IDS and IPS Architecture
Overview
Intrusion-detection and intrusion-prevention systems, at a minimum, actually require only one program or device. Someone might, for example, install a personal firewall with intrusion detection and IP source address shunning capabilities on a system used exclusively for home computing. Although doing so might be sufficient for a few purposes (such as home use or testing a particular IDS), deploying a single system or device is not sufficient for many organizations, such as global corporations, government agencies, and the military. These organizations typically use multiple systems and components that perform a variety of sophisticated intrusion-detection and intrusion-prevention functions. The roles performed by and relationships among machines, devices, applications, and processes, including the conventions used for communication between them, define an architecture. In its most fundamental sense, an intrusion-detection or intrusion-prevention architecture is a designed structure on which every element involved fits.
The architecture is one of the most critical considerations in intrusion detection and prevention. An effective architecture is one in which each machine, device, component, and process performs its role in an effective and (often) coordinated manner, resulting in efficient information processing and output, and also appropriate preventive responses that meet the business and operational needs of an organization. A poorly designed or implemented architecture, on the other hand, can produce a variety of undesirable consequences, such as data not being available or not being available when needed, networking slowdowns, or a lack of appropriate and timely responses.
This chapter covers intrusion-detection and intrusion-prevention architectures, and will look at tiered models, how servers are deployed, how sensors and agents function, and the roles and functionality of management consoles in an intrusion-detection and intrusion-prevention architecture.
Tiered Architectures
At least three types of tiered architectures can be used: single-tiered, multi-tiered, and peer-to-peer architectures.
Single Tiered Architecture
A single-tiered architecture, the most basic of the architectures discussed here, is one in which components in an IDS or IPS collect and process data themselves, rather than passing the output they collect to another set of components. An example of a single-tiered architecture is a host-based intrusion-detection tool that takes the output of system logs (such as the utmp and wtmp files on Unix systems) and compares it to known patterns of attack.
A single tier offers advantages, such as simplicity, low cost (at least in the case of freeware tools running on individual hosts), and independence from other components (an advantage if they should become compromised or disabled). At the same time, however, a single-tiered architecture usually has components that are not aware of each other, reducing considerably the potential for efficiency and sophisticated functionality.
Multi Tiered Architecture
As the name implies, a multi-tiered architecture involves multiple components that pass information to each other. Many of today’s IDSs, for example, consist of three primary components: sensors, analyzers or agents, and a manager.
Sensors perform data collection. For example, network sensors are often programs that capture data from network interfaces. Sensors can also collect data from system logs and other sources, such as personal firewalls and TCP wrappers.
Sensors pass information to agents (sometimes also known as analyzers), which monitor intrusive activity on their individual hosts. Each sensor and agent is configured to run on the particular operating environment in which it is placed. Agents are normally specialized to perform one and only one function. One agent might, for example, examine nothing but TCP traffic, whereas another might examine only FTP (File Transfer Protocol) connections and connection attempts. Additionally, third-party tools, such as network-monitoring tools, neural networks (which are covered in Chapter 17), and connection-tracing tools can be used if expanding the scope of analysis is advantageous.
When an agent has determined that an attack has occurred or is occurring, it sends information to the manager component, which can perform a variety of functions including (but not limited to) the following:
- Collecting and displaying alerts on a console
- Triggering a pager or calling a cellular phone number
- Storing information regarding an incident in a database
- Retrieving additional information relevant to the incident
- Sending information to a host that stops it from executing certain instructions in memory
- Sending commands to a firewall or router that change access control lists
- Providing a management console—a user interface to the manager component
A central collection point allows for greater ease in analyzing logs because all the log information is available at one location. Additionally, writing log data to a different system (the one on which the manager component resides) from the one that produced them is advisable; if an attacker tampers with or destroys log data on the original system (by installing a rootkit tool that masquerades the attacker’s presence on the system, for instance), the data will still be available on the central server—the manager component. Finally, management consoles can enable intrusion-detection and intrusion-prevention staff to remotely change policies and parameters, erase log files after they are archived, and perform other important functions without having to individually authenticate to sensors, agents, and remote systems. Figure 6-1 outlines the multi-tier architecture.
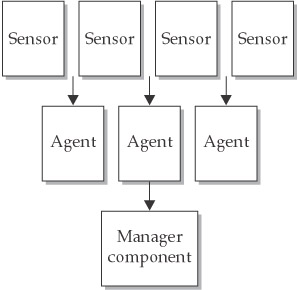
Figure 6-1: A multi-tiered architecture
Advantages of a multi-tiered architecture include greater efficiency and depth of analysis. With each component of the architecture performing the function it is designed to do, often mostly independent of the other components, a properly designed multi-tiered architecture can provide a degree of efficiency not possible with the simpler single- tiered architecture. It can also provide a much more complete picture of the security condition of an organization’s entire network and the hosts therein, compared to a single-tiered architecture. The main downsides include increased cost and complexity. The multiple components, interfaces, and communications methods translate to greater difficulty in setting up this architecture and more day-to-day maintenance and troubleshooting challenges.
Peer to Peer Architecture
Whereas the multi-tiered architecture generally takes raw information, processes it, then sends the output to a higher-order component, the peer-to-peer architecture involves exchanging intrusion-detection and intrusion-prevention information between peer components, each of which performs the same kinds of functions. This peer-to-peer architecture is often used by cooperating firewalls (and, to a lesser degree, by cooperating routers or switches). As one firewall obtains information about events that are occurring, it passes this information to another, which may cause a change in an access control list or addition of restrictions on proxied connections. The second firewall can also send information that causes changes in the first. Neither firewall acts as the central server or master repository of information.
