Problems in Linked Lists
PROBLEM IMPLEMENTATION OF POLYNOMIALS USING LINKED LISTS
Write functions to add, subtract, and multiply two polynomials represented as lists. Also, write a function to evaluate the polynomial for a given value of its variable.
Program
/* compile with -lm option. */
#include
#include
#include
typedef struct node node;
typedef int type;
typedef node *polynomial;
struct node {
type coeff;
type power;
node *next;
};
polynomial createPoly(int n, ...) {
/*
* create a list from the arguments.
* n is the number of nodes which will be created.
* thus after n there should be 2n arguments: (coeff, power) pairs.
* it is assumed that their powers are decreasing.
*/
va_list vl;
polynomial p = NULL;
int i;
va_start(vl, n);
for(i=0; icoeff = va_arg(vl, int);
ptr->power = va_arg(vl, int);
ptr->next = p;
p = ptr;
}
va_end(vl);
return p;
}
void pPrint(polynomial p) {
node *ptr;
for(ptr=p; ptr; ptr=ptr->next)
printf("%dx%d + ", ptr->coeff, ptr->power);
printf("
");
}
polynomial pSub(polynomial p1, polynomial p2) {
/*
* return p1-p2 recursively.
*/
node *ptr = (node *)malloc(sizeof(node));
if(p1 && p2 && p1->power == p2->power) {
ptr->coeff = p1->coeff - p2->coeff;
ptr->power = p1->power;
ptr->next = pSub(p1->next, p2->next);
}
else if(p1 && ((p2 && p1->power < p2->power) || !p2)) {
ptr->coeff = p1->coeff;
ptr->power = p1->power;
ptr->next = pSub(p1->next, p2);
}
else if(p2 && ((p1 && p1->power > p2->power) || !p1)) {
ptr->coeff = -p2->coeff;
ptr->power = p2->power;
ptr->next = pSub(p1, p2->next);
}
else { // p1 == p2 == NULL.
free(ptr);
return NULL;
}
return ptr;
}
polynomial pAdd(polynomial p1, polynomial p2) {
/*
* return p1+p2 recursively.
*/
node *ptr = (node *)malloc(sizeof(node));
if(p1 && p2 && p1->power == p2->power) {
ptr->coeff = p1->coeff + p2->coeff;
ptr->power = p1->power;
ptr->next = pAdd(p1->next, p2->next);
}
else if(p1 && ((p2 && p1->power < p2->power) || !p2)) {
ptr->coeff = p1->coeff;
ptr->power = p1->power;
ptr->next = pAdd(p1->next, p2);
}
else if(p2 && ((p1 && p1->power > p2->power) || !p1)) {
ptr->coeff = p2->coeff;
ptr->power = p2->power;
ptr->next = pAdd(p1, p2->next);
}
else { // p1 == p2 == NULL.
free(ptr);
return NULL;
}
return ptr;
}
void pInsertOrAdd(polynomial p, node *ptr) {
/*
* p->next anytime contains a partial product.
* add ptr at appropriate place in it keeping powers in order.
*/
node *curr, *prev;
for(prev=p, curr=prev->next; curr && curr->power < ptr->power;
prev=curr, curr=curr->next)
;
// prev will always be NON-NULL :).
if(curr && curr->power == ptr->power)
curr->coeff += ptr->coeff, free(ptr);
else
prev->next = ptr, ptr->next = curr;
}
polynomial pMult(polynomial p1, polynomial p2) {
/*
* return p1*p2.
*/
node p3, *ptr1, *ptr2, *ptr;
p3.next = NULL;
for(ptr1=p1; ptr1; ptr1=ptr1->next)
for(ptr2=p2; ptr2; ptr2=ptr2->next) {
ptr = (node *)malloc(sizeof(node));
ptr->coeff = ptr1->coeff * ptr2->coeff;
ptr->power = ptr1->power + ptr2->power;
pInsertOrAdd(&p3, ptr);
}
return p3.next;
}
int pEval(polynomial p1, int x) {
/*
* evaluate p1 at x.
*/
node *ptr;
int result = 0;
for(ptr=p1; ptr; ptr=ptr->next)
result += ptr->coeff * pow(x, ptr->power);
return result;
}
int main() {
polynomial p1 = createPoly(3, 3, 5, -1, 3, -10, 0),
p2 = createPoly(3, -2, 3, 0, 2, 20, 0);
pPrint(p1);
pPrint(p2);
pPrint(pAdd(p1, p2));
pPrint(pSub(p1, p2));
pPrint(pMult(p1, p2));
printf("value of p1 at x=%d is %d.
", 2, pEval(p1, 2));
return 0;
}
Explanation
- A polynomial, such as ax3+bx+c, is represented by using a linked list of nodes. Each node contains a coefficient and a power of the variable x. Thus this above expression is stored as follows:

- The function createPoly() creates a linked list of the given coefficients and powers sent to the function, using the variable number of arguments technique.
- pAdd(p1, p2) adds polynomials p1 and p2 and returns the sum. It adds coefficients of the nodes of lists p1 and p2 containing the same power. The nodes in p1 and p2 for which there is no node in the other list with the same power is copied to the result as it is. The traversal of p1 and p2 is done such that the resulting list is also sorted based on power in ascending order. This traversal is done using recursion. The function pSub() for subtraction is identical. For example,
(3 × 5 + 4 × 3 + 9) + (5 × 3 − 4x) = (3 × 5 + 9 × 3 − 4x + 9)
and
(3 × 5 + 4x 3 + 9) + (5 × 3 − 4x) = (3 × 5 − 1 × 3 + 4x + 9)
- The function pMult(p1, p2) traverses each node n2 of list p2 for each node n1 of list p1, and prepares a new node whose coefficient is the product of the coefficients in the two nodes n1 and n2 and whose power is the sum of the powers of n1 and n2. It is possible to get the same resulting power for two multiplications. So the procedure pInsertOrAdd() traverses the resulting list p3 for occurrence of the node with the same power. If such a node n3 exists, then the new coefficient is added to the old coefficient of n3; otherwise a new node with the new coefficient is inserted in p3. For example,
(3 × 5 + 4 × 3 + 9) × (5 × 3 − 4x)
= (15 × 8 − 12 × 6) + (20 × 6 − 16 × 4) + (45 × 3 − 36x)
= (15 × 8 + 8 × 6 − 16 × 4 + 45 × 3 − 36x). - The function pEval(p1, x) evaluates the expression in p1 at point x and returns the value. This is done by traversing the list p1 once and adding the values coefficient *x∧ power for each node. For example, the value of the polynomial (3x5+4x3+9) at x=2 is (3*2∧5+4*2∧3+9) = (96+32+9) = 137.
