Criteria for Causality
The isolation of cause and effect in controlled experiments is relatively easy. For example, a headache medicine was administered to a sample of subjects who were having headaches. A placebo was administered to another group with headaches (who were statistically not different from the first group). If after a certain time of taking the headache medicine and the placebo, the headaches of the first group were reduced or disappeared, while headaches persisted among the second group, then the curing effect of the headache medicine is clear.
For analysis with observational data, the task is much more difficult. Researchers (e.g., Babbie, 1986) have identified three criteria:
- The first requirement in a causal relationship between two variables is that the cause precede the effect in time or as shown clearly in logic.
- The second requirement in a causal relationship is that the two variables be empirically correlated with one another.
- The third requirement for a causal relationship is that the observed empirical correlation between two variables be not the result of a spurious relationship.
The first and second requirements simply state that in addition to empirical correlation, the relationship has to be examined in terms of sequence of occurrence or deductive logic. Correlation is a statistical tool and could be misused without the guidance of a logic system. For instance, it is possible to correlate the outcome of a Super Bowl (National Football League versus American Football League) to some interesting artifacts such as fashion (length of skirt, popular color , and so forth) and weather. However, logic tells us that coincidence or spurious association cannot substantiate causation.
The third requirement is a difficult one. There are several types of spurious relationships, as Figure 3.8 shows, and sometimes it may be a formidable task to show that the observed correlation is not due to a spurious relationship. For this reason, it is much more difficult to prove causality in observational data than in experimental data. Nonetheless, examining for spurious relationships is necessary for scientific reasoning; as a result, findings from the data will be of higher quality.
Figure 3.8. Spurious Relationships
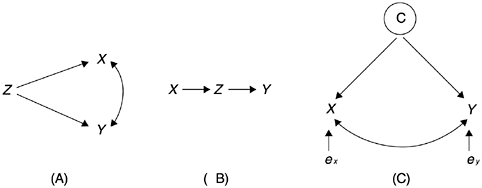
In Figure 3.8, case A is the typical spurious relationship between X and Y in which X and Y have a common cause Z . Case B is a case of the intervening variable, in which the real cause of Y is an intervening variable Z instead of X . In the strict sense, X is not a direct cause of Y . However, since X causes Z and Z in turn causes Y , one could claim causality if the sequence is not too indirect. Case C is similar to case A. However, instead of X and Y having a common cause as in case B, both X and Y are indicators (operational definitions) of the same concept C . It is logical that there is a correlation between them, but causality should not be inferred.
An example of the spurious causal relationship due to two indicators measuring the same concept is Halstead's (1977) software science formula for program length:
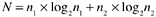
where
N = estimated program length
n 1 = number of unique operators
n 2 = number of unique operands
Researchers have reported high correlations between actual program length (actual lines of code count) and the predicted length based on the formula, sometimes as high as 0.95 (Fitzsimmons and Love, 1978). However, as Card and Agresti (1987) show, both the formula and actual program length are functions of n 1 and n 2 , so correlation exists by definition. In other words, both the formula and the actual lines of code counts are operational measurements of the concept of program length. One has to conduct an actual n 1 and n 2 count for the formula to work. However, n 1 and n 2 counts are not available until the program is complete or almost complete. Therefore, the relationship is not a cause-and-effect relationship and the usefulness of the formula's predictability is limited.
What Is Software Quality?
