IP Addressing Design Considerations
Although security considerations for L2 are important, the attacks require local access to be successful. When designing your L3 layout, the ramifications of your decisions are much more important. This section outlines overall best practices for IP addressing, including basic addressing, routing, filtering, and Network Address Translation (NAT).
General Best Practices and Route Summarization
The basic best practices for IP addressing should be familiar to you. At a high level in your design, you first must decide whether the IP address of the user on your network will have any significance from a security standpoint. For example, if you are an organization with three sites, are you just going to assign a subnet to each of the three sites, even though there are individuals at each site with different levels of security access?
This approach is fine if your security system depends mostly on application layer security controls (AAA, intrusion detection). I've seen many designs that do this successfully, but it does take away a simple control that many find useful: L3 access control. Here, users are put into group-specific subnets that provide an additional layer of access control between the user and the resources. You can compare the two approaches in Figures 6-11 and 6-12.
Figure 6-11. Application Security Design
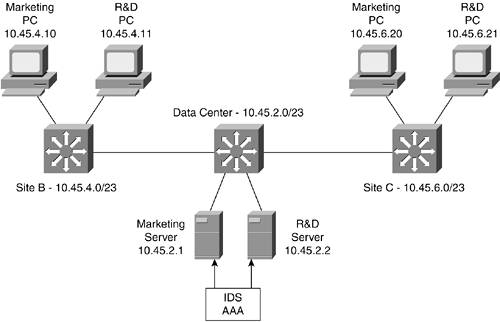
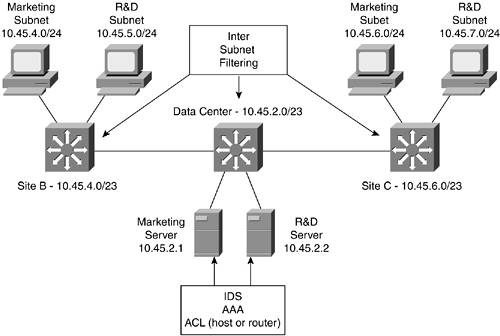
Figure 6-12. Application Security Plus L3 ACL Design
As you can see in Figure 6-11, this simplified diagram shows three sites, each with a /23 subnet of the 10 network. There are two main groups at these three sites, marketing and R&D. In this design, the servers and PCs for each of these groups share the same site-specific subnet. This means any security controls will be unable to take into account the IP address of the system attempting access.
In Figure 6-12, the same /23 subnet exists per site, but it has been further divided into two /24 subnets, one for each organization. This allows intersubnet filtering at the routed connection at each site. This filtering could be used in sites B and C to prevent the R&D and marketing departments from accessing each other's PCs and at the data center to ensure that only marketing PCs can access marketing servers and likewise for the R&D department.
TIP
This sort of filtering is referred to as role-based subnetting throughout the rest of this book.
Although the benefits of the approach shown in Figure 6-12 are pretty clear, this kind of design gets exponentially more difficult as the number of sites of different groups in an organization increase. Wireless features and the wired mobility of the workforce also affect the feasibility of this design. Technologies such as 802.1x (see Chapter 9) can make this easier but by no means solve all the problems.
Like any of the discussions in this book, every design decision should come back to the requirements of your security policy.
TIP
I have seen some designs that attempt to trunk VLANs throughout the sites of an organization. For example, consider if the design in Figure 6-12 had only two subnets, one for R&D and another for marketing. These subnets would need to exist at all three sites. The principal problem with this design is the need to trunk the VLANs at L2 throughout the organization. This increases the dependence on STP and could make the design more difficult to troubleshoot.
Route summarization is always something that sounds easy when you first design a network and gets harder and harder as the network goes into operation. The basic idea is to keep your subnet allocations contiguous per site so that your core routers need the smallest amount of routes in their tables to properly forward traffic. In addition to reducing the number of routes on your routers, route summarization also makes a network far easier to troubleshoot. In Figure 6-12, you can see a very simple example of route summarization. Sites B and C each have two /24 subnets, but they are contiguously addressed so they can be represented as one /23 subnet. These summarizations also help when writing ACLs since a large number of subnets can be identified with a single summarized ACL entry.
Ingress/Egress Filtering
Ingress/egress filtering is different from what you would normally call firewalling. Ingress/egress filtering is the process of filtering large classes of networks that have no business being seen at different parts of your network. Although ingress/egress can mean different things depending on your location, in this book ingress refers to traffic coming into your organization, and egress refers to traffic leaving it. Several types of traffic can be filtered in this way, including RFC 1918 addresses, RFC 2827 antispoof filtering, and nonroutable addresses. The next several sections discuss each option as well as a method of easily implementing filtering using a feature called verify unicast reverse path forwarding (uRPF).
