Design and Complexity Metrics
Classes and methods are the basic constructs for OO technology. The amount of function provided by an OO software can be estimated based on the number of identified classes and methods or its variants. Therefore, it is natural that the basic OO metrics are related to classes and methods, and the size (logical lines of code, or LOC) or function points of the classes and methods. For design and complexity measures, the metrics would have to deal with specific OO characteristics such as inheritance, instance variable, and coupling.
12.2.1 Lorenz Metrics and Rules of Thumb
Based on his experience in OO software development, Lorenz (1993) proposed eleven metrics as OO design metrics. He also provided the rules of thumb for some of the metrics, which we summarized in Table 12.1..
As the table shows, some of these metrics are guidelines for OO design and development rather than metrics in the sense of quantitative measurements. Although most of these eleven metrics are related to OO design and implementation, metric 8 is a statement of good programming practices, metric 9 is a quality indicator, and metric 11 is a metric for validating the OO development process.
With regard to average method size, a large number may indicate poor OO designs and therefore function-oriented coding. For average number of methods per class, a large number is desirable from the standpoint of code reuse because subclasses tend to inherit a larger number of methods from superclasses. However, if the number of methods per object class gets too large, extensibility will suffer. A larger number of methods per object class is also likely to complicate testing as a result to increased complexity. Too many methods in a single class, not counting inherited methods, is also a warning that too much responsibility is being placed in one type of object. There are probably other undiscovered classes. On this point, similar reasoning can be applied to instance variables ”a large number of instance variables indicates that one class is doing more than it should. In other words, the design may need refinement.
Inheritance tree depth is likely to be more favorable than breadth in terms of reusability via inheritance. Deeper inheritance trees would seem to promote greater method sharing than would broad trees. On the other hand, a deep inheritance tree may be more difficult to test than a broad one and comprehensibility may be diminished. Deep class hierarchy may be the result of overzealous object creation, almost the opposite concern of having too many methods or instance variables in one class.
The pertinent question therefore is, what should the optimum value be for OO metrics such as the several just discussed? There may not be one correct answer, but the rules of thumb by Lorenz as shown in Table 12.1. are very useful. They were derived based on experiences from industry OO projects. They provide a threshold for comparison and interpretation.
Table 12.1.. OO Metrics and Rules of Thumb Recommended by Lorenz (1993)
|
Metric |
Rules of Thumb and Comments |
|---|---|
|
1. Average Method Size (LOC) |
Should be less than 8 LOC for Smalltalk and 24 LOC for C++ |
|
2. Average Number of Methods per Class |
Should be less than 20. Bigger averages indicate too much responsibility in too few classes. |
|
3. Average Number of Instance Variables per Class |
Should be less than 6. More instance variables indicate that one class is doing more than it should. |
|
4. Class Hierarchy Nesting Level (Depth of Inheritance Tree, DIT) |
Should be less than 6, starting from the framework classes or the root class. |
|
5. Number of Subsystem/Subsystem Relationships |
Should be less than the number in metric 6. |
|
6. Number of Class/Class Relationships in Each Subsystem |
Should be relatively high. This item relates to high cohesion of classes in the same subsystem. If one or more classes in a subsystem don't interact with many of the other classes, they might be better placed in another subsystem. |
|
7. Instance Variable Usage |
If groups of methods in a class use different sets of instance variables, look closely to see if the class should be split into multiple classes along those "service" lines. |
|
8. Average Number of Comment Lines (per Method) |
Should be greater than 1. |
|
9. Number of Problem Reports per Class |
Should be low (no specifics provided). |
|
10. Number of Times Class Is Reused |
If a class is not being reused in different applications ( especially an abstract class), it might need to be redesigned. |
|
11. Number of Classes and Methods Thrown Away |
Should occur at a steady rate throughout most of the development process. If this is not occurring, one is probably doing an incremental development instead of performing true iterative OO design and development. |
|
Source: Lorenz, 1993. |
|
In 1994 Lorenz and Kidd (1994) expanded their metrics work by publishing a suite of recommended OO metrics with multiple metrics for each of the following categories: method size, method internals, class size, class inheritance, method inheritance, class internals, and class externals . They also showed the frequency distribution of the number of classes for five projects, in the histogram form, along the values of some of the metrics. No numeric parameters of these metrics (e.g., mean or median) were provided, however.
