IDS and IPS Internals
Overview
IDSs and IPSs can be as simple or as complex as you want them to be. At the simplest level, you could use a packet-capturing program to dump packets to files, and then use commands such as egrep and fgrep within scripts to search for strings of interest within the files.
This approach is not practical, though, given the sheer volume of traffic that must be collected, processed, and stored for the simple level of analysis that could be performed. Yet, even at this rudimentary level, more would be happening than one might imagine. Packets would be collected, and then decoded. Some of these packets would be fragmented, requiring they be reassembled before they could be analyzed. TCP streams would often need to be reassembled, too.
In a more complex IDS or IPS, additional sophisticated operations, such as filtering out undesirable input, applying firewall rules, getting certain kinds of incoming data in a format that can be more easily processed, running detection routines on the data, and executing routines such as those that shun certain source IP addresses would occur. In this latter case, even more sophisticated internal events and processes would occur.
This chapter covers the internals of IDSs and IPSs, focusing on information flow in these systems, detection of exploits, dealing with malicious code, how output routines work, and, finally, how IDSs and IPSs can be defended against attacks against them.
Information Flow in IDS and IPS
How does information move internally through IDSs and IPSs? This section answers this question.
Raw Packet Capture
IDS and IPS internal information flow starts with raw packet capture. This involves not only capturing packets, but also passing the data to the next component of the system.
As explained in Chapter 6, promiscuous mode means a NIC picks up every packet at the point at which it interfaces with network media (except, of course, in the case of wireless networks, which broadcast signals from transmitters). To be in nonpromiscuous mode means a NIC picks up only packets bound for its particular MAC address, ignoring the others. Nonpromiscuous mode is appropriate for host-based intrusion detection and prevention, but not for network-based intrusion detection and prevention. A network-based intrusion detection/prevention system normally has two NICs—one for raw packet capture and a second to allow the host on which the system runs to have network connectivity for remote administration.
Most packets in today’s networks are IP packets, although AppleTalk, IPX, SNA, and other packets still persist in some networks. The IDS or IPS must save the raw packets that are captured, so they can be processed and analyzed at some later point. In most cases, the packets are held in memory long enough so initial processing activities can occur and, soon afterwards, written to a file or a data structure to make room in memory for subsequent input or discarded.
Solving Problems
IDSs and IPSs typically experience all kinds of problems, but one of the most-common problems is packet loss. A frequent variation of this problem is that the NIC used to capture packets receives packets much faster than the CPU of the host on which the IDS/IPS runs is capable of despooling them. A good solution is simply to deploy higher-ended hardware.
Another problem is this: the IDS/IPSs itself cannot keep up with the throughput rates. Throughput rate is a much bigger problem than most IDS/IPS vendors publicly acknowledge—some of the best-selling products have rather dismal input processing rates. One solution is to filter out some of the input that would normally be sent to the IDS or IPS, as discussed shortly. Another more drastic solution is to change to another, different IDS or IPS. High-end IDSs/IPSs can now process input at rates up to 2GB (see http://enterprisesecurity.symantec.com/products/products.cfm?ProductID=156 for information about Symantec's ManHunt firewall, for example).
Yet another manifestation of the packet-loss problem is misdirected packet fragments on connections that have an intermediate switching point with a smaller maximum transmission unit (MTU) than that of the remote system. In this case, the problem could, once again, simply be a CPU that is too slow—the problem may not be fragmentation per se. Or, the problem could be inefficient packet reassembly, which is discussed in the section “Fragment Reassembly.”
Whatever the solution to any of these problems might be, it is important to realize that packet loss is a normal part of networking—not exactly anything to panic about (unless, of course, the loss rate starts to get unacceptably high).
Chapters 5 and 6 covered the details of how programs such as tcpdump and libpcap work in connection with packet capture. These programs run in an “endless loop,” waiting until they obtain packets from the network card device driver.
Filtering
No need for an IDS or IPS to capture every packet necessarily exists. Filtering out certain types of packets could, instead, be desirable. Filtering means limiting the packets that are captured according to a certain logic based on characteristics, such as type of packet, IP source address range, and others. Especially in very high-speed networks, the rate of incoming packets can be overwhelming and can necessitate limiting the types of packets captured. Alternatively, an organization might be interested in only certain types of incoming traffic, perhaps (as often occurs) only TCP traffic because, historically, more security attacks have been TCP-based than anything else.
Filtering raw packet data can be done in several ways. The NIC itself may be able to filter incoming packets. Although early versions of NICs (such as the 3COM 3C501 card) did not have filtering capabilities, modern and more sophisticated NICs do. The driver for the network card may be able to take bpf rules and apply them to the card. The filtering rules are specified in the configuration of the driver itself. This kind of filtering is not likely to be as sophisticated as the bpf rules themselves, however.
Another method of filtering raw packet data is using packet filters to choose and record only certain packets, depending on the way the filters are configured. libpcap, for example, offers packet filtering via the bpf interpreter. You can configure a filter that limits the particular types of packets that will be processed further. The bpf interpreter receives all the packets, but it decides which of them to send on to applications. In most operating systems filtering is done in kernel space but, in others (such as Solaris), it is done in user space (which is less efficient, because packet data must be pushed all the way up the OSI stack to the application layer before it can be filtered). Operating systems with the bpf interpreter in the kernel are, thus, often the best candidates for IDS and IPS host platforms, although Solaris has an equivalent capability in the form of its streams mechanism (see http://docs.sun.com/db/doc/801-6679/6i11pd5ui?a=view).