RFC 1918
RFC 1918, which can be downloaded from http://www.ietf.org/rfc/rfc1918.txt, states that a block of addresses has been permanently set aside for use in private intranets. Many organizations today use RFC 1918 addressing inside their organizations and then use NAT to reach the public Internet. The addresses RFC 1918 sets aside are these:
10.0.0.010.255.255.255 (10/8 prefix)
172.16.0.0172.31.255.255 (172.16/12 prefix)
192.168.0.0192.168.255.255 (192.168/16 prefix)
The basic idea of RFC 1918 filtering is that there is no reason you should see RFC 1918 addressing from outside your network coming in. So, in a basic Internet design, you should block RFC 1918 addressing before it crosses your firewall or WAN router. An ACL on a Cisco router to block this traffic looks like this:
IOS(config)#access-list 101 deny ip 10.0.0.0 0.255.255.255 any log IOS(config)#access-list 101 deny ip 172.16.0.0 0.15.255.255 any log IOS(config)#access-list 101 deny ip 192.168.0.0 0.0.255.255 any log IOS(config)#access-list 101 permit ip any any IOS(config-if)#ip access-group 101 in
This ACL stops any traffic with a source IP address in the RFC 1918 range from entering your site. Also, your Internet service provider (ISP) should be blocking RFC 1918 addressing as well; check to make sure it is.
I had a conversation once with the administrator of a popular website who was the victim of a distributed denial of service (DDoS) attack that was launched entirely from RFC 1918 address space. If only his ISP had blocked this space, his website would have been unaffected. You can bet he had some choice words for the ISP after this attack!
One consideration with RFC 1918 addressing is the headaches it can cause when you need to connect to another organization that uses the same range of RFC 1918 addresses. This can happen through a merger or in an extranet arrangement. To at least slightly reduce the chances of this, pick addresses that aren't at the beginning of each major net range. For example, use 10.96.0.0/16, not 10.1.0.0/16.
RFC 2827
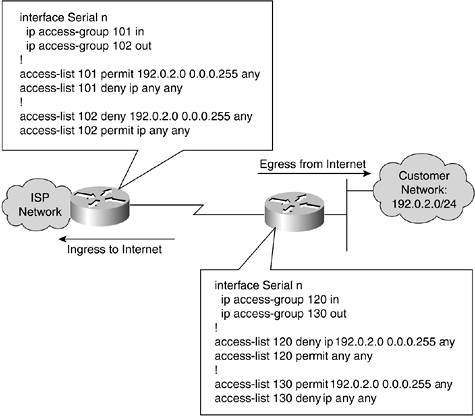
RFC 2827 defines a method of ingress and egress filtering based on the network that has been assigned to your organization. If your organization is assigned the 192.0.2.0/24 address, those are the only IP addresses that should be used in your network. RFC 2827 filtering can ensure that any packet that leaves your network has a source IP address of 192.0.2.0/24. It can also make sure that any packet entering your network has a source IP address other than 192.0.2.0/24. Figure 6-13 shows how this filtering could be applied both at the customer network and the ISP.
Figure 6-13. RFC 2827 Filtering
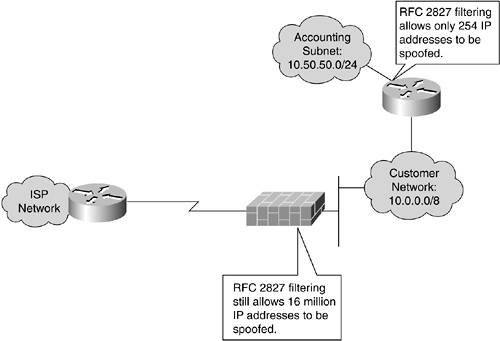
When implementing RFC 2827 filtering in your own network, it is important to push this filtering as close to the edge of your network as possible. Filtering at the firewall only might allow too many different spoofed addresses (thus complicating your own trace back). Figure 6-14 shows filtering options at different points in a network.
Figure 6-14. Distributed RFC 2827 Filtering
WARNING
Be careful about the potential performance implications of RFC 2827 filtering. Make sure the devices you are using support hardware ACLs if your performance requirements dictate that they must. Even with hardware ACLs, logging is generally handled by the CPU, which can adversely affect performance when you are under attack.
When using RFC 2827 filtering near your user systems and those systems that use DHCP, you must permit additional IP addresses in your filtering. Here are the details, straight from the source (RFC 2827):
If ingress filtering is used in an environment where DHCP or BOOTP is used, the network administrator would be well advised to ensure that packets with a source address of 0.0.0.0 and a destination of 255.255.255.255 are allowed to reach the relay agent in routers when appropriate.
If properly implemented, RFC 2827 can reduce certain types of IP spoofing attacks against your network and can also prevent IP spoofing attacks (beyond the local range) from being launched against others from your site. If everyone worldwide implemented RFC 2827 filtering, the Internet would be a much safer place because hiding behind IP spoofing attacks would be nearly impossible for attackers.
Nonroutable Networks
Besides private network addressing and antispoof filtering, there are a host of other networks that have no business being seen, including those that won't be seen for some time because they haven't yet been allocated. For example, at the time this was written, the /8 networks from 82 to 126 had not yet been allocated from the Internet Assigned Numbers Authority (IANA) to any of the regional Internet registries (RIRs). This data can be tracked at a very high level at the following URL: http://www.iana.org/assignments/ipv4-address-space.