The main advantage of a peer-to-peer architecture is simplicity. Any peer can participate in what is effectively a group of peer machines, each of which can benefit from the information the others glean. The main downside is a lack of sophisticated functionality due to the absence of specialized components (although the functionality is better than what is possible in a single-tiered architecture because the latter does not even have cooperating components).
Critical Need for Architectures
Architectures make a critical difference in terms of the quantity and quality of the dividends that intrusion-detection and intrusion-prevention technology produce. At the same time, however, it is important to remember that “Rome was not built in a day.” If you lack financial resources, starting with a simple single-tiered architecture is often the logical first step in developing an intrusion-detection and intrusion-prevention architecture. As more resources become available, and as the exact business and operational objectives of intrusion-detection and intrusion-prevention efforts become clearer, a migration to a more sophisticated architecture can occur.
A peer-to-peer architecture is well suited to organizations that have invested enough to obtain and deploy firewalls capable of cooperating with each other, but that have not invested much (if anything) in IDSs and IPSs. As discussed earlier, firewalls are, all things considered, the best single source of intrusion-detection data. Using them in a peer-to-peer manner to distribute information they have obtained and to make adaptive changes in access control lists or proxy rules can, at least to some degree, compensate for the absence of IDSs and IPSs.
Sensors
Sensors are critical in intrusion-detection and intrusion-prevention architectures—they are the beginning point of intrusion detection and prevention because they supply the initial data about potentially malicious activity. A deeper look at sensor functionality, deployment, and security will provide insight into exactly what sensors are and how they work.
Sensor Functions
Considering all the possible intrusion-detection and intrusion-prevention components within a particular architecture, sensors are usually (but not always) the lowest end components. In other words, sensors typically do not have very sophisticated functionality. They are usually designed only to obtain certain data and pass them on. There are two basic types of sensors: network-based and host-based sensors.
Network-Based Sensors
Network-based sensors, the more frequently deployed of the two types, are programs or network devices (such as physical devices) that capture data in packets traversing a local Ethernet or token ring or a network switching point. One of the greatest advantages of network-based sensors is the sheer number of hosts for which they can provide data. In an extreme case, one sensor might be used to monitor all traffic coming into and out of a network. If the network has a thousand hosts, the sensor can, in theory, gather data about misuse and anomalies in all thousand hosts. The cost-effectiveness of this approach is huge (although critics justifiably point out that a single sensor is also likely to miss a considerable amount of data that may be critical to an intrusion-detection and intrusion-prevention effort if the sensor does not happen to be recording traffic on the particular network route over which packets containing the data are sent). Additionally, if configured properly, sensors do not burden the network with much additional traffic, especially if two network interfaces—one for monitoring and the other for management—are used. A monitoring interface has no TCP/IP stack whatsoever, nor does it have any linkage to any IP address, both of which make it an almost entirely transparent entity on the network.
The programs that intrusion-detection and intrusion-prevention tools most frequently use as sensors are tcpdump (described previously in Chapter 5) and libpcap. To reiterate, tcpdump (www.tcpdump.org) captures data from packets and prints packet headers of packets that match a particular filter (or Boolean) expression. Packet parameters that are particularly useful in intrusion detection and prevention are time, source and destination addresses, source and destination ports, TCP flags, initial sequence number from the source IP for the initial connection, ending sequence number, number of bytes, and window size.
tcpdump is an application, but libpcap is a library called by an application. libpcap (http://sourceforge.net/projects/libpcap/) is designed to gather packet data from the kernel of the operating system and then move it to one or more applications—in this particular case, to intrusion-detection and intrusion-prevention applications. For example, an Ethernet card may obtain packet data from a network. The underlying operating system over which libpcap runs will process each packet in many ways, starting with determining what kind of packet it is by removing the Ethernet header to get to the next layer up the stack. In all likelihood, the next layer will be the IP layer; if so, the IP header must be removed to determine the protocol at the next layer of the stack (although it is important to note that in the case of the IP protocol, hexadecimal values of 1, 6, or 11 starting at byte position 40 within the packet header indicate that the transport protocol is ICMP, TCP, or UDP (User Datagram Protocol), respectively). If the packet is a TCP packet, the TCP header is also removed and the contents of the packet are then passed on to the next layer up, the application layer. libpcap provides intrusion-detection and intrusion-prevention applications with this data (payload) so that these applications can analyze the content to look for attack signatures, names of hacking tools, and so forth. libpcap is advantageous not only in that it provides a standard interface to these applications, but also because, like tcpdump, it is public domain software.
Many other sensors are also used. Some IDS vendors, for example, develop and include their own proprietary sensors in these systems. These sensors sometimes provide more functionality than tcpdump and libpcap have, and sometimes have substantially scaled-down functionality so they are more efficient.
Host-Based Sensors
Host-based sensors, like network-based sensors, could possibly also receive packet data captured by network interfaces and then send the data somewhere. Instead of being set to promiscuous mode, the network interface on each host would have to be set to capture only data sent to that particular host. However, doing so would not make much sense, given the amount of processing of data that would have to occur on each host. Instead, most host-based sensors are programs that produce log data, such as Unix daemons or the Event Logger in Windows NT, 2000, XP, and Windows Server 2003. The output of these programs is sent (often through a utility such as scp, secure copy, which runs as a cron job, or through the Windows Task Scheduler) to an analysis program that either runs on the same host or on a central host. The program might look for events indicating that someone has obtained root privileges on a Unix system without entering the su (substitute user) command and the root password—a possible indication that an attacker has exploited a vulnerability to gain root privileges.