Filtering rules can be inclusive or exclusive, depending on the particular filtering program or mechanism. For example, the following tcpdump filter rule (port http) or (udp port 111) or (len >= 1 and len <= 512) will result in any packets bound for an http port, or for UDP port 111 (the port used by the portmapper in Unix and Linux systems), or that are between 1 and 512 bytes in length being captured—an inclusive filter rule.
Packet Decoding
Packets are subsequently sent to a series of decoder routines that define the packet structure for the layer two (datalink) data (Ethernet, Token Ring, or IEEE 802.11) that are collected through promiscuous monitoring. The packets are then further decoded to determine whether the packet is an IPv4 packet (which is the case when the first nibble in the IP header is 4), an IP header with no options (which is the case when the first nibble in the IP header is 5), or IPv6 (where the first nibble in the IP header will be 6), as well as the source and destination IP addresses, the TCP and UDP source and destination ports, and so forth.
It is quite important to realize just how broken a good percent of the traffic on the Internet is. Everyone agrees on the steps for the so-called TCP three-way handshake, but numerous instances exist where the RFCs have not done a perfect job of defining behavior for certain protocols. Also, in many other cases, RFCs have been at least partially ignored in the implementation of network applications that use these protocols, so some kind of “sanity check” on these protocols is thus needed. Packet decoding accordingly examines each packet to determine whether it is consistent with applicable RFCs. The TCP header size plus the TCP data size should, for instance, equal the IP length. Packets that cannot be properly decoded are normally dropped because the IDS/IPS will not be able to process them properly.
Some IDSs such as Snort (covered in Chapter 10) go even further in packet decoding in that they allow checksum tests to determine whether the packet header contents coincide with the checksum value in the header itself. Checksum verification can be done for one, or any combination of, or all of the IP, TCP, UDP, and ICMP protocols. The downside of performing this kind of verification is that today’s routers frequently perform checksum tests and drop packets that do not pass the test. Performing yet another checksum test within an IDS or IPS takes its toll on performance and is, in all likelihood, unnecessary. (Despite this, the number of IP fragments per day is large).
Storage
Once each packet is decoded, it is often stored either by saving its data to a file or by assimilating it into a data structure while, at the same time, the data are cleared from memory. Storing data to a file (such as a binary spool file) is rather simple and intuitive because “what you see is what you get.” New data can simply be appended to an existing file or a new file can be opened, and then written to.
But writing intrusion detection data to a file also has some significant disadvantages. For one thing, it is cumbersome to sort through the great amount of data within one or more file(s) that are likely to be accumulated to find particular strings of interest or perform data correlation, as discussed in Chapter 12. Additionally, the amount of data that are likely to be written to a hard drive or other storage device presents a disk space management challenge. An alternative is to set up data structures, one for each protocol analyzed, and overlay these structures on the packet data by creating and linking pointers to them.
Taking this latter approach is initially more complicated, but it makes accessing and analyzing the data much easier. Still another alternative is to write to a hash table to condense the amount of data substantially. You could, for example, take a source IP address, determine to how many different ports that address has connected, and any other information that might be relevant to detecting attacks, and then hash the data. The hash data can serve as a shorthand for events that detection routines can later access and process.
Fragment Reassembly
Decoding “makes sense” out of packets, but this, in and of itself, does not solve all the problems that need to be solved for an IDS/IPS to process the packets properly. Packet fragmentation poses yet another problem for IDSs and IPSs. A reasonable percentage of network traffic consists of packet fragments with which firewalls, routers, switches, and IDSs/IPSs must deal. Hostile fragmentation, packet fragmentation used to attack other systems or to evade detection mechanisms, can take several forms:
- One packet fragment can overlap another in a manner that the fragments will be reassembled so subsequent fragments overwrite parts of the first one instead of being reassembled in their “natural” sequential order. Overlapping fragments are often indications of attempted denial-of-service attacks (DoS) or IDS/IPS or firewall evasion attempts (if none of these know how to deal with packets of this nature, they would be unable to process them further).
- Packets may be improperly sized. In one variation of this condition, the fragments are excessively large—greater than 65,535 bytes and, thus, likely to trigger abnormal conditions, such as excessive CPU consumption in the hosts that receive them. Excessively large packets thus usually represent attempts to produce DoS. An example is the “ping of death” attack in which many oversized packets are sent to victim hosts, causing them to crash. Or, the packet fragments could be excessively short, such as less than 64 bytes. Often called a tiny fragment attack, the attacker fabricates, and then sends packets broken into tiny pieces. If the fragment is sufficiently small, part of the header information gets displaced into multiple fragments, leaving incomplete headers. Network devices and IDSs/IPSs may not be able to process these headers. In the case of firewalls and screening routers, the fragments could be passed through and on to their destination although, if they were not fragmented, the packet might not have been allowed through. Or, having to reassemble so many small packets could necessitate a huge amount of memory, causing DoS.
- Still another way of fragmenting packets is to break them up, so a second fragment is contained completely within the first fragment. The resulting offsets create a huge program for fragment-reassembly process, causing the host that received these fragments to crash. This kind of attack is known as a teardrop attack.
Evading Intrusions
As new and better systems to detect and prevent intrusions emerge, the black-hat community is devoting more effort to discover more effective ways to defeat them. Many network-based IDS and IPS tools go through a plethora of data trying to identify signatures of known exploits in the data. Evasion focuses on fooling signature-based attack detection by changing the form of an attack. Fragroute is a tool that works in this manner—it breaks packets into tiny fragments in extremely unusual ways before transmitting them across the network. A network-based IDS or IPS collects these fragments, and then tries to decode and reassemble them before detection routines analyze their data, but it will not be able to do so properly. In particular, older IDSs are vulnerable to fragroute attacks.
