Unauthorized Activity II
Overview
In this chapter, we examine some of the ways in which application programs can be attacked via the network. We have already explored the types of abuses that occur at the network level, but here we focus on how legitimate (from a network level) traffic can nevertheless be used to abuse or compromise applications. The term application runs the gamut from simple services (such as Telnet) installed as a matter of course when the operating system is installed, through the more complex network applications such as web servers, up to the custom application level.
One would expect that custom applications would not be as vulnerable as “off-the-shelf” products for the simple reason that hackers are not likely to be able to examine the inner workings of them for flaws. However, applications are often built on top of underlying foundations, such as databases, which may have exploitable security problems.
Unfortunately, even standard applications suffer from security vulnerabilities, in part due to bad programming practices, lack of awareness of exploitability, and configuration or other issues. When security issues are discovered in applications, operating system software, or utilities, bulletins are issued by various organizations (CERT, CIAC, and so on), vendors, and security professionals to alert administrators of the issues. Responsible vendors rapidly correct or mitigate security problems when they are discovered.
Pros and Cons of Open Source
The movement toward open disclosure of software source code has made tremendous strides in recent years. Operating systems such as Linux and FreeBSD, and major applications that drive the Internet such as the Apache Web Server, Sendmail, and BIND (Berkeley Internet Name Domain) are completely open source, whereas other popular offerings such as Windows and Mac OS X are closed source. From a security standpoint, arguments can be made both ways about the security of open source versus closed source. In reality, whether or not the source is proprietary is secondary to other more important issues:
- Does the software design process embrace security as an important goal?
- Are the software designers, developers, and engineers trained and aware of the importance of security in the development process?
- Are the development tools also designed from a security perspective?
- Is the software sufficiently tested for security issues by competent testing personnel?
Systems designed with these criteria in mind are likely to have fewer security issues than those in which security is an afterthought. New security issues surface all the time, but except in extraordinary circumstances, they can generally be designed for or mitigated in the design process. Many software products do not live up to the maxim “Fail Gracefully” and contribute to security breaches by failing in a catastrophic fashion. Well-designed systems, on the other hand, have internal checks to detect “impossible” conditions and deal with them appropriately.
Most current systems, both open-source and proprietary, have grown organically from an insecure framework and thus have security “patched” in as an afterthought. This, of course, is not the preferred security model but is often necessary when original systems were designed in a much different world.
Types of Exploits
When we talk of application-level exploits, we are indicating those methods of taking control of, or denying, the usage to legitimate users of a service, process, or application which has a presence on the network, using normally crafted network packets. What we’ve seen in Chapter 3 are the sorts of misdeeds that a malicious party can perform by sending abnormal network traffic. In this chapter, we will examine those types of exploits in which the packets are legitimate in form and/or quantity, but where the contents of the traffic interact with the network application to provide unexpected access to the application by a malicious party, or denial of access to legitimate users.
Memory Buffer Overflow
The most common types of remote security breaches are due to memory buffers of various sorts being overflowed. A buffer is a contiguously allocated chunk of memory, in most cases on the computer’s stack or in a memory heap. As this buffer has a defined size, if the bounds of this buffer are exceeded, other memory, not part of the buffer, will be overwritten. Hackers have been extremely clever in exploiting this flaw if possible. When a buffer overflow attack is successful, the execution path of the program is hijacked by the attacker, who therefore inherits the context of the exploited program, including access privileges, open files, and network connections. Thus, when a program running as root is exploited, the hacker code itself also runs as root, which enables complete control over the system. Often, the hacker code will execute an interactive command interpreter (shell) from which the hacker can then continue his compromise of the system.
A trivial C program that contains a buffer overflow will begin our exploration of this topic:
main() {
char buff[10];
strcpy(buff, "This string overflows the buffer"};
}
This C program allocates 10 bytes on the stack for a buffer. It then copies a string whose size exceeds these 10 bytes into the buffer, thus overflowing the allocated size of the buffer. In C, each string is terminated by a zero byte, so the buffer in question can hold only nine characters and the zero byte.
This example is contrived, but programmers often make assumptions about the maximum length of input that anyone should ever make into a field. Hackers, however, are not constrained by what “should” be entered into a field, but by what “can” actually be entered. Let’s examine, therefore, the effects of overflowing a buffer.
Memory Address Space
The memory required to run a program is called the address space. In modern operating systems, it is generally divided into the following memory sections (refer to Figure 4-1):
- Text The binary code loaded from the executable, which is marked read-only. In many architectures, self-modifying code is supported by dynamically creating machine code on the stack or heap and branching to it.
- Initialized data A data area with data copied from the executable. This will contain variables whose values are initialized with a value but are subject to modification, and thus must be marked read-write.
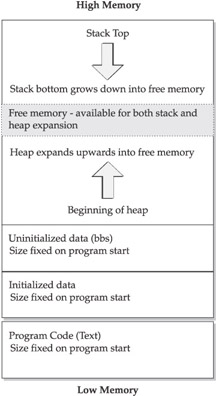
Figure 4-1: Typical program memory map - bss An area for uninitialized data, although in practice this area is often initialized to binary zero. The term bss is an artifact from a long-obsolete operating system.
- Heap This memory area is used for dynamically allocated variables whose lifespan must exist beyond the function that created it. This area can also expand or contract based on program memory demands, but it is structured different from the stack structure described next, since memory is allocated as needed without regard to the state of the stack.
- Stack The stack area is often likened to a stack of plates at a cafeteria, where the last plate pushed onto the stack is the first one taken out. In modern computer systems, the stack is allocated from the top of memory and grows downward, so that the data at the top of the stack has a lower memory address than the data at the bottom. The stack is used for storage of return addresses, as well as local variables for functions. The stack grows and shrinks in response to program memory demands.
