Creating, Destroying, and Viewing Databases
Before you can do anything else with a PostgreSQL database, you must first create the database. Before you get too much further, it might be a good idea to see where a data base fits into the overall scheme of PostgreSQL. Figure 3.1 shows the relationships between clusters, databases, schemas, and tables.
Figure 3.1. Clusters, databases, schemas, and tables.
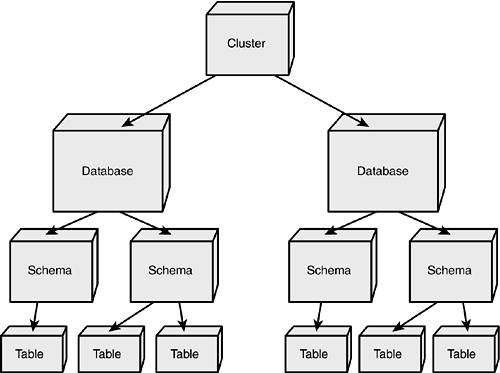
At the highest level of the PostgreSQL storage hierarchy is the cluster. A cluster is a collection of databases. Each cluster exists within a single directory tree, and the entire cluster is serviced by a single postmaster. A cluster is not namedthere is no way to refer to a cluster within PostgreSQL, other than by contacting the postmaster servicing that cluster. The $PGDATA environment variable should point to the root of the cluster's directory tree. A cluster is serviced by a single postmaster process. The postmaster listens for connection requests coming from client applications. When a connection request is received (and the user's credentials are authenticated), the postmaster starts a new server process and connects the client to the server. A single client connection can only interact with a single database at any given time (but a client application can certainly open multiple connections if it needs to interact with several databases simultaneously). A postmaster process can connect a client application to any of the databases in the cluster serviced by that postmaster.
Four system tables are shared between all databases in a cluster: pg_group (the list of user groups), pg_database (the list of databases within the cluster), pg_shadow (the list of valid users), and pg_tablespace (the list of tablespaces).
Each cluster contains one or more databases. Every database has a name that must follow the naming rules described in the previous section. Database names must be unique within a cluster. A database is a collection of schemas.
A schema is a named collection of tables (as well as functions, data types, and operators). The schema name must be unique within a database. Table names, function names, index names, type names, and operators must be unique within the schema. A schema exists primarily to provide a naming context. You can refer to an object in any schema within a single database by prefixing the object name with schema-name. For example, if you have a schema named bruce, you can create a table within that schema as
CREATE TABLE bruce.ratings ( ... ); SELECT * FROM bruce.ratings;
Each connection has a schema search path. If the object that you are referring to is found on the search path, you can omit the schema name. However, because table names are not required to be unique within a database, you may find that there are two tables with the same name within your search path (or a table may not be in your search path at all). In those circumstances, you can include the schema name to remove any ambiguity.
To view the schema search path, use the command SHOW SEARCH_PATH:
movies=# SHOW SEARCH_PATH; search_path -------------- $user,public (1 row)
The default search path, shown here, is $user,public. The $user part equates to your PostgreSQL user name. For example, if I connect to psql as user bruce, my search path is bruce,public. If a schema named bruce does not exist, PostgreSQL will just ignore that part of the search path and move on to the schema named public. To change the search path, use SET SEARCH_PATH TO:
movies=# SET SEARCH_PATH TO 'bruce','sheila','public'; SET
You create a new schema with the CREATE SCHEMA command and destroy a schema with the DROP SCHEMA command:
movies=# CREATE SCHEMA bruce; CREATE SCHEMA movies=# CREATE TABLE bruces_table( pkey INTEGER ); CREATE TABLE movies=# d List of relations Name | Schema | Type | Owner ----------------+--------+-------+------- bruces_table | bruce | table | bruce tapes | public | table | bruce (2 rows) movies=# DROP SCHEMA bruce; ERROR: Cannot drop schema bruce because other objects depend on it Use DROP ... CASCADE to drop the dependent objects too movies=# DROP SCHEMA bruce CASCADE; NOTICE: Drop cascades to table bruces_table DROP SCHEMA
Notice that you won't be able to drop a schema that is not empty unless you include the CASCADE clause. Schemas are a relatively new feature that first appeared in PostgreSQL version 7.3. Schemas are very useful. At many sites, you may need to keep a "development" system and a "production" system. You might consider keeping both systems in the same database, but in separate schemas. Another (particularly clever) use of schemas is to separate financial data by year. For example, you might want to keep one year's worth of data per schema. The table names (invoices, sales, and so on) remain the same across all schemas, but the schema name reflects the year to which the data applies. You could then refer to data for 2001 as FY2001.invoices, FY2001.sales, and so on. The data for 2002 would be stored in FY2002.invoices, FY2002.sales, and so on. This is a difficult problem to solve without schemas because PostgreSQL does not support cross-database access. In other words, if you are connected to database movies, you can't access tables stored in another database. Starting with PostgreSQL 7.3, you can keep all your data in a single database and use schemas to partition the data.
