Understanding Form Technologies
Highlights
In this chapter, you will learn how to
- Describe the files that InfoPath requires to define a form template and data document, and describe how InfoPath uses XPath to navigate a data document
- Relate the files in an InfoPath template to their corresponding World Wide Web Consortium (W3C) XML recommendations and use Internet Explorer 6.0 to test whether XML documents are well- formed
- Read a schema for a simple data document and validate a data document against its schema with the Microsoft XML Schema Definition (XSD) Validator tool
- Apply a custom XSLT transform to a modified data document and display it in Internet Explorer 6, and describe where and how InfoPath uses XHTML
For more information
- Refer to the section Modifying Data Documents for Display in Internet Explorer, in Chapter 2, which describes how to remove the processing instruction that causes InfoPath data files to open in Internet Explorer instead of InfoPath.
- Refer to the section Viewing the Status Report Document in Internet Explorer, in Chapter 2, which shows examples of Extensible Hypertext Markup Language (XHTML) formatting of rich text box content.
- Refer to Chapter 10, Adding Views to a Template, which describes adding multiple transforms to an InfoPath form.
Overview
To work through this chapter
- You should have a basic understanding of HTML. (You dont need to be a Web page designer.)
- You should have the sample files from the CD that accompanies this book installed in your C:Microsoft PressIntroducing InfoPath 2003 Chapter## folders.
Bill Gates introduced the concept of a universal canvas at the Forum 2000 conference, held on June 22, 2000, at Microsoft Corporations Redmond campus. Gates envisioned the universal canvas as a single browser-based UI for common computing activities: gathering information, generating documents, and managing time. All data flowing to and from the universal canvas numbers , text, graphics images, and other complex data types is contained in XML documents, defined by XML schemas, and transformed into HTML by XML style sheets. The universal canvas has not yet arrived, but InfoPath represents an initial step toward achieving Gatess goal. InfoPath uses the XML technologies that will implement the universal canvas.
Its not essential that you master InfoPaths underlying XML technologies, but you need a basic understanding of the W3C XML 1.0 and related recommendations before you begin designing InfoPath forms to accomplish specific data gathering tasks . Knowing how InfoPath handles XML namespaces, interprets or infers XML schemas, and renders XML data documents to HTML prevents false starts and radical form redesigns. By the time you reach the end of this chapter, youll be able to impress your boss and astonish your colleagues with your newfound knowledge of InfoPaths XML technologies.
Relating InfoPath s Components
You learned in the preceding two chapters that an InfoPath form consists of an InfoPath form template file ” also called a solution file ” and an XML data document. The template file is a cabinet file with a .xsn extension, similar to a .zip archive file, that contains compressed versions of the files required to define and render InfoPath data documents. WinZip version 8 or later can t create or extract CAB files, but WinZip can display the contents of a template file, as illustrated by Figure 3-1. When you open the FormName .xsn template file in design mode, InfoPath extracts the files, uncompresses them, and caches their contents in memory automatically. When you save your design changes, InfoPath updates the individual files and reincorporates them in the .xsn file.
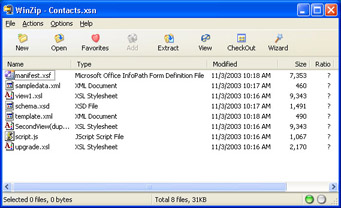
Figure 3-1: WinZip 8.1 SR-1 displays the contents of a simple template file.
Following are the names and descriptions of the files contained in a basic InfoPath template (.xsn) file:
- manifest.xsf The form definition file, which contains a list of all files in the template file, also called the package; global properties of the form, such as language and default view width; view properties; and application parameters, including the last form view you opened. The manifest.xsf file contains all the information needed to generate or re-create the .xsn file.
- sampledata.xml A data document that provides sample data for a form. Unless you specify use of sample data when you create a new form from an XML document, all sample leaf elements are empty.
- schema.xsd The XML schema for the form. The .xsd extension is an abbreviation of XML Schema Definition. The schema specifies the hierarchical structure of the form s data document and the data types of its leaf elements. When you create a form based on a data document instead of a schema, myschema.xsd replaces schema.xsd.
- script.js The file that contains the Microsoft JScript event-handling code for the form, unless Microsoft Visual Basic Scripting Edition (VBScript) was specified as the template s scripting language, in which case the file name is script.vbs. The default script.js or script.vbs file contains a single XDocument.DOM.setProperty expression. XDocument is InfoPath s data document class (called the InfoPath Object Model), and DOM is an acronym for the Microsoft XML Core Services (MSXML) Document Object Model. Chapter 16, Navigating the InfoPath Object Model, describes the XDocument.DOM object and its properties and methods .
- template.xml The XML data document that InfoPath uses to create a new, data document in memory. Form sections and HTML controls bind to the cached document s elements.
- view1.xsl The XSLT document that generates the HTML code for the default view. InfoPath renders the resulting HTML code to display the form in InfoPath s working area. Some InfoPath sample forms use view_1.xsl as the default view file name.
- ViewName .xsl The XSLT transforms that generate additional form views. ViewName is the name, with spaces removed, assigned in design mode to the additional view.
- internal.js The file that contains JScript code to change views of a form. This file is present only if the form was created in the original InfoPath release version and has more than one view. Like script.js, this file is named internal.vbs if VBScript is the form s default programming language.
Figure 3-2 illustrates the relationships between TemplateName .xsn, FormName .xml (a saved data document), and the files described in the preceding list. Files and relationships in gray apply only if the form has a second view. The script.js file isn t included in this diagram, because it s only meaningful if the design includes custom script code.
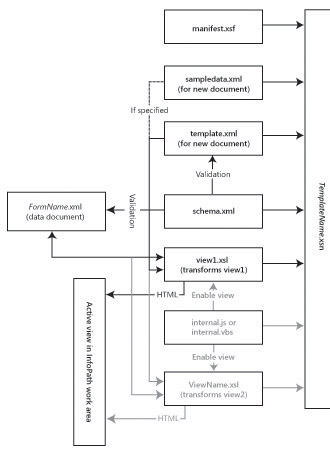
Figure 3-2: This diagram shows the primary files contained in an InfoPath template file and their relationships.