12.2.2 Some Metrics Examples
In early 1993, IBM Object Oriented Technology Council (OOTC) (1993) published a white paper on OO metrics with recommendations to the product divisions. The list included more that thirty metrics, each with a relative importance rating of high, medium, or low. All proposed metrics by Lorenz in 1993 (Table 12.1.), with the exception of metrics 5 and 6, were in the IBM OOTC list with a high importance rating. Almost all of the OOTC metrics were included in Lorenz and Kidd's (1994) comprehensive suite. This commonality was not a coincidence because both Lorenz and Kidd were formerly affiliated with IBM and Lorenz was formerly the technical lead of IBM's OOTC. As one would expect, Lorenz's OO metrics rules of thumb were the same as IBM OOTC's. The OOTC also recommended that the average depth of hierarchy be less than 4 for C++ projects. In terms of project size, the OOTC classified projects with fewer than 200 classes as small, projects with 200 to 500 classes as medium, and projects with more than 500 classes as large.
Table 12.2 shows selected metrics for six OO projects developed at the IBM Rochester software development laboratory. Project A was for the lower layer of a large operating system that interacts with hardware microcode ; Project B was the development of an operating system itself; Project C was for the software that drives the input and output (IO) devices of a computer system; Project D was for a Visualage application; Project E was for a software for a development environment, which was a joint project with an external alliance; and Project F was for a software that provides graphical operations for a subsystem of an operating system. Based on OOTC's project size categorization, Projects A, B, and C were very large projects, Projects E and F were medium- sized projects, and Project D was a small project.
Compared with the rules of thumb per Lorenz (1993) and IBM OOTC (1993), Project E had a much higher average number of methods per class, a larger class in terms of LOC, and a larger maximum depth of inheritance tree. Project E was a joint project with an external alliance and when code drops were delivered, acceptance testing was conducted by IBM. Our defect tracking during acceptance testing did show a high defect volume and a significantly higher defect rate, even when compared to other projects that were developed in procedural programming. This supports the observation that a deep inheritance tree may be more difficult to test than a broad one and comprehensibility may be diminished, thereby allowing more opportunities for error injection.
Table 12.2. Some OO Metrics for Six Projects
|
Metric |
Project A (C++) |
Project B (C++) |
Project C (C++) |
Project D (IBM Smalltalk) |
Project E (OTI Smalltalk) |
Project F (Digitalk of Smalltalk) |
Rules of Thumb |
|---|---|---|---|---|---|---|---|
|
Number of Classes |
5,741 |
2,513 |
3,000 |
100 |
566 |
492 |
na |
|
Methods per Class |
8 |
3 |
7 |
17 |
36 |
21 |
<20 |
|
LOC per Method |
21 |
19 |
15 |
5.3 |
5.2 |
5.7 |
<8(S)* <24(C)* |
|
LOC per Class |
207 |
60 |
100 |
97 |
188 |
117 |
<160(S)* <480(C)* |
|
Max Depth of Inheritance Tree (DIT) |
6 |
na |
5 |
6 |
8 |
na |
<6 |
|
Avg DIT |
na |
na |
3 |
4.8 |
2.8 |
na |
<4 (C)* |
|
(S)* = Smalltalk; (C)* = C++ |
|||||||
The metric values for the other projects all fell below the rule-of-thumb thresholds. The average methods per class for projects A, B, and C were far below the threshold of 20, with project B's value especially low. A smaller number of methods per class may mean larger overheads in class interfaces and a negative impact on the software's performance. Not coincidentally, all three projects were not initially meeting their performance targets, and had to undergo significant performance tuning before the products were ready to ship. The performance challenges of these three projects apparently could not be entirely attributed to this aspect of the class design because there were other known factors, but the data demonstrated a good correlation. Indeed, our experience is that performance is a major concern that needs early action for most OO projects. The positive lesson learned from the performance tuning work of these projects is that performance tuning and improvement are easier in OO development than in procedural programming.