Software Development Process Models
- Software Development Process Models
- The Waterfall Development Model
- The Prototyping Approach
- The Spiral Model
- The Iterative Development Process Model
- The Object-Oriented Development Process
- The Cleanroom Methodology
- The Defect Prevention Process
- Process Maturity Framework and Quality Standards
Fundamentals of Measurement Theory
- Fundamentals of Measurement Theory
- Definition, Operational Definition, and Measurement
- Level of Measurement
- Some Basic Measures
- Reliability and Validity
- Measurement Errors
- Be Careful with Correlation
- Criteria for Causality
Software Quality Metrics Overview
- Software Quality Metrics Overview
- Product Quality Metrics
- In-Process Quality Metrics
- Metrics for Software Maintenance
- Examples of Metrics Programs
- Collecting Software Engineering Data
Applying the Seven Basic Quality Tools in Software Development
- Applying the Seven Basic Quality Tools in Software Development
- Ishikawas Seven Basic Tools
- Checklist
- Pareto Diagram
- Histogram
- Run Charts
- Scatter Diagram
- Control Chart
- Cause-and-Effect Diagram
- Relations Diagram
Defect Removal Effectiveness
- Defect Removal Effectiveness
- Literature Review
- A Closer Look at Defect Removal Effectiveness
- Defect Removal Effectiveness and Quality Planning
- Cost Effectiveness of Phase Defect Removal
- Defect Removal Effectiveness and Process Maturity Level
The Rayleigh Model
- The Rayleigh Model
- Reliability Models
- The Rayleigh Model
- Basic Assumptions
- Implementation
- Reliability and Predictive Validity
Exponential Distribution and Reliability Growth Models
- Exponential Distribution and Reliability Growth Models
- The Exponential Model
- Reliability Growth Models
- Model Assumptions
- Criteria for Model Evaluation
- Modeling Process
- Test Compression Factor
- Estimating the Distribution of Total Defects over Time
Quality Management Models
- Quality Management Models
- The Rayleigh Model Framework
- Code Integration Pattern
- The PTR Submodel
- The PTR Arrival and Backlog Projection Model
- Reliability Growth Models
- Criteria for Model Evaluation
- In-Process Metrics and Reports
- Orthogonal Defect Classification
In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics for Software Testing
- In-Process Metrics and Quality Management
- Possible Metrics for Acceptance Testing to Evaluate Vendor-Developed Software
- How Do You Know Your Product Is Good Enough to Ship?
Complexity Metrics and Models
- Complexity Metrics and Models
- Lines of Code
- Halsteads Software Science
- Cyclomatic Complexity
- Syntactic Constructs
- Structure Metrics
- An Example of Module Design Metrics in Practice
Metrics and Lessons Learned for Object-Oriented Projects
- Metrics and Lessons Learned for Object-Oriented Projects
- Object-Oriented Concepts and Constructs
- Design and Complexity Metrics
- Productivity Metrics
- Quality and Quality Management Metrics
- Lessons Learned from OO Projects
Availability Metrics
- Availability Metrics
- 1 Definition and Measurements of System Availability
- Reliability, Availability, and Defect Rate
- Collecting Customer Outage Data for Quality Improvement
Measuring and Analyzing Customer Satisfaction
- Measuring and Analyzing Customer Satisfaction
- Customer Satisfaction Surveys
- Analyzing Satisfaction Data
- Satisfaction with Company
- How Good Is Good Enough
Conducting In-Process Quality Assessments
- Conducting In-Process Quality Assessments
- The Preparation Phase
- The Evaluation Phase
- The Summarization Phase
- Recommendations and Risk Mitigation
Conducting Software Project Assessments
- Conducting Software Project Assessments
- Audit and Assessment
- Software Process Maturity Assessment and Software Project Assessment
- Software Process Assessment Cycle
- A Proposed Software Project Assessment Method
Dos and Donts of Software Process Improvement
- Dos and Donts of Software Process Improvement
- Measuring Process Maturity
- Measuring Process Capability
- Staged versus Continuous Debating Religion
- Measuring Levels Is Not Enough
- Establishing the Alignment Principle
- Take Time Getting Faster
- Keep It Simple or Face Decomplexification
- Measuring the Value of Process Improvement
- Measuring Process Adoption
- Measuring Process Compliance
- Celebrate the Journey, Not Just the Destination
Using Function Point Metrics to Measure Software Process Improvements
- Using Function Point Metrics to Measure Software Process Improvements
- Software Process Improvement Sequences
- Process Improvement Economics
- Measuring Process Improvements at Activity Levels
Concluding Remarks
- Concluding Remarks
- Data Quality Control
- Getting Started with a Software Metrics Program
- Software Quality Engineering Modeling
- Statistical Process Control in Software Development
A Project Assessment Questionnaire
EAN: 2147483647
Pages: 176
