Reliability and Validity
Recall that concepts and definitions have to be operationally defined before measurements can be taken. Assuming operational definitions are derived and measurements are taken, the logical question to ask is, how good are the operational metrics and the measurement data? Do they really accomplish their task ”measuring the concept that we want to measure and doing so with good quality? Of the many criteria of measurement quality, reliability and validity are the two most important.
Reliability refers to the consistency of a number of measurements taken using the same measurement method on the same subject. If repeated measurements are highly consistent or even identical, then the measurement method or the operational definition has a high degree of reliability. If the variations among repeated measurements are large, then reliability is low. For example, if an operational definition of a body height measurement of children (e.g., between ages 3 and 12) includes specifications of the time of the day to take measurements, the specific scale to use, who takes the measurements (e.g., trained pediatric nurses), whether the measurements should be taken barefooted, and so on, it is likely that reliable data will be obtained. If the operational definition is very vague in terms of these considerations, the data reliability may be low. Measurements taken in the early morning may be greater than those taken in the late afternoon because children's bodies tend to be more stretched after a good night's sleep and become somewhat compacted after a tiring day. Other factors that can contribute to the variations of the measurement data include different scales , trained or untrained personnel, with or without shoes on, and so on.
The measurement of any phenomenon contains a certain amount of chance error. The goal of error-free measurement, although laudable and widely recognized, is never attained in any discipline of scientific investigation. The amount of measurement error may be large or small, but it is universally present. The goal, of course, is to achieve the best possible reliability. Reliability can be expressed in terms of the size of the standard deviations of the repeated measurements. When variables are compared, usually the index of variation (IV) is used. IV is simply a ratio of the standard deviation to the mean:
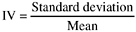
The smaller the IV, the more reliable the measurements.
Validity refers to whether the measurement or metric really measures what we intend it to measure. In other words, it refers to the extent to which an empirical measure reflects the real meaning of the concept under consideration. In cases where the measurement involves no higher level of abstraction, for example, the measurements of body height and weight, validity is simply accuracy. However, validity is different from reliability. Measurements that are reliable are not necessarily valid, and vice versa. For example, a new bathroom scale for body weight may give identical results upon five consecutive measurements (e.g., 160 lb.) and therefore it is reliable. However, the measurements may not be valid; they would not reflect the person's body weight if the offset of the scale were at 10 lb. instead of at zero.
For abstract concepts, validity can be a very difficult issue. For instance, the use of church attendance for measuring religiousness in a community may have low validity because religious persons may or may not go to church and may or may not go regularly. Often, it is difficult to recognize that a certain metric is invalid in measuring a concept; it is even more difficult to improve it or to invent a new metric.
Researchers tend to classify validity into several types. The type of validity we have discussed so far is construct validity, which refers to the validity of the operational measurement or metric representing the theoretical construct. In addition, there are criterion- related validity and content validity . Criterion-related validity is also referred to as predictive validity. For example, the validity of a written driver's test is determined by the relationship between the scores people get on the test and how well they drive. Predictive validity is also applicable to modeling, which we will discuss in later chapters on software reliability models. Content validity refers to the degree to which a measure covers the range of meanings included in the concept. For instance, a test of mathematical ability for elementary pupils cannot be limited to addition, but would also need to cover subtraction, multiplication, division, and so forth.
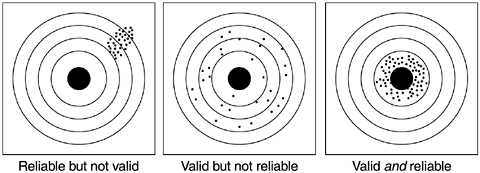
Given a theoretical construct, the purpose of measurement is to measure the construct validly and reliably. Figure 3.4 graphically portrays the difference between validity and reliability. If the purpose of the measurement is to hit the center of the target, we see that reliability looks like a tight pattern regardless of where it hits, because reliability is a function of consistency. Validity, on the other hand, is a function of shots being arranged around the bull's eye. In statistical terms, if the expected value (or the mean) is the bull's eye, then it is valid; if the variations are small relative to the entire target, then it is reliable.
Figure 3.4. An Analogy to Validity and Reliability
From Practice of Social Research (Non-Info Trac Version) , 9th edition, by E. Babbie. 2001 Thomson Learning. Reprinted with permission of Brooks/Cole, an imprint of the Wadsworth Group, a division of Thomson Learning (fax: 800-730-2215).
Note that there is some tension between validity and reliability. For the data to be reliable, the measurement must be specifically defined. In such an endeavor, the risk of being unable to represent the theoretical concept validly may be high. On the other hand, for the definition to have good validity, it may be quite difficult to define the measurements precisely. For example, the measurement of church attendance may be quite reliable because it is specific and observable. However, it may not be valid to represent the concept of religiousness. On the other hand, to derive valid measurements of religiousness is quite difficult. In the real world of measurements and metrics, it is not uncommon for a certain tradeoff or balance to be made between validity and reliability.
Validity and reliability issues come to the fore when we try to use metrics and measurements to represent abstract theoretical constructs. In traditional quality engi-neering where measurements are frequently physical and usually do not involve abstract concepts, the counterparts of validity and reliability are termed accuracy and precision (Juran and Gryna, 1970). Much confusion surrounds these two terms despite their having distinctly different meanings. If we want a much higher degree of precision in measurement (e.g., accuracy up to three digits after the decimal point when measuring height), then our chance of getting all measurements accurate may be reduced. In contrast, if accuracy is required only at the level of integer inch (less precise), then it is a lot easier to meet the accuracy requirement.
Reliability and validity are the two most important issues of measurement quality. These two issues should be well thought-through before a metric is proposed, used, and analyzed . In addition, other attributes for software metrics are desirable. For instance, the draft of the IEEE standard for a software quality metrics methodology includes factors such as correlation, tracking, consistency, predictability, and discriminative power (Schneidewind, 1991).
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