Note Local variables are used by a function as it is running, but they are not needed once the function returns. Thus, the memory used by these local variables are available for other uses when they are no longer needed.
Most buffer overflows involve the stack, as the structure is simpler than the heap. Although our discussion focuses on the x86 family of processors, the concepts are similar in other processor families. A stack pointer (SP) points to the current “top” of the stack region. The term top is somewhat of a misnomer, since the stack region grows downward from the top of memory, and as it expands the SP decreases in value. When a function (or subroutine) is called, the parameters are pushed on the stack, along with the return address and a frame pointer (FP). Local variables (such as buff in the preceding code) are allocated on the stack below, as shown in Figure 4-2.
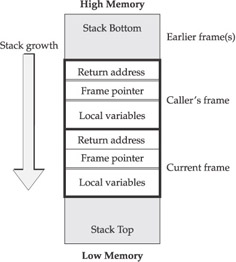
Figure 4-2: Typical stack layout
When a stack-allocated buffer is overflowed by excessive data, as in our example, it will overwrite data higher in memory, on the stack. This data, as described previously, includes the other local variables, the frame pointer, the return address, and data for other functions higher on the stack.
Classic Buffer Overflow
The classic buffer overflow exploit occurs when a buffer on the stack is overflowed, generally overwriting the return address of the function with a value supplied by the attacker. Additionally, the data entered into the stack will often be a machine language program that gains access to the system via this overflow, although, as we’ll see in the section “Return to libc Buffer Overflows” later in the chapter, the data need only consist of a return address if useful code already exists in the program or included libraries. The return address is set to an address within this machine language program (often called shell code, as the object often is to gain access to an interactive shell). When the exploited function returns from its normal execution path, instead of returning whence it came, it returns to the shell code.
When overflowing a buffer, it is often impossible to enter certain values in the buffer, which may cause greater, although not insurmountable, problems for the attacker. For instance, when overflowing an input buffer by entering data into it, it will not be possible to enter either a binary 0 or the end-of-line character (newline), as either of these characters would terminate the input. Some buffer overflows will have even more restricted capabilities, depending on the characteristics of the program involved. Although the point has been hotly debated, some believe that open-source software can be examined more closely by hackers to determine a precise vector of compromise, and it thus may be more vulnerable. Although this may be true, it is often also argued that open-source software benefits by having many (mostly nonmalicious) eyes examining, studying, and improving it.
Because some byte codes may not be entered into the shell code that is executed, hackers oftentimes need to perform various convolutions to generate those values, if needed. Our discussion here will not drift into specific hardware architectures, but methods are available for synthesizing these values programmatically without resorting to the forbidden values themselves. For instance, subtracting a hardware register from itself will generate a binary 0 in the register, without necessarily actually inserting a numeric zero into the shell code.
This classic type of buffer overflow exploit powered the Morris Internet worm of 1988, which caused large-scale disruption of the infant Internet of the time—we will discuss this in the section entitled “A Brief History of Worms”.
A Certain Amount of Slop in Shell Codes
One technique that hackers typically engage in when generating buffer overflow shell codes is to allow for some slop in the return address. Sometimes the buffer being overflowed will not be in precisely the same location on the stack, due to intervening variables taking a different amount of space. Possibly, too, the shell code may target several variants of the vulnerable software and thus needs a method to adapt. If a hacker had unlimited time, he could try numerous combinations of addresses to enter into the stack. However, if the return address doesn't point to some genuine executable code, but rather some random data, the chances are great that the attack will simply crash the program—again, a possible attack, but not likely to be of interest to more ambitious hackers.
If the return address could possibly vary, how could the attacker hope to accommodate that? It turns out that this problem is often overcome by the use of what has been term as a NOOP “sled.” Every processor instruction set contains at least one instruction that is in effect a null operation that makes no change to the state of the program, other than consuming a memory location. Most instruction sets will actually have a number of instructions that will operate as NOOPs. For instance, a binary OR operation of a register with itself will not change its value (although it may change processor flags) and thus likely also functions (for hacker purposes) as a NOOP.
Suppose the hacker shell code is preceded by 512 bytes of NOOPs. The return address merely needs to fall anywhere within this 512-byte window for the shell code to be activated. The processor will simply step through the NOOPs that it encounters until it reaches the actual shell code. Note, of course, that the NOOPs also need to follow the same rules about forbidden byte codes as the actual shell code.
In the x86 instruction set used on commodity PCs, the defined instruction for a NOOP is a hex code 0x90, although about 55 different hex codes could function in this capacity. In fact, depending on the actual shell code, additional instructions could also be used. For instance, if the shell code begins by storing a value in the AX register, any preceding instruction that may have changed the AX register is of no adverse consequence to the shell code. We will explore this issue further later in the chapter as we examine one of the more recent developments in this area, polymorphic shell codes.
Heap-Based Buffer Overflows
Another dynamically allocated memory region is the heap, which generally grows from the bottom of memory toward the top. This region is generally more difficult to exploit than the stack, as return addresses aren’t stored in the heap, which make seizing control of the execution path of a vulnerable program more difficult. However, overflowing the heap can easily cause denial of service by causing memory allocation errors. The Code Red Worm that attacked Microsoft web servers in 2001 used a heap overflow technique to perform the compromise.
Return to libc Buffer Overflows
Instead of injecting shell code directly into a program, suppose that an attacker took advantage of code already known to be on the system. Unlike the standard stack-based or heap-based buffer overflows, this overflow modifies the return address to return to one of the functions in the standard library libc, which contains several functions to execute arbitrary commands. For any given version of the libc library, the addresses of these functions can be easily predetermined by an attacker. Additionally, traditional shell code is not needed, rather the overflowed variable is padded with extraneous data, and multiple copies of the return address, which is set to a known function in libc. This technique is typically used when for technical reasons the classic shell code injection techniques cannot be used, or when constraints exist on the size of the shell code that can be inserted.