Sensor Deployment Considerations
Many sensors require that a host be running one or more network interfaces in promiscuous mode. In many current Unix systems, entering this command
ifconfig
will produce standard output that displays the IP address, the MAC address, the net mask, and other important parameters, including “promisc” if the interface is in promiscuous mode. Note that if there is only one network interface, it is not necessary to enter the name of the interface in question.
Sensors can be placed outside of exterior firewalls, inside them, or both. Sensors outside exterior firewalls record information about Internet attacks. Web servers, FTP servers, external DNS servers, and mail servers are often placed outside of the firewall, making them much more likely to be attacked than other hosts. Placing these systems within an organization’s internal network potentially makes them lesser targets, because being within the internal network at least affords some protection (such as one or more filtering barriers provided by firewalls and screening routers). At the same time, however, having these servers within the internal network will increase the traffic load for the internal network and will also expose the internal network more if any of these servers become compromised. Given that servers placed outside of the internal network are more vulnerable to attack, it is a good idea to place at least one network-based sensor in one or more demilitarized zones (DMZs; see Figure 6-2).
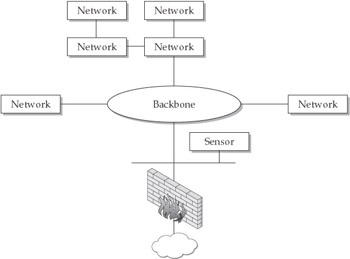
Figure 6-2: Placement of a sensor within a DMZ
More Considerations for Network-Based Sensor Functionality
Ensuring that a network interface is in promiscuous mode is critical for network-based sensor functionality, but there are other important technical considerations, too. For one thing, programs that capture data or read these data need certain privileges or access rights. In most versions of Linux, for example, root privileges are necessary for accessing captured data in files such as/var/log/messages. Running windump, the Windows version of tcpdump, requires Administrator-level privileges on systems such as Windows 2000 or XP. Running tcpdump (or, in the case of Windows systems, windump) sets the network interface in promiscuous mode. Disk space management is another important consideration. Capturing raw packet data off the network can quickly eat up precious disk space. Having a huge amount of disk capacity, regularly checking how full the disk is, and archiving and then purging the contents of files that hold raw packet data is usually a necessary part of operations associated with intrusion detection and prevention.
Installing host-based sensors provides better precision of analysis, because all data gleaned by each sensor are for a particular host, and because the data indicate what traffic that host actually received (and also possibly how that host reacted to the input). In contrast, sensors placed at intermediate points on the network will record data about traffic that may or may not have actually reached the host. Additionally, host-based sensors are far more likely to provide information about insider attacks, especially if the attacker has had physical access to the target host.
Although network-based sensors (especially those deployed at external gateways to networks) provide a wide range of data, effectively covering many hosts, network-based sensors have a number of limitations.
One major concern is throughput rate. A sensor may receive so much input that it simply cannot keep up with it. Many types of sensors (such as those based on bpf) have difficulty handling throughput much greater than 350–400 Mbps, and a few have trouble with even lower input rates. Although a sensor may react by dropping excess packets, the sensor may also crash, yielding no data whatsoever until it is restarted. Alternatively, an overloaded sensor may cause excessive resource utilization on the machine on which it runs.
Additionally, in switched networks, network-based sensors cannot capture packet data simply by putting an interface in promiscuous mode—switched networks present significant hurdles to capturing packets. Obtaining packet data in switched networks thus requires that one or a number of potential special solutions be used. One such method is deploying a special kind of port known as a spanning port between a switch or similar device and a host used to monitor network traffic. Another is to place a hub between two switches, or between a switch and a router, or to simply tap the network traffic using a vampire or other type of tap.
Encrypted network traffic presents an even further level of complication. The most frequently used solution is placing a sensor at an endpoint where the traffic is in cleartext.
Capturing packet data in switched networks is thus anything but a simple matter, but solving this issue is well described elsewhere. If you need more information concerning this issue, see Chapter 6 of Incident Response: A Strategic Guide to Handling System and Network Security Breaches, by Eugene Schultz and Russell Shumway (see www.newriders.com).
One possible solution for bandwidth problems in sensors is to install filters that limit the types of packets that the sensor receives. In our experience, of all the transport protocols (TCP, UDP, and ICMP) that can be captured and analyzed, TCP is the most important to examine because of its association with attack activity. In other words, given a choice between analyzing TCP, UDP, or ICMP traffic, TCP would often be the best single choice for intrusion-detection and intrusion-prevention purposes. A filter can be configured to limit input for one or more sensors to TCP traffic only. This solution is, of course, not optimal from an intrusion-detection perspective because it misses other potentially important data. But if sensors are becoming overwhelmed with traffic, this is a viable strategy.
A variation on this strategy is to install a filter that accepts only TCP traffic on a few sensors, to install a filter that accepts only UDP traffic on others, and to install still another filter that accepts only ICMP packets on yet other sensors. Alternatively, sensors can be removed from points in the network with very high throughput—removed from the external gateway and moved to gateways for internal subnets, for example (see Figure 6-3). Doing this helps overcome any throughput limitations in sensors, but it also diminishes the value of sensors in terms of their breadth of intrusion-detection data gathering.
