Creating a Search Engine with Lucene
Every web site that has more than a few pages requires some attention to be given to information architecture, including navigation, a site map, and a search engine. The JavaEdge application needs a search engine that can be plugged into our existing web infrastructure. To avoid maintaining two different technology stacks on our servers, any search engine that we decide to use should be deployable into Tomcat, WebLogic, WebSphere, or another J2EE application server or servlet container. Also, we need something that can be easily customized to match the look and feel of our site.
In this chapter, we will discuss some of the issues with search engines and present the design needed for an effective search tool. We'll use Lucene, which is the open source search engine from the Jakarta Apache Group, as our solution and show how to configure Lucene to work with the JavaEdge application.
Search Requirements for the JavaEdge Application
To make full use of the JavaEdge application, it's crucial that users can simply search for the content in which they are interested and view previously published stories and comments. We want to incorporate the logical design of our content into the new search facility. Users should be able to use our search engine like any other web search engine they may be familiar with (for example, Google, Lycos, MSN Search, etc.). The user interface should be similar to these popular sites and, therefore, intuitive for the end user.
Our search engine must remain relevant and provide high quality results. This means that when content is added or updated, our search engine should reflect those changes as soon as possible. Furthermore, we have to minimize the amount of time any stale content appears in the search results. It is very frustrating to click on a search link to find out that the content doesn't have anything to do with the search results. Most users select results only from the first page or at the most first few pages into the site. Hence, we have to find a search engine that can reliably rank and score results.
Another consideration for the user interface is that it needs to be consistent with the rest of the JavaEdge site. A link to the search engine should be available from every page. While displaying the results, a summary or description of each link should be given, so the users can figure out what they're likely to get when they select a particular result.
We need a solution that fits in with our existing architecture. If we used a product that isn't J2EE- compatible, we would have a tougher integration problem. It's certainly possible to use a search engine that is written only in Perl, C, or Python with our JavaEdge application, but it would be much harder to integrate with Struts. We would prefer the solution to be ready to go with our Struts framework. But if this isn't the case, we will need to create an integration code between our application and the search engine.
Another requirement is that the search engine should be open source, so we can modify its behavior. Some Java open source web search engines are Lucene, Egothor, and HouseSpider. HouseSpider uses a Java applet to search the items and display the results. This approach is a little different from the search interface that most commercial web search engines use, such as Google. We're looking for an application that can be customized to look like the rest of the JavaEdge site. Egothor and Lucene are both server-side Java search engines. Both projects could be used to fill our search engine needs. Neither contains a web crawler as a part of the core package and each includes similar parsing, stemming, and indexing functionality.
Lucene gets a preference for the JavaEdge application because it is part of the Jakarta Apache Group and has higher visibility than Egothor. You can find more information on Lucene at: http://jakarta.apache.org/lucene/.
Search Engine Fundamentals
We need to discuss how a web search engine works before we can start our Lucene discussion. You may already be familiar with how search engines such as Google are designed. Google uses web crawlers (also known as spiders), which are fed with many starting points. These starting points are usually the URLs that webmasters submit to Google so that they can be indexed. The web crawlers then download the contents of each URL, and follow the links in the HTML to download more web pages. There are usually a lot of web crawlers distributed across a large number of machines. Crawlers are also used to update the existing content in search engine indexes, to ensure that the search engine results are fresh. Search engines can determine how fast the content changes and by measuring this velocity, they can determine when the existing content should be re-indexed.
The content that the crawlers find is fed into an indexer, which processes HTML (and in case of Google, PDF files) into text content that can be searched across. The indexer also processes the words inside the HTML. Each word that is stored in the index is converted to lower case. Many common words, such as the, a, an, I, and so on, are usually not indexed in a way in which they can be directly searched on. For example, if you search Google for just the word "the", you wouldn't get very useful results. These words are known as stop words. Another common processing technique is to use a stemmer. Stemmers are designed for a specific language and they process words into their root stems. For example, the word "dogs" would be stored as the word "dog" in the index, and a search for either would return the results that have both the words.
When a user decides to ask the search engine for hits matching a query, the search engine will need to get the query (typically from a web form), and then parse the query into a data structure that it understands. The details of processing this query vary for different search engines. This parsed query will then be fed to a searcher. The searcher will take the query and process the query words in the same way as the content was processed into the index. The results matching this processed query are then sorted using internal algorithms. This sorting takes into account the size of the content, number of matches, how close the matched terms are, and many other factors that depend on the search engine implementation. The results are then passed back to the application code for display to the end user.
Functionality Provided by Lucene
Lucene implements the indexing and querying capabilities, described in the above search engine architecture. Lucene does not include a web crawler or spider, although there is a project called LARM that is currently in its early stages and will provide a web crawler. LARM is not a part of the core Lucene distribution. If you are planning to write a web crawler, it will be much easier to start with LARM.
Lucene provides a set of English language analyzers to process content for stop words and acronyms, and to convert to lower case. There are also German and Chinese language analyzers available. There are implementations for the Porter stemming algorithm and the Snowball stemmer. An HTML parser that uses WebGain's JavaCC comes with Lucene as part of the Lucene demo. It's also possible to use other HTML parsers, such as NekoHTML or JTidy, which aren't bundled with Lucene.
Several different query objects are available, including a Boolean query, a phrase matching query (that can look for exact phrases or words that are near each other), a prefix matching query, a wildcard query, and a fuzzy search query object.
Lucene can also score each hit in the query results. This means that the most likely hits for the given search terms will be given the highest score. It's up to the developers to determine how to display the scores in the search results. It's also possible to assign added weight (known as a boost) to certain terms in the query, which affects the score given to the search results.
