General Structure of Client Applications
This is a good time to discuss, in general terms, how a client application interacts with a PostgreSQL database. All the client APIs have a common structure, but the details vary greatly from language to language.
Figure 5.1 illustrates the basic flow of a client's interaction with a server.
Figure 5.1. Client/server interaction.
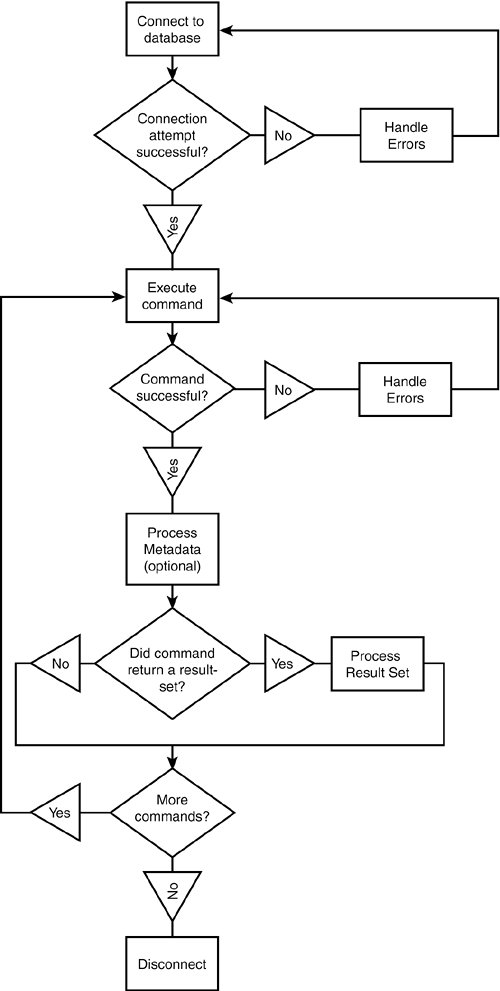
An application begins interacting with a PostgreSQL database by establishing a connection.
Because PostgreSQL is a client/server database, some sort of connection must exist between a client application and a database server. In the case of PostgreSQL, client/server communication takes the form of a network link. If the client and server are on different systems, the network link is a TCP/IP socket. If the client and server are on the same system, the network link is either a Unix-domain socket or a TCP/IP connection. A Unix-domain socket is a link that exists entirely within a single hostthe network is a logical network (rather than a physical network) within the OS kernel.
Connection Properties
Regardless of whether you are connecting to a local server or a remote server, the API uses a set of properties to establish the connection. Connection properties are used to identify the server (a network port number and host address), the specific database that you want to connect to, your user ID (and password if required), and various debugging and logging options. Each API allows you to explicitly specify connection properties, but you can also use default values for some (or all) of the properties. Most of the client-side APIs let you specify connection properties in the form of a string of keyword=value pairs. For example, to connect to a database named accounting on a host named jersey, you would use aproperty string such as
"dbname=accounting host=jersey"
Each keyword=value defines a single connection property. If you omit a connection property, PostgreSQL checks for an environment variable that corresponds to the property and, if the environment variable doesn't exist, PostgreSQL uses a hard-coded default value. See Table 5.2.