Although many types of packet-fragmentation attacks exist, most of them are currently pass. Most OS vendors have developed patches for the vulnerabilities on which fragmentation attacks capitalized soon after the vulnerabilities were made public. Meanwhile, new releases of operating systems have been coded in a manner so they are not vulnerable to these attacks. The same applies to IDSs, IPSs, and firewalls, all of which are likely to detect ill-formed fragments, but not process them any further. So, knowing about packet fragmentation attacks and their potential perils is important, usually nothing special must normally be done to defend systems against them, provided you use recent versions of IDSs/IPSs and network devices.
A critical consideration in dealing with fragmented packets is whether only the first fragment will be retained or whether the first fragment, plus the subsequent fragments, will be retained. Retaining only the first fragment is more efficient. The first fragment contains the information in the packet header that identifies the type of packet, the source and destination IP addresses, and so on—information that detection routines can process later. Having to associate subsequent fragments with the initial fragment requires additional resources. At the same time, however, although some of the subsequent fragments are unlikely to contain information of much value to an IDS or IPS, this is not true for many types of attacks, such as those in which many HTTP GET command options are entered, and then the packets are broken into multiple fragments. Combining fragments is necessary if you want a more thorough analysis of intrusion detection data.
Fragment reassembly can be performed in a number of ways:
- The OS itself can reassemble the fragments.
- A utility can perform this function.
- The previously discussed filtering capability can reassemble fragments. The main advantage of this approach is that reassembly can be selective. UDP packets, especially those used in Network File System (NFS) mount access, tend to fragment more than do other packets, for example. Packet reassembly requires a good amount of system resources, so selecting only certain kinds of packets (such as TCP packets) to be reassembled is often best.
Stream Reassembly
Stream reassembly means taking the data from each TCP stream and, if necessary, reordering it (primarily on the basis of packet sequence numbers), so it is the same as when it was sent by the host that transmitted it and also the host that received it. This requires determining when each stream starts and stops, something that is not difficult given that TCP communications between any two hosts begin with a SYN packet and end with either a RST (reset) or FIN/ACK packet.
Stream reassembly is especially important when data arrive at the IDS or IPS in a different order from their original one. This is a critical step in getting data ready to be analyzed because IDS recognition mechanisms cannot work properly if the data taken in by the IDS or IPS are scrambled. Stream reassembly also facilitates detection of out-of-sequence scanning methods.
According to RFC 793, FIN packets should be sent only while a TCP connection is being closed. If a FIN packet is sent to a closed TCP port, the server should respond back with an RST packet. So, stream reassembly is critical in recognizing situation such as these (such as when an ACK packet is sent for a session that has not been started. Additionally, determining which of two hosts has sent traffic to the other is a critical piece of information needed by analyzers.
Stream reassembly results in knowing the directionality of data exchanges between hosts, as well as when packets are missing (in which case a good IDS/IPS will report this as an anomaly). The data from the reassembled stream are written to a file or data structure, again, either as packet contents or byte streams, or are discarded.
Stream reassembly may sound simple but, in reality, it is rather complicated because many special conditions must be handled. Policies based on system architecture usually dictate how stream reassembly occurs under these conditions.
From an IDS/IPS point of view, it is critical to know what the policy for overlapping fragments is—whether only the first fragment or all fragments are retained, for example—on each target host. One host TCP may drop overlapping fragments, whereas another may attempt to process them. Retransmissions in TCP connections pose yet another problem. Should data from the original retransmission or the subsequent one be retained?
The issue of whether the target host handles data in a SYN packet properly is yet another complication in stream reassembly. According to RFC 793, data can be inserted into a SYN packet, although this is not usually done. This also applies to FIN and RST packets. Should these data be included in the reassembled stream? Failure to include them could mean the detection routines to which the stream will be sent could miss certain attacks.
The packet timeout is another issue. What if a packet from a stream arrives after the timeout? How does the reassembly program handle this? Once again, the program doing the session reconstruction needs to know the characteristics of the target host to understand what this host saw. You might think the session has been properly reassembled when, in fact, it has not. The saving grace is that you can assume something is wrong whenever you see overlapping fragments. Reacting to overlapping fragments is, usually unnecessary; simply flagging the fact that they have been sent is sufficient, at least for intrusion-detection purposes.
A type of stream reassembly with UDP and ICMP traffic can also be done but, remember, both these protocols are connectionless and sessionless and, thus, do not have the characteristics TCP stream reassembly routines use. Some IDSs/IPSs make UDP and ICMP traffic into “pseudosessions” by assuming that whenever two hosts are exchanging UDP or ICMP packets with no pause of transmission greater than 30 seconds, something that resembles the characteristics of a TCP session (at least to some degree) is occurring. The order of the packets can then be reconstructed. This approach to dealing with UDP and ICMP traffic is based on some pretty shaky assumptions but, nevertheless, useful analyses could be subsequently performed on the basis of data gleaned from these reassembled pseudosessions.
| Note |
In general, the current generation of IDSs and IDPs actively reassemble IP fragments and TCP streams. Accordingly, certain types of fragmentation attacks against these systems that used to be able to evade these systems’ recognition capabilities no longer work. Other attacks are based on how differing operating systems put fragments back together but, even these types of attack are being thwarted by IDSs and IPSs that are aware of the flavor of the OS at the destination and that reassemble the stream appropriately for each particular OS. |
Stateful Inspection of TCP Sessions
Stateful inspection of network traffic is a virtual necessity whenever the need to analyze the legitimacy of packets that traverse networks presents itself. As mentioned previously, attackers often try to slip packets they create through firewalls, screening routers, IDSs, and IPSs by making the fabricated packets (such as SYN/ACK or ACK packets) look like part of an ongoing session or like one being negotiated via the three-way TCP handshake sequence, even though such a session was never established.