12.2.3 The CK OO Metrics Suite
In 1994 Chidamber and Kemerer proposed six OO design and complexity metrics, which later became the commonly referred to CK metrics suite:
- Weighted Methods per Class (WMC): WMC is the sum of the complexities of the methods, whereas complexity is measured by cyclomatic complexity. If one considers all methods of a class to be of equal complexity, then WMC is simply the number of methods defined in each class. Measuring the cyclomatic complexity is difficult to implement because not all methods are assessable in the class hierarchy due to inheritance. Therefore, in empirical studies, WMC is often just the number of methods in a class, and the average of WMC is the average number of methods per class.
- Depth of Inheritance Tree (DIT): This is the length of the maximum path of a class hierarchy from the node to the root of the inheritance tree.
- Number of Children of a Class (NOC): This is the number of immediate successors (subclasses) of a class in the hierarchy.
- Coupling Between Object Classes (CBO): An object class is coupled to another one if it invokes another one's member functions or instance variables (see the example in Figure 12.1). CBO is the number of classes to which a given class is coupled .
- Response for a Class (RFC): This is the number of methods that can be executed in response to a message received by an object of that class. The larger the number of methods that can be invoked from a class through messages, the greater the complexity of the class. It captures the size of the response set of a class. The response set of a class is all the methods called by local methods. RFC is the number of local methods plus the number of methods called by local methods.
- Lack of Cohesion on Methods (LCOM): The cohesion of a class is indicated by how closely the local methods are related to the local instance variables in the class. High cohesion indicates good class subdivision. The LCOM metric measures the dissimilarity of methods in a class by the usage of instance variables. LCOM is measured as the number of disjoint sets of local methods. Lack of cohesion increases complexity and opportunities for error during the development process.
Chidamber and Kemerer (1994) applied these six metrics in an empirical study of two companies, one using C++ and one using Smalltalk. Site A, a software vendor, provided data on 634 classes from two C++ libraries. Site B, a semiconductor manufacturer, provided data on 1,459 Smalltalk classes. The summary statistics are shown in Table 12.3.
The median weighted methods per class (WMC) for both sites were well below the threshold value for the average number of methods (20) as discussed earlier. The DIT maximums exceeded the threshold of 6, but the medians seemed low, especially for the C++ site. The classes for both sites had low NOCs ”with medians equal to zero, and 73% of site A and 68% of site B had zero children. Indeed the low values of DIT and NOC led the authors to the observation that the designers might not be taking advantage of reuse of methods through inheritance. Striking differences in CBOs and RFCs were shown between the C++ and Smalltalk sites, with the median values for the Smalltalk site much higher. The contrast reflects the differences in the lan-guages with regard to OO implementation. Smalltalk has a higher emphasis on pure OO message passing and a stronger adherence to object-oriented principles (Henderson-Sellers, 1995). Last, the distribution of lack of cohesion on methods was very different for the two sites. Overall, this empirical study shows the feasibility of collecting metrics in realistic environments and it highlights the lack of use of inheritance. The authors also suggested that the distribution of the metric values be used for the identification of design outliers (i.e., classes with extreme values).
Table 12.3. Median Values of CK Metrics for Two Companies
|
Site A (C++) |
Site B (Smalltalk) |
|
|---|---|---|
|
WMC (Weighted Methods per Class) |
5 |
10 |
|
DIT (Depth of Inheritance Tree) |
1(Max. = 8) |
3 (Max = 10) |
|
NOC (Number of Children) |
||
|
RFC (Response for a Class) |
6 |
29 |
|
CBO (Coupling Between Object Classes) |
9 |
|
|
LCOM (Lack of Cohesion on Methods) |
0 (Range: 0 “200) |
2 (Range: 0 “17) |
|
Source: Chidamber and Kemerer, 1993, 1994; Henderson-Sellers, 1995. |
||
12.2.4 Validation Studies and Further Examples
To evaluate whether the CK metrics are useful for predicting the probability of detecting faulty classes, Basili and colleagues (1996) designed and conducted an empirical study over four months at the University of Maryland. The study participants were the students of a C++ OO software analysis and design class. The study involved 8 student teams and 180 OO classes. The independent variables were the six CK metrics and the independent variables were the faulty classes and number of faults detected during testing. The LCOM metric was operationalized as the number of pairs of member functions without shared instance variables, minus the number of pairs of member functions with shared instance variables. When the above subtraction is negative, the metric was set to zero. The hypotheses linked high values of the CK metrics to higher probability of faulty classes. Key findings of the study are as follows :
- The six CK metrics were relatively independent.