|
Keyword |
Environment Variable |
Description |
|---|---|---|
|
dbname |
PGDATABASE |
Specifies the name of the database that you want to connect to. If not specified, the client application tries to connect to a data-base with the same name as your username. |
|
user |
PGUSER |
Specifies the PostgreSQL username you want to connect as. If not specified, the client uses your operating system identity. |
|
host |
PGHOST |
Specifies the name (or IP address) of the computer that hosts the database you want to connect to. If the value starts with a '/', the client assumes that you want to connect to a Unix-domain socket located in that directory. If not specified, the client connects to a Unix-domain socket in /tmp. |
|
hostaddr |
PGHOSTADDR |
Specifies the IP address of the computer that hosts the database you want to connect to. When you specify hostaddr (instead of host), you avoid a name lookup (which can be slow on some networks). If not specified, the client uses the value of the host property to find the server. |
|
port |
PGPORT |
Specifies the TCP/IP port number to connect to (or, if you're connecting to a Unix-domain socket, the socket filename extension). If not specified, the default PGPORT is 5432. |
|
connect_timeout |
PGCONNECT_TIMEOUT |
Specifies the maximum amount of time (in seconds) to wait for the connection process to complete. If not specified (or if you specify a value of 0), the client will wait forever. |
|
slmode |
PGSSLMODE |
Specifies whether the client will attempt (or accept) an SSL-secured connection. Possible values are disable, allow, prefer, and require. disable and require are obvious, but allow and prefer seem a bit mysterious. If sslmode is allow, the client first attempts an insecure connection, but allows an SSL connection if an insecure connection can't be built. If sslmode is preferred, the client first attempts a secure connection, but accepts an insecure connection if a secure connection can't be built. If not specified, the default sslmode is prefer. |
|
service |
PGSERVICE |
Specifies the name of a service as defined in the pg_service.conf file (see next section). |
A more convenient way to encode connection parameters is to use the pg_service.conf file. When you specify a service name (with the PGSERVICE environment variable or the service=service-name connection property), the client application (actually the libpq library) opens a file named $PREFIX/etc/pg_service.conf and searches for a section that matches the service-name that you provided. If libpq locates the section that you named, it reads connection properties from that section. A typical pg_service.conf file might look similar to the following:
[accounting] dbname=accounting host=jersey sslmode=required [development] dbname=accounting host=guernsey sslmode=prefer
Each service begins with the service name (enclosed in square brackets) and continues until the next section (or the end of the file). A service is simply a collection of connection properties in the usual keyword=value format. The sample above defines two services (one named accounting and the other named development).
The nice thing about using a service name is that you can consolidate all your connection properties in a single location and then give only the service name to your database users. When you connect to a database using a service name, the client application loads the service definition first then processes the connection string. That means that you can specify both a service name and a connection string (properties found in the connection string will override the properties specified in the service). Environment variables are only consulted in a last-ditch effort to find missing values.
After a server connection has been established, the API gives you a handle. A handle is nothing more than a chunk of data that you get from the API and that you give back to the API when you want to send or receive data over the connection. The exact form of a handle varies depending on the language that you are using (or more precisely, the data type of a handle varies with the API that you use). For example, in libpq (the C API), a handle is a void pointeryou can't do anything with a void pointer except to give it back to the API. In the case of libpq++ and JDBC, a handle is embedded within a class.
After you obtain a connection handle from the API, you can use that handle to interact with the database. Typically, a client will want to execute SQL queries and process results. Each API provides a set of functions that will send a SQL command to the database. In the simplest case, you use a single function; more complex applications (and APIs) can separate command execution into two phases. The first phase sends the command to the server (for error checking and query planning) and the second phase actually carries out the command; you can repeat the execution phase as many times as you like. The advantage to a two-phase execution method is performance. You can parse and plan a command once and execute it many times, rather than parsing and planning every time you execute the command. Two-phase execution can also simplify your code by factoring the work required to generate a command into a separate function: One function can generate a command and a separate function can execute the command.
After you use an API to send a command to the server, you get back three types of results. The first result that comes back from the server is an indication of success or failureevery command that you send to the server will either fail or succeed. If your command fails, you can use the API to retrieve an error code and a translation of that code into some form of textual message.
If the server tells you that the command executed successfully, you can retrieve the next type of result: metadata. Metadata is data about data. Specifically, metadata is information about the results of the command that you just executed. If you already know the format of the result set, you can ignore the metadata.
When you execute a command such as INSERT, UPDATE, or DELETE, the metadata returned by the server is simply a count of the number of rows affected by the command. Some commands return no metadata. For example, when you execute a CREATE TABLE command, the only results that you get from the server are success or failure (and an error code if the command fails). When you execute a SELECT command, the metadata is more complex. Remember that a SELECT statement can return a set of zero or more rows, each containing one or more columns. This is called the result set. The metadata for a SELECT statement describes each of the columns in the result set.
When the server sends result set metadata, it returns the number of rows in the result set and the number of fields. For each field in the result set, the metadata includes the field name, data type information, and the size of the field (on the server).
I should mention here that most client applications don't really need to deal with all the metadata returned by the server. In general, when you write an application you already know the structure of your data. You'll often need to know how many rows were returned by a given query, but the other metadata is most useful when you are processing ad-hoc commandscommands that are not known to you at the time you are writing your application.