Format String Overflows
One particular form of exploit that has achieved a level of popularity is the exploitation of a format string error. In the C programming language, a template string is used to format output. This template string can contain instructions to access variables on the stack that require formatting to output. A typical programming flaw that allows exploitation is that lazy programmers simply pass unchecked input directly as the format string. By injecting carefully crafted inputs, the format string forces the exploited program to access unintended data on the stack, thus potentially clobbering stack data that, although not technically a buffer overflow, has the same potential for abuse.
Recent Applications and Operating systems vulnerable to the format string overflow vulnerability include
- CERT Advisory CA-2002-10 Format String Vulnerability in rpc.rwalld
- CERT Advisory CA-2002-12: Format String Vulnerability in ISC DHCPD
- CERT Vulnerability Note VU#700575: Buffer overflows in Microsoft SQL Server 7.0 and SQL Server 2000
- CERT-intexxia 12/20/2001: pfinger Format String Vulnerability
- SuSE-SA:2002:037: 'heartbeat' Remote format string
- Securiteam.com 10/12/2000:PHP remote format string overflow
Polymorphic Shell Code
A continual arms race exists between those who protect systems from compromise and those who hope to harm them. Technology now exists to create “polymorphic” shell code, which actually mutates the code that is used to compromise systems. In 2001, an online tool (ADMutate) was released that (among other things) substitutes the NOOP codes generated in shell code with functional equivalents. As we saw earlier, approximately 55 byte codes are such equivalents. Thus, by changing NOOPs to random byte codes selected from this list, ADMutate attempts to evade IDSs that look for simple patterns. ADMutate uses an application programming interface (API) and library that can be included by worm or virus authors to mutate the shell code, so that each attack uses a differing byte sequence.
Defense Against Buffer Overflow Attacks
Ultimately, the responsibility for systems being vulnerable to buffer overflow attacks rests with the vendors of vulnerable software. In the case of open-source software, especially those packages that are widely used, cooperative efforts arise in the open-source community to correct known vulnerabilities quickly. Generally, closed-source vendors will also be fairly responsive as well, as security issues have been raised to popular consciousness by high-profile exploits.
Although primary responsibility for providing security patches lies with the vendor, prudent system administrators can make some defensive measures to reduce or remove this exposure. Since it is unknown (by definition) what service may next be discovered to be vulnerable, it is wise to treat any network accessible service as potentially vulnerable. One mitigation that helps shield systems from exploitation is to restrict access to services only to authorized users by employing either network or host-level firewalling techniques.
In the case of publicly accessible services, such as web servers, anonymous FTP servers, or remote login services that must remain open to a significant portion of the Internet, the general recommendation is to stay on top of security problems for these products and patch when vulnerabilities are disclosed. Often, too, more secure alternatives to popular products do not suffer from the same reputation for security problems. For instance, a popular web server in the PC arena has been plagued with numerous security problems in the past. At some point, an honest appraisal of the total cost of ownership (TCO) might convince some enterprises to replace this product with a product whose security exposure is less problematic.
Systems can often be configured to harden themselves against buffer overflow attacks. Some architectures (such as Sparc) have the capability to make the stack “non-executable,” so that shell code residing on the stack cannot be executed. An attempt to return into the stack on such systems will cause the program to abort, rather than be exploited. This can still pose a problem, albeit generally of less concern, as this changes a system compromise to a denial of service (DoS) attack. It is often possible to configure services to restart automatically if they exit, so this may prove to be acceptable.
Another recent development that has been implemented in the PaX Linux kernel patch and other systems is the idea of randomization of memory and stack allocation. As we have seen, shell codes can have some slop but need some idea of what to insert as a return address to wrest control away from the program. Absent some form of address randomization, these addresses are highly predictable, which allows easy exploitation of buffer overflows. With this patch, the stack is allocated at a random address that is selected when the program begins running. Along with the stack, this patch also randomizes the heap, shared libraries (such as libc), and each executable program executed in turn. As long as the randomization scheme is sufficiently strong, exploiting even a well-known vulnerability is unlikely to be successful. Even if an exploit is successful, the same attack will fail the next time due to the differing addressing. More information on these and other techniques for host protection are available at these links:
- http://sourceforge.net/projects/stjude
- http://people.redhat.com/mingo/exec-shield/ANNOUNCE-exec-shield
- http://www.grsecurity.net
Intrusion-detection system (IDS) defensive measures against polymorphic shell codes is proceeding. Current detection mechanisms are CPU intensive, as they employ regular expression matching on real-time data streams. No doubt that as more research takes place, IDS systems will be more capable of identifying these threats.
Commonly Exploited Programs and Protocols
Although the range of vulnerabilities is wide and rapidly expanding (Bugtraq lists newly-discovered exploits on a regular basis), there are applications and protocols which are as familiar as the “hit-parade” for the number of network exploitable vulnerabilities that they have historically exhibited. Problems may occur in programs that were designed during the early days of the Internet, before security became a significant issue; other problems are due to flaws in design or implementation. The following sections examine commonly exploited issues. (Space does not permit a full discussion of the myriad security issues extant on the Internet today.)
Cleartext Communications
Many protocols developed in the infancy of the Internet are still in use today. Those days, of course, were mainly concerned with getting the functionality of the infrastructure in place, as opposed to significant concerns about security. Some IP options did mark packets with security levels, but no attempt was made to embed encryption into the packet contents. This led to the development of cleartext protocols, of which the most widely used have been Telnet, Rlogin, and FTP.