Lucene includes some highlighting features, as an add-on to the core API, for marking the search terms in the results. This is a complicated task because the searcher relies on matching the processed words in the query (terms) against the terms stored in the index and neither may match the original words in the content, displayed to the user as a summary in the search results.
Lucene doesn't include any summarization technology. It's possible to cache documents, but there isn't any functionality provided with Lucene. Instead, it's handled in the application that uses Lucene.
Lucene s Architecture
Lucene is a component with a well-defined API that can be driven from another application. Here we're going to discuss some of Lucene's architecture:
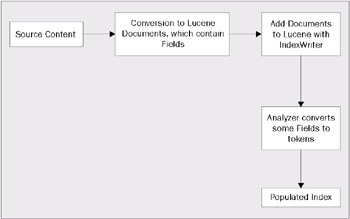
The indexer requires all the source contents to be converted into Lucene documents. Each document is a collection of fields. Each field has a name and a value. The developers can decide the field names. This document is then added to the index with an IndexWriter object. This object is responsible for updating the Lucene index with the new entries. The index is stored on the file system. The field values are fed through an analyzer. The analyzer converts the content into tokens. Tokens can be delimited in the source content by whitespace, punctuation, or anything else that the analyzer can determine. The tokens are stored as a document entry in the index.
Searching through Lucene is done using queries:
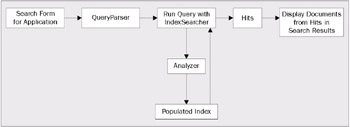
Each query from the form on a web page needs to be translated, with the QueryParser, into a query object that Lucene can understand. That query is then passed on to the IndexSearcher class. The query is run through an analyzer to translate the query terms into tokens that can be matched against results in the index. The index searcher gets back a Hits object, which contains the number of hits, the Document object for each hit, and the score for each hit. Our application then takes the Hits object and displays the search results to the user.
Index
The indexer is responsible for adding new content to our search engine. Lucene works with org.apache.lucene.document.Document objects to build its index. Our existing content will have to be processed into Document objects that Lucene can understand. These objects are composed of Field objects. These Field objects are name-value pairs that Lucene uses as keywords in its index. In addition, we require our indexer to get a list of all the content in the JavaEdge application, so that it can crawl through the content and update or refresh the search engine index.
We need to design the indexer so that it can:
- Get content from the JavaEdge application
- Determine what content needs to be refreshed in the index
- Ensure that the index gets updated on a frequent basis
Let's discuss each of these issues in more detail.
Get Content from the JavaEdge Application
The first design decision is how to get content out of the JavaEdge application. Lucene can be used with any kind of data source, for which an indexer can be written, including web sites, database tables, or free-form text. We could create an indexer that used the JavaEdge application web pages to generate Document objects for Lucene. This would be the most general case for a web search engine; it need not know anything about how the web site was built internally, since it would only communicate via HTTP.
In addition, the search engine is loosely coupled with our web site, that is, if we change some of our classes, we won't have to rewrite the entire search engine. This approach usually requires a general- purpose web spider for the indexing. We could create a list of every URL with content in our system and feed it to the spider. The disadvantage of this method is that our data would be less structured. We couldn't separate pieces of information into fields for Lucene unless we wrote a screen scraper tool to pick the pieces of information from the web page. This approach can be fragile unless metadata is embedded in the web page to highlight information for the indexer.
Another approach would be to create an indexer, which could use JavaEdge's data-access layer to get a list of all stories and comments in the application and use that to build Lucene's index for the application. This would have the advantage of being able to use our internal Story and Comment value objects to directly access data. The code that transforms our content into Lucene documents would be a relatively straightforward tool. As more properties are added to stories and comments, we could add them as fields for the search engine. For this approach, we won't have to do any HTML parsing. We will use this approach for the JavaEdge application.
The last approach would be to ignore the data-access layer and write an indexer that would directly access the database using JDBC. It shares many advantages with the above approach, but it is better to abstract away the database access behind the data-access layer that we have already created.
Keeping the Search Index Fresh
The search engine should be able to determine when content has been changed. It is not desirable to have stale content in the search engine index. This will result in incorrect results being generated, leading to a frustrating user experience.
There are two solutions to solve this problem:
- Always completely rebuild the index when content has been added or changed
- Check each piece of content to determine whether it has been updated or deleted since the last index.
A combination of these solutions can be used. For example, you might want to perform an incremental index update every hour and perform a full rebuild only when the server is less loaded during the night. These sorts of decisions can only be made with lots of performance, load, and stress testing. You will discover the optimal strategy after the first few weeks when an application is in a production environment.
If we always rebuild the index when we generate the site, we solve the problem of having stale content, which would only be around for the time between application updates. With Lucene, controlling when to rebuild the index is a simple Boolean flag passed to the IndexWriter class. For this solution, the best approach is to create the index in a separate directory, make sure the index is created without any errors, and then point Lucene's reader to the new index. However, we won't use this method for the JavaEdge application.
To check whether each piece of content is fresh, we can compare each story to the entry stored in the search index. We could create a Lucene document out of each story and then compare the content field in the index with the content field in the document. If the fields aren't identical, we can delete the item out of the index and then add the updated document to the index. If the story isn't found in the index, we can add it to the index. This is how we implemented incremental indexing in JavaEdge.
If we delete a story feature in JavaEdge, we would also need to go through each document in Lucene's index and determine if it still exists as a story in JavaEdge. If it does, we'll need to delete it from the index.