IDSs and IPSs also have a special problem in that if they were to analyze every packet that appeared to be part of a session, an attacker could flood the network with such packets, causing the IDSs and IPSs to become overwhelmed. An IDS evasion tool called stick does exactly this.
Current IDSs and IPSs generally perform stateful inspections of TCP traffic. These systems generally use tables in which they enter data concerning established sessions, and then compare packets that appear to be part of a session to the entries in the tables. If no table entry for a given packet can be found, the packet is dropped. Stateful inspection also helps IDSs and IPSs that perform signature matching by ensuring this matching is performed only on content from actual sessions. Finally, stateful analysis can enable an IDS or IPS to identify scans in which OS fingerprinting is being attempted. Because these scans result in a variety of packets sent that do not confirm to RPC 793 conventions, these scans “stand out” in comparison to established sessions.
Firewalling
Earlier in this chapter, you learned that part of the internal information flow within an IDS and IPS includes filtering packet data according to a set of rules. Filtering is essentially a type of firewalling, even through it is relatively rudimentary. But, after stateful inspections of traffic are performed, more sophisticated firewalling based on the results of the inspections can be performed. While the primary purpose of filtering is to drop packet data that are not of interest, the primary purpose of firewalling after stateful inspection is to protect the IDS or IPS itself. Attackers can launch attacks that impair or completely disable the capability of the IDS or the IPS to detect and protect. The job of the firewall is to weed out these attacks, so attacks against the IDS or IPS do not succeed. Amazingly, a number of today’s IDSs and IPSs do not have a built-in firewall that performs this function. Why? A firewall limits performance.
Putting It All Together
Figure 7-1 shows how the various type of information processing covered so far are related to each other in a host that does not support bpf. The NIC collects packets and sends them to drivers that interface with the kernel. The kernel decodes, filters, and reassembles fragmented packets, and then reassembles streams. The output is passed on to applications.
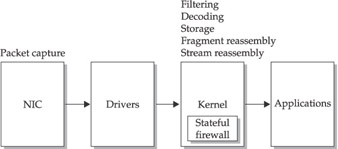
Figure 7-1: Information processing flow without bpf
Figure 7-2 shows how information processing occurs when an operating system supports bpf. In this case, a program such as libpcap performs most of the work that the kernel performs in Figure 7-1, and then passes the output to bpf applications.
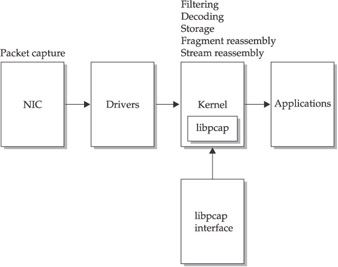
Figure 7-2: Information processing flow with bpf
Detection of Exploits
We turn our attention next toward how IDSs and IPSs detect exploits. After defining various kinds of attacks that IDSs and IPSs are designed to detect and prevent, we consider several matching methods: signature matching, rule matching, profiling, and others.
Types of Exploits
The number of exploits with which an IDS or IPS potentially must deal is in the thousands. Snort, a tool discussed in Chapter 10, has over 2000 exploit signatures, for example. Although describing each exploit is not possible in this book, the SANS Institute (http://www.sans.org) has helped the user community become acquainted with the most frequently exploited vulnerabilities by publishing the “SANS Top 20 Vulnerabilities” at http://isc.sans.org/top20.html. Consider the top 20 vulnerabilities at press time.
Top Vulnerabilities in Windows Systems
A list of Windows systems’ top vulnerabilities follows:
- Buffer overflows in Internet Information Server (IIS) script mappings and WebDAV that can be exploited by sending specially crafted excessive input, resulting in DoS, execution of rogue code, and other outcomes.
- Multiple vulnerabilities in Microsoft SQL Server that can allow unauthorized read and write access to database entries, execution of rogue commands and code, and control of the server itself by attackers (in the last case because the SQL Server administrator account is unpassworded by default).
- Weak and crackable passwords that can result in unauthorized access to systems and resources therein.
- A variety of vulnerabilities in Microsoft Internet Explorer (IE) that can allow execution of rogue commands and code, control of systems that run this browser by attackers, disclosure of cookies, and other negative outcomes.
- Unprotected shares, anonymous logons, remote Registry access, and remote procedure calls that can allow unauthorized access to and subversion of systems and resources therein.
- Vulnerabilities, such as buffer overflow conditions in Microsoft Data Access Components, such as Remote Data Services (RDS) that can allow unauthorized execution of rogue commands and code.
- Multiple vulnerabilities in Windows Scripting Host (such as in the autoexecution feature, which can be made to run unauthorized Visual Basic scripts) that can allow execution of rogue code.
- Vulnerabilities in embedded automation features in Microsoft Outlook and Outlook Express that can allow execution of rogue code.
- Peer-to-peer file sharing that can result in unauthorized access to systems and legal troubles.