All files except the .js or .vbs scripts are XML 1.0 documents. The W3C recommendations don t specify the .xsd and .xsl file extensions for schema and transform documents, but these extensions have become standardized by common usage. You might see an .xslt extension for transform files occasionally. InfoPath projects include TemplateName.dll (a .NET 1.1 assembly file) and, when you build a form in debug mode, TemplateName.pdb (a debug symbols file.)
| Note |
Exploring the sample files for this chapter |
Spelunking the manifest xsf File
This chapter uses the Contacts form from Chapter 1 for many examples, because Contacts.xsn contains very simple schema and moderately complex transform files. Changes to the manifest.xsf file structure for complex forms, such as Chapter 2 s Status Report, are minor, as you ll discover when you reach this chapter s On Your Own section.
To open and explore the Contacts form s manifest.xsf file in Internet Explorer 6.0, follow these steps.
Open the manifest.xsf file in Internet Explorer 6.0
- Start Microsoft Windows Explorer, and navigate to the C:Microsoft Press Introducing InfoPath 2003Chapter03 Contacts folder.
- Right-click the manifest.xsf item, and choose Open With, Internet Explorer.
- If Internet Explorer doesn t appear as an Open With menu item, click Choose Program, select Internet Explorer in the Programs list, and click OK.
Figure 3-3 shows the beginning of manifest.xsf in Internet Explorer 6.0. Like all other InfoPath XML documents, the first line of manifest.xsf is the XML 1.0 declaration. All but a few element names in the file carry the xsf: namespace prefix, which is defined by the xmlns:xsf="http://schemas.microsoft.com/office/infopath/2003/solutionDefinition" namespace declaration. Only one of the other namespaces declared ( xd: for XDocument ) is used in this sample document. The section Understanding XML Namespaces, later in this chapter, explains how InfoPath uses XML namespaces.
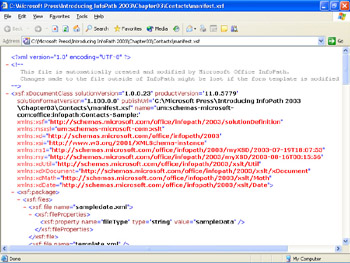
Figure 3-3: Internet Explorer 6.0 displays the beginning of the manifest.xsf file for the Contacts template.
Child elements of the < xsf:files > node define the file names and properties of the other files contained in the .xsn file. (This book uses node as a synonym for element .) Scrolling to the < xsf:views ... > node shows the properties of the two identical views and the Insert menu items that are defined for this version of the Contacts form. The < xsf:fragmentToInsert > node defines the empty element to add to the form when you choose Insert Contact from the repeating section s drop-down menu, as shown in Figure 3-4.
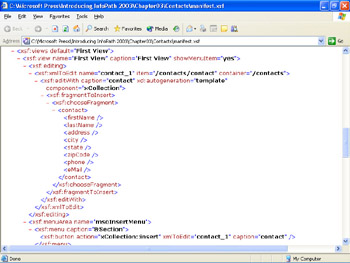
Figure 3-4: These are the initial nodes of manifest.xsf that define the available views of the form.
As you continue to scroll through the file s contents, you encounter < xsf:menuArea ... > nodes that define the drop-down menu s items for the repeating section and the View menu s first two items ”First View and Second View (Duplicate) for this example, as shown in Figure 3-5.
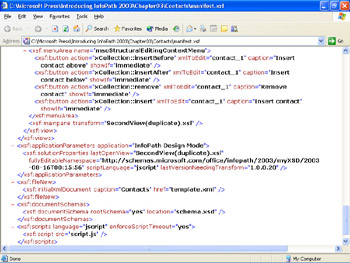
Figure 3-5: These nodes specify Insert and View menu items, the namespace for fields you add to the form, the file used for new forms, and the name of the schema file.
The remaining nodes specify the transform file for the second view, the namespace for elements you add to the schema (the same as the xmlns:my namespace at the top of the file), the empty template.xml file for new Contacts data documents, and the data document schema. Figure 3-4 doesn t include the last node, which specifies the default script language (JScript) and, for this example, internal.js for changing views.
Learning More About manifest xsf
InfoPath s online help system contains an InfoPath XSF Reference book that expands to display several XSF- related chapters and topics, which probably tell you more than you want to know about form definition files.
To open an XSF diagram and display the help topic for an XSF element, follow these steps.
Open an XSF diagram and display the help topic for an XSF element
- Open InfoPath with or without an active form, and press F1 to display the InfoPath Help task pane.
- Click the Table Of Contents link to open the Table Of Contents, and click InfoPath Developer s Reference to display its contents.
- Click to expand the InfoPath XSF Reference book, and click the InfoPath XSF Diagram to display the first few elements of the diagram, as shown in Figure 3-6 (left). Elements with red asterisks are optional.
- Click an element with a help topic, such as < documentSchemas > , to display the associated help file, as shown in Figure 3-6 (right).
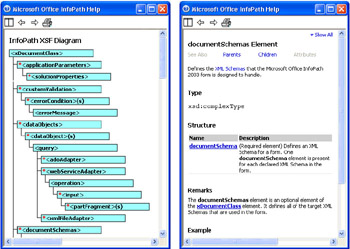
Figure 3-6: The first 16 elements of the InfoPath XSF Diagram are shown on the left, and the help topic for the < documentSchemas > element is shown on the right.
The XSF Diagram lists child elements of the root < xDocumentClass > node in alphabetical order. The position of the < documentSchemas > node is near the end of the .xsf file (refer to Figure 3-5). The relative position of nonleaf elements of the .xsf file isn t significant.
XSF help topics have Parents and Children links to open help files for elements higher and lower in the document s hierarchy. The < documentSchemas > node has only one child element (< documentSchemas >) and a single parent node (< xDocumentClass >). Most elements have several child nodes, and some, such as < query >, appear under multiple parent nodes. Links to child nodes also appear under the Structure heading. The Example section displays a sample node s contents.