Updating the Index
The Lucene index is contained in a directory on the file system. The developers can choose any location for this directory, but your application will have to keep track of where the index is located. If the index doesn't exist, we will have to create a new index in the chosen directory. When the index already exists, we will need to make sure we don't destroy the index when we open up a file writer. The index creation behavior is controlled with a single Boolean flag in the constructor of the IndexWriter class. Our application will use Lucene's IndexReader class to determine whether an index already exists.
Our next design decision is to determine when to update the index. There are three ways of doing this:
- Administrator updates the index on a manual basis
- Index is updated on a fixed time interval (such as 10 minutes or an hour)
- The index is updated every time a piece of content is changed in the JavaEdge application
The first solution is not very effective. The application administrator would have to be responsible for doing an action that can easily be automated. We can add a feature to the JavaEdge application to trigger an index rebuild any time the administrator wants. This could be added in the second version, in an administrator's interface.
The next approach is attractive. Timer functionality was added to the Java Developer's Kit in version 1.3, which allows us to easily write code that is invoked at a regular interval by a scheduler thread. We could load the timer class into Struts by implementing the org.apache.struts.action.PlugIn interface. Struts plug-ins have init() and destroy() methods that are respectively called by Struts whenever it is loaded or shut down. Using init(), we could invoke the scheduler, which would then run our indexer for a time period that can be configured by the administrator. For example, we could update every ten minutes. If this period loads the server heavily, we can increase it. We are going to use the above approach with JavaEdge, by creating a Struts plug-in. The time interval can be modified in the struts-config.xml file.
To implement the final approach, we need to create an object that could take a storyID and add or update the corresponding story in the index. From the PostStory action in Struts, we would add that story to the Lucene index. (Refer to Chapter 3 for the discussion on the PostStory action). In the Postcomment action, we would update the story in the Lucene index by calling a class that we would write to abstract the process of adding a story to the search index. However, this method can become problematic. If the site gets a large number of comments and stories posted every hour, the search engine will be adding or updating content all of the time. If an error occurs during the indexing process, the index may be out of synchronization with the content in the JavaEdge application.
Analyzers
Search engines need to process data to be used in the index to ensure consistent search results. This processing is called tokenizing, which consists of splitting up the data. Lucene tokenizes data in fields to be used in the search engine index. It uses analyzers to perform all of the processing for tokenization. Lucene also uses analyzers for querying the index. The user's query is also tokenized and the searcher looks for results in the index that match the tokens for the query. Each analyzer does tokenization differently; we are going to discuss these differences here.
Each token consists of four different fields:
- The text
- The beginning position in the original text
- The end position in the original text
- The type of token
Most of this goes on behind the scenes. We're just going to use one of Lucene's built-in analyzers.
| Note |
If these analyzers aren't giving you the results that you want, you may have to subclass an existing analyzer and use it for your own search engine. You may want to refer to the Lucene web site in the contributions and sand box section for more analyzers. Also check the mailing list archives for the Lucene users and developers mailing lists. If you use a language other than English, German, or Chinese, you will have to write your own analyzer. You may search the Lucene user mailing list archives to determine if someone else has written an analyzer for your language. The Lucene mailing list directions and archives can be found at: http://jakarta.apache.org/site/mail.html. |
Lucene has several built-in analyzers. The three that are most interesting are:
- SimpleAnalyzer
- StopAnalyzer
- StandardAnalyzer
The SimpleAnalyzer is the most basic of the built-in analyzers. It creates a stream of tokens by splitting words into tokens, whenever it reaches a character that isn't a letter. For English, it strips out punctuation and converts individual words into tokens. It also converts all letters in the tokens to a lower case.
The StopAnalyzer does everything that the SimpleAnalyzer does, but in addition, it removes some common English words, known as stop words. Most search engines remove these words from the list of tokens to make the search more effective. In Lucene, the stop words are defined as an array in the source code for the StopAnalyzer class. They are also independently defined in the StandardAnalyzer class. If you need to change them, you will have to extend the standard analyzer. Here is the list of English stop words in Lucene 1.2:
|
a |
and |
are |
as |
|
at |
be |
but |
by |
|
for |
if |
in |
into |
|
is |
it |
no |
not |
|
of |
on |
or |
s |
|
such |
t |
that |
the |
|
their |
then |
there |
these |
|
they |
this |
to |
was |
|
will |
with |
We are going to use the StandardAnalyzer for our search engine. It does everything that the SimpleAnalyzer and StopAnalyzer do. The StandardAnalyzer also uses the StandardFilter class to do processing. This filter removes the ending apostrophe s ('s) from words, such as it's, Sun's, Judy's, etc. The StandardAnalyzer would create a token with "it", instead of "it's". Hence, a search for either of those terms would match the other. If the word is an acronym (IBM, N.I.H., NBA), the StandardAnalyzer also strips any dots (.) from it. The tokens for N.F.L. and NFL would be the same.
Stemming
Lucene comes with a filter class called PorterStemFilter, which allows you to create stems for the words in your index. The filter uses a class called PorterStemmer, which is a Java implementation of an algorithm for removing suffixes from words (leaving the root) by Martin Porter. You will have to create your own analyzer class to use this filter, and directions are given in the source code for PorterStemFilter. We're not going to use this stemming functionality in our application.