After you process the metadata (if you need to), your application will usually process all the rows in the result set. If you execute a SELECT statement, the result set will include all the rows that meet the constraints of the WHERE clause (if any). In some circumstances, you will find it more convenient to DECLARE a cursor for the SELECT statement and then execute multiple FETCH statements. When you execute the DECLARE statement, you won't get metadata. However, as you execute FETCH commands, you are constructing a new result set for each FETCH and the server has to send metadata describing the resulting fieldsthat can be expensive.
After you have finished processing the result set, you can execute more commands, or you can disconnect from the server.
LISTEN/NOTIFY
Sometimes, you might want a client application to wait for some server-side event to occur before proceeding. For example, you might need a queuing system that writes a work order into a PostgreSQL table and then expects a client application to carry out that work order. The most obvious way to write a client of this sort is to put your client application to sleep for a few seconds (or a few minutes), then, when your application awakens, check for a new record in the work-order table. If the record exists, do your work and then repeat the whole cycle.
There are two problems with this approach. First, your client application can't be very responsive. When a new work order is added, it may take a few seconds (or a few minutes) for your client to notice (it's fast asleep after all). Second, your client application might spend a lot of time searching for work orders that don't exist.
PostgreSQL offers a solution to this problem: the LISTEN/NOTIFY mechanism. A PostgreSQL server can signal client applications that some event has occurred by executing a NOTIFY eventName command. All client applications that are listening for that event are notified that the event has occurred. You get to choose your own event names. In a work-order application, you might define an event named workOrderReceived. To inform the server that you are interested in that event, the client application executes a LISTEN workOrderReceived command (to tell the server that you are no longer interested in an event, simply UNLISTEN workOrderReceived). When a work order arrives at the server (via some other client application), executing the command NOTIFY workOrderReceived will inform all clients that a workOrderReceived event has occurred (actually, PostgreSQL will only notify those clients listening for that specific event).
Each client-side API offers a different LISTEN mechanism and you rarely execute a LISTEN command yourselfinstead, you call an API function that executes the LISTEN command for you (after arranging to intercept the event in a language-specific way).
Regardless of the language that you choose, you should be aware that notifications are only sent at the end of a successful transaction. If you ROLLBACK a transaction, any NOTIFY commands executed within that transaction are ignored. That makes sense if you think about it: If your application adds a work order record, but then aborts the transaction, you don't want to wake client applications with a false alarm.
Part I: General PostgreSQL Use
Introduction to PostgreSQL and SQL
- Introduction to PostgreSQL and SQL
- A Sample Database
- Basic Database Terminology
- Prerequisites
- Connecting to a Database
- Creating Tables
- Viewing Table Descriptions
- Adding New Records to a Table
- Installing the Sample Database
- Retrieving Data from the Sample Database
- The CASE Expression
- Aggregates
- Multi-Table Joins
- UPDATE
- DELETE
- A (Very) Short Introduction to Transaction Processing
- Creating New Tables Using CREATE TABLE...AS
- Using VIEW
- Summary
Working with Data in PostgreSQL
- Working with Data in PostgreSQL
- NULL Values
- Character Values
- Numeric Values
- Date/Time Values
- Boolean (Logical) Values
- Geometric Data Types
- Object IDs (OID)
- BLOBs
- Network Address Data Types
- Sequences
- Arrays
- Column Constraints
- Expression Evaluation and Type Conversion
- Creating Your Own Data Types
- Summary
PostgreSQL SQL Syntax and Use
- PostgreSQL SQL Syntax and Use
- PostgreSQL Naming Rules
- Creating, Destroying, and Viewing Databases
- Creating New Tables
- Adding Indexes to a Table
- Getting Information About Databases and Tables
- Transaction Processing
- Summary
Performance
- Performance
- How PostgreSQL Organizes Data
- Gathering Performance Information