While we will discuss other FTP security concerns in more detail later, all of these cleartext protocols suffer from the glaring weakness of transparency. Not only is the authentication step visible to anyone who is capturing packets on the wire, but the entire session is also available for inspection. In the early days, too, most Ethernet networks used shared media, where all packets were visible to anyone on the network. Thus, one compromised system anywhere on a network could be used to capture traffic from any connected system. In these days of switched networks, this problem isn’t as severe, although, as we’ve seen in Chapter 3, it may be possible to subvert switches to allow sniffing of unintended packets. However, when a cleartext session is established across router boundaries, or across the Internet, the traffic is vulnerable to sniffing at multiple locations.
For these and other reasons, the use of these cleartext protocols should generally be restricted to internal routing at an enterprise. Most enterprises choose to filter the ports associated with these protocols from inbound connections. As an alternative, IDS systems can monitor and flag these connections and examine them for malicious content. Many systems with embedded networking stacks, such as printers, conferencing equipment, and so on, allow configuration only via these cleartext protocols. In such cases, it is important to protect the system as much as possible by the selection of a strong password and strong access controls to the system. It is also important to change these passwords frequently, ideally from a nonremote location. Cleartext communication mechanisms with strong, one-time mechanisms (use of Kerberos or one-time passwords) can improve protection, as the password used for authentication, even if sniffed, cannot be easily reused by a hacker for later access.
Encrypted Communications
In contrast to the doom and gloom, the good news is that encryption now has taken an important place in Internet security. From encrypted web sites for e-commerce or other privacy-sensitive applications, and encrypted replacements for cleartext communications, to end-to-end Virtual Private Networks (VPNs), the future looks brighter for encrypted communications. However, such communications have their own security concerns. As we will delve into more closely when we discuss SSH, the Secure Shell, the “transparency” concern we mentioned earlier has advantages for IDS monitoring, in that session content can be monitored for attack signatures. In an encrypted connection, the IDS is essentially blind to traffic contents (unless it has a decoding module and access to decrypting keys).
VPN technology allows for the encrypted transfer of all traffic between two endpoints. Each individual connection is not itself specially encrypted; rather, the tunnel between the two sides is encrypted. Traffic enters the VPN tunnel unencrypted, is encrypted and transported securely over the Internet to the other end, and is then decrypted and transported to its destination. Although exciting, this is not a panacea for remote access inside an enterprise, since, in effect, the security perimeter is extended to include the VPN, which could be a CEO’s virus-infested laptop in a hotel room. Thus, at the point of decryption, it is often recommended that an IDS monitor the (now decrypted) traffic for malicious content.
FTP
The File Transfer Protocol (FTP), defined in RFC 959, is used for unencrypted data transfer between systems, and authenticates users via a cleartext account and password authentication mechanism, similar to that used by Telnet. The same concerns about exposure of account names and passwords on cleartext passwords that we examined earlier are expected in the case of FTP. More modern authentication mechanisms also exist but have enjoyed limited success. FTP is unique among major protocols in that the control and data communication channels do not share the same port. In fact, it is not necessary for the two channels even to refer to the same system. An instruction can be sent down the command channel from the FTP client to the FTP server, initiating a data transfer to a third system. Although uncommon, this behavior is sometimes seen in normal traffic.
Generally, however, FTP transfers involving third parties are FTP bounce attacks. FTP allows the client to specify the IP address and TCP port on which the data transfer will occur. Under normal conditions, the IP address will be that of the client and the TCP port will be an ephemeral port. On the other hand, a malicious FTP client can use the PORT command to specify a system and service to attack, and then request that a file (already in place on the FTP server, perhaps uploaded previously by the hacker) be transferred to the victim. This file could contain commands relevant to the service being attacked, such as Simple Simple Mail Transfer Protocol (SMTP), Telnet, and so on. From the perspective of the attacked system, it would appear that the FTP server is attacking the victim. In actuality, though, the malicious FTP client is “bouncing” the attack off of the FTP server, hence the name of the attack.
Most current FTP servers avoid this problem either by refusing to accept PORT commands that do not refer to the actual FTP client or by disallowing PORT commands that refer to low ports (less than 1024), where most important services live. Note, as well, that the FTP bounce attack generally requires that the attacker be able to upload a file to the FTP server and then download it later to the victim system. Proper use of file permissions (that is, not allowing an upload directory to be readable as well as writable) will prevent this behavior. However, some services may be vulnerable to crashing when confronted with random binary data as well.
File permissions are also important for preventing improper use of system resources, particularly if the FTP server allows anonymous access. Hackers, file-sharers, and others have been known to use improperly configured FTP servers for storage and transfer of data. If an anonymous FTP directory intended for file upload also allows files to be downloaded, the potential for this type of abuse exists. Often, of course, system administrators may want to set up an area for files to be downloaded and uploaded without requiring authentication. To prevent abuse, it is recommended that two areas be set up—an upload area that is only writable, and a download area that is marked read-only. After reviewing files uploaded to the FTP server, the system administrator can move them to the download section for others to access.
An optional FTP command SITE EXEC, allows clients to execute commands on the FTP server. Clearly, if this feature is implemented on a server, the range of commands that can be executed needs to be configured with extreme care to avoid compromise of systems. Many IDSs are configured to trigger an alarm on SITE EXEC on FTP connections.
SSH
SSH, the Secure Shell, was developed as an encrypted replacement for cleartext protocols such as Telnet, Rlogin, and FTP. It provides for authentication and data transfer over an encrypted channel, and it thus provides an increased level of security for interactive data transfers. As such, it invaluable for remote system administration (especially those connections requiring privileged access) and transfer of sensitive data. However, the use of encryption comes at a cost: with cleartext protocols, evidence of intrusion can be determined by inspection of packet contents, while the contents of an encrypted connection are not available for inspection unless the IDS has access to the decryption keys.