When you create a schema, you can specify an optional tablespaceby default, tables created within the schema will be stored in the schema's tablespace. We discuss tablespaces in more detail in the nextwith the CREATE SCHEMA section.
Tablespaces
Starting with PostgreSQL version 8.0, you can store database objects (tables and indexes) in alternate locations using a new feature called a tablespace. A tablespace is a name that you give to some directory within your computer's filesystem. Once you create a tablespace (we'll show you how in a moment), you can create schemas, tables, and indexes within that tablespace. A tablespace is defined within a single clusterall databases within a cluster can refer to the same tablespace.
To create a new tablespace, use the CREATE TABLESPACE command:
CREATE TABLESPACE tablespacename [ OWNER username ] LOCATION 'directory'
The tablespacename parameter must satisfy the normal rules for all identifiers; it must be 63 characters or shorter and must start with a letter (or the name must be quoted). In addition, you can't create a tablespace whose name begins with the characters 'pg_' since those names are reserved for the PostgreSQL development team. If you omit the OWNER username clause, the new tablespace is owned by the user executing the CREATE TABLESPACE command. By default, you can't create an object in a tablespace unless you are the owner of that tablespace (or you are a PostgreSQL superuser). You can grant CREATE privileges to other users with the GRANT command (see Chapter 23, "Security" for more information on the GRANT command).
The interesting part of a CREATE TABLESPACE command is the LOCATION 'directory' clause. The LOCATION clause includes a directoryobjects created within the tablespace are stored in that directory. There are a few rules that you must follow before you can create a tablespace:
- You must be a PostgreSQL superuser
- PostgreSQL must be running on a system that supports symbolic links (that means you can't create tablespaces on a Windows host)
- The directory must already exist (PostgreSQL won't create the directory for you)
- The directory must be empty
- The directory name must be shorter than 991 characters
- The directory must be owned by the owner of the postmaster process (typically a user named postgres)
If all of those conditions are satisfied, PostgreSQL creates the new tablespace.
When you create a tablespace, the PostgreSQL server performs a number of actions behind the scenes. First, the permissions on the directory are changed to 700 (read, write, and execute permissions for the directory owner, all other permissions denied). Next, PostgreSQL creates a single file named PG_VERSION in the given directory (the PG_VERSION file stores the version number of the PostgreSQL server that created the tablespaceif the PostgreSQL developers change the structure of a tablespace in a future version, PG_VERSION will help any conversion tools understand the structure of an existing tablespace). If the permission change succeeds, PostgreSQL adds a new row to the pg_tablespace table (a cluster-wide table) and assigns a new OID (object-id) to that row. Next, the server uses the OID to create a symbolic link between your cluster and the given directory. For example, consider the following scenario:
movies# CREATE TABLESPACE mytablespace LOCATION '/fastDrive/pg'; CREATE TABLESPACE movies# SELECT oid, spcname, spclocation movies-# FROM movies-# pg_tablespace movies-# WHERE movies-# spcname = 'mytablespace'; oid | spcname | spclocation -------+--------------+-------------- 34281 | mytablespace | /fastDrive/pg
In this case, PostgreSQL assigned the new tablespace (mytablespace) an OID of 34281. PostgreSQL creates a symbolic link that points from $PGDATA/pg_tblspc/34281 to /fastDrive/pg. When you create an object (a table or index) inside of this tablespace, the object is not created directly inside of the /fastDrive/pg directory. Instead, PostgreSQL creates a subdirectory in the tablespace and then creates the object within that subdirectory. The name of the subdirectory corresponds to the OID of the database (that is, the object-id of the database's entry in the pg_database table) that holds the new object. If you create a new table within the mytablespace tablespace, like this:
movies# CREATE TABLE foo ( data VARCHAR ) TABLESPACE mytablespace; CREATE TABLE
Then find the OID of the new table and the OID of the database (movies):
movies# SELECT oid FROM pg_class WHERE relname = 'foo'; oid ------- 34282 (1 row) movies# SELECT oid FROM pg_database WHERE datname = 'movies'; oid ------- 17228 (1 row)
You can see the relationships between the tablespace, the database subdirectory, and the new table:
$ ls -l $PGDATA/pg_tblspc total 0 lrwxrwxrwx 1 postgres postgres 12 Nov 9 19:31 34281 -> /fastDrive/pg $ ls -l /fastDrive/pg total 8 drwx------ 2 postgres postgres 4096 Nov 9 19:50 17228 -rw------- 1 postgres postgres 4 Nov 9 19:31 PG_VERSION $ ls -l /fastDrive/pg/17228 total 0 -rw------- 1 postgres postgres 0 Nov 9 19:50 34282
Notice that $PGDATA/pg_tblspc/34281 is a symbolic link that points to /fastDrive/pg (34281 is the OID of mytablespace's entry in the pg_tablespace table), PostgreSQL has created a subdirectory (17228) for the movies database, and the table named foo was created in that subdirectory (in a file whose name, 34282, corresponds to the table's OID). By creating a subdirectory for each database, PostgreSQL ensures that you can safely store objects from multiple databases within the same tablespace without worrying about OID collisions.
