Productivity Metrics
As stated in the preface, productivity metrics are outside the scope of this book. Software productivity is a complex subject that deserves a much more complete treatment than a brief discussion in a book that focuses on quality and quality metrics. For non-OO projects, much research has been done in assessing and measuring productivity and there are a number of well-known books in the literature. For example, see Jones's work (1986, 1991, 1993, 2000). For productivity metrics for OO projects, relatively few research has been conducted and published. Because this chapter is on OO metrics in general, we include a brief discussion on productivity metrics.
Metrics like lines of code per hour , function points per person-month (PM), number of classes per person-year (PY) or person-month, number of methods per PM, average person-days per class, or even hours per class and average number of classes per developer have been proposed or reported in the literature for OO productivity (Card and Scalzo, 1999; Chidamer et al., 1997; IBM OOTC, 1993; Lorenz and Kidd, 1994). Despite the differences in units of measurement, these metrics all measure the same concept of productivity, which is the number of units of output per unit of effort. In OO development, the unit of output is class or method and the common units of effort are PY and PM. Among the many variants of productivity metric, number of classes per PY and number of classes per PM are perhaps the most frequently used.
Let us look at some actual data. For the five IBM projects discussed earlier, data on project size in terms of number of classes were available (Table 12.2). We also tracked the total PYs for each project, from design, through development, to the completion of testing. We did not have effort data for Project E because it was a joint project with an external alliance. The number of classes per PY thus calculated for these projects are shown in Table 12.5. The numbers ranged from 2.8 classes per PM to 6 classes per PM. The average of the projects was 4.4 classes per PM, with a standard deviation of 1.1. The dispersion of the distribution was small in view of the fact that these were separate projects with different development teams , albeit all developed in the same organization. The high number of classes per PM for Project B may be related to the small number of methods per class (3 methods per class) for the project, as discussed earlier. It is also significant to note that the differences between the C++ projects and the Smalltalk projects were small.
Lorenz and Kidd (1994) show data on average number of person-days per class for four Smalltalk projects and two C++ projects, in a histogram format. From the histograms, we estimate the person-days per class for the four Smalltalk projects were 7, 6, 2, and 8, and for the two C++ projects, they were about 23 and 35. The Smalltalk data seem to be close to that of the IBM projects, amounting to about 4 classes per PM. The C++ projects amounted to about one PM or more per class.
Table 12.5. Productivity in Terms of Number of Classes per PY for Five OO Projects
|
Project A C++ |
Project B C++ |
Project C C++ |
Project D IBM Smalltalk |
Project E OTI Smalltalk |
Project F Digitalk Smalltalk |
|
|---|---|---|---|---|---|---|
|
Number of Classes |
5,741 |
2,513 |
3,000 |
100 |
566 |
492 |
|
PY |
100 |
35 |
90 |
2 |
na |
10 |
|
Classes per PY |
57.4 |
71.8 |
33.3 |
50 |
na |
49.2 |
|
Classes per PM |
4.8 |
6 |
2.8 |
4.2 |
na |
4.1 |
|
Methods per PM |
8 |
18 |
20 |
71 |
na |
86 |
Lorenz and Kidd (1994) list the pertinent factors affecting the differences, including user interface versus model class, abstract versus concrete class, key versus support class, framework versus framework-client class, and immature versus mature classes. For example, they observe that key classes, classes that embody the "essence" of the business domain, normally take more time to develop and require more interactions with domain experts. Framework classes are powerful but are not easy to develop, and require more effort. Mature classes typically have more methods but required less development time. Therefore, without a good understanding of the projects and a consistent operational definition, it is difficult to make valid comparisons across projects or organizations.
It should be noted that all the IBM projects discussed here were systems software, either part of an operating system, or related to an operating system or a development environment. The architecture and subsystem design were firmly in place. Therefore, the classes of these projects may belong more to the mature class category. Data on classes shown in the tables include all classes, regardless of whether they were abstract or concrete, and key or support classes.