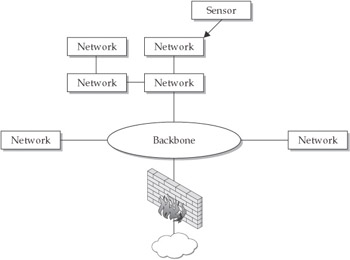
Figure 6-3: Deploying sensors in the network periphery
Still another possibility is to modify sensors to sample input according to a probabilistic model if they become overloaded with packets. The rationale for doing so is that although many packets may be missed, at least a representative set of packets can be analyzed, yielding a realistic view of what is occurring on the network and serving as a basis for stopping attacks that are found at gateways and in individual hosts.
Host-based sensors can be placed at only one point—on a host—so the point within the network where this type of sensor is deployed is not nearly as much of an issue. As always, the benefits should outweigh the costs. The costs of deploying host-based sensors generally include greater financial cost (because of the narrower scope of host-based as opposed to network-based sensors), greater utilization of system resources on each system on which they are deployed, and the consequences of being blind to what is happening on a host due to unauthorized disabling of the sensor on the host (especially if that host is a sensitive or valuable system). Although network-based sensors are generally used in DMZs, for example, deploying a host-based sensor on a particularly critical public web server within a DMZ would be reasonable.
A hybrid approach—deploying network-based sensors both at external gateways as well as at gateways to subnets or within virtual local area networks (VLANs) and using host-based sensors where most needed—is in many cases the best approach to deploying sensors (see Figure 6-4). This kind of sensor deployment ensures that packet data for traffic going in and out of the network, as well as at least some of the internal traffic, will be captured. If a sensor at an external gateway becomes overwhelmed with data, data capture within the network itself can still occur. Furthermore, although the network-based sensors at external gateways are unlikely to glean information about insider attacks, the internal network-based sensors are much more likely to do so. At the same time, deploying host-based sensors on especially sensitive and valuable servers is likely to yield the information necessary to determine whether inside or outside attacks have occurred and, in the case of IPSs, may possibly stop malicious code from executing or unauthorized commands from being run in the first place. Finally, if host-based sensors fail, there will at least be some redundancy—network-based sensors (especially the internally deployed network-based sensors) can provide some information about attacks directed at individual systems.
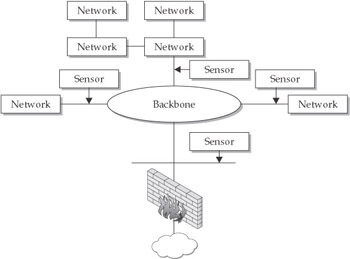
Figure 6-4: A hybrid approach to deploying sensors
Sensor Security Considerations
Both the placement and sophistication of sensors vary considerably from one intrusion-detection or intrusion-prevention implementation to another. The security considerations associated with sensors thus also vary considerably. Despite these variations, of the three major components of a multi-tiered architecture, sensors are the most frequently attacked.
In the case of low-end sensors that can only capture network traffic, the normal worst case if they become compromised is that they yield a lower hit rate. Conceivably, an ingenuous attacker could also subvert a low-end sensor to inject false data to be sent to clients or to cause denial of service by flooding them with input. However, in the case of high-end sensors, such as sensors that have embedded policies and that may also preprocess data sent to agents, the range of outcomes in case of subversion is potentially more diverse. Injection of bogus data and denial of service are just a few of the outcomes if one or more high-end sensors become compromised. One of the worst possible outcomes is subversion of the entire IDS or IPS itself. In other words, the other components of the system may be compromised because the sensors are under the control of attackers. Dependencies between systems and devices may enable someone who has gained unauthorized access to one component (in this case, sensors) to more easily gain access to others. Sensors may contain information concerning the configuration of other systems, they may have dependencies that allow trusted access to other systems, they may identify hosts of which the sensors are aware, and so forth. Ideally, each component in a multi-tiered architecture will be relatively independent of the others, but in reality this is often not true.
Component Independence
Lack of independence of components in an IDS can spell big trouble. An interesting example is the remote procedure call (RPC) reassembly bug in earlier (version 1) versions of Snort. It is possible for an attacker to gain unauthorized access to the node running Snort with the privileges of the process under which it is running by sending specially crafted packets. Even if the process is not root, the IDS will nevertheless be able to control data flow and records. This is actually an agent-specific problem, but the vulnerability that allows access to a process spawned on behalf of the agent can allow more widespread access. The major lesson here is that there needs to be as much independence between the components of an architecture as possible. Additionally, countermeasures need to be built in, such that if one component is compromised, the others will not be more at risk.
The bottom line is that sensors need at least a baseline level of security, perhaps even higher in many cases. At a minimum, the host on which each sensor resides needs to be hardened by tightening file permissions (especially permissions for files that the sensor uses and creates), restricting privileges, restricting access to the system itself, running as few services as possible, installing patches, and so on. Each sensor should normally be placed where it is most needed, but if a sensor is not very hardened, it might be best to move it behind a firewall so that the firewall can at least repel some of the attacks that originate from the Internet. Many vendors of IDSs provide sensors that are surprisingly vulnerable to attack; hopefully, these vendors will start providing much more attack-resistant sensors in the future.