- The lack of use of inheritance was confirmed because of the low values in the DITs and NOCs.
- The LCOM lacked discrimination power in predicting faulty classes.
- DITs, RFCs, NOCs, and CBOs were significantly correlated with faulty classes in multivariate statistical analysis.
- These OO metrics were superior to code metrics (e.g., maximum level of statement nesting in a class, number of function declaration, and number of function calls) in predicting faulty classes.
This validation study provides positive confirmation of the value of the CK metrics. The authors, however, caution that several factors may limit the generalizability of results. These factors include: small project sizes, limited conceptual complexity, and student participants.
In 1997 Chidamber, Darcy, and Kemerer (1997) applied the CK metrics suite to three financial application software programs and assessed the usefulness of the metrics from a managerial perspective. The three software systems were all developed by one company. They are used by financial traders to assist them in buying, selling, recording, and analysis of various financial instruments such as stocks, bonds , options, derivatives, and foreign exchange positions . The summary statistics of the CK metrics of these application software are in Table 12.4.
One of the first observed results was the generally small values for the depth of inheritance tree (DIT) and number of children (NOC) metrics in all three systems, indicating that developers were not taking advantage of the inheritance reuse feature of the OO design. This result is consistent with the earlier findings of an empirical study by two of the authors on two separate software systems (Chidamber and Kemerer, 1994). Second, the authors found that three of the metrics, weighted methods per class (WMC), response for a class (RFC), and coupling between classes (CBO) were highly correlated, with correlation coefficients above the .85 level. In statistical interpretation, this implies that for the three software systems in the study, all three metrics were measuring something similar. This finding was in stark contrast to the findings by the validation study by Basilli and colleagues (1995), in which all six CK metrics were found to be relatively independent. This multi-collinearity versus independence among several of the CK metrics apparently needs more empirical studies to clarify.
We noted that the metrics values from these three systems are more dissimilar than similar, especially with regard to the maximum values. This is also true when including the two empirical data sets in Table 12.3. Therefore, it seems that many more empirical studies need to be accumulated before preferable threshold values of the CK metrics can be determined. The authors also made the observation that the threshold values of these metrics cannot be determined a priori and should be derived and used locally from each of the data sets. They decided to use the "80-20" principle in the sense of using the 80th percentile and 20th percentile of the distributions to determine the cutoff points for a "high" or "low" value for a metric. The authors also recommended that the values reported in their study not be accepted as rules, but rather practitioners should analyze local data and set thresholds appropriately.