In a recent assessment of OO productivity, we looked at data from two OO projects developed at two IBM sites, which were developing middleware software related to business frameworks and Web servers. Their productivity numbers are shown in Table 12.6. The productivity numbers for these two projects were much lower than those discussed earlier. These numbers certainly reflected the difficulty in designing and implementing framework-related classes, versus the more mature classes related to operating systems. The effort data in the table include the end-to-end effort from architecture to design, development, and test. If we confined the measurement to development and test and excluded the effort related to design and architecture, then the metrics value would increase to the following:
Web server: 2.6 classes per PM, 4.5 methods per PM
Framework: 1.9 classes per PM, 14.8 methods per PM
Table 12.6. Productivity Metrics for Two OO Projects
|
Classes (C++) |
Methods (C++) |
Total PMs |
Classes per PM |
Methods per PM |
|
|---|---|---|---|---|---|
|
Web Server |
598 |
1,029 |
318 |
1.9 |
3.2 |
|
Framework |
3,215 |
24,670 |
2,608 |
1.2 |
9.5 |
The IBM OOTC's rule of thumb for effort estimate (at the early design stage of a project) is one to three PM per business class (or key class) (West, 1999). In Lorenz and Kidd's (1994) definition, a key class is a class that is central to the business domain being automated. A key class is one that would cause great difficulties in developing and maintaining a system if it did not exist. Since the ratio between key classes and support classes, or total classes in the entire project is not known, it is difficult to correlate this 1 to 3 PM per key class guideline to the numbers discussed above.
In summary, we attempt to evaluate some empirical OO productivity data, in terms of number of classes per PM. With the preceding discussion, we have the following tentative values as a stake in the ground for OO project effort estimation:
- For project estimate at the early design phase, 1 to 3 PM per business class (or one-third of a class to one class per PM)
- For framework-related projects, about 1.5 classes per PM
- For mature class projects for systems software, about 4 classes per PM
Further studies and accumulation of empirical findings are definitely needed to establish robustness for such OO productivity metrics. A drawback of OO metrics is that there are no conversion rules to lines of code metrics and to function point metrics. As such, comparisons between OO projects described by OO metrics and projects outside the OO paradigm cannot be made. According to Jones (2002), function point metrics works well with OO projects. Among the clients of the Software Productivity Research, Inc. (SPR), those who are interested in comparing OO productivity and quality level to procedural projects all use function point metrics (Jones, 2002). The function point could eventually be the link between OO and non-OO metrics. Because there are variations in the function and responsibility of classes and methods, there are studies that started to use the number of function points as a weighting factor when measuring the number of classes and methods.
Finally, as a side note, regardless of whether it is classes per PM for OO projects or LOC per PY and function points per PM for procedural languages, these productivity metrics are two dimensional: output and effort. The productivity concept in software, especially at the project level, however, is three-dimensional: output (size or function of deliverables), effort, and time. This is because the tradeoff between time and effort is not linear, and therefore the dimension of time must be addressed. If quality is included as yet another variable, the productivity concept would be four-dimensional. Assuming quality is held constant or quality criteria can be established as part of the requirements for the deliverable , we can avoid the confusion of mixing productivity and quality, and productivity remains a three-dimensional concept. As shown in Figure 12.2, if one holds any of the two dimensions constant, a change in the third dimension is a statement of productivity. For example, if effort (resources) and development time are fixed, then the more output (function) a project produces, the more productive is the project team. Likewise, if resources and output (required functions) are fixed, then the faster the team delivers, the more productive it is.
Figure 12.2. Dimensions of the Productivity Concept
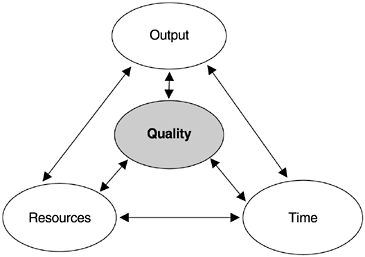
It appears then that the two-dimensional metrics are really not adequate to measure software productivity. Based on a large body of empirical data, Putnam and Myers (1992) derived the software productivity index (PI), which takes all three dimensions of productivity into account. For the output dimension, the PI equation still uses LOC and therefore the index is subject to all shortcomings associated with LOC, which are well documented in the literature (Jones, 1986, 1991, 1993, 2000). The index is still more robust comparing to the two-dimensional metrics because (1) it includes time in its calculation, (2) there is a coefficient in the formula to calibrate for the effects of project size, and (3) after the calculation is done based on the equation, a categorization process is used to translate the raw number of productivity parameters (which is a huge number) to the final productivity index (PI), and therefore the impact of the variations in LOC data is reduced. Putnam and associates also provided the values of PI by types of software based on a large body of empirical data on industry projects. Therefore, the calculated PI value of a project can be compared to the industry average according to type of software.
For procedural programming, function point productivity metrics are regarded as better than the LOC-based productivity metrics. However, the time dimension still needs to be addressed. This is the same case for the OO productivity metrics. Applying Putnam's PI approach to the function point and OO metrics will likely produce better and more adequate productivity metrics. This, however, requires more research with a large body of empirical data in order to establish appropriate equations that are equivalent to the LOC-based PI equation.
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