Standardizing on XML Data Documents
Chapter 1 explained the benefits of a nonproprietary, open standard document format for exchanging information between desktop applications, local server-based systems or software components , remote servers, or all three. One of the primary advantages of text- based documents is their ability to emulate HTML traffic delivered by the HTTP to TCP port 80. Almost all corporate and personal firewalls permit unlimited two-way, HTTP transfer of text that s encoded as ordinary ASCII characters or their Unicode UTF-8 and UTF-16 counterparts. Firewalls that block port-80 traffic would prevent users with network connections behind the firewall from accessing the Internet.
| Note |
Blocking XML traffic |
Encoding Text
Encoding the world s alphabets and pictograms into standardized, computer-compatible binary data has been and still is an enormous task. XML is self-describing , but the encoding= ... attribute in the XML declaration line isn t. Following are the most common text encoding methods in use today, in the approximate order of their development:
- ASCII Abbreviation for the American Standard Code for Information Interchange, which uses seven binary bits to define 128 characters, including uppercase and lowercase letters of the English alphabet, numbers , punctuation symbols, and special control characters, such as horizontal tab, linefeed , and carriage return. The XML encoding attribute for ASCII is encoding= us-ascii , but specifying ASCII encoding of XML documents isn t a common practice. Internet Explorer versions 5.5 and earlier don t recognize this encoding; you receive a System does not support the specified encoding error message when you attempt to open the document; Internet Explorer 6.0 fixed this problem.
- EBCDIC Abbreviation for IBM s Extended Binary Coded Decimal Interchange Code for its mainframe computers. EBCDIC is an 8-bit encoding scheme that s related to but differs greatly from ASCII encoding. One of the objectives of the pending XML 1.1 recommendation is to permit use of EBCDIC-specific characters in XML documents. Translation between ASCII and EBCDIC is tricky, at best. EBCDIC isn t used for XML text encoding.
- ANSI Abbreviation for the American National Standards Institute. ANSI defines 128 additional characters based on ”but not identical to ”the ISO Latin-1 character set that s the default for Web browsers. The last four rows of the Microsoft Windows 95 and 98 CharMap applet display the ANSI extensions. You can specify ANSI (Windows) encoding for 14 alphabets in the Microsoft Windows 2000 and later and Windows XP CharMap applet by selecting the Advanced View check box and making a selection from the Character Set list. The encoding attribute for Windows: Western European is encoding= widows-1252 ; ISO Latin-1 uses encoding= ISO-8859-1 .
- Unicode Text-encoding system based on the Universal Character Set (UCS). UCS is an international standard ”ISO/IEC 1046-1 ”for a multibyte (more correctly, multi-octet ) encoding scheme that can handle most writing systems in use through the world. Unicode ”now quite mature at version 4.0 ”is a registered trademark of the Unicode Organization ( www.unicode.org ), whose members include most major software vendors . Unicode, which is the default text encoding method for Windows 2000 and later, Windows NT, and Windows XP, uses 16 bits to represent 63,000 different characters.
- UTF Abbreviation for Unicode (or UCS) Transformation Formats. Most, but not all, XML documents use one of the following UTF encoding formats:
- UTF-8 Encodes the standard 128 ASCII characters as single bytes, which makes UTF-8 and ASCII encoding compatible. Non-ASCII characters are encoded in 1-byte to 4-byte sequences or blocks. UTF-8 is becoming a more common format for encoding Web pages, especially those that use Extensible HTML (XHTML), and is the most common encoding scheme for XML documents. The encoding attribute for UTF-8 is, not surprisingly, encoding= UTF-8 , although you sometimes see encoding= utf-8 .
- UTF-16 A Unicode variant that extends to about 1 million the maximum number of different encoded characters. UTF-16 is less common than UTF-8 as a Web page and XML encoding format. A byte-order mark (BOM) at the beginning of a file distinguishes UTF-16 from UTF- 8 encoding. If the BOM is missing or not understood , the encoding attribute for UTF-16, encoding= UTF-16 , usually handles the problem.
The Internet Explorer versions 5.0 and later View, Encoding menu item lets you specify the encoding scheme, but it s better to turn on Auto-Select and let Internet Explorer determine the encoding. If Internet Explorer displays an encoding error message when opening an XML document, verify that the Auto-Select option is selected.
See Also You can learn more about Unicode, UTF-8, UTF-16, and the new UTF-32 encoding formats at www.unicode.org/faq/ . The Internet Engineering Taskforce (IETF) has an Internet Note on the relationship between UTF-8 and UCS encoding at www.ietf.org/rfc/rfc2279.txt .
Testing for Well Formed Data Documents
XML documents that serve as InfoPath data sources must be well-formed . When you design a new form, an easy method for creating the new form s data source is to modify an existing XML document or write a new one from scratch. Doing this requires that you know the definition of a well-formed document.
The Extensible Markup Language (XML) 1.0 (Second Edition) recommendation, paraphrased here, defines a well-formed XML document as having the following basic characteristics:
- The document must contain one or more elements. An element is defined by a start tag and an end tag or, for empty elements, the empty element tag.
- The names of an element s start tag and end tag must match.
- The document must contain a single root element, which also is known as the top- level element.
- All other document elements are descendants (children), of the root element. Child elements must be properly nested with matching start tags and end tags or employ empty tags.
- Processing instructions (PIs) are instructions to applications that process the document, and are not considered elements. Technically, PIs aren t part of the document s character data.
The XML 1.0 specification contains many other requirements for well-formed documents, such as restrictions on the attributes of an element, but the preceding list contains the most important requirements for elements.
| Note |
Comparing well-formed and malformed documents |
Internet Explorer performs a test for well-formed XML documents prior to applying its built-in XSLT formatting code. Figure 3-7 shows Contacts- WellFormed.xml open in Internet Explorer 6.0. You can collapse elements by clicking the minus sign prefix; when an element is collapsed , clicking the plus sign prefix expands it.
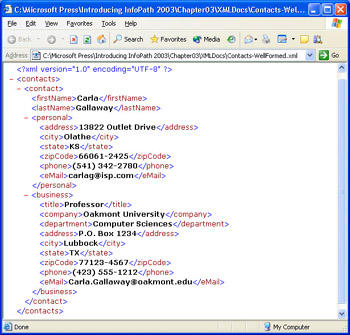
Figure 3-7: This is a well-formed XML document open in Internet Explorer 6.0.