- The complexity of pAdd() and pSub() is O(m1+m2), where m1 and m2 are the lengths of the input lists. The complexity of pInsertOrAdd() is O(m1+m2). Thus the complexity of pMult() is O(m1*m2*(m1+m2)). The complexity of pEval() is O(m) where m is the length of the input list.
Points to Remember
- Polynomials can be represented using linked lists. This has the advantage of reduced space if many of the coefficients in the list are zero. Also, the procedures operating on polynomials represented by arrays and lists are not different as far as complexity is concerned.
- To avoid sending a variable number of arguments to createPoly(), an array can be passed as a parameter.
- The program should be compiled with the –lm option in order to link libm library for the function pow().
PROBLEM IMPLEMENTATION OF CIRCULAR LISTS BY USING ARRAYS
A linear list is maintained circularly in an array clist[0…N–1] with rear and front set up as for circular queues. Write functions to delete the k-th element in the list and to insert an element e immediately after the k-th element.
Program
#include
#define N 10 // size of the list.
#define FIRSTINDEX 0 // index of first element in the list.
#define ILLEGALINDEX -1 // illegal index - for special cases.
#define EINDEXOUTOFBOUND -1 // error code on overflow in the list.
#define SUCCESS 0 // success code.
typedef int type; // type of each data item.
type clist[N]; // list implemented using array.
int front = ILLEGALINDEX; // points to first element in the list.
int rear; // points to last element in the list.
int lPush( type data ) {
/*
* appends 'data' to the end of the list if space is available.
* otherwise returns error.
*/
if( front == ILLEGALINDEX ) { // list empty.
front = rear = FIRSTINDEX;
}
else if( (rear+1)%N == front ) { // list overflow.
return EINDEXOUTOFBOUND;
}
else // normal case.
rear = (rear+1)%N; // %N for wrapping around of index.
clist[rear] = data;
return SUCCESS;
}
void lPrint() {
/*
* prints elements in the list from front to rear.
*/
int i;
int nelem = lGetNElements();
for( i=0; i nelem || k < 1 )
return EINDEXOUTOFBOUND;
index = (front+k-1)%N; // index of the element to be deleted.
for( i=k+1; i<=nelem; ++i )
clist[ (front+i-2)%N ] = clist[ (front+i-1)%N ];
if( nelem == 1 ) // list is empty now.
front = ILLEGALINDEX;
else if( k == 1 )
front = (front+1)%N;
else
rear = (rear-1+N)%N;
return SUCCESS;
}
int lInsertAfterK( type data, int k ) {
/*
* inserts 'data' after k'th element in the list.
* if list is full or k is out of bounds, error is returned.
* k starts from 0.
*/
int i, index;
int nelem = lGetNElements();
printf( "inserting %d after %d'th element...
", data, k );
if( k > nelem || k < 0 || nelem == N )
return EINDEXOUTOFBOUND;
if( nelem == 0 ) // list empty.
front = rear = FIRSTINDEX;
else
rear = (rear+1)%N;
index = (front+k)%N; // index at which data should be inserted.
for( i=nelem; i>k; -i )
clist[ (front+i)%N ] = clist[ (front+i-1)%N ];
clist[ (front+k)%N ] = data;
}
int main() {
lInsertAfterK(100,0);
lPrint();
lPush(0);
lPush(4);
lPush(7);
lPush(1);
lPush(13);
lPush(2);
lPush(5);
lPrint();
lInsertAfterK(2,1);
lPrint();
lDeleteK(4);
lPrint();
lPush(6);
lPush(3);
lPush(23);
lPrint();
lDeleteK(9);
lPrint();
lInsertAfterK(20,9);
lPrint();
lDeleteK(10);
lPrint();
lInsertAfterK(20,0);
lPrint();
return 0;
}
Explanation
- clist[0…N–1] is a global queue of integers. The rear and front are its two pointers (indices) maintained for insertion and deletion of elements. The rear points to the last element inserted in the queue while front points to the next element to be removed from the queue.
- An empty queue is represented by front = –1. The front and rear are updated on insertions and deletions. Since the queue is circular and the array size is fixed, element e is inserted when rear = N – 1 goes to clist[0], if it is empty. Also, after removal of an element from the queue when front = N – 1, front points to clist[0], if it exists. Thus the indices front and rear wrap around in the range 0…N – 1.
- The number of elements in the queue at any time (lGetNElements()) can be found using the following formula:
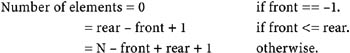
- To delete the k-th element (k > 0) (lDeleteK()), it is first checked to see if the number of elements in the queue is less than or equal to k. If there is a k- th element, its index in the array can be found using the formula (front+k−1)%N. After deletion of the element, all the elements after it are shifted back by one position and rear is updated. If k == 1, or if the deleted element was the last element in the queue, then front needs to be updated accordingly. For example, let the queue look like this:

If k == 5, then after lDeleteK() runs, the queue looks like this:

Note that elements 6 and 7 have been shifted back by one position.
