under the control of the software development organization. Therefore, it may not be feasible to set a PUM goal that the total customer problems cannot increase from release to release, especially when the sales of the software are increasing.
The key points of the defect rate metric and the customer problems metric are briefly summarized in Table 4.1. The two metrics represent two perspectives of product quality. For each metric the numerator and denominator match each other well: Defects relate to source instructions or the number of function points, and problems relate to usage of the product. If the numerator and denominator are mixed up, poor metrics will result. Such metrics could be counterproductive to an organization's quality improvement effort because they will cause confusion and wasted resources.
The customer problems metric can be regarded as an intermediate measurement between defects measurement and customer satisfaction. To reduce customer problems, one has to reduce the functional defects in the products and, in addition, improve other factors (usability, documentation, problem rediscovery, etc.). To improve customer satisfaction, one has to reduce defects and overall problems and, in addition, manage factors of broader scope such as timing and availability of the product, company image, services, total customer solutions, and so forth. From the software quality standpoint, the relationship of the scopes of the three metrics can be represented by the Venn diagram in Figure 4.1.
Figure 4.1. Scopes of Three Quality Metrics
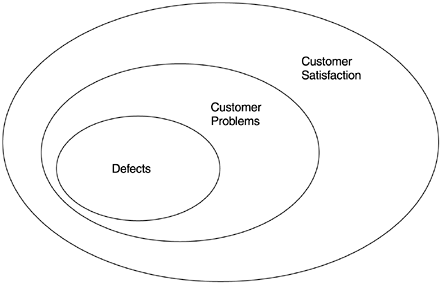
Table 4.1. Defect Rate and Customer Problems Metrics
|
Defect Rate |
Problems per User-Month (PUM) |
|
|---|---|---|
|
Numerator |
Valid and unique product defects |
All customer problems (defects and nondefects, first time and repeated) |
|
Denominator |
Size of product (KLOC or function point) |
Customer usage of the product (user-months) |
|
Measurement |
perspective Producer ”software development organization |
Customer |
|
Scope |
Intrinsic product quality |
Intrinsic product quality plus other factors |
4.1.3 Customer Satisfaction Metrics
Customer satisfaction is often measured by customer survey data via the five-point scale:
- Very satisfied
- Satisfied
- Neutral
- Dissatisfied
- Very dissatisfied.
Satisfaction with the overall quality of the product and its specific dimensions is usually obtained through various methods of customer surveys. For example, the specific parameters of customer satisfaction in software monitored by IBM include the CUPRIMDSO categories (capability, functionality, usability, performance, reliability, installability , maintainability, documentation/information, service, and overall); for Hewlett-Packard they are FURPS (functionality, usability, reliability, performance, and service).
Based on the five-point-scale data, several metrics with slight variations can be constructed and used, depending on the purpose of analysis. For example:
(1) Percent of completely satisfied customers
(2) Percent of satisfied customers (satisfied and completely satisfied)
(3) Percent of dissatisfied customers (dissatisfied and completely dissatisfied)
(4) Percent of nonsatisfied (neutral, dissatisfied, and completely dissatisfied)
Usually the second metric, percent satisfaction, is used. In practices that focus on reducing the percentage of nonsatisfaction, much like reducing product defects, metric (4) is used.
In addition to forming percentages for various satisfaction or dissatisfaction categories, the weighted index approach can be used. For instance, some companies use the net satisfaction index ( NSI ) to facilitate comparisons across product. The NSI has the following weighting factors:
- Completely satisfied = 100%
- Satisfied = 75%
- Neutral = 50%
- Dissatisfied = 25%
- Completely dissatisfied = 0%
NSI ranges from 0% (all customers are completely dissatisfied) to 100% (all customers are completely satisfied). If all customers are satisfied (but not completely satisfied), NSI will have a value of 75%. This weighting approach, however, may be masking the satisfaction profile of one's customer set. For example, if half of the customers are completely satisfied and half are neutral, NSI's value is also 75%, which is equivalent to the scenario that all customers are satisfied. If satisfaction is a good indicator of product loyalty, then half completely satisfied and half neutral is certainly less positive than all satisfied. Furthermore, we are not sure of the rationale behind giving a 25% weight to those who are dissatisfied. Therefore, this example of NSI is not a good metric; it is inferior to the simple approach of calculating percentage of specific categories. If the entire satisfaction profile is desired, one can simply show the percent distribution of all categories via a histogram. A weighted index is for data summary when multiple indicators are too cumbersome to be shown. For example, if customers' purchase decisions can be expressed as a function of their satisfaction with specific dimensions of a product, then a purchase decision index could be useful. In contrast, if simple indicators can do the job, then the weighted index approach should be avoided.
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