Additionally, it is very important to be notified immediately if the sensor fails. Losing one or two sensors results in a somewhat lower hit rate and impaired intrusion prevention, but losing even more sensors can prove catastrophic if an organization is highly dependent on intrusion-detection and intrusion-prevention. An IDS or IPS that attempts to contact all sensors at frequent, scheduled times to discover failed sensors is very advantageous in this respect.
Finally, a secure communication channel between each sensor and the other components is highly desirable. The interception of communications between sensors and other components could lead to a range of undesirable outcomes, such as attackers being able to discover whether their attempts to evade intrusion detection have been successful, or it could lead to a compromise of privacy if personal information is contained in the packets that sensors capture. Having an authenticated, encrypted channel between sensors and other components is a reasonable solution to this problem.
Agents
Agents are the next consideration in intrusion-detection and intrusion-prevention architectures. This section discusses the functions, deployment considerations, and security considerations associated with agents.
Agent Functions
Agents are relatively new in intrusion detection and prevention, having been developed in the mid-1990s. As mentioned previously in this chapter, their primary function is to analyze input provided by sensors. Although many definitions exist, we’ll define an agent as a group of processes that run independently and that are programmed to analyze system behavior or network events or both to detect anomalous events and violations of an organization’s security policy. Each agent should ideally be a bare-bones implementation of a specialized function. Some agents may, for example, examine network traffic and host-based events rather generically, such as checking whether normal TCP connections have occurred, their start and stop times, and the amount of data transmitted or whether certain services have crashed. Having agents that examine UDP and ICMP traffic is also desirable, but the UDP and ICMP protocols are stateless and connectionless. Other agents might look at specific aspects of application layer protocols such as FTP, TFTP, HTTP, and SMTP as well as authentication sessions to determine whether data in packets or system behavior is consistent with known attack patterns. Still others may do nothing more than monitor the performance of systems.
Our definition of agent states that agents run independently. This means that if one agent crashes or is impaired in some manner, the others will continue to run normally (although they may not be provided with as much data as before). It also means that agents can be added to or deleted from the IDS or IPS as needed. In fact, in a small intrusion-detection or intrusion-prevention effort, perhaps only a few of two dozen or so agents may be deployed. In a much larger effort, perhaps all of the agents may be deployed.
Although each agent runs independently on the particular host on which it resides, agents often cooperate with each other. Each agent may receive and analyze only one part of the data regarding a particular system, network, or device. Agents normally share information they have obtained with each other by using a particular communication protocol over the network, however. When an agent detects an anomaly or policy violation (such as a brute force attempt to su to root, or a massive flood of packets over the network), in most cases, the agent will immediately notify the other agents of what it has found. This new information, combined with the information another agent already has, may cause that agent to report that an attack on another host has also occurred.
Agents sometimes generate false alarms, too, thereby misleading other agents, at least to some degree. The problem of false alarms is one of the proverbial vultures hovering over the entire intrusion-detection and intrusion-prevention arena, and cooperating but false-alarm-generating agents can compound this problem. However, a good IDS or IPS will allow the data that agents generate to be inspected on a management console, allowing humans to spot false alarms and to intervene by weeding them out.
The Advantages and Disadvantages of Agents
The use of agents in intrusion detection and prevention has proven to be one of the greatest breakthroughs. Advantages include:
- Adaptability Having a number of small agents means that any of them can potentially be modified to meet the needs of the moment; agents can even be programmed to be self-learning, enabling them to be able to deal with novel threats.
- Efficiency The simplicity of most agent implementations makes them more efficient than if each agent were to support many functions and to embody a great deal of code.
- Resilience Agents can and do maintain state information even if they fail or their data source fails.
- Independence Agents are implemented to run independently, so if you lose one or two, the others will not be affected.
- Scalability Agents can readily be adapted to both large- and small-scale intrusion-detection and intrusion-prevention deployments.
- Mobility Some agents (believe it or not) may actually move from one system to another; agents might even migrate around networks to monitor network traffic for anomalies and policy violations.
There are some drawbacks to using agents, too:
- Resource allocation Agents cause system overhead in terms of memory consumption and CPU allocation.
- False alarms False alarms from agents can cause a variety of problems.
- Time, effort, and resources needed Agents need to be modified according to an organization's requirements, they must be tuned to minimize false alarms, and they must be able to run in the environment in which they are deployed—this requires time, effort, and financial and other resources.
- Potential for subversion A compromised agent is generally a far greater problem than a compromised sensor.
At a bare minimum, an agent needs to incorporate three functions or components:
- A communications interface to communicate with other components of IDSs
and IPSs - A listener that waits in the background for data from sensors and messages from other agents and then receives them
- A sender that transmits data and messages to other components, such as other agents and the manager component, using established means of communication, such as network protocols
Agents can also provide a variety of additional functions. Agents can, for example, perform correlation analyses on input received from a wide range of sensors. In some agent implementations, the agents themselves generate alerts and alarms. In still other implementations, agents access large databases to launch queries to obtain more information about specific source and destination IP addresses associated with certain types of attacks, times at which known attacks have occurred, frequencies of scans and other types of malicious activity, and so forth. From this kind of additional information, agents can perform functions such as tracking the specific phases of attacks and estimating the threat that each attack constitutes.
Although the types of additional functions that agents can perform may sound impressive, “beefing up” agents to do more than simple analysis is not necessarily advantageous. These additional functions can instead be performed by the manager component (to be discussed shortly), leaving agents free to do what they do best. Simplicity—in computer science jargon, Occam’s razor—should be the overwhelming consideration with agents, provided, of course, that each agent implementation embodies the required functionality. Additionally, if resource utilization is already a problem with simple agents, think of the amount of resources multifunctional agents will use!