Here are several examples of words that have been stemmed with the Porter stemming algorithm: (taken from Martin Porter's web site: http://snowball.tartarus.org/porter/stemmer.html):
|
Word |
Stemmed as |
|---|---|
|
happy |
happi |
|
happiness |
happi |
|
happier |
happier |
|
drive |
drive |
|
driven |
driven |
|
drives |
drive |
|
driving |
drive |
Indexing HTML
We can use the NekoHTML parser, written by Andy Clark, to index any reasonably well-formed HTML files. NekoHTML can be found at http://www.apache.org/~andyc/neko/doc/index.html. One of the most difficult parts of writing a search engine is parsing HTML that isn't correct, but is still on the web because it works in the leading browsers. NekoHTML can strip the HTML tags out of our HTML files. It can be configured with filters to let certain tags through to the output and also retrieve the attributes or contents of any tags we want. We could get the contents of tags or
tags and use them as fields in our Lucene documents. NekoHTML has to be used with the Xerces XML parser for parsing our HTML. We have used the Xerces 2.0.0 JAR files.
Here is a short example demonstrating the use of NekoHTML to strip all HTML tags from an HTML file. We used the Xerces DOM serializer for output, but you can use the one of your choice. However, you'll have to tell the serializer to write to a different output:
package com.wrox.javaedge.search;
import org.cyberneko.html.parsers.DOMParser;
import org.cyberneko.html.filters.ElementRemover;
import org.apache.xerces.xni.parser.XMLDocumentFilter;
import org.apache.xerces.util.DOMUtil;
import org.apache.xml.serialize.OutputFormat;
import org.apache.xml.serialize.XMLSerializer;
import org.xml.sax.SAXNotRecognizedException;
import org.xml.sax.SAXException;
import org.w3c.dom.Document;
import java.io.IOException;
public class HTMLParser {
public static void main(String[] args)
throws SAXException, SAXNotRecognizedException, IOException {
DOMParser parser = new DOMParser();
ElementRemover remover = new ElementRemover();
//keep the link element
remover.acceptElement("A",null);
XMLDocumentFilter[] f = {remover};
parser.setProperty("http://cyberneko.org/html/properties/filters", f);
parser.parse("test.html");
Document xmlDoc = parser.getDocument();
OutputFormat outputFormat = new OutputFormat(xmlDoc);
outputFormat.setPreserveSpace(true);
outputFormat.setOmitXMLDeclaration(true);
outputFormat.setOmitDocumentType(true);
XMLSerializer serializer = new XMLSerializer(System.out, outputFormat);
serializer.serialize(xmlDoc);
}
}
Here is the sample HTML file (test.html) that we used:
HTML test
Here is some sample text.
And a link <a href="http://www.cnn.com/">CNN</a>.
The Lucene distribution comes with a simple demo application. The demo includes an HTML parser that was built with WebGain's JavaCC. If you are interested in using JavaCC as part of your application, you may want to take a look at the source code in the demo directory.
Implementing the Index
In this section, we'll examine in detail the classes used to implement the index. This consists of the IndexContent class, which adds stories into the index, the DocumentConversionTool class, which translates those stories into Lucene documents, and the scheduler classes. The scheduler classes implement a Struts plug-in and a TimerTask. We also update struts-config.xml with the settings for our scheduler plug-in. (Refer to Chapter 2 for the discussion on the struts-config.xml file)
Building the Scheduler
In this section, we'll be looking at the IndexScheduler class, which schedules the content indexing process. It is really just a wrapper around a JDK Timer class that runs a complete index of the site on schedule. The IndexScheduler class uses a class called IndexTask, which extends TimerTask from the JDK. The only method creates an index by using the IndexContent utility class. The scheduler will run the indexing process every hour. We will make this time period configurable in the struts-config.xml file.
Struts 1.1 has a built-in mechanism for running code when the Struts application is launched. Struts calls these application-lifecycle objects as plug-ins. Plug-ins are an alternative to creating a servlet, which is loaded when the servlet container initializes. Any code that needs to be initialized at the startup may be implemented as a plug-in.
We need to write a plug-in class to implement the org.apache.struts.action.PlugIn interface. This interface has only two methods:
- init(ActionServlet servlet, ApplicationConfig config):
We're going to use this method to invoke a timer to schedule our indexer. - destroy():
Used when the Struts application is shutting down. We are not going to use this.
Our plug-in will be configured in the struts-config.xml file. We already have one plug-in configured in the file. The validator plug-in configuration uses the element to call a JavaBeans setter in the org.apache.struts.validator.ValidatorPlugIn class. (Refer to Chapter 3 for the discussion on the validator plug-in). Our indexer plug-in is simple and takes only a timeout value for the scheduler as a property.
Here is the code for both plug-ins in struts-config.xml:
... ...
The plug-in class calls the scheduler from the init() method. The setTime() method is called by Struts before the init() method is executed. We supply a default, in case the time property isn't configured properly for the plug-in.
Here is the code for IndexerPlugIn.java:
package com.wrox.javaedge.struts.search;
import org.apache.struts.action.ActionServlet;
import org.apache.struts.action.PlugIn;
import org.apache.struts.config.ApplicationConfig;
import com.wrox.javaedge.search.IndexScheduler;
public class IndexerPlugIn implements PlugIn {
protected IndexScheduler scheduler;
// default is one hour
protected long time = 60*60*1000;
// Doesn't do anything in this implementation
public void destroy() {
}
public void init(ActionServlet servlet, ApplicationConfig config) {
scheduler = new IndexScheduler(time);
}
public void setTime(long time) {
this.time = time;
}
}
The scheduler uses the JDK 1.3 Timer class to run a timer task that starts the indexer. We use an initial delay of one minute before the indexer is first started.