- Understanding How PostgreSQL Executes a Query
- Execution Plans Generated by the Planner
- The ARC Buffer Manager
- Table Statistics
- Performance Tips
Part II: Programming with PostgreSQL
Introduction to PostgreSQL Programming
- Introduction to PostgreSQL Programming
- Server-Side Programming
- Client-Side APIs
- General Structure of Client Applications
- Choosing an Application Environment
- Summary
Extending PostgreSQL
- Extending PostgreSQL
- Extending the PostgreSQL Server with Custom Functions
- Returning Multiple Values from an Extension Function
- The PostgreSQL SRF Interface
- Returning Complete Rows from an Extension Function
- Extending the PostgreSQL Server with Custom Data Types
- Internal and External Forms
- Defining a Simple Data Type in PostgreSQL
- Defining the Data Type in C
- Defining the Input and Output Functions in C
- Defining the Input and Output Functions in PostgreSQL
- Defining the Data Type in PostgreSQL
- Indexing Custom Data Types
- Summary
PL/pgSQL
- PL/pgSQL
- Installing PL/pgSQL
- Language Structure
- Function Body
- Cursors
- Triggers
- Polymorphic Functions
- PL/pgSQL and Security
- Summary
The PostgreSQL C APIlibpq
- The PostgreSQL C APIlibpq
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Simple ProcessingPQexec() and PQprint()
- Client 4An Interactive Query Processor
- Summary
A Simpler C APIlibpgeasy
- A Simpler C APIlibpgeasy
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
The New PostgreSQL C++ APIlibpqxx
- The New PostgreSQL C++ APIlibpqxx
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4Working with transactors
- Summary
Embedding SQL Commands in C Programsecpg
- Embedding SQL Commands in C Programsecpg
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing SQL Commands
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL from an ODBC Client Application
- Using PostgreSQL from an ODBC Client Application
- ODBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
- Resources
Using PostgreSQL from a Java Client Application
- Using PostgreSQL from a Java Client Application
- JDBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with Perl
- Using PostgreSQL with Perl
- DBI Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with PHP
- Using PostgreSQL with PHP
- PHP Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Query Processor
- Other Features
- Summary
Using PostgreSQL with Tcl and Tcl/Tk
- Using PostgreSQL with Tcl and Tcl/Tk
- Prerequisites
- Client 1Connecting to the Server
- Client 2Query Processing
- Client 3An Interactive Query Processor
- The libpgtcl Large-Object API
- Summary
Using PostgreSQL with Python
- Using PostgreSQL with Python
- Python/PostgreSQL Interface Architecture
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Command Processor
- Summary
Npgsql: The .NET Data Provider
- Npgsql: The .NET Data Provider
- Prerequisites
- Preparing Visual Studio
- Understanding the ADO.NET Class Hierarchy
- Creating an Npgsql-enabled VB Project
- Client 1Connecting to the Server
- Client 2An Interactive Query Processor
- Client 3Updating the Database with a DataSet
- Client 4A More Robust Query Processor
- Client 5Using a Typed DataSet
- Summary
Other Useful Programming Tools
- Other Useful Programming Tools
- PL/JavaWriting Stored Procedures in Java
- pgcurlWeb-enabling Your PostgreSQL Server
- pgbashWriting PostgreSQL-enabled Shell Scripts
Part III: PostgreSQL Administration
Introduction to PostgreSQL Administration
- Introduction to PostgreSQL Administration
- Security
- User Accounts
- Backup and Restore
- Server Startup and Shutdown
- Running PostgreSQL on a Windows Host
- Tuning
- Installing Updates
- Localization
- Summary
PostgreSQL Administration
- PostgreSQL Administration
- Roadmap (Wheres All My Stuff?)
- Installing PostgreSQL
- Managing Databases
- The PostgreSQL BGWRITER process
- Managing User Accounts
- Configuring Your PostgreSQL Runtime Environment
- Arranging for PostgreSQL Startup and Shutdown
- Backing Up and Copying Databases
- Point-in-time Recovery
- Summary
Internationalization and Localization
Security
- Security
- Securing the PostgreSQL Data Files
- Securing Network Access
- Securing Tables
- Securing Functions
- Summary
Replicating PostgreSQL Data with Slony
- Replicating PostgreSQL Data with Slony
- Overview
- Requirements
- Creating a Replication Cluster
- Starting the Replication Daemons
- Creating a Replication Set
- Subscribing to a Replication Set
- Changing the Cluster Topology (Re-mastering and Failover)
- Summary
Contributed Modules
Index
EAN: N/A
Pages: 261