When you create a cluster (which is done for you automatically when you install PostgreSQL), PostgreSQL silently creates two tablespaces for you: pg_default and pg_global. PostgreSQL creates objects in the pg_default tablespace when it can't find a more appropriate tablespace. The pg_default tablespace is always located in the $PGDATA/base directory. The pg_global tablespace stores cluster-wide tables like pg_database, pg_group, and pg_tablespaceyou can't create objects in the pg_global tablespace.
The name of the pg_default tablespace can be a bit misleading. You may think that PostgreSQL always creates an object in pg_default if you omit the TABLESPACE tablespacename clause, but that's not the case. Instead, PostgreSQL follows an inheritance hierarchy to find the appropriate tablespace. If you specify a TABLESPACE tablespacename clause when you execute a CREATE TABLE or CREATE INDEX command, the server creates the object in the given tablespacename. If you don't specify a tablespace and you're creating an index, the index is created in the tablespace of the parent table (that is, the table that you are indexing). If you don't specify a tablespace and you're creating a table, the table is created in the tablespace of the parent schema. If you are creating a schema and you don't specify a tablespace, the schema is created in the tablespace of the parent database. If you are creating a database and you don't specify a tablespace, the database is created in the tablespace of the template database (typically, template1). So, an index inherits its tablespace from the parent table, a table inherits its tablespace from the parent schema, a schema inherits its tablespace from the parent database, and a database inherits its database from the template database.
To view the databases defined in a cluster, use the db (or db+) command in psql:
movies=# db+
List of tablespaces
Name | Owner | Location | Access privileges
--------------+----------+------------------+------------------
mytablespace | postgres | /fastDrive/pg |
pg_default | postgres | |
pg_global | postgres | | {pg=C/pg}
(4 rows)
To see a list of objects defined with a given tablespace, use the following query:
SELECT relname FROM pg_class WHERE reltablespace = ( SELECT oid FROM pg_tablespace WHERE spcname = 'tablespacename' );
Don't confuse schemas and tablespacesthey both provide organization for the tables and indexes in your cluster, but they are definitely not the same thing. A tablespace affects the physical organization of data within a cluster (that is, it a tablespace defines where your data is stored). A schema affects the logical organization of data within a databasea schema affects name resolution; a tablespace does not. A schema acts as a part of a name; once you've created an object, you can ignore its physical location (its tablespace).
Creating New Databases
Now let's see how to create a new database and how to remove an existing one.
The syntax for the CREATE DATABASE command is
CREATE DATABASE database-name
[ WITH [ OWNER [=] {username|DEFAULT}]
[ TEMPLATE [=] {template-name|DEFAULT}]
[ ENCODING [=] {encoding|DEFAULT}]
[ TABLESPACE [=] tablespace ]]
As I mentioned earlier, the database-name must follow the PostgreSQL naming rules described earlier and must be unique within the cluster.
If you don't include the OWNER=username clause or you specify OWNER=DEFAULT, you become the owner of the database. If you are a PostgreSQL superuser, you can create a database that will be owned by another user using the OWNER=username clause. If you are not a PostgreSQL superuser, you can still create a database if you have the CREATEDB privilege, but you cannot assign ownership to another user. Chapter 21, "PostgreSQL Administration," describes the process of defining user privileges.