Numerous security issues have occurred with various implementations of the SSH protocols as well as with the libraries (OpenSSL) that support encryption. As compromise is difficult or impossible to detect, due the encrypted nature of the connections; it is imperative that these services be patched whenever new vulnerabilities are announced. In addition, it is important that users not be lulled into a false sense of security by the use of the “encrypted connection” buzzword. Hackers have been known to install “keyboard sniffer” programs on compromised systems, which capture accounts and passwords for other systems directly from the keyboard of the compromised box, when the unsuspecting user logs into it. In this case, the encryption fails to assist, as the accounts/passwords are captured before they are encrypted. The encryption may actually detract from the detection of this compromise, since the IDS has no way of examining the connection for evidence of hacking activities.
SSH, if not already on a system, is sometimes installed by hackers, possibly on a nonstandard port for precisely these reasons. Hackers can further their penetration essentially undetected under these circumstances, and reliance must be made on other detection mechanisms. Occasionally, the hacker may slip up and download tools via an unencrypted channel, or host-level detection mechanisms may provide some indication that the system in question has been compromised. In Chapter 5, we will discuss detection of SSH connections on these nonstandard ports, which provides evidence of possible compromise.
Web Services
The Hypertext Transfer Protocol (HTTP), in its initial incarnation developed in 1990, was small and somewhat inefficient, as each graphic required a separate connection to the web server. Due to the low bandwidth of the day, such inefficiency was tolerable. When dynamic pages became more prevalent, though, both the potential for abuse and the functionality of these web pages dramatically increased.
The common gateway interface (CGI) defined an early, and still quite commonly used method for the web server to interact with external programs that can vary their output based on the input they receive from the client browser. For security and performance reasons, many web servers include add-ons that will run CGIs in the web server itself. In general, this trend has proven to enhance security by disallowing dangerous actions (such as access outside of specified directories) within the framework of the web server itself, rather than relying on the expertise of the CGI author to provide these security features. On the browser side, both industry-standard and vendor-specific mechanisms exist to execute code on the browser with varying types of security controls.
The security considerations that exist are basically of two sorts (in addition to the network level risks we’ve explored earlier): web server bugs or misconfiguration that allow unauthorized remote attackers to
- Download data not intended for them
- Execute commands on the server, or break out of the constraints of the commands allowed
- Gain information on the configuration of the host or the software patch level, which will allow them to attack the web server
- Launch DoS attacks, rendering the system temporarily unavailable
The second type, on the browser side, includes the following:
- Active content downloaded from a malicious web page that damages the user’s system, or damages confidentiality of user’s data
- Misuse of personal data provided by the user
- Eavesdropping of confidential information
SSL encryption is often used for web traffic that requires confidentiality. This does indeed provide protection against eavesdropping. However, as always, the security of such transactions are only as strong as the weakest link. Unless both browser and server sides are secured adequately, such information is still vulnerable to interception and misuse. It is important to keep in mind that the data is encrypted only during transit over the network, and is decrypted upon reaching its destination. Thus, the security of the encrypted data also, as always, is subject to the “weakest-link” principle, and attention must be given to host-level security of the server and the client.
In the following sections we will examine web security from the standpoints of both the server and the client.
Web Server Security
The two most popular web servers are Microsoft Internet Information Services (IIS) and the open-source Apache Web Server. Although many other servers exist, due to their popularity, these full-featured offerings dominate the web server landscape. However, as they include many components that some web pages may not need, and that may have security implications, prudent administrators will examine the feature sets of possible web servers and select a product based on the features that are needed. Unless esoteric web pages are needed, other web servers such as thttpd (available at http://www.acme .com/software/thttpd/) may be more appropriate.
Many optional features are also provided by modern web servers. These features allow increased convenience and functionality at the cost of increased security risk. In many cases, these additional features are not necessary, and should be turned off.
Directory Listing in the Absence of index.html
Unless a good reason exists for presenting a directory listing, this should be disabled, as it may reveal information of value to an attacker, such as misconfigured files or directories, source code to CGI scripts, log files, and other information. If an attacker can guess the name of a file, he may be able to download it anyway, but by making it more difficult, we can often deter attackers, who may seek more fruitful targets.
Symbolic Links
Following symbolic links can provide attackers with access to sensitive parts of the file system. This feature should be turned off. If it is desired to extend the directory tree, most modern servers allow this via an entry in the configuration file.
Server-Side Includes (SSIs)
SSIs are used to allow access to real-time data from the server by the inclusion of special commands in the web page. Some are relatively innocuous, such as displaying the current time, but others such as the “exec” server-side include may allow execution of arbitrary commands on the web server. In fact, in these days of plug-in CGI scripts and client-side software, the value of SSIs has been reduced to historical interest. Most web servers have no need to enable this obsolete and insecure feature.
Excessive Privileges
To bind a listening socket on TCP port 80 (the default web port) or 443 (the default encrypted web port) requires administrative-level privileges on most systems. Unless the web server restricts the directories that are publicly accessible, other unintended directories may also be available to web clients. For this reason, many web servers’ privileges are dropped to a lower, less dangerous level, after binding to these ports.
Directory Traversal
This is seen in more contexts than web servers but is a common technique used by hackers to access files outside the desired directory structure. In this type of attack, an attacker will construct a request for a filename with a format similar to ../../../etc/passwd. The .. directory is a shorthand for the parent (or directory higher up). This construct goes up the directory tree, and then it goes down to the desired file to access it. Most current web servers reject requests with this sort of structure, as there is little if any legitimate use for this sort of access. However, Unicode encoding of this type of access may slip past unpatched servers. Most IDS systems will trigger alerts on directory traversal attacks.