Agent Deployment Considerations
Decisions about deployment of agents are generally easier to make than decisions concerning where to deploy sensors. Each agent can and should be configured to the operating environment in which it runs. In host-based intrusion detection, each agent generally monitors one host, although, as mentioned before, sometimes sensors on multiple hosts send data to one or more central agents. Choosing the particular hosts to monitor is thus the major dilemma in deciding on the placement of host-based agents. Most organizations that use host-based intrusion detection select “crown jewel” hosts, such as servers that are part of billing and financial transaction systems, more than any other. A few organizations also choose a few widely dispersed hosts throughout the network to supplement network-based intrusion detection.
In network-based intrusion detection, agents are generally placed in two locations:
- Where they are most efficient Efficiency is related to the particular part of a network where connections to sensors and other components are placed. The more locally coresident the sensors and agents are, the better the efficiency. Having an agent in one network and the sensors that feed the agent in another is an example of inefficiency.
- Where they will be sufficiently secure Security of agents is our next topic, so suffice it to say here that placing agents in secure zones within networks, or at least behind one or more firewalls, is essential.
Finally, tuning agents is a very complicated issue. It is highly desirable that each agent produce as high a hit rate (positive recognition rate) as possible, while also producing as low a false-alarm rate as possible. When agents are first deployed, however, they usually perform far from optimally in that they yield output with excessively high false-alarm rates. Fortunately, it is possible to reduce the false-alarm rate by eliminating certain attack signatures from an analyzer, or by adjusting the statistical criteria for an attack to be more rigorous, thereby reducing the sensitivity of the sensor. Doing so, however, may lower the positive recognition rate, causing other problems. Many intrusion- detection experts would rather have more false alarms than false negatives (misses). Each false negative, after all, represents a failure to notice ongoing events that may quickly proliferate catastrophically if you don’t have the opportunity to intervene. Each false alarm represents extra effort, but experts can quickly dismiss false alarms. Most commercial IDSs have management consoles that enable those with sufficient privileges to make whatever adjustments in agents are necessary.
Agent Security Considerations
The threat of subversion of agents is a major issue. Agents are typically much smarter than sensors; if an agent is successfully attacked, not only will the attacker be able to stop or subvert the type of analysis that the agent performs, but this person will also be able to glean information that is likely to prove useful in attacking the other components of the IDS or IPS. Compromised agents thus can rapidly become a security liability.
Fortunately, the way agents are typically deployed provides at least some level of defense against attacks that are directed at them. Agents (especially in network-based IDSs and IPSs) are generally distributed throughout a network or networks. Each agent must therefore be individually discovered and then attacked. This substantially increases the work involved in attacking agents, something that is very desirable from a security perspective. The diversity of functionality within agents also provides some inherent security—each is to some degree unique, and attacking each presents unique challenges to the attacker. Additionally, mobile agents are becoming increasingly popular, and agent mobility makes discovery of agents by attackers considerably more difficult.
Nevertheless, agents need to be secured by doing many of the same things that must be done to protect sensors—hardening the platform on which they run, ensuring that they can be accessed only by authorized persons, and so on. Here are a few guidelines:
- Dedicate the hardware platform Dedicating the hardware platform on which agents run to agent functionality is essential. If other applications run on the same platform as one that houses one or more agents, attackers may be able to access the platform via the other applications and then escalate privileges to the point where they gain control over all the agents.
- Encrypt traffic Because of the high importance of agent security, encrypting all traffic between agents and other agents and possibly also between agents and other components is also advisable. Including a digital signature that
must be validated before any message is processed is another good measure. - Filter input Additionally, to guard against denial-of-service attacks, filters that prevent excessive and repetitive input from being received should be deployed. Many vendor agent implementations have this kind of filtering capability built in.
Other interesting approaches to agent security include using APIs (application programming interfaces) to control data transfer between agents. In this approach, one of the most important considerations is sanitizing the data transferred between agents to guard against the possibility of exploiting vulnerabilities to gain control of agents and the platforms on which they run by passing specially crafted data.
Manager Component
The final component in a multi-tiered architecture is the manager (sometimes also known as the server) component. The fundamental purpose of this component is to provide an executive or master control capability for an IDS or IPS.
Manager Functions
We’ve seen that sensors are normally fairly low-level components and that agents are usually more sophisticated components that, at a minimum, analyze the data they receive from sensors and possibly from each other. Although sensors and agents are capable of functioning without a master control component, having such a component is extremely advantageous in helping all components work in a coordinated manner. Additionally, the manager component can perform other valuable functions, which we’ll explore next.
Data Management
IDSs and IPSs can gather massive amounts of data. One way to deal with this amount of data is to compress (to help conserve disk space), archive it, and then periodically purge it. This strategy, however, is in many cases flawed, because having online rather than archived data on storage media is often necessary to perform the necessary ongoing analyses. For example, you might notice suspicious activity from a particular internal host and wonder if there has been similar activity over the last few months. Going to a central repository of data is preferable to having to find the media on which old data reside and restoring the data to one or more systems.
Having sufficient disk space for management purposes is, of course, a major consideration. One good solution is RAID (Redundant Array of Inexpensive Disks), which writes data to multiple disks and provides redundancy in case of any disk failing. Another option is optical media, such as worm drives (although performance is an issue).