Table 12.4. Summary Statistics of the CK Metrics for Three Financial Software Systems
|
Software A (45 Classes) |
Median |
Mean |
Maximum |
|
WMC (Weighted Methods per Class) |
6 |
9.27 |
63 |
|
DIT (Depth of Inheritance Tree) |
0.04 |
2 |
|
|
NOC (Number of Children) |
0.07 |
2 |
|
|
RFC (Response for a Class) |
7 |
13.82 |
102 |
|
CBO (Coupling Between Object Classes) |
2 |
4.51 |
39 |
|
LCOM (Lack of Cohesion on Methods) |
6.96 |
90 |
|
|
Software B (27 classes) |
Median |
Mean |
Maximum |
|
WMC (Weighted Methods per Class) |
22 |
20.22 |
31 |
|
DIT (Depth of Inheritance Tree) |
1 |
1.11 |
2 |
|
NOC (Number of Children) |
0.07 |
2 |
|
|
RFC (Response for a Class) |
33 |
38.44 |
93 |
|
CBO (Coupling Between Object Classes) |
7 |
8.63 |
22 |
|
LCOM (Lack of Cohesion on Methods) |
29.37 |
387 |
|
|
Software C (25 Classes) |
Median |
Mean |
Maximum |
|
WMC (Weighted Methods per Class) |
5 |
6.48 |
22 |
|
DIT (Depth of Inheritance Tree) |
2 |
1.96 |
3 |
|
NOC (Number of Children) |
0.92 |
11 |
|
|
RFC (Response for a Class) |
7 |
9.8 |
42 |
|
CBO (Coupling Between Object classes) |
1.28 |
8 |
|
|
LCOM (Lack of Cohesion on Methods) |
4.08 |
83 |
|
|
Source: Chidamber et al., 1997. |
|||
The authors' major objective was to explore the effects of the CK metrics on managerial variables such as productivity, effort to make classes reusable, and design effort. Each managerial variable was evaluated using data from a different project. Productivity was defined as size divided by the number of hours required (lines of code per person hour ), and was assessed using data from software A. Assessment of the effort to make classes reusable was based on data from software B. Some classes in software B were reused on another project and the rework effort was recorded and measured in the number of hours spent by the next project staff to modify each class for use in the next project. Assessment on design effort was based on data from software C. Design effort was defined as the amount of time spent in hours to specify the high-level design of each class. Multivariate statistical techniques were employed with class as the unit of analysis and with each managerial variable as the independent variable. The CK metrics were the independent variables; other relevant variables, such as size and specific developers who had superior performance, were included in the models to serve as control variables so that the net effect of the CK metrics could be estimated. The findings indicated that of the six CK metrics, high levels of CBOs (coupling between object classes) and LCOMs (lack of cohesion on methods) were associated with lower productivity, higher effort to make classes reusable, and greater design effort. In other words, high values of CBO and LCOM were not good with regard to the managerial variables. Specifically, the final regression equation for the productivity evaluation was as follows:
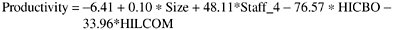
The equation indicates that controlling for the size of the classes and the effect of a star performer (STAFF_4), the productivity for classes with high CBO (coupling between object classes) and LCOM (lack of cohesion on methods) values was much lower (again, the authors used the 80th percentile as the cutoff point to define high values). Because productivity was defined as lines of code per person hour, the regression equation indicates that the productivity was 76.57 lines of code per hour lower (than other classes) for classes with high CBO values, and 33.96 lines of code per hour lower for classes with high LCOM values. The effects were very significant! As a side note, it is interesting to note that the productivity of the classes developed by the star performer (STAFF_4) was 48.11 lines of code per hour higher!
This finding is significant because it reflects the strength of the underlying concepts of coupling and cohesion. In practical use, the metrics can be used to flag out-lying classes for special attention.
Rosenberg, Stapko, and Gallo (1999) discuss the metrics used for OO projects at the NASA Software Assurance Technology Center (SATC). They recommend the six CK metrics plus three traditional metrics, namely, cyclomatic complexity, lines of code, and comment percentage based on SATC experience. The authors also used these metrics to flag classes with potential problems. Any class that met at least two of the following criteria was flagged for further investigation:
- Response for Class (RFC) > 100
- Response for Class > 5 times the number of methods in the class
- Coupling between Objects (CBO) > 5
- Weighted Methods per Class (WMC) > 100
- Number of Methods > 40
Considerable research and discussions on OO metrics have taken place in recent years , for example, Li and Henry (1993), Henderson-Sellers (1996), De Champeaux (1997), Briand (1999), Kemerer (1999), Card and Scalzo (1999), and Babsiya and Davis (2002). With regard to the direction of OO metrics research, there seems to be agreement that it is far more important to focus on empirical validation (or refuta-tion) of the proposed metrics than to propose new ones, and on their relationships with managerial variables such as productivity, quality, and project management.
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