The TEMPLATE=template-name clause is used to specify a template database. A template defines a starting point for a database. If you don't include a TEMPLATE=template-name or you specify TEMPLATE=DEFAULT, the database named template1 is copied to the new database. All tables, views, data types, functions, and operators defined in the template database are duplicated into the new database. If you add objects (usually functions, operators, and data types) to the template1 database, those objects will be propagated to any new databases that you create based on template1. You can also trim down a template database if you want to reduce the size of new databases. For example, you might decide to remove the geometric data types (and the functions and operators that support that type) if you know that you won't need them. Or, if you have a set of functions that are required by your application, you can define the functions in the template1 database and all new databases will automatically include those functions. If you want to create an as-distributed database, you can use template0 as your template database. The template0 database is the starting point for template1 and contains only the standard objects included in a PostgreSQL distribution. You should not make changes to the template0 database, but you can use the template1 database to provide a site-specific set of default objects.
You can use the ENCODING=character-set clause to choose an encoding for the string values in the new database. An encoding determines how the bytes that make up a string are interpreted as characters. For example, specifying ENCODING=SQL_ASCII tells PostgreSQL that characters are stored in ASCII format, whereas ENCODING=ISO-8859-8 requests ECMA-121 Latin/Hebrew encoding. When you create a database, all characters stored in that database are encoded in a single format. When a client retrieves data, the client/server protocol automatically converts between the database encoding and the encoding being used by the client. Chapter 22, "Internationalization and Localization," discusses encoding schemes in more detail.
The TABLESPACE=tablespace-name clause tells PostgreSQL that you want to create the database in an alternate location (that is, the database should not be created in the usual $PGDATA/base directory). You must create a tablespace before you can use it. If you don't include a TABLESPACE clause in the CREATE DATABASE command, the new database is created in the same tablespace as the template database.
If you're using an older version of PostgreSQL (older than 8.0), you can't use tablespaces to create a database in a non-standard location. Instead, you must use a feature known as a location. In versions of PostgreSQL older than 8.0, the last option for the CREATE DATABASE command is the LOCATION=path clause. In most cases, you will never have to use the LOCATION option, which is good because it's a little strange.
If you do have need to use an alternate location, you will probably want to specify the location by using an environment variable. The environment variable must be known to the postmaster processor at the time the postmaster is started and it should contain an absolute pathname.
The LOCATION=path clause can be confusing. The path might be specified in three forms:
- The path contains a /, but does not begin with a /this specifies a relative path
- The path begins with a /this specifies an absolute path
- The path does not include a /
Relative locations are not allowed by PostgreSQL, so the first form is invalid.
Absolute paths are allowed only if you defined the C/C++ preprocessor symbol "ALLOW_ABSOLUTE_DBPATHS" at the time you compiled your copy of PostgreSQL. If you are using a prebuilt version of PostgreSQL, the chances are pretty high that this symbol was not defined and therefore absolute paths are not allowed.
So, the only form that you can rely on in a standard distribution is the lasta path that does not include any "/" characters. At first glance, this may look like a relative path that is only one level deep, but that's not how PostgreSQL sees it. In the third form, the path must be the name of an environment variable. As I mentioned earlier, the environment variable must be known to the postmaster processor at the time the postmaster is started, and it should contain an absolute pathname. Let's look at an example:
$ export PG_ALTERNATE=/bigdrive/pgdata $ initlocation PG_ALTERNATE $ pg_ctl restart -l /tmp/pg.log -D $PGDATA ... $ psql -q -d movies movies=# CREATE DATABASE bigdb WITH LOCATION=PG_ALTERNATE; ...
First, I've defined (and exported) an environment variable named PG_ALTERNATE. I've defined PG_ALTERNATE to have a value of /bigdrive/pgdatathat's where I want my new database to reside. After the environment variable has been defined, I need to initialize the directory structurethe initlocation script will take care of that for me. Now I have to restart the postmaster so that it can see the PG_ALTERNATE variable. Finally, I can start psql (or some other client) and execute the CREATE DATABASE command specifying the PG_ALTERNATE environment variable.