Unicode
Unicode encoding allows for internationalization of web addresses, by encoding a 16-bit superset of ASCII standard web addresses, which are encoded in ASCII. It also allows for encoding of otherwise inexpressible characters, such as spaces, in web addresses. Unfortunately, some unpatched servers did not treat the same character in the same way, when expressed in Unicode form, as when it is expressed as a normal ASCII character. The / character, for example, used to separate directory components can be expressed in Unicode as %c0%af. Unfortunately, due to this bug, this allowed for successful exploitation of the directory traversal issue. Most IDSs canonicalize (convert to a standard form) Unicode data, so that it can be analyzed consistently. This is especially important, since Unicode provides multiple methods of expressing the same character.
CGI Security
One major source of web server compromise is the exploitation of vulnerable CGI programs. Quite a few canned CGI applications (many of them open source) exist for such diverse applications such as web guestbooks, bulletin board systems, feedback forms, groupware, and many e-commerce applications. Unfortunately, many of these applications are not created with adequate attention to security matters for network enabled applications that must deal with untrusted input. This is a crucial security matter, as web-based applications must be prepared to accept input of any sort and any length, if they expect to be robust enough to survive in the Wild Web atmosphere of the Internet. In general, it is best to check for historical vulnerabilities before using a pre-made CGI package.
Some security concerns with CGI applications include the following:
Unchecked Input Causing Buffer Overflow or DoS
We’ve dealt with this at length earlier in the chapter. If a program allows a static buffer, and the hacker enters more data than the buffer has allocated, a buffer overflow occurs, potentially leading to a compromise of the system.
Command Injection
Many CGI functions build commands to be executed via a shell command. Sometimes, the full pathname to the command is not specified, thus allowing for the possibility that an unintended program of the same name may be executed in the context of the CGI program. Also, input containing shell metacharacters may cause unintended commands to be executed, and thus should be scanned for the standard shell metacharacters. See the man pages for your favorite shell for more information on metacharacters.
An Example of CGI Command Injection
Many web sites exist which allow “ping”ing of another site on the internet via a web browser. One such site recently implemented this functionality via a CGI, which tacked unchecked user input after the ping command, then executed the result. When run against an unknown site, the following was returned:
/usr/sbin/ping: unknown host noonehome.nothere
By appending a semicolon, and another command (in this case the “id” command) in the window for specifying the host to ping, the other (unintended) command was also run:
Pinging noonehome.nothere;id; from host.fictionalisp.net uid=60001(nobody) gid=60001(nobody)
Obviously, something more destructive could also have been run. The problem here is that unchecked user input is passed from the CGI script directly to the command line. A simple command which filters out dangerous characters would have alleviated this problem. For example, the following Perl fragment will drop any input characters that are not alphanumeric, dashes, underscores, or periods:
$user_input =~ s/[^A-Za-z0-9_-.]//g;
As this web page was designed to simply ping remote sites, the character set described is adequate. Depending on the application, the valid characters that could be input to it would vary. The important point to remember is that only input that is valid for the application should be allowed.
Directory Traversal
If precautions are not taken with user supplied filenames, the CGI function may be tricked into accessing a file outside the expected file structure, as discussed earlier.
SQL Injection
This is a case of command injection that deserves special attention. Many e-commerce or other database applications that take input via a web form construct a SQL command from this input for query of a database. It is possible, with malformed unchecked input, to construct a valid SQL command that is significantly different from the desired command, and execute queries or other SQL commands that are unintended.
An Example of SQL Injection
Often, a secure web application will have a login page that allows access to the application. On this page, an account and password is provided by the user before access is granted.
In this scenario, the web designer has chosen to build a dynamic SQL statement which queries a database against the provided account and password. The following code provides an example of building the query:
System.Text.StringBuilder AccountInquiry = new System.Text.StringBuilder(
"SELECT * from UserDB WHERE account = '")
.Append(txtAccount.Text).Append("' AND passwd='")
.Append(txtPassword.Text).Append("'");
Here, the account and password are used to build the query without any sanity checking. A malicious user who desires to gain access to the system and who knows a valid account could enter the following into the password field:
“' or ‘0'='0'”
This input will cause the code to create the following (valid, but unintended) SQL query:
SELECT * from UserDB WHERE account='validuser' AND passwd = '' or '0'='0'
This command, when run against the database, could incorrectly grant access, as the ‘0'='0' portion of the query would cause the database entry for the account validuser to be returned, as if the correct password was entered.
As we saw when examining command injection, it is important to check untrusted input before using it to construct database queries. In particular, the use of quotes and hyphens should (unless necessary) be disallowed in input. We have just seen how quotes can be abused. Hyphens can be used in SQL queries to indicate comments, and allow an attacker to comment out part of a query and thus bypass access controls.
Excessive Privileges
CGIs often run in the context of the web server and thus may inherit the web server’s privileges. Even if the application is considered secure, it is always important to take advantage of any mechanisms that help restrict access only to those resources that the applications need. Multiple application wrappers exist (cgiwrap, sbox, and so on) that enforce that CGI scripts be run as unprivileged users.
Browser Security
Client-side code (applets) has also been developed and become standard in browsers, beginning with relatively humble beginnings such as Java and JavaScript, up to the complex (and insecure) framework of ActiveX. Most of these client-side programs attempt to restrict the actions of a possible malicious (or simply buggy) web site by creating a “sandbox” where all actions of the untrusted applet are confined. Theoretically, this sandbox prevents the applet from making file, configuration, or other security-sensitive changes to the client system. In actuality, bugs in sandbox implementations and user-overrides (where the user is asked to override the sandbox controls, and accept the risk that the applet is not malicious or buggy) reduce the sandboxes’ effectiveness. Vulnerabilities in both Java and JavaScript allow for the creation of a malicious applet that can bypass applet sandbox restrictions.