- To insert an element after the k-th element (k >= 0) (lInsertAfterK()), again k is checked against the number of elements in the queue. The index for the new element would be (front+k)%N. To create space for the new element, all the elements after k-th element need to be shifted foward by one position. The new element can then be inserted and the indices front and rear are updated accordingly. For example, say the queue looks like the following:

Then, after lInsertAfterK() is run with k == 4, the queue becomes

Note how the rear is wrapped around.
- Because of the shifting required in insertion and deletion, the time complexity of both the functions is O(n). We note that if insertions and deletions take place at rear and front, respectively, the complexity remains O(1). The constant of proportionality of the complexity can be improved by checking the number of elements before and after the k-th element and then shifting the smaller number of the two.
Points to Remember
- In an array-based circular queue implementation, the indices front and rear wrap around the N elements.
- The index of a k-th element is calculated as (front+k–1)%N.
- The number of elements in the queue is calculated as 0, (rear−front+1), or (N–front+rear+1) depending on whether the queue is empty (front == −1). There is no wrapping of indices (front <= rear) and rear is wrapped around (front > rear).
- To insert an element after the k-th element, all the elements after it should be first shifted forward by one position. To delete an element at the k-th position, all the elements after it should be shifted back by one position.
- Corner cases such as queue full and queue empty should be handled properly.
PROBLEM REVERSING LINKS IN THE CASE OF CIRCULAR LIST
Write a function for a singly linked circular list that reverses the direction of the links.
Program
#include
#define SUCCESS 0
#define ERROR -1
typedef int type;
typedef struct node node;
struct node {
type data;
node *next;
};
node *head = NULL;
int lInsert( type data ) {
/*
* inserts a new node containing data at start of the list.
*/
node *ptr = (node *)malloc( sizeof(node) );
ptr->data = data;
if( head == NULL ) { // this is the first element in the list.
ptr->next = ptr;
head = ptr;
}
else {
ptr->next = head->next;
head->next = ptr;
}
return SUCCESS;
}
void lPrint() {
node *ptr;
if( head == NULL )
return;
else
printf( "%d ", head->data );
for( ptr=head->next; ptr!=head;
ptr=ptr->next ) printf( "%d ", ptr->data );
printf( "
" );
}
int lReverse() {
/*
* insitu reverses the list.
*/
node *curr, *prev, *next;
printf( "reversing list...
" );
if( head == NULL )
return SUCCESS;
for( prev=head, curr=prev->next, next=curr->next; curr!=head; prev=curr, curr=next, next=next->next ) {
curr->next = prev;
}
head->next = prev;
return SUCCESS;
}
int main() {
lPrint();
lInsert(1);
lPrint();
lInsert(2);
lInsert(3);
lInsert(4);
lInsert(5);
lInsert(6);
lPrint();
lReverse();
lPrint();
return 0;
}
Explanation
- main() creates a linked list of integers and then calls lReverse() to reverse the list. Note that the list is circular.
- The function lReverse() maintains three pointers, prev, curr, and next, while traversing the list. They point to consecutive nodes in the list. If the list is non-empty, then prev points to the head node while curr and next are accordingly assigned to the next elements in the list. The circular list is traversed until curr == head of the list. At every step, curr->next points to prev. At the end of the loop, all the nodes in the list except the head node point to their original previous nodes. Thus at the end of the loop, head->next is assigned prev which is the last node in the list.
- Example:
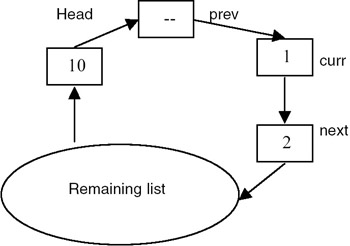
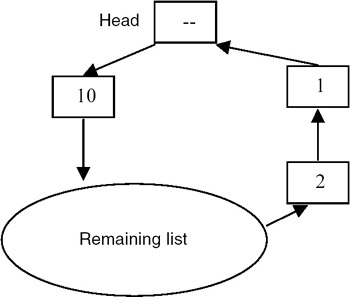
After reversal this list appears as shown here:
Points to Remember
- Note that the loop advances curr as curr=next rather than curr=curr->next, because curr->next gets changed in the loop.
- The complexity of the reversal procedure is O(n).
- If the head is maintained as a fixed node, that is, an empty list is denoted by a single node rather than NULL, then the functions operating on the list get simplified.
PROBLEM MEMORY MANAGEMENT USING LISTS
Design a storage management scheme where all requests for memory are of the same size, say K. Write functions to free and allocate storage in this scheme.
Program
#include
#define N 90
#define K 10
#define SUCCESS 0
#define ERROR -1
typedef struct node node;
struct node {
void *ptr; // points to free block of size K.
node *next;
};
struct head {
//int nnodes;
node *next;
char *bytes; // mem will be allocated from this pool.
}freelist;
void init() {
/*
* initialize the memory space.
*/
int i;
void memfree( void * );
//freelist.nnodes = 0;
freelist.next = NULL;
freelist.bytes = (char *)malloc(N);
for( i=N/K-1; i>=0; -i ) {
memfree( freelist.bytes+K*i );
}
}
void *memalloc() { // assume request to be of size K.
/*
* returns a void
* pointer to area from freelist.
*/
void *ptr;
node *nodeptr;
if( freelist.next == NULL )
return (void *)NULL;
nodeptr = freelist.next;
ptr = nodeptr->ptr;
freelist.next = freelist.next->next;
free(nodeptr); // this is standard free().
return ptr;
}
void memfree( void *ptr ) {
/*
* adds ptr to freelist.
*/
node *nodeptr;
if( ptr == NULL )
return;
nodeptr = (node *)malloc( sizeof(node) );
nodeptr->ptr = ptr;
nodeptr->next = freelist.next;
freelist.next = nodeptr;
}
void print() {
node *ptr;
for( ptr=freelist.next; ptr!=NULL; ptr=ptr->next ) {
printf( "%u ", ptr->ptr );
}
printf( "
" );
}
int main() {
void *p1, *p2, *p3, *p4;
init();
printf( "after init...