The following code shows IndexScheduler.java, which schedules a content indexing process. The constructor takes the number of milliseconds of delay before the execution of the timer task from the search configuration:
package com.wrox.javaedge.search;
import java.util.Timer;
public class IndexScheduler {
// jdk 1.3 and above timer class
Timer timer;
public IndexScheduler(long time) {
timer = new Timer();
timer.schedule(new IndexTask(), 1000, time);
}
}
Finally, we have the task that runs the search engine indexer by calling the createIndex() method in our IndexContent utility class:
package com.wrox.javaedge.search;
import java.util.TimerTask;
public class IndexTask extends TimerTask {
public void run() {
IndexContent indexer = new IndexContent indexer.createIndex();
}
}
The IndexContent Class
The IndexContent class takes our stories and comments from JavaEdge and gives them to Lucene for indexing. We use Lucene's IndexWriter class to access a Lucene index stored on disk. We tell the writer to create an index if one doesn't exist, and to use the old one if it already exists when we call the constructor on the index writer.
All of the stories are pulled out of JavaEdge using the Story data-access object. (Refer to Chapter 5 for the discussion on the data-access tier). Each of the stories in turn is run through the document conversion tool and the resulting document is indexed by Lucene. Most of the details are hidden, but you can see the code, as Lucene is an open source tool.
The methods implemented in this class are summarized in the table below:
|
Method |
Description |
|---|---|
|
GetWriter() |
Gets a copy of the index writer that we use to add entries to the index. |
|
CreateIndex() |
Creates an index from all the stories. Stories are retrieved using the getAllStories() and are converted to a Lucene Document before being added to the index, using the index writer obtained in getWriter(). |
|
GetAllStories() |
Makes a call out to storyDAO to get all the stories. |
|
CloseWriter() |
Closes down the writer, after running the index optimizer. |
Here is the full code for the IndexContent class:
package com.wrox.javaedge.search;
import java.io.IOException;
import java.util.*;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Searcher;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.Hits;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.queryParser.ParseException;
import org.apache.log4j.Category;
import com.wrox.javaedge.common.DataAccessException;
import com.wrox.javaedge.story.StoryVO;
import com.wrox.javaedge.story.dao.StoryDAO;
public class IndexContent {
// Create Log4j category instance for logging
static private Category log =
Category.getInstance(IndexContent.class.getName());
public IndexWriter getWriter() throws IOException {
Analyzer analyzer = new StandardAnalyzer();
IndexWriter writer;
// check to see if an index already exists
if (IndexReader.indexExists(SearchConfiguration.getIndexPath())) {
writer = new IndexWriter(SearchConfiguration.getIndexPath(),
analyzer, false);
} else {
writer = new IndexWriter(SearchConfiguration.getIndexPath(),
analyzer, true);
}
return writer;
}
public IndexReader getReader() throws IOException {
IndexReader reader =
IndexReader.open(SearchConfiguration.getIndexPath());
return reader;
}
public void createIndex() {
try {
// Lucene's index generator
IndexWriter writer = getWriter();
// Lucene's index reader
IndexReader reader = getReader();
// set up our analyzer
Analyzer analyzer = new StandardAnalyzer();
// set up our searcher
String indexPath = SearchConfiguration.getIndexPath();
Searcher searcher = new IndexSearcher(indexPath);
// from the DAO
Collection stories = getAllStories();
if (stories == null) {
return;
}
// Easier to use an iterator for retrieving the stories
Iterator iter = stories.iterator();
while (iter.hasNext()) {
// this could throw a class cast exception
StoryVO story = (StoryVO) iter.next();
// we wrote the Document Conversion Tool specifically for the
// story value objects
Document doc = DocumentConversionTool.createDocument(story);
// get out the content field
String content =
doc.getField(DocumentConversionTool.CONTENT_FIELD).stringValue();
// get the search entry for this story id
// create a query that looks up items by our searchId
Query query = QueryParser.parse(story.getStoryId().toString(),
"storyId", analyzer);
// get all of the hits for the query term out of the index
Hits hits = searcher.search(query);
// should only have one or zero entries for each story id,
// otherwise log a warning
if (hits.length() == 0) {
// this story is brand new
// add the converted document to the Lucene index
writer.addDocument(doc);
log.info("new story added: " + story.getStoryId());
} else if (hits.length() == 1) {
log.info("story is old: " + story.getStoryId());
// get the entry out of the search engine
Document oldDoc = hits.doc(0);
// get the old content
String oldContent =
oldDoc.getField(DocumentConversionTool.CONTENT_FIELD).
stringValue();
// if it has been updated, delete it from the index, then re-add it.
if (!content.equals(oldContent)) {
log.info("story is being updated: " + story.getStoryId());
reader.delete(new Term("storyId",story.getStoryId().toString()));
writer.addDocument(doc);
} else {
log.warn("Wrong number of entries for story id: " +
story.getStoryId() + ": " + hits.length() + " found." );
}
}
}
closeWriter(writer);
} catch (IOException ie) {
log.error ("Error creating Lucene index: " + ie.getMessage(), ie);
} catch (ClassCastException cce) {
log.error ("Error casting object to StoryVO: " + cce.getMessage(), cce);
} catch (ParseException pe) {
log.error ("Error parsing Lucene query for storyId: " +
pe.getMessage(), pe);
}
}
public Collection getAllStories() {
try {
StoryDAO storyDAO = new StoryDAO();
return storyDAO.findAllStories();
} catch (DataAccessException dae) {
log.error("Error retrieving all stories from DAO: " + dae.getMessage(),
dae);
}
return null;
}
public void closeWriter(IndexWriter writer) throws IOException {
if (writer == null) {
return;
}
writer.optimize();
writer.close();
}
}
}
The DocumentConversionTool Class
From the above code listing of the IndexContent class, you can see that the createIndex() method uses a DocumentConversionTool class to convert the index content from a StoryVO class to a Lucene Document. The DocumentConversionTool class contains methods that read content out of the Lucene story and comment value objects and transform them:
|
Method |
Description |
|---|---|
|
createDocument() |
This method is the core of the class. It takes a populated JavaEdge StoryVO object as a parameter, creates a new Lucene Document object and then populates it with Lucene fields. Responsible for creating content, title, introduction, date, and storyId fields. |
|
addContent() |
Adds content from the story and comment value objects to the content field. Uses the title, introduction, story body, and comment bodies to generate the content. |
Our Lucene Document object is going to contain a set of fields that are specific to our JavaEdge application. Specifically, the body of each comment will be appended to the introduction, title, and body of the story, so that we can search through the entire text of the story.