Ideally, the manager component of an IDS or IPS will also organize the stored data. A relational database, such as an Oracle or Sybase database, is well suited for this purpose. Once a database is designed and implemented, new data can be added on the fly, and queries against database entries can be made.
Alerting
Another important function that the manager component can perform is generating alerts whenever events that constitute high levels of threat occur (such as a compromise of a Windows domain controller or a network information service (NIS) master server, or of a critical network device, such as a router). Agents are designed to provide detection capability, but agents are normally not involved in alerting because it is more efficient to do so from a central host. Agents instead usually send information to a central server that sends alerts whenever predefined criteria are met. This requires that the server not only contain the addresses of operators who need to be notified, but also have an alerting mechanism.
Normally, alerts are either sent via e-mail or via the Unix syslog facility. If sent via e-mail, the message content should be encrypted using PGP (Pretty Good Privacy) or some other form of message encryption. Attackers who discover the content of messages concerning detected intrusions or shunned IP addresses can adjust their strategies (such as using a different source IP address if the one they have been using is now blocked), thereby increasing their efficiency. The syslog facility’s main advantage is flexibility— syslog can send messages about nearly anything to just about everybody if desired. Encrypting syslog content is a much bigger challenge than encrypting e-mail message content, however. Fortunately, a project called syslog-ng will sometime in the future provide encryption solutions for syslog-related traffic. Additionally, the syslog server will ideally keep an archive of alerts that have been issued in case someone needs to inspect the contents of previous alerts.
Event Correlation
Another extremely important function of the manager component is correlating events that have occurred to determine whether they have a common source, whether they were part of a series of related attacks, and so forth. Event correlation is so important that Chapter 12 is devoted to the topic.
High-Level Analysis
Still another function that the manager component may perform is high-level analysis of the events that the intrusion-detection or intrusion-prevention tool discovers. The manager component may, for example, track the progression of each attack from stage to stage, starting with the preparatory (doorknob rattling) stage. Additionally, this component can analyze the threat that each event constitutes, sending notification to the alert- generation function whenever a threat reaches a certain specified value. Sometimes high-level analysis is performed by a neural network or expert system that looks for patterns in large amounts of data.
Monitoring Other Components
We’ve seen previously in this chapter how having a monitoring component to check the health of sensors and agents is important. The manager is the ideal component in which to place this function because (once again) this function is most efficient if it is centralized.
The manager can, for instance, send packets to each sensor and agent to determine whether each is responsive to input on the network. Better yet, the manager can initiate connections to each sensor and agent to determine whether each is up and running. If the manager component determines that any other component has failed, it can notify its alerting facility to generate an alert.
In host-based intrusion detection, the manager can monitor each host to ensure that logging or auditing is functioning correctly. The manager component can also track utilization of system and network resources, generating an alert if any system or any part of the network is overwhelmed.
Policy Generation and Distribution
Another function that is often embedded in the manager component is policy generation and distribution. In the context of the manager component, policy refers to settings that affect how the various components of an intrusion-detection or intrusion-prevention system function. A policy could be set, for example, to activate all agents or to move an agent from one machine to another.
Nowhere is policy more important than in IPSs. Based on data that the manager component receives, the manager component creates and then distributes a policy or a change in policy to individual hosts. The policy might tell each host to not accept input for a particular source IP address or to not execute a particular system call. The manager component is generally in charge of creating, updating, and enforcing policy.
Security Management and Enforcement
Security management and enforcement is one of the most critical functions that can be built into the manager component. This function is covered in the “Manager Security Considerations” section later in this chapter.
Management Console
Providing an interface for users through a management console is yet another function of the manager component. This function, like most of the others covered in this section, makes a huge difference in terms of the value of an IDS or IPS to an organization. The management console should display critical information—alerts, the status of each component, data in individual packets, audit log data, and so forth—and should also allow operators to control every part of an IDS or IPS. For example, if a sensor appears to be sending corrupted data, an operator should be able to quickly shut down this sensor using the management console.
The Importance of Being Able to View Packet Data
Management consoles should allow operators to readily access all data that an IDS or IPS gathers, sends, and processes. A type of data not available in some implementations of IDSs and IPSs is packet data. Saving packet data, after all, requires huge amounts of disk space. But packet data are often one of the most useful types of data for operators. Errors in applications, the universal tendency for IDSs to produce false alarms, and tricks played by attackers can, for example, cause erroneous output or may prompt further questions. Going directly to packet data often resolves these issues and questions.
Suppose, for example, that an IDS reports a distributed scan from a certain range of IP addresses. Going to the IP portion of each packet will yield information such as the indicated IP source address, the version of the IP protocol, and the TTL (time-to-live parameter). If the apparent IP source addresses for the distributed scan are 15 hops away (as revealed by the output of the “traceroute or “tracert command), but the TTL parameter of most packets is equal to four or five, something is wrong. Many operating systems and applications assign an initial TTL value of 64 or 128 to IP packets they create. In this case, packets from hosts that are 15 hops away on the network should have TTL values equal to 115 (or perhaps 51) or so. The illogically low TTL values indicate that these packets have almost certainly been fabricated (spoofed).
The bottom line is that you should think twice if you are considering buying an IDS or IPS that does not allow you to easily access packet data.