" );
print();
p1 = memalloc();
printf( "after memalloc(p1)...
" );
p2 = memalloc(); p3 = memalloc();
print();
memfree(p1); memfree(p2); memfree(p3);
printf( "after memfree(p1)...
" );
print();
return 0;
}
Explanation
- Since all requests are of the same size, theoretically only one bit is required with each block of size K to tag it as free or allocated. However, we do not know the number of blocks (the size of the memory pool). So we need a list of such status bits. An array-based list would have been sufficient but the size of a memory pool can be very large. So we prefer a linked list of status bits.
- The functions on the memory pool are memfree() and memalloc(), which need pointers to the memory areas to be exchanged between the memory manager and the user program. So instead of bits, we store only the pointers to the memory areas. We further shorten this list by storing only pointers to the free blocks in the lists. Thus we maintain a free-list of free pointers.
- We take advantage of all the requests of the same size to make memfree() and memalloc() functions O(1). memalloc() returns the first free pointer in the list and memfree() adds the free pointer to the head of the free-list. The only loop in the program is required only once, for initializing the free-list at the start of the program. A global memory pool of size N acts as the free pool. It is divided into blocks of size K and pointers to the start of each block are inserted into the free-list.
Points to Remember
- If all the requests are of the same size, then allocation and free operations can be done in O(1) time.
- Instead of a separate free-list, each free block of size K can contain a pointer to the next free block of memory.
PROBLEM MEMORY MANAGEMENT USING VARIOUS SCHEMES
Implement a memory allocation scheme by using the algorithms first-fit, next-fit, and best-fit.
Program
#include
#define N 100
typedef struct node node;
typedef enum {FALSE, TRUE} bool;
struct node {
char *ptr; // start addr.
int size; // size of the free block.
node *next; // next free block.
};
char mem[N]; // total memory pool.
node freelist; /*
* the freelist should be sorted on start addr.
* this will ease coalescing adjacent blocks.
*/
void init() {
/*
* init freelist to contain the whole mem.
*/
node *ptr = (node *)malloc( sizeof(node) );
ptr->ptr = mem;
ptr->size = N;
ptr->next = NULL;
freelist.next = ptr;
}
void removenode( node *ptr, node *prev ) {
/*
* remove a node ptr from the list whose previous node is prev.
*/
prev->next = ptr->next;
free(ptr);
}
char *firstfit( int size ) {
*
* returns ptr to free pool of size size from freelist.
*/
node *ptr, *prev;
char *memptr;
for( prev=&freelist, ptr=prev->next; ptr; prev=ptr, ptr=ptr->next )
if( ptr->size > size ) {
memptr = ptr->ptr;
ptr->size -= size;
ptr->ptr += size;
return memptr;
}
else if( ptr->size == size ) {
memptr = ptr->ptr;
removenode( ptr, prev );
return memptr;
}
return NULL;
}
char *nextfit( int size ) {
/*
* returns ptr to free pool of size size from freelist.
* the free pool is second allocatable block instead of first.
* if no second block then first is returned.
*/
bool isSecond = FALSE;
node *prev, *ptr;
node *firstprev, *firstptr;
for( prev=&freelist, ptr=prev->next; ptr; prev=ptr, ptr=ptr->next )
if( ptr->size >= size && isSecond == FALSE ) {
isSecond = TRUE;
firstprev = prev;
firstptr = ptr;
}
else if( ptr->size > size && isSecond == TRUE ) {
char *memptr = ptr->ptr;
ptr->size -= size;
ptr->ptr += size;
return memptr;
}
else if( ptr->size == size && isSecond == TRUE ) {
char *memptr = ptr->ptr;
removenode( ptr, prev );
return memptr;
}
// ptr is NULL.
ptr = firstptr;
prev = firstprev;
if( ptr->size > size && isSecond == TRUE ) {
char *memptr = ptr->ptr;
ptr->size -= size;
ptr->ptr += size;
return memptr;
}
else if( ptr->size == size && isSecond == TRUE ) {
char *memptr = ptr->ptr;
removenode( ptr, prev );
return memptr;
}
else // isSecond == FALSE
return NULL;
}
char *bestfit( int size ) {
/*
* returns ptr to free pool of size size from freelist.
* the allocated block's original size - size is min in the freelist.
*/
node *ptr, *prev;
char *memptr;
int minwaste = N+1;
node *minptr = NULL, *minprev;
for( prev=&freelist, ptr=prev->next; ptr; prev=ptr, ptr=ptr->next )
if( ptr->size >= size && ptr->size-size < minwaste ) {
minwaste = ptr->size-size;
minptr = ptr;
minprev = prev;
}
if( minptr == NULL ) // could NOT get any allocatable mem.
return NULL;
ptr = minptr;
prev = minprev;
if( ptr->size > size ) {
memptr = ptr->ptr;
ptr->size -= size;
ptr->ptr += size;
return memptr;
}
else if( ptr->size == size ) {
memptr = ptr->ptr;
removenode( ptr, prev );
return memptr;
}
return NULL;
}
void addtofreelist( char *memptr, int size ) {
/*
* add memptr of size to freelist.
* remember that block ptrs are sorted on mem addr.
*/
node *prev, *ptr, *newptr;
for( prev=&freelist, ptr=prev->next; ptr && ptr->ptrnext )
;
// memptr is to be added between prev and ptr.
newptr = (node *)malloc( sizeof(node) );
newptr->ptr = memptr;
newptr->size = size;
newptr->next = ptr;
prev->next = newptr;
}
void coalesce() {
/*
* combine adj blocks of list if necessary.
*/
node *prev, *ptr;
for( prev=&freelist, ptr=prev->next; ptr; prev=ptr, ptr=ptr->next )
// check for prev mem addr and size against ptr->ptr.
if( prev != &freelist && prev->ptr+prev->size == ptr->ptr ) {// prev->size += ptr->size; //
prev->next = ptr->next;
free(ptr);
ptr = prev; // ).