All of our fields will use String objects for the values. Lucene is also capable of using Reader objects for the values if the field is to be tokenized and indexed, but not stored in the index as a copy. The table below summarizes the Document Fields:
|
Field |
Meaning |
|---|---|
|
content |
The introduction of each story will be appended to the body of each story, and then the body of each comment will be appended to this |
|
title |
The title of the story |
|
date |
The date the story was submitted |
|
introduction |
The introduction for the story |
|
storyId |
The ID for the story, so we can retrieve it from the data-access object layer in the future |
Here is the code listing for DocumentConversionTool:
package com.wrox.javaedge.search;
import org.apache.lucene.document.DateField;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import com.wrox.javaedge.story.StoryVO;
import com.wrox.javaedge.story.StoryCommentVO;
import java.util.Iterator;
public class DocumentConversionTool {
public static Document createDocument(StoryVO story) {
// create a Document object
Document document = new Document();
// create a field that is only stored in the index
Long storyId = story.getStoryId();
if (storyId != null) {
document.add(Field.UnIndexed("storyId", storyId.toString()));
}
}
We are going to use the storyId field to create links from the search results to the actual story. We intend to allow it to be searched on for the incremental indexing feature, so we will use the Keyword() method in the Field object to add our storyId to the document. The Keyword() method creates a field that is stored in the index for access later, and can be used for querying.
Most of our Lucene fields are going to be created by calling the Text() method on the Field class:
// create a field that is tokenized, indexed, and stored in the index
String title = story.getStoryTitle();
document.add(Field.Text("title", title));
// create a field that is tokenized, indexed, and stored in the index
String introduction = story.getStoryIntro();
document.add(Field.Text("introduction", introduction));
The Field.Text() method creates fields that are indexed, tokenized, and stored in the index. If a field is tokenized, that means it is broken up into individual elements by a Lucene analyzer (refer to the section called Analyzers). You should use this method when you need to retrieve the contents of the field during the query results. For the JavaEdge application, we need the title and introduction to display the search results:
The date is created with the help of a special class called DateField:
//create a field that is indexed and stored in the index
java.util.Date date = story.getSubmissionDate();
document.add(Field.Keyword("date", DateField.dateToString(date)));
addContent(story, document, title, introduction);
return document;
}
The DateField class contains methods for converting between Java date and time objects and Lucene's internal string representation of dates. Here, we've used the dateToString() method to store our dates as strings in Lucene's format.
Finally, we've got the addContent() method, which adds the story title, the introduction, body content, and comment bodies to the content field of the Document object. This field is our all-purpose content field that we will use for querying. Our title, introduction, story body, and comment bodies are all appended together to create one large content value:
protected static void addContent(StoryVO story,
Document document,
String title,
String introduction) {
// create the content for the search query
// and then store it in the index, tokenized and indexed
String content = title + " " + introduction +
" " + story.getStoryBody();
Iterator iter = story.getComments().iterator();
while (iter.hasNext()) {
StoryCommentVO comment = (StoryCommentVO) iter.next();
if (comment != null) {
content = content + " " + comment.getCommentBody();
}
}
document.add(Field.UnStored("content",content));
}
}
Note that we use the Field.Text() method to create this field, so we can retrieve our content later to compare it with existing versions for the incremental indexer.
Querying the Index
Our search form layer has to be integrated with the presentation layer. We will need to create a search form using Struts and then make it accessible from the JavaEdge navigation. We'll need a link to the search form in the JSP header file, which will require an addition to the ApplicationResources.properties resource bundle. While we're modifying the resource bundle, we will need to add some messages for the JSP page that come out of the properties file.
After submitting a query from the JSP page that we are going to build, our request will go to an Action class called Search, which will perform some error checking and exception handling, but won't contain any logic. Instead, it will delegate most of its work to a utility class we are going to build, called SearchIndex.
We're also going to use our own class to transport the results between Lucene and the JSP, called SearchResults. This class will hold the hits from Lucene, along with the original search terms. More properties could be added to this class in the future to support new Lucene functionality.
For our query form, we will create a class that extends the Struts ActionForm class. The only property in this class will be called query and it will be a String.
The implementation of the search form can, therefore, be broken up into several pieces:
- The navigation links to the search form
- The JSP for the search form (this JSP will also display results if they exist)
- Modifying struts-config.xml
- The Struts Action for the query
- A class that interfaces with Lucene directly to retrieve search results from a query
- Navigation Links
The resources bundle of ApplicationResources.properties contains the navigation URLs. We had to add our path for the search engine form action to the bundle of header URLs. The relevant portion of this configuration is highlighted below:
# Sample ResourceBundle properties file #URL For the Login Screen #Header URLS javaedge.header.search=<a href="/javaedge/execute/SearchSetup">Search</a> ... #Search Form javaedge.search.form.text.header=Search JavaEdge javaedge.search.form.text.intro=Use the below form for searching JavaEdge javaedge.search.form.querylabel=Search terms
In addition to creating the link in the ApplicationResources.properties, we needed to update the navigation bar JSP file to show our search link. The relevant code is highlighted in the code listing for header.jsp below:
<%@ page language="java" %>
JSP Pages
There are two JSP pages for the search functionality. The first, searchForm.jsp, is a simple wrapper page that includes a title, a header, content, and footer inside a template:
<%@ page language="java" %> <%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean" %> <%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html" %> <%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic" %> <%@ taglib uri="/WEB-INF/struts-template.tld" prefix="template" %>
Our second page, searchFormContent.jsp, provides an HTML form for querying the search engine, and it also displays any query results. We're going to walk through this JSP page and explain it step-by-step.