ActiveX takes a different approach to security and places no restrictions on what an ActiveX control (the equivalent of a Java applet) can do. The security of ActiveX is achieved through the trust-relationship that the user has with the vendor of the ActiveX control, which can be digitally signed by the vendor, who certifies that the software is virus and malicious content free. This certification ensures that the ActiveX control cannot be manipulated by a malicious third party, but it does not ensure that the control will be well-behaved.
A fully signed and certified ActiveX control called Exploder was developed by Fred McLain to prove this point. Exploder (whose certificate has since been revoked) caused Windows systems to shut down when run. It is available for inspection at http://www .halcyon.com/mclain/ActiveX. Although the certificate has been revoked, users can still choose to activate this control.
Uneducated users often download and install such software without a clear understanding of the risks that they are taking. Putting the onus to determine the security risks of installing unknown software on nave users poses a severe security risk, one that is likely to increase with time. The emergence of a control that performs a subtle or stealthy action of transmitting confidential data to its creator, in addition to performing some legitimate action, can be expected in the next few years.
SNMP
The Simple Network Management Protocol, developed in 1988, is now the standard for network management. SNMP has had the derisive acronym "Security Not My Problem" due its unencrypted nature and lack of attention to security issues. Some of the most egregious SNMP security issues have been addressed in SNMP v3, however. Nearly all network hardware that supports remote management includes an SNMP agent for this purpose. The SNMP system is partitioned into two elements: management console(s), and multiple agents deployed on the managed network hardware (bridges, routers, hubs, firewalls, servers, and so on). Each managed device contains multiple managed objects, which may consist of hardware, software, or network performance statistics, configuration parameters, and so on These objects are arranged in a distributed virtual database, called a Management Information Base, or MIB. SNMP is the glue that allows management consoles and agents to communicate for the purposes of monitoring and modifying the objects in this database.
An SNMP community string is used to define the relationship among a management console and the agents, essentially a password to control access. The default access level is read-only, which allows inspection but not modification of data/configuration on the agent device. By default, most network devices come with a default read-only community string of public and a read/write community string of private. A surprising number of network devices are not reconfigured from these strings, which presents a severe vulnerability to the entire network to which they are connected.
Armed with knowledge of the read-only community string, a hacker can walk through the entire MIB of an enterprise by the use of the one-liner:
snmpwalk [-d] [-p port] -v 1 host community [variable_name]
where host is the name of a starting place to start the walk, and community is the community string. By utilizing an SNMP Get Next operation, this command will walk through the entire accessible MIB database and display configuration information highly useful for penetrating a network.
With knowledge of the read/write community string, an attacker can reconfigure at will the network configuration. It is critically important to change the community strings from their defaults and to protect these strings as appropriate.
SNMP has had several publicized vulnerabilities, so, as usual for important services, it is important to apply the appropriate patches. Generally, SNMP traffic shouldn’t be allowed to traverse an organizational firewall, as outsiders have no need to access this important service. Blocking the following ports (TCP and UDP) at the border are recommended: 161, 162, 199, and 391.
Viruses and Worms
Everyone who has an e-mail account or Internet presence has been touched in some manner by the proliferation of viruses. (Note that in distinction to biological virii, generally the plural of a computer virus is viruses.) A virus, in the computer sense, is a piece of program code designed to replicate, or make copies of. itself, in an analogous manner to biological reproduction. Strictly speaking, it is not necessary that the virus do any damage, but its unwelcome nature makes eradication important. Recently, there has evolved a somewhat gray area between worms and viruses, but the following is generally true:
- If the malicious code automatically detects and spreads to another vulnerable system without human intervention, it is a worm.
- If the malicious code is transported to another system, but requires human intervention (such as opening an e-mail attachment) to activate it, it is considered a virus.
The key distinction is whether the malicious code requires some action to activate it, or whether it immediately begins running. Some viruses/worms straddle this line, as they incorporate several different infection mechanisms. For instance, the recent Nimda worm has several infection vectors:
- A viral infection mechanism of searching for and e-mailing itself to e-mail addresses found on the infected system
- A worm-like infection mechanism of scanning for unprotected network shares and copying itself there
- A worm infection mechanism of scanning for and infecting vulnerable IIS servers
- A viral mechanism of infecting both local and network accessible files on a compromised system; it also creates unprotected network shares for anyone
on the Internet to access
Recent examples of pure viruses are “I Love You” and “SoBig,” which propagate through e-mail attachments. Pure worm examples would be “Code Red,” “Slammer,” and “Blaster,” which actively scan for and infect further vulnerable systems in a chain-reaction fashion.
Fortunately, up to this time, the worms and viruses seen on the Internet have been somewhat mild in their actions. Current worms/viruses have performed one or more of the following actions:
- Install back-door software for remote control of systems
- Install an e-mail engine for relaying spam
- Deface web sites
- Conduct distributed denial of service (DDOS) attacks against targets
- Clog Internet bandwidth
Fears about future worms include the following:
- Corruption or deletion of data on systems. Paradoxically, those worms that perform this act slowly are considered to have more destructive potential,
as they may spread more widely before completely crippling their victims.
Of particular concern is the possibility of a “bit-rotting” worm that, over an extensive period of time, rots the data on the hard drive. Before its presence is detected, all data backups may themselves be copies of corrupted data as well. - Contrary to some beliefs, software can, in fact, damage hardware. A worm could overdrive a monitor and burn it out, or even scarier, reflash the BIOS
of the system either to contain a permanent back door or render the system unusable. - Construct a large scale DDOS army of controlled computers, ready to be unleashed against targets, with crippling effect.
- Espionage, both commercial and military.
- Personal information theft, such as credit card numbers, Social Security numbers, or other personal information of value.