}
}
char *memalloc( int size ) {
/*
* return ptr to pool of mem of the size.
* return NULL if NOT available.
* ptr-sizeof(int) contains size of the pool allocated, like malloc.
*/
char *ptr = bestfit( size+sizeof(int) ); // change this to
firstfit() or nextfit().
printf( "allocating %d using bestfit...
", size );
if( ptr == NULL )
return NULL;
*(int *)ptr = size;
return ptr+sizeof(int);
}
void memfree( char *ptr ) {
/*
* adds ptr to freelist and combine adj blocks if necessary.
* size of the mem being freed is at ptr-sizeof(int).
*/
int size = *(int *)(ptr-sizeof(int));
printf( "freeing %d...
", size );
addtofreelist( ptr-sizeof(int), size+sizeof(int) );
coalesce(); // combine adjacent blocks.
}
void printfreelist() {
node *ptr;
printf( " " );
for( ptr=freelist.next; ptr; ptr=ptr->next )
printf( "{%u %d} ", ptr->ptr, ptr->size );
printf( "
" );
}
int main() {
char *p1, *p2, *p3, *p4, *p5;
init();
printfreelist();
p1 = memalloc(10);
printfreelist();
p2 = memalloc(15);
printfreelist();
p3 = memalloc(23);
printfreelist();
p4 = memalloc(3);
printfreelist();
p5 = memalloc(8);
printfreelist();
memfree(p1);
printfreelist();
memfree(p5);
printfreelist();
memfree(p3);
printfreelist();
p1 = memalloc(23);
printfreelist();
p1 = memalloc(23);
printfreelist();
memfree(p2);
printfreelist();
p1 = memalloc(3);
printfreelist();
memfree(p4);
printfreelist();
p2 = memalloc(1);
printfreelist();
memfree(p1);
printfreelist();
memfree(p2);
printfreelist();
return 0;
}
Explanation
- A memory manager provides a pool of memory when requested (memalloc()) and frees a pool of memory (memfree()) to be used for the next allocation request. It maintains a free-list of pointers to memory blocks along with their sizes. Whenever there is a request for a free pool of memory having the size size, this free-list is searched for the appropriate block depending on the algorithm. If such a block is found, it is removed from the free-list and a pointer to it is returned. Whenever a pool of memory is freed using memfree(p), the pointer p is added to the free-list. If possible, the adjacent blocks are combined using coalesce() to get a bigger free pool.
- In a first-fit algorithm, the first free pool of memory is granted if it has sufficient size to satisfy the request. Thus, if sizes of free pools in the free-list are {10 9 20 34 43 12 22}, and the request is for size 21, then the pointer to the pool pointed to by the node having size 34 is returned.
- In a next-fit algorithm, the second free pool of memory is granted if it has sufficient size to satisfy the request. If no such second free pool is available, then the first such free pool is granted. Thus, if the free-list is as shown earlier, then a request for size 21 is fulfilled using the block having size 43.
- In a best-fit algorithm, that free pool of memory is granted which retains the minimum amount of space after allocation. Thus, if the free-list is as shown earlier, then a request for size 21 is fulfilled by the block having size 22, as its residual memory is 22 – 21 = 1.
- Note that the free-list is sorted on the address each node saves and not on size. Sorting on size can help improve the performance of memalloc() by a constant factor. The advantage of sorting on addresses is realized during coalescing of adjacent blocks. This happens when two adjacent blocks that are free are stored in the free-list in adjacent nodes. This may keep a request unsatisfied, even if a free pool of the requested size existed. So, we check for the start address of a block added to its size with the start address of the next block. If they match, we combine the two nodes. This procedure is followed until this condition is violated.
- The complexity of each of the three algorithms is O(n) where n is the number of nodes in the free-list. It has been seen using experiments that first- and best-fit have nearly similar performances and somewhat better than the next-fit algorithm. The complexity of memalloc() is the same as the algorithm it implements. The complexity of memfree() is O(n), as it needs to insert the free pointer in a sorted list.
Points to Remember
- In first-fit, the first free pool satisfying the request is returned. In next-fit, the second such free pool is returned. In best-fit, the free pool which leaves a free pool of minimum size after allocation is returned.
- If the application requires two pointers to point to the same area, then the problem of a dangling pointer may arise in the system, where a pointer may point to an area that is not allocated. This happens when another pointer pointing to the same memory area frees the pool.
- Garbage collection is the process of collecting the memory that was previously allocated but is no longer being used by the application. Garbage is generated as a result of bad programming practice, wherein we allocate memory as required but do not free it after its use. Algorithms using reference counts and the mark-and-sweep algorithm are generally used for garbage collection.
PROBLEM GARBAGE COLLECTION THE FIRST METHOD
Implement a mark() procedure used in garbage collection to mark all the nodes traversible from a head node by using a stack.
Program
/************************ mark1.s.c **************************/
#include
typedef struct snode snode;
typedef list stype;
typedef struct snode *stack;
struct snode {
stype op;
snode *next;
};
bool sEmpty( stack *s ) {
return (*s == NULL);
}
void sPush( stack *s, stype op ) {
/*
* pushes op in stack s.
*/
snode *ptr = (snode *)malloc( sizeof(snode) );
ptr->op = op;
ptr->next = *s;
*s = ptr;
}
stype sTop( stack *s ) {
/*
* returns top op from stack s without popping.
*/
if( sEmpty(s) )
return NULL;
return (*s)->op;
}
stype sPop( stack *s ) {
/*
* pops op from top of stack s.