- Vulnerabilities in the Simple Network Management Protocol (SNMP) that can lead to DoS and unauthorized configuration changes in systems.
Top Vulnerabilities in Unix Systems
A list of Unix systems’ top vulnerabilities follows:
- Vulnerabilities in the Berkeley Internet Name Domain (BIND) program (particularly in nxt, qinv, and in.named) that can result in DoS and execution of rogue code.
- Multiple vulnerabilities in the remote procedure call (RPC) that can lead to DoS.
- Multiple bugs in the Apache web server (such as a heap buffer overflow vulnerability in the apr_psprintf() function) that can result in DoS, unauthorized access to information, defacement of web pages, and root-level compromise of the host that runs Apache.
- Unpassworded accounts or accounts with weak passwords that can allow unauthorized access to systems (sometimes with root privileges).
- Cleartext network traffic that can lead to unauthorized reading of information and unauthorized access to systems (because cleartext passwords are exposed).
- Vulnerabilities in sendmail (such as an error in the prescan() function that enables someone to write past the end of a buffer) that can result in DoS, unauthorized execution of rogue code with root privileges or unauthorized spam relay.
- SNMP vulnerabilities that can lead to DoS and unauthorized configuration changes in systems.
- Bugs in Secure Shell (ssh) that can lead to unauthorized root access and other outcomes.
- Misconfiguration of the Network Information Service (NIS) and the Network File System (NFS) that can result in unauthorized access to files, unauthorized access to systems, and other outcomes.
- Bugs in Open Secure Sockets Layer (SSL), such as improper integer overflow handling and insecure memory deallocation, that can cause unauthorized execution of rogue code and unauthorized root access.
Although these 20 vulnerabilities are currently the most exploited ones, an IDS or IPS that recognized nothing more than the exploits for these vulnerabilities would be a dismal failure. But, because of the frequency with which these vulnerabilities are exploited in real-life settings, failure to recognize any of these 20 vulnerabilities would also be catastrophic.
The SANS Top 20 List: How Current?
The SANS Top 20 List has proven extremely useful, but it is not always updated as quickly as it needs to be. At press time, for example, the SANS Top 20 List did not include an at-the-time new, serious vulnerability in Windows systems that the MSBlaster worm and its variants exploited. The problem is in an RPC function that deals with TCP/IP message exchanges, particularly in the manner it handles improperly formed messages. The Distributed Component Object Model (DCOM) interface with RPC listens for client requests for activating DCOM objects via TCP port 135. An attacker could forge a client RPC request with a group of specially crafted arguments in a packet, causing the server that receives this packet to execute the arguments with full privileges. This vulnerability will undoubtedly be included in the next SANS Top 20 List.
Signature Matching
We’ll start with the simplest type of matching, signature-based matching.
How Signature Matching Works
As discussed previously, a signature is a string that is part of what an attacking host sends to an intended victim host that uniquely identifies a particular attack. In the case of the exploit for the ida script mapping buffer overflow vulnerability (see the sidebar “How Vulnerabilities Are Exploited”),.ida? is sufficient to distinguish an attempt to exploit the buffer overflow condition from other attacks, such as exploiting a buffer overflow condition in the idq script mapping.
Signature matching means input strings passed on to detection routines match a pattern in the IDS/IPS’s signature files. The exact way an IDS or IPS performs signature matching varies from system to system. The simplest, but most inefficient, method is to use fgrep or a similar string search command to compare each part of the input passed from the kernel to the detection routines to lists of signatures. A positive identification of an attack occurs whenever the string search command finds a match.
How Vulnerabilities Are Exploited
How are vulnerabilities exploited? Consider the first vulnerability from the SANS Top 20, buffer overflows in IIS script mappings. One of the script mappings that the IIS Indexing Service Application Programming Interface (ISAPI) uses is ida (Internet data administration). This script mapping has an unchecked buffer when it is encoding double-byte characters. Whoever wrote this script mapping did not consider what would happen if this kind of input were sent to it. Ida.dll should not accept this kind of input at all. An attacker can exploit this problem in an IIS server that has not been patched by sending the following input to the server:
GET /default.ida?NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNnnnnnnnn%u9090%u6858%ucbd3%u7801% %u9090%u6858%ucbd3%u7801%%u9090%u6858%ucbd3%u7801%%u9090%u9090%u8190%u ooc3%u0003%u8b00%u531b%u53ff%u0078%u0000%u00=a FTTP/1.0
240 of more Ns (of any other character—this does not matter) overflow the buffer, at which point the remaining input spills over into memory where the commands—the portion of the previous input after the string of Ns (note, they are in Unicode format) will be executed. A similar vulnerability also exists in the Internet data query (idq) script mapping. Interestingly, these vulnerabilities are the ones exploited by the Code Red worm family
More sophisticated types of signature matching exist, however. For example, Snort, an IDS covered in Chapter 10, creates a tree structure of attack patterns and uses a search algorithm that results in only patterns relevant to the particular packets being matched in a particular branch of the tree being used in the matching process. This produces a far more efficient search process.
Evaluation of Signature Matching
Signature-based matching is not only simple, it is also intuitive. People who understand little about intrusion detection quickly understand that certain input patterns, if picked up by an IDS or IPS, indicate an attack has occurred. But few additional advantages of signature-based matching exist.
