How PostgreSQL Organizes Data
Before you can really dig into the details of performance tuning, you need to understand some of the basic architecture of PostgreSQL.
You already know that in PostgreSQL, data is stored in tables and tables are grouped into databases. At the highest level of organization, databases are grouped into clustersa cluster of databases is serviced by a postmaster.
Let's see how this data hierarchy is stored on disk. You can see all databases in a cluster using the following query:
perf=# SELECT datname, oid FROM pg_database; datname | oid -----------+------- perf | 16556 template1 | 1 template0 | 16555
From this list, you can see that I have three databases in this cluster. You can find the storage for these databases by looking in the $PGDATA directory:
$ cd $PGDATA $ ls base pg_clog pg_ident.conf pg_xlog postmaster.opts global pg_hba.conf PG_VERSION postgresql.conf postmaster.pid
The $PGDATA directory has a subdirectory named base. The base subdirectory is where your databases reside:
$ cd ./base $ ls -l total 12 drwx------ 2 postgres pgadmin 4096 Jan 01 20:53 1 drwx------ 2 postgres pgadmin 4096 Jan 01 20:53 16555 drwx------ 3 postgres pgadmin 4096 Jan 01 22:38 16556
Notice that there are three subdirectories underneath $PGDATA/base. The name of each subdirectory corresponds to the oid of one entry in the pg_database table: the subdirectory named 1 contains the template1 database, the subdirectory named 16555 contains the template0 database, and the subdirectory named 16556 contains the perf database.
Let's look a little deeper:
$ cd ./1 $ ls 1247 16392 16408 16421 16429 16441 16449 16460 16472 1249 16394 16410 16422 16432 16442 16452 16462 16474 1255 16396 16412 16423 16435 16443 16453 16463 16475 1259 16398 16414 16424 16436 16444 16454 16465 16477 16384 16400 16416 16425 16437 16445 16455 16466 pg_internal.init 16386 16402 16418 16426 16438 16446 16456 16468 PG_VERSION 16388 16404 16419 16427 16439 16447 16457 16469 16390 16406 16420 16428 16440 16448 16458 16471
Again, you see a lot of files with numeric filenames. You might guess that these numbers also correspond to oids, and (by chance) you would often be correct. Every table (and index) in a database is catalogued in the pg_class system table. To find a table in pg_class, search for a row where the relname column is equal to the name of the table. For example, to find the pg_class entry for the pg_group table, execute the command
SELECT * FROM pg_class WHERE relname = 'pg_group';
The pg_class.relfilenode value for a table determines the name of the file that stores the table (likewise, the pg_class.relfilenode value for an index determines the name of the file that stores in the index). In most cases, the OID of a table's pg_class entry matches the table's relfilenode, but that's not always the case. If you ALTER a table in such a way that PostgreSQL must first make a new copy of the table and then drop the original, the table's relfilenode will change. The relfilenode may also change if you CLUSTER the table (PostgreSQL makes a new copy of the table in the desired order and then drops the original). The relfilenode value for an index may change if you rebuild in the index with a REINDEX command, or if you ALTER the data type of a column covered by the index.
To see the correspondence between a table's relfilenode and its filename, simply compare the output from the following SELECT command to the filesystem directory that contains the database
test=# SELECT relfilenode, relname FROM pg_class ORDER BY relfilenode; relfilenode | relname -------------+--------------------------------- 0 | pg_xactlock 1247 | pg_type 1249 | pg_attribute 1255 | pg_proc 1259 | pg_class ... | ...
Each table is stored in its own disk file and the name of the file is determined by the oid relfilenode of the table's entry in the pg_class table.
There are two more columns in pg_class that might help explain PostgreSQL's storage structure:
perf=# SELECT relname, oid, relpages, reltuples FROM pg_class perf-# ORDER BY oid relname | oid | reltuples | relpages --------------+------+-----------+---------- pg_type | 1247 | 143 | 2 pg_attribute | 1249 | 795 | 11 pg_proc | 1255 | 1263 | 31 pg_class | 1259 | 101 | 2 pg_shadow | 1260 | 1 | 1 pg_group | 1261 | 0 | 0 ... | ... | ... | ...