The first part of the JSP page contains standard references to the language and tag libraries used:
<%@ page language="java" %> <%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean" %> <%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html" %>
The next tag library is Velocity. Velocity is a simple templating language we can use as a drop-in replacement for JSP syntax inside a JSP file. The Velocity tag library allows us to write Velocity code directly into our JSP page. We used Velocity for the search results to demonstrate how simple it can be. For the discussion on Velocity and installing the Velocity tag library, refer to Chapter 6.
<%@ taglib uri="/WEB-INF/veltag.tld" prefix="vel" %>
First, we display some header text at the top of the page. These messages are pulled out of the ApplicationResources.properties file in the WEB-INF/classes directory:
We use the Search action we've configured with Struts after we submit the form:
|
Struts can call the query setter on our form class (SearchForm): |
||||
This is the beginning of the Velocity code for the search results. We use the tag library we declared above. First, we check for the existence of an object called searchResults. If it exists, we need to display those results. If it doesn't exist, we won't run any more code on this page.
#if ($searchResults)
We'll set up some short names for properties on the searchResults object. Velocity uses shortcut syntax to reference properties that are really accessed with getter and setter methods:
#set($length = $searchResults.length) #set($hits = $searchResults.hits)
If we searched for something that wasn't in our index, we'll display a nice message telling the user we couldn't find anything for their terms:
#if ($length == 0) No Search results found for terms $searchResults.terms #else
Otherwise, we'll tell the user how many results they have:
$length Search Results present #set($docsLength = $length - 1)
We can iterate through our results. The hits object isn't an iterator, so we have to use a range ([0..$docsLength]) to move through our results. A future improvement would be to include paging for our results:
#foreach ($ctr in [0..$docsLength]) #set($doc = $hits.doc($ctr))
Here, we're making calls to the Lucene Document object to get the title field, rendered as a string. We do the same for the introduction:
$doc.getField("title").stringValue()
$doc.getField("introduction").stringValue()
The storyId is used to make a link to the full story:
#set($storyId = $doc.getField("storyId").stringValue())
<a href="/JavaEdge/execute/storyDetailSetup?storyId=
$storyId">Full Story</a>
#end
#end
#end
Configuring Struts for our Pages and Actions
For our search results page, we need to add entries to struts-config.xml. The relevant parts of the configuration file are highlighted below. The search form class had to be defined under the element so we could use it for the action mappings.
The action mappings are similar to other mappings we used for JavaEdge. One minor difference is that both of our actions use the same JSP page, which allows us to keep the search query code in one place.
... ...
Struts Forms and Actions
There are three classes associated with the search forms:
- SearchForm extends ActionForm and represents the form on the search page
- SearchFormSetupAction is used to set up the search form
- Search gets the search results from Lucene and puts them into the request
The Search action retrieves the query terms from the form bean, after checking to make sure the form is actually for the search engine. All of the work with Lucene is done by a utility class, called SearchIndex, so Search doesn't need to import any Lucene classes.
| Important |
It's good practice to keep your actions away from any back-end integration code you have, in case you need to switch web frameworks in the future, or you need to support non-web clients. |
Most of the Search action concerns itself with error checking and exception handling. We try to catch every exception before it bubbles up to the servlet runner. Instead of showing a stack trace or exception to the end user, we will display the system-failure error page for the JavaEdge application.