*/
snode *ptr = *s;
stype op;
if( sEmpty(s) )
return NULL;
*s = (*s)->next;
op = ptr->op;
free(ptr);
return op;
}
/************************ mark1.c ***************************/
#include
typedef struct node node;
typedef int type;
typedef enum {FALSE, TRUE} bool;
typedef node *list;
#include "mark1.s.c"
struct node {
bool mark;
type val;
node *horiz;
node *vert;
};
list newNode() {
/*
* return a new node.
*/
return (list)calloc(1, sizeof(node));
}
list createList() {
/*
* return a dummy list created.
*/
list ptr;
snode *s = NULL;
list sixptr;
list nineptr;
ptr = newNode();
sPush(&s, ptr);
ptr->val = 1;
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
ptr->val = 2;
ptr->vert = newNode();
ptr = ptr->vert;
sPush(&s, ptr);
ptr->val = 3;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 4;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->val = 5;
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
sixptr = ptr;
ptr->val = 6;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 7;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->val = 8;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
nineptr = ptr;
ptr->val = 9;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 10;
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->val = 11;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->vert = nineptr; // an internal link.
ptr->val = 12;
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
ptr->val = 13;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 14;
ptr->horiz = sixptr; // an internal link.
ptr = sPop(&s);
return sPop(&s);
}
void markList(list ptr) {
/*
* print the horiz and vert lists iteratively using a stack.
*/
snode *s = NULL;
list horiz;
if(!ptr || ptr->mark)
return;
ptr->mark = TRUE;
printf("marked=%d.
", ptr->val);
sPush(&s, ptr);
while(!sEmpty(&s)) {
ptr = sPop(&s);
do {
horiz = ptr->horiz;
if(horiz && horiz->mark == FALSE) {
horiz->mark = TRUE;
printf("marked=%d.
", horiz->val);
sPush(&s, horiz);
}
ptr = ptr->vert;
if(!ptr || ptr->mark)
break;
ptr->mark = TRUE;
printf("marked=%d.
", ptr->val);
} while(TRUE);
}
}
void markListRec(list ptr) {
/*
* mark the list pointed to by ptr recursively.
*/
for(; ptr && !ptr->mark; ptr=ptr->horiz) {
ptr->mark = TRUE;
printf("marked=%d.
", ptr->val);
markListRec(ptr->vert);
}
}
int main() {
list head = createList();
markListRec(head);
return 0;
}
Explanation
- An algorithm called mark-and-sweep is used for garbage collection. In this, from every variable, memory is traversed and marked as used. Then a traversal over the whole memory is done to add all the unmarked nodes to the free-list, thus collecting the garbage. The former is called mark while the latter is called sweep.
- We implement the marking procedure here. We assume the node structure as follows:
struct node { bool mark; type val; node *horiz; node *vert; };Thus the lists are generalized and can grow in both horizontal and vertical directions.
- The recursive marking algorithm is as shown here:
markListRec(ptr) { for(; ptr && !ptr->mark; ptr=ptr->horiz) { ptr->mark = TRUE; markListRec(ptr->vert); } }This procedure uses the system stack for recursion (internally).
- The iterative procedure markList(ptr) uses an explicit stack to store the nodes. It contains a nested loop in which the list is traversed horizontally and vertically. The next node on the horizontal list is marked and pushed on stack and the whole vertical list is then traversed. The same strategy is used for each node in the vertical list. Whenever a node is visited, it is checked to see if it was marked. If yes, then it is not processed; otherwise, it is marked.
- Example: The function createlist() creates an arbitrary list structure as shown here.
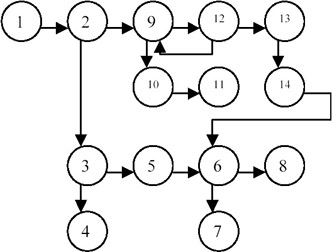
Different steps of the algorithm:
|
STEP |
PTR |
PTR->MARK |
HORIZ |
HORIZ->MARK |
STACK |
OUTPUT |
|---|---|---|---|---|---|---|
|
0 |
1 |
F |
— |
— |
1 |
1 |
|
1 |
1 |
T |
2 |
F |
2 |
1 2 |
|
2 |
2 |
T |
9 |
F |
9 |
1 2 9 |
|
3 |
3 |
F |
9 |
T |
9 |
1 2 9 3 |
|
4 |
3 |
T |
5 |
F |
9 5 |
1 2 9 3 5 |
|
5 |
4 |
F |
5 |
T |
9 5 |
1 2 9 3 5 4 |
|
6 |
5 |
T |
6 |
F |
9 6 |
1 2 9 3 5 4 6 |
|
7 |
6 |
T |
8 |
F |
9 8 |
1 2 9 3 5 4 6 |
|
8 |
7 |
F |
8 |
T |
9 8 |
1 2 9 3 5 4 6 8 7 |
|
9 |
8 |
T |
nil |
— |
9 |
1 2 9 3 5 4 6 8 7 |
|
10 |
9 |
T |
12 |
F |
12 |
1 2 9 3 5 4 6 8 7 12 |
|
11 |
10 |
F |
12 |
F |
12 |
1 2 9 3 5 4 6 8 7 12 10 |
|
12 |
10 |
T |
11 |
F |
12 11 |
1 2 9 3 5 4 6 8 7 12 10 11 |
|
13 |
11 |
T |
11 |
T |
12 |
1 2 9 3 5 4 6 8 7 12 10 11 |
|
14 |
12 |
T |
13 |
F |
13 |
1 2 9 3 5 4 6 8 7 12 10 11 13 |
|
15 |
9 |
T |
13 |
T |
13 |
1 2 9 3 5 4 6 8 7 12 10 11 13 |
|
16 |
13 |
T |
nil |
— |
empty |
1 2 9 3 5 4 6 8 7 12 10 11 13 |
|
17 |
14 |
F |
6 |
T |
empty |
1 2 9 3 5 4 6 8 7 12 10 11 13 14 |
|
18 |
14 |
T |
6 |
T |
empty |
1 2 9 3 5 4 6 8 7 12 10 11 13 14 |
Thus in each step, the horizontal node is pushed as the return point and the whole vertical list is traversed. The return point is then popped and the procedure is continued until the stack becomes empty.