A Brief History of Worms
In 1988, the Morris Internet worm made news by causing a disruption of the Internet for several days; it caused enormous slowdowns in the Internet, which had only 60,000 hosts at the time. Each successful worm in turn prompts, or popularizes, the correction of those bugs that it exploits. Although the Morris worm days are long past, it is worth reviewing the nature of this attack, as it is somewhat sophisticated. The Morris worm had three different attack vectors:
- Attack on Sendmail The worm connected to another system’s Sendmail process and invoked debug mode to download a 40-line C program to the target, which then was compiled on the target host. This compiled program downloaded additional code from the attacking system to create an executable called /usr/tmp/sh.
- Attack on fingerd, the finger daemon A buffer overflow attack allowed for the execution of a shell on the fingerd port, which was then used to download the additional code, as in the Sendmail attack.
- Attack using host trust relationships It accessed the .rhosts and /etc/hosts.equiv files to determine which hosts were trusted by the infected hosts. To access these new victims, the worm attempted to guess passwords of accounts harvested from the /etc/passwd file. It tried a number of combinations, as well as reading the entire /usr/dict/words file (which contained an online dictionary). Once a password was successfully guessed, the worm would look for a .rhosts file and log into the next victim, downloading code, as in the other attack vectors, and continued the process again.
The bugs responsible for the first two vectors were quickly corrected, but variations of the third infection vector are still used to spread worms to this day. When a web of trust exists between hosts, the security of this web is only as strong as its weakest link.
These days, Unix worms are fairly uncommon, as Windows systems are the victims of choice for worm writers these days. This is not, per se, an indictment of Windows security, but it is an indication of the popularity of the operating system and the target-rich environment. Worms now propagate through Windows shares to infect additional systems, as well as attempting to guess remote access passwords. Unlike the Morris worm, modern worms do not generally download and compile source code, but instead target a particular architecture, although they sometimes are adapted to different versions of the Windows operating system.
The modern worm era pretty much began with the emergence of the Code Red worm in 2001, which employed a heap overflow to exploit vulnerability in Microsoft’s IIS Web Server to deface web sites and scan for other victims. The original Code Red worm was entirely memory-resident, which means that rebooting the infected system would stop the worm’s scanning action, but unless the system was patched for the vulnerability, it would rapidly become infected again.
The first variant of Code Red was released on July 12, 2001, and was relatively harmless, as each infected system attacked the same computed list of systems. On July 19, 2001, Code Red v2 was unleashed with an improved random number generator that rapidly infected an estimated 359,000 systems in 14 hours. At its peak, more than 2000 systems were being infected every minute. This worm was also programmed to launch a massive DDOS attack on http://www.whitehouse.gov. The IP address of this site was hard-coded into the worm, so the attack was foiled by moving the web site to a different IP address. Consequently, the programmed attack (which took place as scheduled) targeted an unused IP address. At the scheduled time, many backbone providers took the additional step of refusing to route traffic destined for the programmed address.
Code Red II (distinct from Code Red v2), discovered on August 4, 2001, exploited the same vulnerability that the original Code Red used, but it actually installed a back door for hackers to enter the system and remained on the system through reboots. Surprisingly enough, even as of this writing (October 2003), Code Red still exists in the wild on the Internet, and it still scans sites for vulnerable hosts.
The Nimda worm followed on the heels of Code Red to exploit another Microsoft IIS vulnerability and in fact attempted to spread via the back door created by Code Red II. It has numerous infection vectors, including e-mail, open shares, and the aforementioned IIS vulnerability. One interesting feature that other worm authors have emulated is that the Nimda worm disables common antivirus products on infected systems, thus increasing the difficulty of detection.
In 2003, the Slammer Worm hit, entirely enclosed in a single 376-byte User Datagram Protocol (UDP) packet. This worm was by far the fasted spreading worm to date, infecting every vulnerable system reachable on the Internet within 30 minutes of its release into the wild. The main effect of this worm was the enormous increase in traffic on UDP port 1434, clogging the Internet with high-speed scanning. As this worm was memory-resident, turning off the system removed the worm, but patching was required to prevent reinfection.
Later in 2003, the Blaster worm hit the Internet with a vengeance, exploiting a Windows Distributed Component Object Model (DCOM) vulnerability. Exploited systems began immediately scanning for other vulnerable systems and compromised them, and in turn lead the newly infected systems began scanningfor more vulnerable systems to infect. Fortunately, we have not seen malicious content in these worms, but researchers expect that to be merely a matter of time. The Welchia worm followed quickly on its heels, as a misguided attempt to install the Microsoft patch on vulnerable systems, but quickly achieved a life of its own and wreaked havoc in its own right.
It is clear that more virulent worms and viruses are to be expected. The goal of IDS is to detect and contain these incidents quickly so that they do not overwhelm enterprise security resources.
Summary
We have seen some of the types of vulnerabilities in common software packages used on the Internet today. As the software industry matures further, we will see advances in application, system, and process security. We can also expect the hacking community to continue creatively challenging security professionals with new techniques and corresponding advances in IDS techniques to combat these threats. In Chapter 5, we will examine one of the seminal tools in IDS, TCPDump, and how it can be used to capture and foil attacks.
Part I - Intrusion Detection: Primer
- Understanding Intrusion Detection
- Crash Course in the Internet Protocol Suite
- Unauthorized Activity I
- Unauthorized Activity II
- Tcpdump
Part II - Architecture
Part III - Implementation and Deployment
Part IV - Security and IDS Management
EAN: 2147483647
Pages: 163
- The Second Wave ERP Market: An Australian Viewpoint
- Data Mining for Business Process Reengineering
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare
- Development of Interactive Web Sites to Enhance Police/Community Relations