The reltuples column tells you how many tuples are in each table. The relpages column shows how many pages are required to store the current contents of the table. How do these numbers correspond to the actual on-disk structures? If you look at the table files for a few tables, you'll see that there is a relationship between the size of the file and the number of relpages columns:
$ ls -l 1247 1249 -rw------- 1 postgres pgadmin 16384 Jan 01 20:53 1247 -rw------- 1 postgres pgadmin 90112 Jan 01 20:53 1249
The file named 1247 (pg_type) is 16,384 bytes long and consumes two pages. The file named 1249 (pg_attribute) is 90,122 bytes long and consumes 11 pages. A little math will show that 16,384/2 = 8,192 and 90,122/11 = 8,192: each page is 8,192 (8K) bytes long. In PostgreSQL, all disk I/O is performed on a page-by-page basis[1]. When you select a single row from a table, PostgreSQL will read at least one pageit may read many pages if the row is large. When you update a single row, PostgreSQL will write the new version of the row at the end of the table and will mark the original version of the row as invalid.
[1] Actually, most disk I/O is performed on a page-by-page basis. Some configuration files and log files are accessed in other forms, but all table and index access is done in pages.
The size of a page is fixed at 8,192 bytes. You can increase or decrease the page size if you build your own copy of PostgreSQL from source, but all pages within a database will be the same size. The size of a row is not fixeddifferent tables will yield different row sizes. In fact, the rows within a single table may differ in size if the table contains variable-length columns. Given that the page size is fixed and the row size is variable, it's difficult to predict exactly how many rows will fit within any given page.
[2] This data (ftp://ftp.nhtsa.dot.gov/rev_recalls/) is in the form of a flat ASCII file. I had to import the data into my perf database.
The recalls table in the perf database contains 39,241 rows in 4,413 pages:
perf=# SELECT relname, reltuples, relpages, oid FROM pg_class perf-# WHERE relname = 'recalls'; relname | reltuples | relpages | oid ---------+-----------+----------+------- recalls | 39241 | 4413 | 96409
Given that a page is 8,192 bytes long, you would expect that the file holding this table ($PGDATA/base/16556/96409) would be 36,151,296 bytes long:
$ ls -l $PGDATA/base/16556/96409 -rw------- 1 postgres pgadmin 36151296 Jan 01 23:34 96409
Figure 4.1 shows how the recalls table might look on disk. (Notice that the rows are not sortedthey appear in the approximate order of insertion.)
Figure 4.1. The recalls table as it might look on disk.
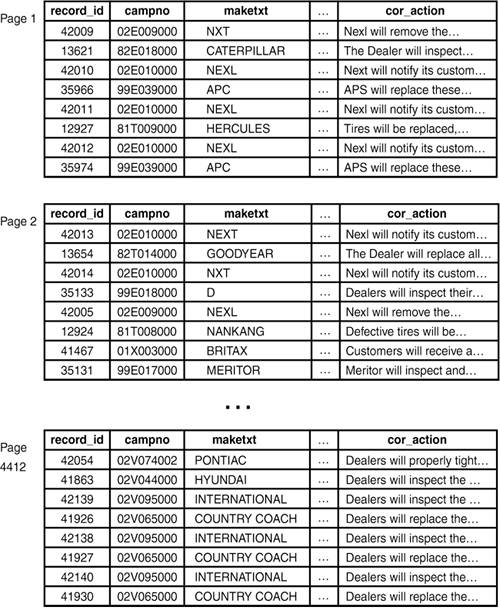
If a row is too large to fit into a single 8K block[3], PostgreSQL will write part of the data into a TOAST[4] table. A TOAST table acts as an extension to a normal table. It holds values too large to fit inline in the main table.
[3] PostgreSQL tries to store at least four rows per heap page and at least four entries per index page.