In step 9, since 8 is already marked, nothing is output. In step 14, ptr points to 12, which is marked, and horiz points to 13, which is unmarked. Thus it marks 13 and pushes it on stack. In the next step, the vertical list is traversed and ptr points to 9 while horiz is still 13. Since 9 is already marked, it is left and 13 is popped. horiz is now nil. Now the vertical list of 13 is traversed and ptr points to 14, which is unmarked, and so is marked. horiz now points to 6, which is marked, so nothing is done to it. A vertical pointer of 14 is traversed and it is found to be nil, so the inner loop quits. The stack is empty at this point, so the outer loop also quits and the procedure terminates.
Points to Remember
- A simple recursive procedure such as markListRec() can be more readable and compact than its iterative version markList().
- The complexity of the marking algorithm is O(e), where e is equal to the number of links in the graph.
- To mark all the memory traversible from program variables, markList() should be called for each of the variables.
- There is a serious caveat in using this algorithm for garbage collection. Usually, garbage is created when the user runs out of memory. This algorithm, however, requires a stack to work, so it will not proceed when there is not enough memory. So an algorithm that does not require more than a constant amount of extra memory should be used for garbage collection.
PROBLEM GARBAGE COLLECTION THE SECOND METHOD
Implement the marking procedure used in garbage collection without using more than a constant amount of memory.
Program
/************************ mark2.s.c *************************/
#include
typedef struct snode snode;
typedef list stype;
typedef struct snode *stack;
struct snode {
stype op;
snode *next;
};
bool sEmpty( stack *s ) {
return (*s == NULL);
}
void sPush( stack *s, stype op ) {
/*
* pushes op in stack s.
*/
snode *ptr = (snode *)malloc( sizeof(snode) );
ptr->op = op;
ptr->next = *s;
*s = ptr;
}
stype sTop( stack *s ) {
/*
* returns top op from stack s without popping.
*/
if( sEmpty(s) )
return NULL;
return (*s)->op;
}
stype sPop( stack *s ) {
/*
* pops op from top of stack s.
*/
snode *ptr = *s;
stype op;
if( sEmpty(s) )
return NULL;
*s = (*s)->next;
op = ptr->op;
free(ptr);
return op;
}
/************************ mark2.c ***************************/
#include
typedef struct node node;
typedef int type;
typedef enum {FALSE, TRUE} bool;
typedef node *list;
struct node {
bool mark;
bool tag;
type val;
node *horiz;
node *vert;
};
#include "mark2.s.c"
list newNode() {
/*
* return a new node.
*/
list ptr = (list)calloc(1, sizeof(node));
return ptr;
}
list createList() {
/*
* return a dummy list created.
*/
list ptr;
snode *s = NULL;
list sixptr;
list nineptr;
ptr = newNode();
sPush(&s, ptr);
ptr->val = 1;
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
ptr->val = 2;
ptr->vert = newNode();
ptr = ptr->vert;
sPush(&s, ptr);
ptr->val = 3;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 4;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->val = 5;
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
sixptr = ptr;
ptr->val = 6;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 7;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->val = 8;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
nineptr = ptr;
ptr->val = 9;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 10;
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->val = 11;
ptr = sPop(&s);
ptr->horiz = newNode();
ptr = ptr->horiz;
ptr->vert = nineptr; // an internal link.
ptr->val = 12;
ptr->horiz = newNode();
ptr = ptr->horiz;
sPush(&s, ptr);
ptr->val = 13;
ptr->vert = newNode();
ptr = ptr->vert;
ptr->val = 14;
ptr->horiz = sixptr; // an internal link.
ptr = sPop(&s);
return sPop(&s);
}
void markList(list ptr) {
/*
* print the horiz and vert lists iteratively without using a stack.
*/
list p, q, t;
p = ptr; t = NULL;
do {
printf("p->val=%d.
", p->val);
q = p->vert;
if(q)
if(q->mark == FALSE && q->tag == FALSE) {
q->mark = TRUE; p->tag = TRUE;
p->vert = t; t = p;
p = q;
}
else {
q->mark = TRUE;
label:
q = p->horiz;
if(q)
if(q->mark == FALSE && q->tag == FALSE) {
q->mark = TRUE; p->horiz = t;
t = p; p = q;
}
else {
q->mark = TRUE;
label2:
while(t) {
q = t;
if(q->tag) {
t = q->vert; q->vert = p;
q->tag = FALSE; p = q;
goto label;
}
t = q->horiz; q->horiz = p;
p = q;
}
}
else
goto label2;
}
else
goto label;
} while(t);
}
int main() {
list head = createList();
markList(head);
return 0;
}
Explanation
- The node structure is assumed to be as follows.
struct node { bool mark; bool tag; type val; node *horiz; node *vert; };Thus, using horiz and vert, generalized lists can be created containing data in val. mark is used for marking the nodes as visited or not. An additional Boolean tag is needed since we are not using an extra amount of memory in the algorithm, except for a few pointers. The mark and tag fields are initially FALSE for each node.
The explicit stack is used for creating the list (createList()), not for marking the nodes.
- This algorithm modifies some of the links in the list. However, by the time it finishes its task, the list structure is restored. Starting from ptr, markList() traces all possible paths made up of horiz and vert. Whenever a choice is to be made, the vert direction is explored first. Instead of maintaining a stack of return points, we now maintain the path taken from ptr to the node p that is currently being examined. This path is maintained by changing some of the pointers along the path from ptr to p.
- Example: Consider this example list. We omit the val field as it is not important here.