Some of the major limitations of signature-based matching include the following:
- Numerous variations of an attack often exist, each with its own signature. For example, in many versions of Washington University (wu) ftp, a SITE EXEC vulnerability exists in which an attacker can gain root access to an ftp server. The attacker can initiate a SITE EXEC attack by connecting to a wu-ftp server and entering the following:
quote site exec exec echo toor::0:0::/:/bin/sh >> /etc/passwd
- The previous character string constitutes a signature for one version of the
SITE EXEC attack, so having only this signature in a file or database would result in numerous missed attacks if other SITE EXEC attack methods were used. A hacker tool, ADMutate (see http://www.nwfusion.com/news/2002/0415idsevad.html), starts with a single buffer overflow exploit and creates a plethora of functionally equivalent exploits, every one with a unique signature.- Signature-based IDSs have gotten well behind the proverbial power curve given the variety and pace of discovery of new attacks. Adding a new signature to an IDS or IPS’s signature library before that system is capable of recognizing an attack pattern is necessary. Thus, signature-based IDSs and IPSs initially miss new types of attacks.
- Signature databases or flat files storing lists of signature tend to get cluttered with archaic signatures (so the vendors can “beat their chests,” claiming their products can detect more attacks than their competitors' products). This not only hurts performance (because the more signatures there are, the slower detection becomes), but also causes those who deploy IDSs and IPSs to become falsely optimistic about detection rates.
- Signature-based IDS and IPSs tend to generate unacceptably high false alarm rates. The reason is that some types of input patterns such as
vipw /etc/passwd.adjunct
can constitute attacks, but may sometimes also constitute legitimate usage (for example, by system administrators). Signatures are all-or-none in nature—in and of themselves, they reveal virtually nothing about the context of the input. Any time one of the predesignated signatures comes along, a signature-based IDS or IPS issues an alarm.
Rule Matching
We’ll next turn our attention to rule matching, another matching method.
How Rule Matching Works
Rule-based IDSs and IPSs are, as their name implies, based on rules. These types of IDSs hold considerable promise because they are generally based on combinations of possible indicators of attacks, aggregating them to see if a rule condition has been fulfilled.
Signatures themselves may constitute one possible indication. In some cases (but not usually), a signature that invariably indicates an attack may be the only indicator of an attack that is necessary for a rule-based IDS or IPS to issue an alert. In most cases, though, particular combinations of indicators are necessary. For example, an anonymous FTP connection attempt from an outside IP address may not cause the system to be suspicious at all. But, if the FTP connection attempt is within, say, 24 hours of a scan from the same IP, a rule-based IDS should become more suspicious. If the FTP connection attempt succeeds and someone goes to the /pub directory and starts entering cd .., cd .., cd .., a good rule-based IDS or IPS should go crazy. This is because what we have here is most likely a dot-dot attack (in which the intention is to get to the root directory itself) with the major antecedent conditions having been present. This example is simple, yet it is powerful. Real rule-based systems generally have much more sophisticated (and thus even more powerful) rules.
Evaluation of Rule Matching
The main advantages of rule matching are as follows:
- A relatively small set of rules can cover many exploits, exploits for which perhaps scores of signatures would be needed for signature matching.
- Rule matching has considerable robustness—minor variations in string patterns are also normally no problem in rule matching. Consider the previously covered IIS ida script-mapping buffer-overflow attack. A rule-based system might ignore the .ida? signature and, instead, focus on any input with large numbers of repeated characters, regardless of what the particular characters are.
The Pros and Cons of Protocol Analysis
Using rules based on protocol behavior has become increasingly popular (especially in IDSs) over the years and for good reason. Deviations from expected protocol behavior—each protocol is supposed to behave according to RFC specifications (although, as mentioned before, these specifications are not always as “air tight” as they should be)—is one of the most time-proven and reliable ways of detecting attacks, regardless of the particular signature involved. Many consecutive finger requests from a particular IP address are, for example, almost always an indication of an attack, as is a flood of SYN packets from a particular host. Excessively large packet fragments and improperly chunked data sent to a web server are other indications of anomalous protocol behavior. Most of the systems with the highest overall detection proficiency use a variety of protocol analysis methods. On the downside, protocol analysis can result in a substantially elevated false alarm rate if a network is not working properly. For example, a malfunctioning router may spray packets, causing protocol anomaly routines to go berserk.
- Rule matching is a good way to detect new, previously unobserved attacks (although no rule-based system is anywhere near perfect as far as this goes). New rules have to be added and existing ones must be updated, but not nearly at the rate that signature-based systems require.
The main limitations of rule matching include the following:
- Rules are better suited to detecting new variations of exploits than radically new types of exploits. Like signatures, new rules need to be added to IDSs and IPSs, although they generally need to be added much less often.
- In rule-based systems, packet data are generally stored in data structures, and then compared to representations of the rules. If hash tables are used to store the data, hash values are usually calculated for the portions of the packet that represent each event of potential interest. If the hash function uses XOR operations to combine one part of its input with another, and if a relatively weak hashing algorithm is used, it is possible to determine in what manner and when incoming packets are handled before hash table entries for them are created. Once this determination is made, it is possible to send floods of specially created packets to the rule-based IDS or IPS that will produce identical hash values as normal packets, creating hash table “collisions.” The CPU becomes massively overloaded trying to resolve these collisions, resulting in DoS or a substantial slowdown.
Profile Based Matching
Next we’ll look at profile-based matching methods.
How Profile-Based Matching Works
Information about users’ session characteristics is captured in system logs and process listings. Profiling routines extract information for each user, writing it to data structures that store it. Other routines build statistical norms based on measurable usage patterns. When a user action that deviates too much from the normal pattern, occurs the profiling system flags this event and passes necessary information on to output routines. For example, if a user normally logs in from 8:00 A.M. to 5:30 P.M. but, then, one day logs in at 2 A.M., a profile-based system is likely to flag this event.