[4] The acronym TOAST stands for "the oversized attribute storage technique."
Indexes are also stored in page files. A page that holds row data is called a heap page. A page that holds index data is called an index page. You can locate the page file that stores an index by examining the index's entry in the pg_class table. And, just like tables, it is difficult to predict how many index entries will fit into each 8K page[5]. If an index entry is too large, it is moved to an index TOAST table.
[5] If you want more information about how data is stored inside a page, I recommend the pg_filedump utility from Red Hat.
In PostgreSQL, a page that contains row data is a heap block. A page that contains index data is an index block. You will never find heap blocks and index blocks in the same page file.
Page Caching
Two of the fundamental performance rules in any database system are:
- Memory access is fast; disk access is slow.
- Memory space is scarce; disk space is abundant.
Accordingly, PostgreSQL tries very hard to minimize disk I/O by keeping frequently used data in memory. When the first server process starts, it creates an in-memory data structure known as the buffer cache. The buffer cache is organized as a collection of 8K pageseach page in the buffer cache corresponds to a page in some page file. The buffer cache is shared between all processes servicing a given database.
When you select a row from a table, PostgreSQL will read the heap block that contains the row into the buffer cache. If there isn't enough free space in the cache, PostgreSQL will move some other block out of the cache. If a block being removed from the cache has been modified, it will be written back out to disk; otherwise. it will simply be discarded. Index blocks are buffered as well.
In the "Gathering Performance Information" section, you'll see how to measure the performance of the cache and how to change its size.
Summary
This section gave you a good overview of how PostgreSQL stores data on disk. With some of the fundamentals out of the way, you can move on to more performance issues.
Part I: General PostgreSQL Use
Introduction to PostgreSQL and SQL
- Introduction to PostgreSQL and SQL
- A Sample Database
- Basic Database Terminology
- Prerequisites
- Connecting to a Database
- Creating Tables
- Viewing Table Descriptions
- Adding New Records to a Table
- Installing the Sample Database
- Retrieving Data from the Sample Database
- The CASE Expression
- Aggregates
- Multi-Table Joins
- UPDATE
- DELETE
- A (Very) Short Introduction to Transaction Processing
- Creating New Tables Using CREATE TABLE...AS
- Using VIEW
- Summary
Working with Data in PostgreSQL
- Working with Data in PostgreSQL
- NULL Values
- Character Values
- Numeric Values
- Date/Time Values
- Boolean (Logical) Values
- Geometric Data Types
- Object IDs (OID)
- BLOBs
- Network Address Data Types
- Sequences
- Arrays
- Column Constraints
- Expression Evaluation and Type Conversion
- Creating Your Own Data Types
- Summary
PostgreSQL SQL Syntax and Use
- PostgreSQL SQL Syntax and Use
- PostgreSQL Naming Rules
- Creating, Destroying, and Viewing Databases
- Creating New Tables
- Adding Indexes to a Table
- Getting Information About Databases and Tables
- Transaction Processing
- Summary
Performance
- Performance
- How PostgreSQL Organizes Data
- Gathering Performance Information
- Understanding How PostgreSQL Executes a Query
- Execution Plans Generated by the Planner
- The ARC Buffer Manager
- Table Statistics
- Performance Tips
Part II: Programming with PostgreSQL
Introduction to PostgreSQL Programming
- Introduction to PostgreSQL Programming
- Server-Side Programming
- Client-Side APIs
- General Structure of Client Applications
- Choosing an Application Environment
- Summary
Extending PostgreSQL
- Extending PostgreSQL
- Extending the PostgreSQL Server with Custom Functions
- Returning Multiple Values from an Extension Function
- The PostgreSQL SRF Interface
- Returning Complete Rows from an Extension Function
- Extending the PostgreSQL Server with Custom Data Types