The document s root, or top-level element is < contacts >; < contact > is a child element of the root, and has four child elements of its own: < firstName >, < lastName >, < personal >, and < business >. It s common practice to refer to these elements as grandchildren and their child elements as great-grandchildren of the root element. The < firstName >, < lastName >, and great-grandchildren elements are leaf nodes in this example. The four grandchild elements are called siblings , as are the three sets of leaf nodes.
The Zoology of Element Names
You ve probably noticed that the tag names used in InfoPath s sample forms and many of this book s examples begin with a lowercase word or prefix. If the names have two or more words, these words are internal caps, as in orderLineItems . Tag names must begin with a letter or an underscore and can t contain spaces or other common punctuation symbols, other than a colon (:), hyphen (-), underscore (_), or period (.). The colon is reserved for separating namespace prefixes from element names. Using internal caps to identify multiple words makes tag names more legible, although using the underscore as a word separator also solves the readability problem.
The common term for the lowercaseInternalCaps tag name format is camelCase , although there is some controversy as to the format s rules, as a visit to http://c2.com/cgi/wiki?CamelCase demonstrates . Some folks argue that camelCase should allow only one capitalized letter (which might be better named dromedaryCase, because a dromedary has one hump).
Lowercasing the initial word or abbreviation might have originated from naming conventions for C- language variables , called Hungarian notation , in which a lowercase prefix specifies the variable s data type, as in lpszLongPointerToAStringZeroTerminated . (The term Hungarian notation might have originated from the use of sz in the prefix, or from the birthplace ”Budapest ”of the notation s originator, Charles Simonyi.) There s no official standard for case in tag names, but remember to be consistent. XML, unlike Microsoft Visual Basic and Visual Basic for Applications (VBA), is case- sensitive .
| Note |
Generating friendly names from camelCase |
Troubleshooting Malformed Documents
If a document is malformed, Internet Explorer displays an error message to indicate the type of problem and its location. To learn how Internet Explorer handles malformed XML documents, follow these steps.
View a malformed XML document in Internet Explorer
- Start Windows Explorer, and navigate to the C:Microsoft PressIntroducing InfoPath 2003Chapter03XMLDocs folder.
- Double-click the Contacts-NoRoot.xml item to display it in Internet Explorer, which displays an Only one top-level element is allowed in an XML document error message and opens a message box.
- Click the Show Details button to expand the dialog box and display the line and character numbers to pinpoint where the error occurred, as shown here:
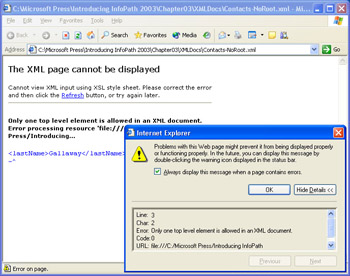
- Choose View, Source to open a temporary text copy of the errant document in Notepad, as shown here, with the line highlighted:
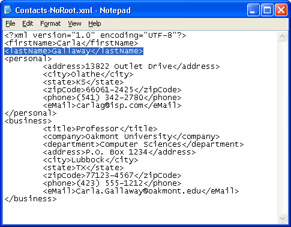
- Close Notepad, and repeat steps 2 through 4 for the Contacts-BadEndTag.xml and Contents- Mis-Nested.xml files. Use the line and character numbers to identify the error in the Notepad copy.
| Note |
Uncovering hidden malformations |
The errors in the three deliberately malformed documents are obvious, but tracking problems in long, complex documents isn t easy without Internet Explorer s assistance. When authoring InfoPath data source documents, give them a pass through Internet Explorer before attempting to create the form.
Avoiding Mixed Content
Mixed content consists of an element containing text and one or more child elements. Mixed content is quite common in XML files used by publishers, but not in XML Information Sets (infosets), which are the subject of the section Gathering Data into XML Infosets , later in this chapter. Figure 3-8 illustrates mixed content in the < contact > element of the Contacts-Mixed.xml file; the highlight emphasizes the added text that creates the mixed content.
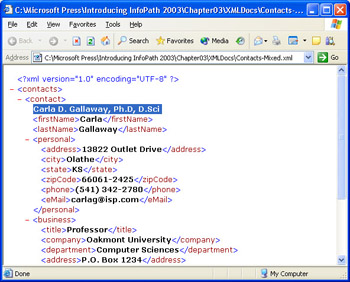
Figure 3-8: This member of the sample Contacts-*.xml documents contains mixed content.
InfoPath disregards mixed content when you create a data source from an XML document or an XML schema that specifies mixed= true in the element s definition. If the text of a mixed content element is important, add an element to contain the text, such as < fullName > ... < /fullName > for this example.
Understanding XML Namespaces
Gaining a full understanding of XML namespaces and how to use them properly in an XML document isn t a walk in the park. The purpose of XML namespaces is to prevent namespace collisions ” situations in which two software modules share the same tag name but interpret it differently. The W3C Namespaces in the XML recommendation (at www.w3.org/TR/REC-xml-names/ ) lists query processors, style-sheet-driven rendering engines, and schema-driven validators as typical software modules . InfoPath performs all three functions.
The W3C recommendation requires that namespaces be specified by a Universal Resource Identifier (URI), which takes the form of a unique URL, such as http://schema.oakleaf.ws/infopath/contacts , or a Universal Resource Name (URN) in the form urn:schemas-oakleaf-ws:infopath:contacts . Namespace names based on registered domain names, such as oakleaf.ws , can be made unique by extensions managed by the domain name s owner.
InfoPath uses URLs and URNs as namespace names in the manifest.xsf file, as illustrated by the following lines in the < xsf:xDocumentClass ... > root element tag that have an xmlns: namespace prefix:
| Note |
Opening namespace pages from URLs |
Figure 3-9 shows a modified version of the Contacts-WellFormed.xml file (Contacts- Namespace1.xml) with a default namespace declaration: xmlns= http://schemas.oakleaf.ws/ infopath/contacts . The default namespace applies to all elements of the document that don t have local namespace declarations. The < personal > and < business > elements have local namespace declarations, which apply to these elements and their children. In this example, the default namespace applies only to the root < contacts > node, its < contact > child node, and the < firstName > and < lastName > leaf nodes.