package com.wrox.javaedge.struts.search;
import java.io.IOException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.log4j.Logger;
import org.apache.lucene.queryParser.ParseException;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
import com.wrox.javaedge.search.SearchIndex;
import com.wrox.javaedge.search.SearchResults;
public class Search extends Action {
private static Logger logger = Logger.getLogger(Search.class);
public ActionForward execute (ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response){
logger.info("***Entering Search***");
if (!(form instanceof SearchForm)) {
logger.warn("Form passed to Search not an instance of SearchForm");
return (mapping.findForward("system.failure"));
}
// get the query from the form bean
String query = ((SearchForm)form).getQuery();
// get the search results
SearchIndex searchIndex = new SearchIndex();
SearchResults results = null;
try {
results = searchIndex.search(query);
logger.info("Found " + results.getLength() + " hits.");
} catch (IOException e) {
logger.error("IOException with search index for: " + query,e);
return (mapping.findForward("system.failure"));
} catch (ParseException e) {
logger.error("ParseException with search index for: " + query,e);
return (mapping.findForward("system.failure"));
}
// put the search results into the request
request.setAttribute("searchResults", results);
logger.info("***Leaving Search***");
return (mapping.findForward("search.success"));
}
}
The form we use for the search engine query isn't very complicated at all. It only has one property, query:
package com.wrox.javaedge.struts.search;
import javax.servlet.http.HttpServletRequest;
import org.apache.struts.action.ActionErrors;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionMapping;
import org.apache.struts.action.ActionServlet;
import org.apache.struts.util.MessageResources;
public class SearchForm extends ActionForm {
protected String query = "";
public ActionErrors validate(ActionMapping mapping,
HttpServletRequest request) {
ActionErrors errors = new ActionErrors();
return errors;
}
public void reset(ActionMapping mapping,
HttpServletRequest request) {
ActionServlet servlet = this.getServlet();
MessageResources messageResources = servlet.getResources();
}
public String getQuery() {
return query;
}
public void setQuery(String query) {
this.query = query;
}
}
The SearchFormSetupAction class for the search engine form doesn't do anything right now. It's possible that your form may need to change to support different uses. For now, we just have some skeleton code that can be used later for more advanced search form functionality:
package com.wrox.javaedge.struts.search;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionMapping;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import com.wrox.javaedge.member.*;
import com.wrox.javaedge.member.dao.*;
import com.wrox.javaedge.common.*;
import java.util.*;
public class SearchFormSetupAction extends Action {
// Performs no work for the action
public ActionForward perform(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response){
return (mapping.findForward("search.success"));
}
}
Utility Class for Lucene integration
The integration code for querying with Lucene is contained in one utility class, SearchIndex. This class takes a query string, and returns a SearchResults object, but doesn't contain any references to Struts, just as the action that calls it knows nothing about Lucene. If we ever need to move to another software package for either, this should make the task that much simpler:
package com.wrox.javaedge.search;
import java.io.IOException;
import java.util.*;
import org.apache.log4j.Logger;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.Searcher;
public class SearchIndex {
protected static Logger logger = Logger.getLogger(SearchIndex.class);
public SearchResults search(String terms)
throws IOException, ParseException {
First, we create a SearchResults object (we'll cover this class in the next section):
SearchResults results = new SearchResults();
logger.info("Search terms are: " + terms);
It's possible that someone has passed us a bad query string, and if they did, we'll log it, and give them back empty results. It's up to the JSP search results page to handle any error messages:
if (terms == null) {
logger.warn("Terms passed to SearchIndex are null");
return results;
}
The StandardAnalyzer we use here is the same analyzer we used to build the index. It's necessary to use the same analyzer to search the index as we used to build the index. Each analyzer processes words in fields into terms differently, and Lucene creates terms from the query and retrieves documents with matching terms from the index:
// set up our analyzer Analyzer analyzer = new StandardAnalyzer();
The searcher goes into the index that is stored on disk in segments and read it through. It then comes back with a set of hits:
// set up our searcher String indexPath = SearchConfiguration.getIndexPath(); Searcher searcher = new IndexSearcher(indexPath);
The query parser takes our search terms, the name of the field we are searching, and our analyzer. We had created a field that contains the text out of the other fields for use in searching. We'll find the stories we're looking for, even if the search terms are in the title, introduction, or comments and not the body of the story:
// create a query object out of our query Query query = QueryParser.parse(terms, DocumentConversionTool.CONTENT_FIELD, analyzer);
The searcher will give us the hits returned from the index for our query. The Hits class from Lucene only contains three methods. The length() method gives the number of hits from the current search. The doc() method retrieves the Lucene document from the index (passed in as a parameter), by position. The score() method gives you the score Lucene assigned to each document, based on its position in the results. We then fill up the results object with our hits, length, and terms:
// get all of the hits for the query term out of the index
Hits hits = searcher.search(query);
results.setHits(hits);
results.setLength(hits.length());
results.setTerms(terms);
if (hits == null) {
logger.info("Hits object is null for: " + terms);
}
// debugging
logger.info("Number of hits found for: "
+ terms + " is " + hits.length());
return results;
}
}
SearchResults Class
This class is a simple wrapper class that contains:
- The hits object, which points to each document that was found in the index
- The length of the hits object, which is the number of documents found
- The original terms used in the search form
This class is passed around between the action, the utility class, and the JSP content page:
package com.wrox.javaedge.search;
import org.apache.lucene.search.Hits;
public class SearchResults {
protected int length = 0;
protected Hits hits = null;
protected String terms = null;
public Hits getHits() {
return hits;
}
public int getLength() {
return length;
}
public void setHits(Hits hits) {
this.hits = hits;
}
public void setLength(int length) {
this.length = length;
}
public String getTerms() {
return terms;
}
public void setTerms(String terms) {
this.terms = terms;
}
}
Summary
In this chapter, we've discussed the issues of integrating Lucene into a Struts-based application. We've also used Velocity in our JSP page with the Velocity tag library. We've demonstrated keeping business logic or integration code out of our Struts action classes, and keeping Struts code out of our back-end integration classes.
Lucene is a well-built API for creating applications that use searches. We've shown that Lucene doesn't have to be used with HTML files over HTTP. On the contrary, it excels at integrating with existing content data stores.
For this integration, we created:
- A scheduler system that runs as a Struts plug-in to perform incremental indexing
- A conversion tool that translates JavaEdge stories and comments into native Lucene documents
- A utility class that takes a query string and returns Search Results
- JSP content and wrapper pages for the search form and results
- A simple demonstration of using Velocity inside JSP as a tag library
- A Struts action that sits between our JSP and our utility class and handles errors and exceptions
- An example that uses NekoHTML to parse text out of an HTML file.
In the final chapter, now that our JavaEdge application is complete, we'll look at how we can use the Ant build tool to coordinate all the various technologies we have covered in this book.
Introduction
- The Challenges of Web Application Development
- Creating a Struts-based MVC Application
- Form Presentation and Validation with Struts
- Managing Business Logic with Struts
- Building a Data Access Tier with ObjectRelationalBridge
- Templates and Velocity
- Creating a Search Engine with Lucene
- Building the JavaEdge Application with Ant and Anthill
EAN: 2147483647
Pages: 83