Evaluation of Profile-Based Matching
Profile matching offers the following major advantages:
- Profile-based systems are the best way to detect insider attacks. Profiles are typically constructed on a user-by-user basis, making the IDS or IPS capable of detecting specific “eccentricities” in special users’ usage patterns. Conventional IDSs and IPSs, which do not focus on particular individuals and their actions, simply “miss the mark” when it comes to insider attacks. Profiling is the most effective way to identify perpetrators of insider attacks.
- Profile-based systems are well suited for discovering new kinds of attacks. These systems do not look at specific characteristics of attacks, but rather at deviations from normal patterns. No one but a few individuals (in all likelihood, a few members of the black hat community) may be aware of a signature for a new attack, making that attack impossible to detect using conventional methods, such as signature matching. But, if the attacker uses the new exploit to break into a user’s account, the usage characteristics of this account are likely to change radically, something a profile-based system is likely to pick up.
Some major downsides of profile-based intrusion detection include the following:
- Profile-based intrusion detection is based on a limited number of simplistic types of usage patterns, such as time of usage or the number of privileged commands entered. Accordingly, profile-based systems also tend to generate high false alarm rates.
- A clever trusted insider can make reasonable guesses concerning how much “deviance from normal” will be tolerated and cause his/her profile to become broader and broader over time, making the IDS or IPS miss deviant actions that occur later.
- An attacker who knows the basic usage patterns of a user can break into that user’s account, and then use compromised credentials to engage in a wide variety of unauthorized actions. Unless the attacker does something far from the ordinary (such as surf a hacking tools site), these actions are not likely to be discovered.
Other Matching Methods
Many other types of matching or, more properly, detection methods, too numerous to cover here, are also used. Tripwire-type tools compare previous and current cryptochecksum and hash values to detect tampering with files and directories. Another method uses Bayes’ theorem, which allows computation of the probability of one event given that another has occurred, providing a way of calculating the probability that a given host has been successfully attacked given certain indications of compromise.
Malicious Code Detection
Malicious code is so prevalent and so many different types of malicious code exist, antivirus software alone cannot detail with the totality of the problem. Accordingly, another important function of intrusion detection and intrusion prevention is detecting the presence of malicious code in systems. The next section discusses this function.
Types of Malicious Code
According to Edward Skoudis in Malware: Fight Malicious Code (Addison Wesley, 2003), major types of malicious code include the following:
- Viruses Self-replicating programs that infect files and normally need human intervention to spread
- Worms Self-replicating programs that spread over the network and can spread independently of humans
- Malicious mobile code Programs downloaded from remote hosts, usually (but not always) written in a language designed for interaction with web servers
- Backdoors Programs that circumvent security mechanisms (especially authentication mechanisms)
- Trojan horses Programs that have a hidden purpose; usually, they appear
to do something useful, but instead they perform some malicious function - User level rootkits Programs that replace or change programs run by system managers and users
- Kernel level rootkits Programs that modify the operating system itself without indication that this has occurred
- Combination malware Malicious code that crosses across category boundaries
How Malicious Code Can Be Detected
IDSs and IPSs generally detect the presence of malicious code in much the same manner as these systems detect attacks in general. This is how these systems can detect malicious code:
- Malicious code sent over the network is characterized by signatures such as those recognized by antivirus software. IDSs and IPSs can match network data with signatures, distinguishing strings of malicious code within executables, unless the traffic is encrypted.
- Rules based on port activation can be applied. If, for example, UDP port 27374 in a Windows system is active, a good chance exists that the deadly SubSeven Trojan horse program (that allows remote control by perpetrators) is running on that system.
- Worms often scan for other systems to infect. The presence of scans (such as TCP port 135 scans by Windows system infected by the MSBlaster worm and its many variants) can thus also be indications of malicious code infections for rule-based IDSs and IPSs.
- Tripwire-style tools can detect changes to system files and directories.
- Symptoms within systems themselves, as detected by host-based IDSs and IPSs, can indicate malicious code is present. Examples include the presence of certain files and changes to the Registry of Windows systems (particularly to the HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrent VersionRun key, in which values can be added to cause malicious code to start whenever a system boots).
Challenges
Although IDSs and IPSs can be useful in detecting malicious code, relying solely on these kinds of systems to do so is unwise. Instead, they should be viewed more as an additional barrier in the war against malicious code than anything else. Why? First and foremost, other types of detection software (at least antivirus software for Windows and Macintosh systems) is more directly geared to serving this kind of function. Antivirus vendors generally do better in writing malicious code detection routines in these systems in the first place. The situation with Unix, Linux, and other systems is quite different, however. In these cases, IDSs and IPSs should be considered one of a few first-line defenses against malicious code. This is because antivirus software for these systems is not as necessary as for Windows systems and it is not as freely available. This is not to imply that malware detection software in these systems is useless. The chkrootkit program, for example, is simple to use and quite effective in detecting the presence of rootkits on Unix and Linux systems. It can even detect when something in a system is not behaving correctly that might indicate the presence of a rootkit. Additionally, network encryption presents a huge obstacle to detection of malicious code on systems on which this code runs. Finally, symptoms of possible malicious code attacks often turn out to be nothing more than false alarms. Suppose, for example, an IDS or IPS detects that a host has received packets on UDP port 27374. This could possibly indicate the host is running the SubSeven Trojan horse, but this could also simply mean a network program has sent packets to this port. It may transmit packets to a different port next time and still another port the time after that. The behavior of many network applications with respect to ephemeral ports is, at best, weird.