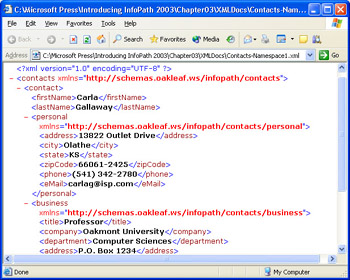
Figure 3-9: This XML document shows examples of default and local namespace declarations.
The more common method of defining namespaces is that used by InfoPath s .xsf files. In this case, you declare all namespaces as attributes of the root element and designate a namespace prefix in this format: xmlns:tns= This-NameSpace-URI , where tns is the prefix. You add the namespace prefix (also called a namespace qualifier ) with a colon separator to the element name, which becomes the local name . The Contacts- Namespace2.xml file, shown in Figure 3-10, takes this approach.
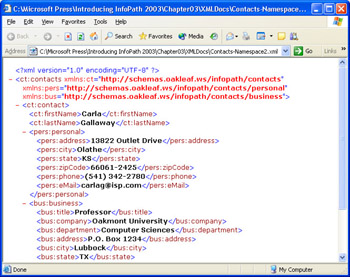
Figure 3-10: This document declares and assigns XML namespaces with namespace prefixes.
Using namespace prefixes minimizes ambiguities when a document contains elements from several different namespaces. When you create an InfoPath form from an XML document that uses either of the approaches described here, the resulting XML data documents reproduce the namespace assignments faithfully.
InfoPath makes extensive use of XML namespaces in its manifest, view, and schema files, but there s no absolute requirement that the XML documents you use as source documents for your forms use namespaces. If you expect to base your InfoPath form designs on documents that rely on namespaces, it s comforting to know that InfoPath provides full namespace support.
Gathering Data into XML Infosets
XML was used primarily for delivering the content of text documents, such as Web pages, when the W3C approved the original XML 1.0 recommendation in February 1998. Since then, it s become a common practice to use XML for representing a wide range of other data types, such as information extracted from databases and spreadsheets. The W3C XML Information Set (infoset) recommendation (at www.w3.org/TR/xml- infoset/ ) defines a formal information model for XML documents. Many XML purists consider the infoset to be the real XML and the XML 1.0 specification as a character- based syntax for XML infosets.
The infoset recommendation comprises a set of definitions for information items, which the editors describe as an abstract description of some part of an XML document: each information item has a set of associated named properties . The recommendation also specifies allowable properties for each information item. For example, the XML 1.0 specification allows element names to contain colons without defining how colons are used; a colon in an infoset element name is restricted to acting as a separator for namespace prefixes and local names.
A detailed analysis of the infoset recommendation is beyond the scope of this book. Simply put, InfoPath adheres to the infoset information model, so the XML data documents your forms produce are real XML.
Validating Documents with XML Schemas
XML is a simplified subset of the Standard Generalized Markup Language (SGML), which is an international standard document publishing format. SGML originated in the late 1980s and remains widely used for publishing complex documents, such as commercial aircraft maintenance manuals. The U.S. Government Printing Office uses SGML to publish the Federal Register and other official documents. SGML requires document type definitions (DTDs) to define the tags used for specifying the content and formatting of documents. One of the purposes of a DTD is to validate documents; validation means testing the contents of a document for conformance to a set of rules expressed in the DTD. A software module called a parser performs the validation.
The XML 1.0 specification adopted a simplified version of SGML DTDs to define the elements, attributes, and entities of a document. The most common example of entities is HTML s named entities, which substitute for characters , such as & amp; for the ampersand (&). Early XML developers wanted a simpler DTD version that could be expressed as an XML document. (The text format of a DTD doesn t comply with the XML 1.0 recommendation.) The result was W3C s three-part XML Schema recommendation, which turned out to be much more complex than XML DTDs. The moral of this story is: Be careful what you wish for, especially from a technical standards committee.
| See Also |
If you re interested in learning more about XML DTDs, the four-part DTD Tutorial at www.javacommerce.com/tutorial/xmlj/dtd.htm explains the DTD and its element, attribute, and entity definitions in detail. |
Constraining Element and Attribute Data Types and Values with XML Schemas
One of the primary benefits of XML schemas is their capability to define data type constraints for element contents and attribute values. DTDs assume that XML documents represent only textual information. An XML schema lets you select from a wide range of built-in data types, such as string (text), integer , decimal , date , dateTime , and many others ”you can even define your own custom data types. You can restrict the range of numeric values and string formats also. Listing 3-1, which is adapted from an example in the XML Schema Part 0: Primer recommendation, illustrates data type, value, and format constraints.
Listing 3-1: Part of an XML schema for a purchase order (from the W3C XML Schema Part 0: Primer recommendation).
The < xsd:restriction base="xsd:positiveInteger" > tag restricts the values of the < quantity > element to positive values, and < xsd:maxExclusive value="100"/ > specifies 100 as its maximum value. The < xsd:pattern value="d{3}-[A-Z]{2} / > regular expression restricts the user -defined SKU type for the partNum attribute value to a combination of three digits, a hyphen, and two capital letters . The ability of an XML schema to define data type constraints makes XML practical as a messaging format for database content, as you ll learn in Chapter 13.
| See Also |
You can view the data document (po.xml) and read a more detailed description of the purchase order schema (po.xsd) at www.w3.org/TR/xmlschema-0/ . The other two parts of the recommendation, XML Schema Part 1: Structures and XML Schema Part 2: Datatypes, are at www.w3.org/TR/xmlschema-1/ and www.w3.org/TR/xmlschema-2/ . |
Viewing a Simple InfoPath Schema
The schema for Chapter 1 s Contacts form is simpler than the W3C purchase order schema, because the data document contains non-numeric data and imposes no restrictions on the text content or format. XML schemas are well- formed XML documents, so Internet Explorer displays them with its built-in transform. Figure 3-11 shows part of the schema.xsd file in your C:Microsoft PressIntroducing InfoPath 2003Chapter03Contacts folder displayed in Internet Explorer 6.0. To get the most out of the following brief discussion of the file s contents, open schema.xsd in Internet Explorer.