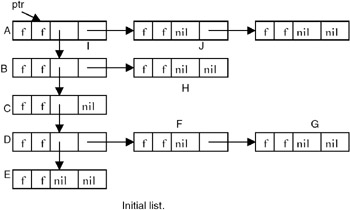
Initially, all nodes except node A are unmarked. From A we can move down to B or right to I. This algorithm always moves down when faced with such an alternative. We use p to point to the node currently being examined and t to point to the node preceding p in the path from ptr to p. The path t to ptr will be examined as a chain composed of the nodes on this t – ptr (read as "t to ptr") path. If we advance from node p to node q, then either q=p->horiz or q=p->vert, and q will become the node currently being examined. The node preceding q on the ptr–q path is p, and so the path list must be updated to represent the path from p to ptr. This is done simply by adding the node p to the t–ptr path that has been already constructed. Nodes will be linked onto this path through either their vert or horiz field. When node p is added to the path chain, p is linked to t via its vert field, if q=p->vert. When q=p->horiz, p is linked to t via its horiz field. In order to be able to determine whether a node on the t–ptr path list is linked through either the vert or horiz field, we make use of the tag field. When vert is used for linking, this tag will be TRUE. Thus, for nodes on t–ptr path we have:
tag = FALSE if the node is linked via horiz field. = TRUE if the node is linked via vert field.
The tag will be reset to FALSE when the node gets off the t–ptr path list. Different snapshots of the list are shown here:
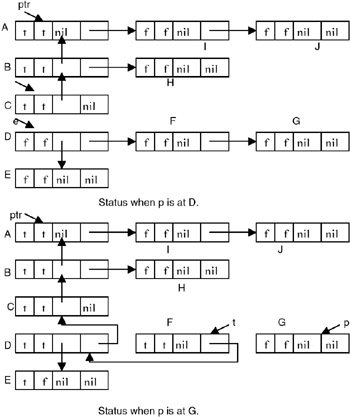
At the end of the algorithm, all the nodes are marked and all tag fields are restored to FALSE. Thus the list looks like this.
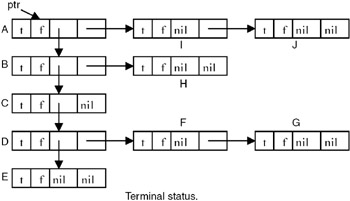
Points to Remember
- We require an extra tag field if the marking is to be done without using an extra amount of memory.
- The computing time of markList() is O(m) where m is the number of newly marked nodes.
- By properly maintaining the predicate for t–ptr list, the code can be easily understood.
- It is said that gotos should be avoided as much as possible. However, judicious use of gotos at proper places can make an otherwise tiring code easier to understand.
PROBLEM COMPUTE N EQUIVALENCE CLASSES
Write a program to produce N equivalent classes as linked lists from a linked list of integers, applying the mod function.
Program
#include
typedef struct node node;
struct node {
int val;
node *next;
};
node *getList(int a[], int n) {
/*
* form a list of n integers in a[].
*/
int i;
node *list = NULL;
for( i=0; ival = a[i];
ptr->next = list;
list = ptr;
}
return list;
}
node **applyMod(node *list, int n) {
/*
* apply (mod n) on every element of list and store that element in
* the list modlists[(mod n)].
* thus we form array[n] of lists.
* each list is one equivalence class.
*/
node **modlists;
node *ptr, *next;
modlists = (node **)calloc( n, sizeof(node *) );
for(ptr=list, next=(ptr?ptr->next:NULL); ptr; ptr=next, next=(next?next->next:NULL))
ptr->next = modlists[ptr->val%n], modlists[ptr->val%n] = ptr;
return modlists;
}
void printModlists(node **modlists, int n) {
/*
* prints the equivalence classes.
*/
node *ptr;
int i;
for(i=0; inext)
printf("%d ", ptr->val);
printf("
");
}
printf("
");
}
main() {
int a[] = {10,2,3,44,432,35,6576,34,12,5456,23423,234,23};
node *list = getList(a, sizeof(a)/sizeof(int));
node **modlists;
int n;
printf( "Enter number of equivalence classes: " );
scanf( "%d", &n );
modlists = applyMod(list, n);
printModlists(modlists, n);
return 0;
}
Explanation
- A relation that is symmetric, reflexive, and transitive is termed an equivalence relation. Each equivalence relation divides its elements into partitions called equivalence classes.
- A relation R is symmetric if aRb => bRa for all a, b in R and a!=b.
- A relation R is reflexive if aRa for all a in R.
- A relation R is transitive if aRb and bRc => aRc for all a, b, c in R.
- mod(), (the modulus function) is an equivalence relation. It partitions its set of elements into N equivalence classes where N is the number used for division.
- The program creates a linked list of integers (getList()). It then asks for the value of N for applying the mod() function. The function applyMod() takes a list of integers and the value of N as arguments and applies mod(N) over each element e of the list to get a value v as the remainder. The element e is then put in modlists[v], where modlists[N] is an array of list of integers. Each list modlists[i] represents one partition. Each list is finally printed.
- The complexity of applyMod() is O(m) where m is the number of elements in the original list. For each element, mod() is applied, which is assumed to be an O(1) operation, and the insertion of the element in the list is O(1). So applyMod() has linear complexity.
Points to Remember
- A relation which is symmetric, reflexive, and transitive is called an equivalence relation.
- An equivalence relation partitions its elements into disjointed sets.
- mod() is an equivalence relation.
- We save space in applyMod() by reusing the nodes from the original list into the array of lists.
Part I - C Language
- Introduction to the C Language
- Data Types
- C Operators
- Control Structures
- The printf Function
- Address and Pointers
- The scanf Function
- Preprocessing
- Arrays
- Function
- Storage of Variables
- Memory Allocation
- Recursion
- Strings
- Structures
- Union
- Files
Part II - Data Structures
Part III - Advanced Problems in Data Structures
EAN: 2147483647
Pages: 232
- Integration Strategies and Tactics for Information Technology Governance
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control
- Governance in IT Outsourcing Partnerships
- Governance Structures for IT in the Health Care Industry