The bottom line is this: IDSs and IPSs can help in numerous ways in the war against malicious code. Many of the indications of incidents jibe with indications of the presence of malicious code. In and of themselves, however, IDSs and IPSs are not likely to be sufficient
Output Routines
Once detection routines in an IDS or IPS have detected some kind of potentially adverse event, the system needs to do something that at a minimum alerts operators that something is wrong or, perhaps, to go farther by initiating evasive action that results in a machine no longer being subjected to attack. Normally, therefore, calls within detection routines activate output routines. Alerting via a pager or mobile phone is generally trivial to accomplish, usually through a single command such as the
rasdial <phone_number>
command in Windows systems. Additionally, most current IDSs and IPSs write events to a log that can easily be inspected. Evasive action is generally considerably more difficult to accomplish, however. The following types of evasive actions are currently often found in IDSs and IPSs:
- Output routines can dynamically kill established connections. If a connection appears to be hostile, there is no reason to allow it to continue. In this case, an RST packet can be sent to terminate a TCP connection. One important caveat exists, however: sending an RST packet may not work. Systems with low-performance hardware or that are overloaded may be unable to send the RST packet in time. Additionally, ICMP traffic presents a special challenge when it comes to terminating ICMP “sessions.” The best alternatives for stopping undesirable ICMP traffic are one of the following ICMP options: icmp_host (meaning to transmit an “ICMP host unreachable” message to the other host), icmp_net (resulting in transmitting an “icmp network unreachable” to the client), or icmp_port (causing an “ICMP port unreachable” to be sent to the client). Unfortunately, terminating UDP traffic from a hostile host is usually not feasible. The best alternative is to temporarily block the ports to which this traffic is sent.
- Systems that appear to have hostile intentions can be blocked (shunned) from further access to a network. Many IDSs and IPSs are capable of sending commands to firewalls and screening routers to block all packets from designated source IP addresses.
- A central host that detects attack patterns can recognize a new attack and its manifestations within a successfully attacked system. The central host can change a policy accordingly. It can, for example, forbid overflow input from going into the stack or heap. It can also prevent recursive file system deletion commands from being carried out, given that commands to do either are entered on a system, and then send the changed policy to other systems, keeping them from performing these potentially adverse actions.
A major limitation to taking evasive action (other than the fact that, with UDP traffic this is, for all practical purposes, impossible) is the action may not be appropriate. Only heaven knows the number of packets daily transmitted over the Internet that have spoofed source IP addresses. Blocking traffic from these apparent hostile addresses can block legitimate connections, causing all kinds of trouble. Additionally, evasive action by IPSs can readily result in DoS in systems. IPSs can prevent systems from processing commands and requests that may be necessary in certain operational contexts, but that are identical or similar to those that occur during identified attacks. Critics of intrusion prevention technology are in fact quick to point out that they are ideally suited to the purposes of insiders (and possibly also outsiders) intent on causing massive DoS attacks.
Defending IDS IPS
Most of the currently available IDSs and IPSs have little or no capability of monitoring their own integrity. This potentially is an extremely serious problem given the importance that intrusion detection and intrusion protection play in so many organizations. An attacker who wants to avoid being noticed can break into the host on which an IDS or IPS runs, and then corrupt the system, so it will not record the actions of the attacker (and also possibly anyone else!). Or, the attacker can send input that causes an IDS or IPS to process it improperly or that results in DoS. Countermeasures against these kinds of threats include the following:
- Filtering out any input that could cause the IDS/IPS to become dysfunctional. Stateful firewalling often best serves this purpose.
- Stopping further processing of input if some particular input could result in partial or full subversion of the IDS or IPS. This is an extreme measure given that intrusion detection and prevention functions are temporarily suspended while this option is in effect.
- Shunning apparently hostile IP addresses, as discussed previously.
- Building an internal watchdog function into the system. This function may determine whether the IDS/IPS is doing what it is supposed to do. If this function determines the system is not performing its functions normally, it sends an alert to the operator.
Summary
This chapter has covered the topic of IDS and IPS internals. These systems almost always process information they receive in a well-defined order, starting with packet capture, filtering, decoding, storage, fragment reassembly, and then stream reassembly. The packets are then passed on to detection routines that work on the basis of signatures, rules, profiles, and possibly even other kinds of logic. IDSs and IPSs can also detect the presence of malicious code, although antivirus software (if available for a particular operating system) is likely to be the more logical first line of defense against this kind of code. Detection routines can call output routines that perform a variety of actions, including alerting operations staff, resetting connections, shunning IP addresses that appear to be the source of attacks, and/or modifying intrusion prevention policy for systems. IDSs and IPSs are a likely target of attacks, so they need to have adequate defenses. Defensive measures include filtering out any input that could cause the IDS/IPS to become dysfunctional, terminating further processing of input if that input could cause partial or full subversion of the IDS or IPS, shunning ostensibly malicious IP addresses, and incorporating an internal watchdog function into the system.
Part I - Intrusion Detection: Primer
- Understanding Intrusion Detection
- Crash Course in the Internet Protocol Suite
- Unauthorized Activity I
- Unauthorized Activity II
- Tcpdump
Part II - Architecture
Part III - Implementation and Deployment
Part IV - Security and IDS Management
EAN: 2147483647
Pages: 163