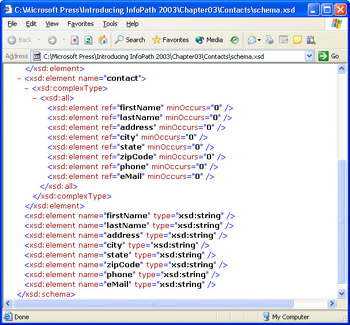
Figure 3-11: These are the last lines of the XML schema for the Contacts.xsn template s data documents.
InfoPath schemas define elements by their names and data types, as in < xsd:element name="firstName" type="xsd:string"/ > and refer in complexType elements to the element definition, as in < xsd:element ref="firstName" minOccurs="0"/ >. (A complexType element has more than one subelement.) The minOccurs="0" attribute indicates that the element is optional and infers that, if present, it can occur only once. Scrolling to the top of the schema exposes the < xsd:element ref="contact" minOccurs="0" maxOccurs="unbounded"/> definition for multiple subelements. Elements having the maxOccurs="unbounded" attribute bind to InfoPath repeating sections or tables.
Validating an XML Document to an InfoPath Schema
Internet Explorer tests for well-formed XML documents, but it doesn t validate them against a schema. Microsoft s GotDotNet site at www.gotdotnet.com offers an online validating parser that validates XML documents against XML schemas that reside on your PC.
To give the XSD Schema Validator a test drive, follow these steps
Test the XSD Schema Validator
- Start Internet Explorer, and open the XSD Schema Validator, at
- http://apps.gotdotnet.com/xmltools/xsdvalidator/ .Click the Schema Document s Browse button to open the Choose File dialog box.
- Navigate to C:Microsoft PressIntroducing Infopath 2003Chapter03Contacts, and double- click schema.xsd to close the dialog box.
- Leave the Namespace URI text box empty, because Contacts.xsd and Contacts.xml don t have a namespace declaration. Technically speaking, Contacts.xml s elements don t belong to a namespace.
- Click the Browse button next to the XML Document field, and double-click Contacts.xml.
- Click the Submit button to validate Contacts.xml against its schema, as shown on the next page.
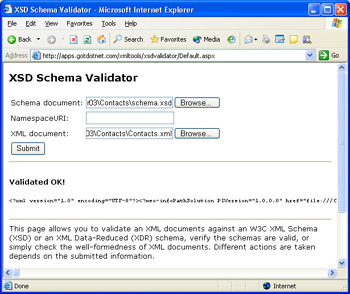
- Repeat steps 3 through 6, but substitute Contacts-Invalid.xml for Contacts.xml in step 5. You receive a Validation error message because the first contact substitutes < givenName > for < firstName > and < familyName > for < lastName > . Red text describes the errors and gives their locations by line and character number.
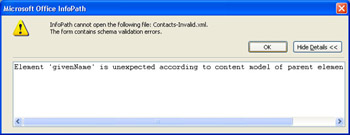
- Double-click Contacts-Invalid.xml in Windows Explorer to attempt opening it in InfoPath. You ll get the error message shown here when you click the Show Details button. InfoPath shows the first error only and doesn t provide the row and character location of the error.
You ll find the XSD Schema Validator tool handy when you modify data documents or schemas manually for use in creating your own forms. It s a good practice to validate a data document against its schema ”or vice versa ”before basing a form design on either file.
Navigating Documents with XPath
InfoPath uses XPath 1.0 to locate specific nodes of a document, return node values, manipulate text, and perform calculations on numeric values. XPath is InfoPath s only XML technology that isn t represented by XML documents; XSLT form views use XPath expressions to select the XML data document s element and attribute values to appear in HTML controls. The declarative conditional formatting and data validation rules you add to forms generate XPath expressions to perform the tests.
| See Also |
The Microsoft XML Core Services (MSXML) 3.0 parser was the first version to support XSLT 1.0 and XPath 1.0. Installing Microsoft Office System 2003 or InfoPath installs MSXML 5.0. To learn more about XPath, search for XPath Developer (with the quotation marks) at msdn.microsoft.com to find the latest version of the XPath Developer s Guide. The W3C XML Path Language (XPath) 1.0 specification, at www.w3.org/TR/xpath , describes XPath syntax in turgid detail. XPath 2.0 ( www.w3.org/TR/xpath20/ ) was in the working draft stage when this book was written. |
Your introduction to XPath in Chapter 6, Adding Basic Controls and Lists, will involve writing XPath expressions to calculate expression box values. The OrderEdit.xsn template that you create in Chapter 13, Connecting Forms to Databases, uses the XPath expression shown in Figure 3-12 to calculate the extended values of order line items.
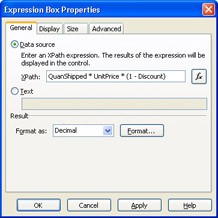
Figure 3-12: An XPath expression for calculating order line items totals.
XPath s @ name expression returns the value of an attribute; omitting @ returns the value of an element. If the value is a number, you can specify XPath s numeric operators ” such as + , -, * , and div ” to return calculated values. The @Quantity * @UnitPrice * (1 - @Discount) expression in Figure 3-12 calculates the total net amount of each line item of an order in Microsoft Access s NorthwindCS sample database and displays it in the Extended column s expression boxes, as illustrated by Figure 3-13. Fortunately, you don t need a full understanding of XPath syntax to create formulas. InfoPath s Insert Formula dialog box generates XPath statements from combinations of field names , operators, and functions that you select from lists or type in a text box.
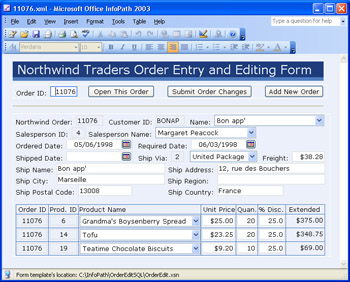
Figure 3-13: The extended line item values are calculated by the XPath expression in Figure 3-12.
At this point, you need to be aware only that XPath is integrated with XSLT and is an important element of InfoPath form development. XPath provides the compass for navigating InfoPath s XML DOM with JScript, VBScript, Visual Basic .NET, or Visual C# .NET code. InfoPath s sample forms and the examples in Part IV of this book, Programming InfoPath Forms, make extensive use of XPath expressions in programming code.