This all sounds a bit convoluted, and it is. The PostgreSQL developers consider it a security risk to allow users to create databases in arbitrary locations. Because the postmaster must be started by a PostgreSQL administrator, only an administrator can choose where databases can be created. So, to summarize the process:
|
1. |
Create a new environment variable and set it to the path where you want new databases to reside. |
|
2. |
Initialize the new directory using the initlocation application. |
|
3. |
Stop and restart the postmaster. |
|
4. |
Now, you can use the environment variable with the LOCATION=path clause. |
createdb
The CREATE DATABASE command creates a new database from within a PostgreSQL client application (such as psql). You can also create a new database from the operating system command line. The createdb command is a shell script that invokes psql for you and executes the CREATE DATABASE command for you. For more information about createdb, see the PostgreSQL Reference Manual or invoke createdb with the --help flag:
$ createdb --help createdb creates a PostgreSQL database. Usage: createdb [OPTION]... [DBNAME] [DESCRIPTION] Options: -D, --tablespace=TABLESPACE default tablespace for the database -E, --encoding=ENCODING encoding for the database -O, --owner=OWNER database user to own the new database -T, --template=TEMPLATE template database to copy -e, --echo show the commands being sent to the server -q, --quiet don't write any messages --help show this help, then exit --version output version information, then exit Connection options: -h, --host=HOSTNAME database server host or socket directory -p, --port=PORT database server port -U, --username=USERNAME user name to connect as -W, --password prompt for password By default, a database with the same name as the current user is created. Report bugs to .
Dropping a Database
Getting rid of an old database is easy. The DROP DATABASE command will delete all of the data in a database and remove the database from the cluster.
For example:
movies=# CREATE DATABASE redshirt; CREATE DATABASE movies=# DROP DATABASE redshirt; DROP DATABASE
There are no options to the DROP DATABASE command; you simply include the name of the database that you want to remove. There are a few restrictions. First, you must own the database that you are trying to drop, or you must be a PostgreSQL superuser. Next, you cannot drop a database from within a transaction blockyou cannot roll back a DROP DATABASE command. Finally, the database must not be in use, even by you. This means that before you can drop a database, you must connect to a different database (template1 is a good candidate). An alternative to the DROP DATABASE command is the dropdb shell script. dropdb is simply a wrapper around the DROP DATABASE command; see the PostgreSQL Reference Manual for more information about dropdb.
Viewing Databases
Using psql, there are two ways to view the list of databases. First, you can ask psql to simply display the list of databases and then exit. The -l option does this for you:
$ psql -l List of databases Name | Owner | Encoding -----------+-------------+---------- template0 | postgres | UNICODE template1 | postgres | UNICODE movies | bruce | UNICODE (3 rows) $
From within psql, you can use the l or l+ meta-commands to display the databases within a cluster:
movies=# l+ List of databases Name | Owner | Encoding | Description -----------+---------------+----------+-------------------------- template0 | postgres | UNICODE | template1 | postgres | UNICODE | Default template database movies | bruce | UNICODE | Virtual Video database (3 rows)
Part I: General PostgreSQL Use
Introduction to PostgreSQL and SQL
- Introduction to PostgreSQL and SQL
- A Sample Database
- Basic Database Terminology
- Prerequisites
- Connecting to a Database
- Creating Tables
- Viewing Table Descriptions
- Adding New Records to a Table
- Installing the Sample Database
- Retrieving Data from the Sample Database
- The CASE Expression
- Aggregates
- Multi-Table Joins
- UPDATE
- DELETE
- A (Very) Short Introduction to Transaction Processing
- Creating New Tables Using CREATE TABLE...AS
- Using VIEW
- Summary
Working with Data in PostgreSQL
- Working with Data in PostgreSQL
- NULL Values
- Character Values
- Numeric Values
- Date/Time Values
- Boolean (Logical) Values
- Geometric Data Types
- Object IDs (OID)
- BLOBs
- Network Address Data Types
- Sequences
- Arrays
- Column Constraints
- Expression Evaluation and Type Conversion
- Creating Your Own Data Types
- Summary
PostgreSQL SQL Syntax and Use
- PostgreSQL SQL Syntax and Use
- PostgreSQL Naming Rules
- Creating, Destroying, and Viewing Databases
- Creating New Tables
- Adding Indexes to a Table