The importance of human-factors engineering in the design of a management console cannot be overstated. Management consoles are almost invariably designed to be the sole means through which operators and analysts interact with IDSs and IPSs. Display formats should be easy to comprehend, and interaction sequences should be intuitive. In short, the possibility of human error should be minimized. The major problems with management consoles in IDSs and IPSs today include excessive complexity, nonintuitive navigation methods, and cluttered displays, resulting in unnecessarily long learning times, confusion, and elevated error rates.
Manager Deployment Considerations
One of the most important deployment considerations for the manager component is ensuring that it runs on extremely high-end hardware (with a large amount of physical memory and a fast processor) and on a proven and reliable operating system platform (such as Solaris or Red Hat Linux). Continuous availability of the manager component is essential—any downtime generally renders an IDS or IPS totally worthless. Using RAID and deploying redundant servers in case one fails are additional measures that can be used to help assure continuous availability.
Decisions concerning where within a network to deploy the management console should (like the deployment of agents) be based on efficiency—the management component should be in a location within the network that minimizes the distance from agents with which it communicates—and on security, as discussed next.
Manager Security Considerations
Of the three major components of a multi-tiered architecture, sensors are attacked most often, and compromised or disabled agents can cause considerable trouble, but a single successful attack on a management console is generally the worst imaginable outcome. Because of the centrality of the manager component to an entire IDS or IPS, such an attack can quickly result in all components in a multi-tiered architecture becoming compromised or unusable, and it can also result in destruction of all data and alerts that are centrally collected. It is thus advisable to devote considerable effort to hardening the host on which the management console runs.
Hardening includes implementing measures that prevent denial-of-service attacks, such as installing a properly configured firewall or TCP wrapper on the box that houses the manager component, ensuring that all vendor patches are installed, and not running unnecessary services. The server should also be protected by one or more external and possibly also internal firewalls, and it should not be located in a portion of a network that has particularly high levels of traffic. The hardware platform on which the manager component runs must also be dedicated solely to this function, and it should have a special sensor—a watchdog function that is independent of the built-in logging capabilities—to provide specialized monitoring of all activity on that host.
Unauthorized physical access is always a major concern in any system, but unauthorized access to the management console is even more critical. Putting suitable physical access controls in place is thus imperative. Implementing measures such as a keyboard lock and a locking encasement over all hardware used in connection with the manager component, and placing the system in a server room with restricted access (through a combination lock or badge reader), is a good starting point. Assigning a CMOS boot password or, in the case of Unix and Linux systems, protecting against unauthorized single user boots is also essential. Auditing all access to the room in which the manager component resides and enabling a password-protected screensaver that activates shortly after each user’s session becomes inactive are further effective physical security measures. Protecting against fire and water hazards and providing suitable temperature control are also highly advisable.
Authentication is also a special consideration for the manager component. Given that password-based authentication has become increasingly ineffective in keeping out unauthorized users, you should require third-party authentication for access to any part of the manager component, but especially the management console. Smart cards and tokens (such as SecurID tokens by RSA) are two of the currently popular forms of third-party authentication. Although biometric authentication is still in its infancy, some forms of biometric authentication, such as facial recognition, are also becoming sufficiently reliable to merit their strong consideration in contexts such as management console access.
Finally, providing suitable levels of encryption is critical. All communications between the manager component and any other component need to be encrypted using strong encryption, such as 192- or 256-bit Advanced Encryption Standard (AES) encryption. Sessions from remote workstations to the management console, in particular, need to be encrypted. If not, they could be hijacked, or their contents could be divulged to unauthorized persons. Any kind of data about individuals that is stored on the manager component should also be encrypted to avoid privacy breaches and to conform to state and local laws.
Summary
This chapter has covered intrusion-detection and intrusion-prevention system architectures. The term architecture refers to the functions supported by and relationships among machines, network devices, programs, and processes, and the communications between each. Three major types of architectures—single-tiered, multi-tiered, and peer-to-peer— are generally used in intrusion detection and intrusion prevention.
A single-tiered architecture consists of one component that performs all of the functions. A multi-tiered architecture has more than one component, and each component communicates with some or all of the others. Components are hierarchical, and they include the sensors (which tend to be at the low-end), the agents (which are more sophisticated, but usually are dedicated to one type of analysis), and the manager component, which typically embodies many centralized functions. The final type of architecture considered in this chapter is the peer-to-peer architecture, an architecture in which there are multiple components, such as firewalls, each of which is a peer (not a subordinate or superordinate) of the others.
Of the three major types of architectures, multi-tiered architectures are used more than any other. Sensors perform data collection, agents take the information they obtain from sensors and possibly also from other agents and analyze it, and the manager component provides centralized, sophisticated functionality, such as data aggregation, data correlation, policy creation and distribution, and alerting. Operators and analysts generally interact with the management console, which is the user interface portion of the manager component, to control the entire IDS or IPS.
Many decisions about deployment and security need to be made for each component. In general, the higher the level of the component, the more need for high levels of security. Sensors, for example, generally can be deployed anywhere on the network without causing undo concern, whereas agents need greater levels of protection and should reside where they operate most efficiently and are the most secure. Manager components need the most security and should be afforded the same protections that agents receive, as well as having additional controls, such as physical security measures, strong authentication, and strong encryption.
Part I - Intrusion Detection: Primer
- Understanding Intrusion Detection
- Crash Course in the Internet Protocol Suite
- Unauthorized Activity I
- Unauthorized Activity II
- Tcpdump
Part II - Architecture
Part III - Implementation and Deployment
Part IV - Security and IDS Management
EAN: 2147483647
Pages: 163