Presenting Form Views with XSLT
XSLT is a language for transforming an XML document (called the source tree ) into another document (the result tree ). The most common use of XSLT is transforming XML documents into HTML or XHTML Web pages, but XSLT also can transform XML documents into other XML documents, plain text, and comma-separated values. XSLT is a declarative language, not a procedural language like VBA, Visual Basic .NET, JScript, or VBScript. You define rules for the transformation, and the XSLT processor (MSXML5 for InfoPath) establishes the sequence of operations required to complete the task. A template contains the transformation rules, which use XPath expressions to specify values that the transform assigns to the output document.
Working with a Simplified Style Sheet
InfoPath s default view1.xsl template is a forbiddingly complex document, even for the very rudimentary Contacts form. A simple transform is the best approach to gaining a basic understanding of how XSLT works. Fortunately, XSLT has an abbreviated syntax to make writing style sheets easier for XSLT beginners who have basic HTML authoring skills. Listing 3-2 is the abbreviated XSLT template to transform a modified version of Contacts.xml (Contacts-Simplified.xml) to a formatted HTML table that s sorted by ZIP Code.
Listing 3-2: This simplified transform syntax renders an XML document as a formatted XHTML table.
Oakmont Contacts
| Oakmont Contacts Sorted by Zip Code | |||||
|---|---|---|---|---|---|
The < html xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xsl:version = "1.0" > namespace declaration in the root element designates all elements with the xsl: prefix as XSLT template rules. The transform copies the HTML tags and their contents to the HTML document.
Here s a brief explanation of the purpose of the template rules in Listing 3-2:
- The < xsl:for-each select="//contact" > rule instructs the processor to inspect each descendant node of the root node. ( // is XPath shorthand for children of the current node, which is the root node by default.)
- The < xsl:sort select="zipCode" / > instruction sorts the resulting document by ZIP Code.
- The < td >< xsl:value-of select="elementName" / >< /td > instructions insert the value of the specified element in the corresponding cell of the table.
Internet Explorer 6.0 uses MSXML s XSLT processor to apply transforms to XML data documents and display the resulting document. To specify the appropriate .xsl file, you add this XSLT PI immediately after the document s XML declaration: < ?xml:stylesheet type="text/xsl" href="Filename.xsl"? >. (The href="Filename.xsl" attribute value assumes that the .xml and .xls files are in the same folder. If not, prefix the file name with its full path or specify a URL to a Web-accessible template.) Figure 3-14 shows the Contacts-SimplifiedSS.xml file transformed by SimplifiedSS.xsl, which applies Contacts.css ”a cascading style sheet (CSS) file ”to format the table. All three files are in your C:Microsoft PressIntroducing InfoPath 2003 Chapter03XSLT folder; double- click Contacts-SimplifiedSS.xml to open the files in Internet Explorer.
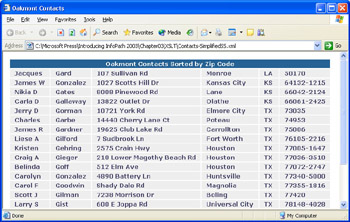
Figure 3-14: This formatted HTML table was generated by transforming the sample XML file with the simplified style sheet from Listing 3-2.
| See Also |
The W3C XSL Transform 1.0 specification at www.w3.org/TR/xpath describes XPATH documents in prose that s best described as a sure cure for insomnia. For a more readable explanation of XSLT techniques, search for XSLT Developer at msdn.microsoft.com to find the current version of the XSLT Developer s Guide. |
Upgrading to Conventional Style Sheets
Simplified style sheets have limitations, which makes them suitable only for basic transformation tasks . InfoPath uses conventional style sheets, which include < xsl:stylesheet > and < xsl:template match= / > or < xsl:template match= rootName > elements. Listing 3-3 shows the standard version of the style sheet in Listing 3-2, with a sort on < lastName >, and the < firstName > and < lastName > elements combined with the XPath concat string concatenation function. The < xsl:output method="html" indent="yes" / > line is optional, but adding it is a good XSLT programming practice.
Oakmont Contacts
| Oakmont Contacts Sorted by Last Name | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
To see the effect of the < td >< xsl:value-of select="concat(firstName, ' ', lastName)" / >< /td > rule on the HTML table design, double-click the Contacts-StandardSS.xml document item.
Displaying a Document with an InfoPath Transform
The Contacts-InfoPathSS.xml file in your C:Microsoft PressIntroducing InfoPath 2003Chapter03XSLT folder uses a copy of the view1.xsl transform from the ...Contacts folder. Double-click Contacts-InfoPathSS.xml to display a static version of the Contacts form in Internet Explorer 6.0, as shown in Figure 3-15. This version is identical to the exported Contacts_FirstView.mht file in the ...Contacts folder ”a whopping 126 KB of inscrutable HTML code.
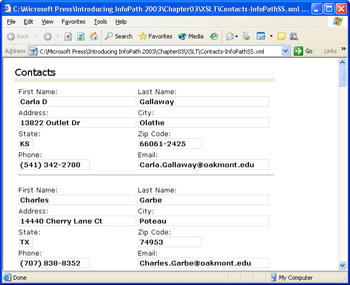
Figure 3-15: Applying the view1 transform to the Contacts-InfoPathSS.xml data document generates a 126-KB inanimate clone of InfoPath s version of the form.