- Getting Information About Databases and Tables
- Transaction Processing
- Summary
Performance
- Performance
- How PostgreSQL Organizes Data
- Gathering Performance Information
- Understanding How PostgreSQL Executes a Query
- Execution Plans Generated by the Planner
- The ARC Buffer Manager
- Table Statistics
- Performance Tips
Part II: Programming with PostgreSQL
Introduction to PostgreSQL Programming
- Introduction to PostgreSQL Programming
- Server-Side Programming
- Client-Side APIs
- General Structure of Client Applications
- Choosing an Application Environment
- Summary
Extending PostgreSQL
- Extending PostgreSQL
- Extending the PostgreSQL Server with Custom Functions
- Returning Multiple Values from an Extension Function
- The PostgreSQL SRF Interface
- Returning Complete Rows from an Extension Function
- Extending the PostgreSQL Server with Custom Data Types
- Internal and External Forms
- Defining a Simple Data Type in PostgreSQL
- Defining the Data Type in C
- Defining the Input and Output Functions in C
- Defining the Input and Output Functions in PostgreSQL
- Defining the Data Type in PostgreSQL
- Indexing Custom Data Types
- Summary
PL/pgSQL
- PL/pgSQL
- Installing PL/pgSQL
- Language Structure
- Function Body
- Cursors
- Triggers
- Polymorphic Functions
- PL/pgSQL and Security
- Summary
The PostgreSQL C APIlibpq
- The PostgreSQL C APIlibpq
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Simple ProcessingPQexec() and PQprint()
- Client 4An Interactive Query Processor
- Summary
A Simpler C APIlibpgeasy
- A Simpler C APIlibpgeasy
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
The New PostgreSQL C++ APIlibpqxx
- The New PostgreSQL C++ APIlibpqxx
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4Working with transactors
- Summary
Embedding SQL Commands in C Programsecpg
- Embedding SQL Commands in C Programsecpg
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing SQL Commands
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL from an ODBC Client Application
- Using PostgreSQL from an ODBC Client Application
- ODBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
- Resources
Using PostgreSQL from a Java Client Application
- Using PostgreSQL from a Java Client Application
- JDBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with Perl
- Using PostgreSQL with Perl
- DBI Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with PHP
- Using PostgreSQL with PHP
- PHP Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Query Processor
- Other Features
- Summary
Using PostgreSQL with Tcl and Tcl/Tk
- Using PostgreSQL with Tcl and Tcl/Tk
- Prerequisites
- Client 1Connecting to the Server
- Client 2Query Processing
- Client 3An Interactive Query Processor
- The libpgtcl Large-Object API
- Summary
Using PostgreSQL with Python
- Using PostgreSQL with Python
- Python/PostgreSQL Interface Architecture
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Command Processor
- Summary
Npgsql: The .NET Data Provider
- Npgsql: The .NET Data Provider
- Prerequisites
- Preparing Visual Studio
- Understanding the ADO.NET Class Hierarchy
- Creating an Npgsql-enabled VB Project
- Client 1Connecting to the Server
- Client 2An Interactive Query Processor
- Client 3Updating the Database with a DataSet
- Client 4A More Robust Query Processor
- Client 5Using a Typed DataSet
- Summary
Other Useful Programming Tools
- Other Useful Programming Tools
- PL/JavaWriting Stored Procedures in Java
- pgcurlWeb-enabling Your PostgreSQL Server
- pgbashWriting PostgreSQL-enabled Shell Scripts
Part III: PostgreSQL Administration
Introduction to PostgreSQL Administration
- Introduction to PostgreSQL Administration
- Security
- User Accounts
- Backup and Restore
- Server Startup and Shutdown
- Running PostgreSQL on a Windows Host
- Tuning
- Installing Updates
- Localization
- Summary
PostgreSQL Administration
- PostgreSQL Administration
- Roadmap (Wheres All My Stuff?)
- Installing PostgreSQL
- Managing Databases
- The PostgreSQL BGWRITER process
- Managing User Accounts
- Configuring Your PostgreSQL Runtime Environment
- Arranging for PostgreSQL Startup and Shutdown
- Backing Up and Copying Databases
- Point-in-time Recovery
- Summary
Internationalization and Localization
Security
- Security
- Securing the PostgreSQL Data Files
- Securing Network Access
- Securing Tables
- Securing Functions
- Summary
Replicating PostgreSQL Data with Slony
- Replicating PostgreSQL Data with Slony
- Overview
- Requirements
- Creating a Replication Cluster
- Starting the Replication Daemons
- Creating a Replication Set
- Subscribing to a Replication Set
- Changing the Cluster Topology (Re-mastering and Failover)
- Summary
Contributed Modules
Index
EAN: N/A
Pages: 261