- Internal and External Forms
- Defining a Simple Data Type in PostgreSQL
- Defining the Data Type in C
- Defining the Input and Output Functions in C
- Defining the Input and Output Functions in PostgreSQL
- Defining the Data Type in PostgreSQL
- Indexing Custom Data Types
- Summary
PL/pgSQL
- PL/pgSQL
- Installing PL/pgSQL
- Language Structure
- Function Body
- Cursors
- Triggers
- Polymorphic Functions
- PL/pgSQL and Security
- Summary
The PostgreSQL C APIlibpq
- The PostgreSQL C APIlibpq
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Simple ProcessingPQexec() and PQprint()
- Client 4An Interactive Query Processor
- Summary
A Simpler C APIlibpgeasy
- A Simpler C APIlibpgeasy
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
The New PostgreSQL C++ APIlibpqxx
- The New PostgreSQL C++ APIlibpqxx
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4Working with transactors
- Summary
Embedding SQL Commands in C Programsecpg
- Embedding SQL Commands in C Programsecpg
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing SQL Commands
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL from an ODBC Client Application
- Using PostgreSQL from an ODBC Client Application
- ODBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
- Resources
Using PostgreSQL from a Java Client Application
- Using PostgreSQL from a Java Client Application
- JDBC Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with Perl
- Using PostgreSQL with Perl
- DBI Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Processing Queries
- Client 4An Interactive Query Processor
- Summary
Using PostgreSQL with PHP
- Using PostgreSQL with PHP
- PHP Architecture Overview
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Query Processor
- Other Features
- Summary
Using PostgreSQL with Tcl and Tcl/Tk
- Using PostgreSQL with Tcl and Tcl/Tk
- Prerequisites
- Client 1Connecting to the Server
- Client 2Query Processing
- Client 3An Interactive Query Processor
- The libpgtcl Large-Object API
- Summary
Using PostgreSQL with Python
- Using PostgreSQL with Python
- Python/PostgreSQL Interface Architecture
- Prerequisites
- Client 1Connecting to the Server
- Client 2Adding Error Checking
- Client 3Query Processing
- Client 4An Interactive Command Processor
- Summary
Npgsql: The .NET Data Provider
- Npgsql: The .NET Data Provider
- Prerequisites
- Preparing Visual Studio
- Understanding the ADO.NET Class Hierarchy
- Creating an Npgsql-enabled VB Project
- Client 1Connecting to the Server
- Client 2An Interactive Query Processor
- Client 3Updating the Database with a DataSet
- Client 4A More Robust Query Processor
- Client 5Using a Typed DataSet
- Summary
Other Useful Programming Tools
- Other Useful Programming Tools
- PL/JavaWriting Stored Procedures in Java
- pgcurlWeb-enabling Your PostgreSQL Server
- pgbashWriting PostgreSQL-enabled Shell Scripts
Part III: PostgreSQL Administration
Introduction to PostgreSQL Administration
- Introduction to PostgreSQL Administration
- Security
- User Accounts
- Backup and Restore
- Server Startup and Shutdown
- Running PostgreSQL on a Windows Host
- Tuning
- Installing Updates
- Localization
- Summary
PostgreSQL Administration
- PostgreSQL Administration
- Roadmap (Wheres All My Stuff?)
- Installing PostgreSQL
- Managing Databases
- The PostgreSQL BGWRITER process
- Managing User Accounts
- Configuring Your PostgreSQL Runtime Environment
- Arranging for PostgreSQL Startup and Shutdown
- Backing Up and Copying Databases
- Point-in-time Recovery
- Summary
Internationalization and Localization
Security
- Security
- Securing the PostgreSQL Data Files
- Securing Network Access
- Securing Tables
- Securing Functions
- Summary
Replicating PostgreSQL Data with Slony
- Replicating PostgreSQL Data with Slony
- Overview
- Requirements
- Creating a Replication Cluster
- Starting the Replication Daemons
- Creating a Replication Set
- Subscribing to a Replication Set
- Changing the Cluster Topology (Re-mastering and Failover)
- Summary
Contributed Modules
Index
EAN: N/A
Pages: 261