Transforming an XML data document with the corresponding InfoPath view s transform applies the form s styles to the HTML rendition , but not the behavior of the HTML controls. Double-click view1.xsl to see why a detailed explanation of InfoPath s template rules would require more than the number of pages in this chapter.
| See Also |
The Microsoft Office InfoPath 2003 Software Development Kit (SDK) installs a Downlevel command-line tool that you can use to automate generation of static HTML versions of forms. |
Displaying Rich Text as XHTML
The section Formatting Rich Text Data, in Chapter 2, introduced you to XHTML. The W3C XHTML 1.0 The Extensible HyperText Markup Language (Second Edition) recommendation calls XHTML a reformulation of HTML 4 as an XML 1.0 application. The XHTML specification imposes a set of rules for expressing HTML 4.01 content as a well- formed XML document. The most evident XHTML rule is this: HTML element and attribute tag names must be all lowercase (not camelCase). There is a growing trend among Web page authors to replace traditional capitalized tag names with lowercase versions in anticipation of moving to XHTML 1.0 or a later version.
| See Also |
The W3C XHTML 1.0 recommendation, at www.w3.org/TR/xhtml1/ , is an XHTML document that conforms to the XHTML 1.0 Strict requirements. Open the document in Internet Explorer, and choose View, Source to display its contents in Notepad. There are several W3C XHTML recommendations; visit www.w3.org/MarkUp/ for a list of ”and links to ”the other recommendations. |
InfoPath s transforms don t generate XHTML to render forms; InfoPath uses XHTML to apply formatting to rich text box contents only. The section Viewing the Status Report Document in Internet Explorer, in Chapter 2, shows part of the XHTML content of the Status Report form s < sr:summary > and < sr:notes > elements. XHTML embedded in XML data documents requires a local xmlns="http://www.w3.org/1999/xhtml" namespace declaration and embedded CSS for formatting.
Summary
InfoPath forms are created from an InfoPath template file (.xsn), which contains compressed versions of the files required to define the forms design, render the form in InfoPaths work area, and validate XML data documents. The manifest.xsf file contains a list of the files required by the template, which include the schema for the data document (schema.xsd or myschema.xsd), at least one XSLT file to define the default form view (view1.xsl), XML files used when opening an empty form (template.xml and sampledata.xml), and script files (script.js and, in some instances, internal.js).
InfoPath forms are based on W3C standards that were current when Microsoft first released InfoPath 2003 in October 2003. All files, except programming script (.js or .vbs) files, conform to the XML 1.0 specification. Schemas for validating data documents meet the requirements of parts 0, 1, and 2 of the W3C XML Schema recommendation. Transforms for views comply with the XSLT 1.0 and XPath 1.0 recommendations. InfoPath uses XHTML 1.0 syntax to format the content of rich text box controls. Contrary to a few computer press analysts reports , InfoPath does not use Microsoft-proprietary schemas to generate XML data documents. You can define your own data documents with almost any schema you create yourself or obtain from someone else. The basic requirement is that the schema conform to the W3C XML Schema recommendation.
Q A
|
1. |
Do I need to know XPath and XSLT syntax to design InfoPath forms? |
|
|
2. |
Is a data document opened in Internet Explorer with an InfoPath transform an exact duplicate of the exported .mht version? |
|
|
3. |
Does a data document that I modify to open in Internet Explorer with an InfoPath transform PI enable users without InfoPath to edit the document? |
|
|
4. |
I ve heard of a W3C proposed recommendation called XForms. Does InfoPath support XForms? |
|
|
5. |
Can I modify an InfoPath style sheet to customize a view? |
|
Answers
|
1. |
No. InfoPath interactively builds the XSLT transform body with the required XPath expressions as you add sections, tables, HTML controls, and validation rules to views in design mode. The XPath expressions you use to calculate expression box values are simple ”they resemble ordinary math notation (except div for division). Customizing forms with JScript or VBScript requires some familiarity ”but not expertise ”with XPath. |
|
2. |
Almost. The primary difference is that pictures you add to rich text boxes are missing, as you ll see when you complete the following On Your Own section. |
|
3. |
No. Users must have InfoPath installed on their computers to create new documents or edit existing documents. Adding the PI for the transform prevents InfoPath from opening the form. |
|
4. |
No. XForms share many of the objectives of InfoPath, such as separation of form presentation and form data, which XForms calls instance data , and data validation. InfoPath relies on the XML Schema and XSLT standards to create form views that contain HTML- based controls. XForms are intended primarily for browser-based data capture applications from a variety of devices. InfoPath is a conventional, thick-client Windows application, similar to the other Microsoft Office applications. For more information about XForms, go to www.w3.org/MarkUp/Forms/ . |
|
5. |
Yes, but it s much easier and less error-prone to customize views in InfoPath s design mode, which is the subject of Chapter 5, Laying Out Forms ; Chapter 7, Formatting Forms ; and Chapter 10, Adding Views to a Template. You also lose the changes you make to the style sheet when you redesign a view. Chapter 17, Writing Advanced Event Handlers, shows you how to preserve the template changes you must make to display in expression boxes values that you calculate with Visual Basic .NET code. |
On Your Own
Heres an additional exercise to learn more about the XML technologies described in this chapter:
- Navigate to your C:Microsoft PressIntroducing InfoPath 2003Chapter03 StatusReport folder.
- Right-click StatusReport.xsn, and choose Design from the shortcut menu to open the template in design mode.
- Choose File, Extract Form Files to open the Browse For Folder dialog box.
- Accept the default location (the current folder), and click OK to extract and decompress the files, which include a secondary data source file (currencies.xml) and its schema (currencies.xsd), and a custom aggregation template (agg.xsl) for merging Status Report data documents.
- Double-click currencies.xml to display it in Internet Explorer. The currency file provides the data source for the Currency drop-down list.
- Open currencies.xsd to view the very simple schema for currencies.xml.
- Double-click SR6789-1.xml, which has been modified to apply the view_1.xsl transform in Internet Explorer rather than in InfoPath.
- Right-click SR6789-1.xml, and choose Microsoft Office InfoPath to attempt to open the modified document in InfoPath. Youll receive a error message as a result of the modifications.
- Scroll to the Notes rich text box, which is missing the image you added in Chapter 2. Displaying embedded images outside of InfoPath requires you to export the form in Web Archive Single-File (.mht) format.
- Open and explore the other files you extracted from StatusReport.xsn in Internet Explorer or Notepad. Use Notepad to open the script.js file, which contains several event-handling functions and many other functions for calculating dates and values.
- Close InfoPath, and proceed to Chapter 4.
Part I - Introducing Microsoft Office InfoPath 2003 SP-1
Part II - Designing InfoPath Forms
- Creating Forms
- Laying Out Forms
- Adding Basic Controls and Lists
- Formatting Forms
- Validating Form Data
- Working with Advanced Form Elements
- Adding Views to a Template
- Setting Form Template and Digital Signing Options
- Publishing Form Templates
Part III - Working with Databases and Web Services
Part IV - Programming InfoPath Forms
EAN: 2147483647
Pages: 248