IANA is responsible for allocating Internet Protocol version 4 (IPv4) address space to the RIRs; the RIRs then allocate address space to customers and ISPs. All of this is of interest to ISPs, which might try not to forward traffic from address space that has yet to be allocated. In doing so, they will reduce the available networks that attackers can use in spoofing attacks. Rob Thomas (founder of Cymru.com) maintains an unofficial page of something called "bogon" ranges. Bogon ranges are address ranges that have no business being seen on the Internet. They are either reserved, specified for some special use, or unallocated to any RIR. Filtering this comprehensive list of subnets can narrow the potential source of spoofed IP packets. Be aware that this list can change every few months, meaning these filters must also be periodically changed. Thomas's bogon list is available here: http://www.cymru.com/Documents/bogon-list.html.
WARNING
Be aware that, with all this filtering, you are making things more difficult for the attacker but not impossible. An attack tool could easily decide to spoof only address ranges that have been allocated. In fact, attackers have started to reduce the amount of attacks that they actually spoof traffic from. By compromising several other hosts around the world, they feel safe launching attacks from those remote systems directly.
For organizations unable to track the changing bogon list, RFC 3330 states some special subnets that can permanently be filtered from your network. They are the following:
- 0.0.0.0/8 This network refers to hosts on this network, meaning the network where the packet is seen. This range should be used only as a source address and should not be allowed in most situations except DHCP/Bootstrap Protocol (BOOTP) broadcast requests and other similar operations. It can certainly be filtered inbound and outbound from your Internet connection.
- 127.0.0.0/8 This subnet is home to the address 127.0.0.1, referring to localhost, or your machine. Packets should never be seen on networks sourced from the 127/8 network. RFC 3330 says it best: "No addresses within this block should ever appear on any network anywhere."
- 169.254.0.0/16 This subnet is reserved for hosts without access to DHCP to autoconfigure themselves to allow communications on a local link. You are safe in filtering this subnet on your network.
- 192.0.2.0/24 This subnet, commonly called the "TEST-NET," is a /24 subnet allocated for sample code and documentation. You might notice that some diagrams in this book use this address when a registered address is represented. You should never see this network in use anywhere.
- 198.18.0.0/15 This subnet has been set aside for performance benchmark testing as defined in RFC 2544. Legitimate network-attached devices should not use this address range, so it can be filtered.
- 224.0.0.0/4 This is the multicast range. On most networks, this can be filtered at your Internet edge, but obviously, if your network supports multicast, this would be a bad idea. In most cases, it is a bad idea to filter it internally because multicast addresses are used for many popular routing protocols.
- 240.0.0.0/4 This is the old Class E address space. Until IANA decides what to do with this space, it can be safely filtered at your Internet edge.
TIP
One thing to consider is that although filtering bogons or the subset listed in RFC 3330 is possible on your internal network, it isn't necessary. If you are properly implementing RFC 2827 filtering, you implicitly deny any network that is not your own, which would include all bogon ranges. Filtering bogons is most appropriate at your Internet edge, where you would also implement RFC 2827 and RFC 1918 filtering. Within your campus network, filtering with RFC 2827 is sufficient.
uRPF
A far easier way to implement RFC 2827 filtering is to use something that on Cisco devices is called verify unicast reverse path forwarding (uRPF). This functionality is available on multiple vendors' platforms, though it might be known by a different name. Cisco documentation for basic uRPF configuration can be found here: http://www.cisco.com/univercd/cc/td/doc/product/software/ios122/122cgcr/fsecur_c/fothersf/scfrpf.htm.
This filtering works by blocking inbound source IP addresses that don't have a route in the routing table pointing back at the same interface on which the packet arrived. To be more specific, uRPF checks the forwarding information base (FIB) that is created from the routing table on all Cisco devices running Cisco express forwarding (CEF). As such, uRPF works only on Cisco devices that support CEF. For example, consider the following situation:
|
1. |
A packet arrives on a router with a source IP address of 192.0.2.5 at interface Ethernet0/0. |
|
2. |
uRPF checks the FIB by doing a reverse lookup to determine whether the return path to the source IP address would use the same interface that the packet arrived on. If the best return path would use a different interface, the packet is dropped. |
|
3. |
If the best return path is the interface that the packet arrived on, the packet is forwarded toward its destination. |
If there are multiple best paths (as in the case of load balancing), uRPF will forward the packet as long as the interface the packet arrived on is in the list of best paths.
The syntax for uRPF is very simple:
IOS(config-if)#ip verify unicast reverse-path
Some additional options are available to provide more granularity in configuration. For example, ACLs that are evaluated when a uRPF check fails can be applied.
WARNING
Like RFC 2827, uRPF is most effective close to the edge of your network. This is because the edge of your network is the most likely location in your network to have routing symmetry (meaning packets arrive on the same interface that the return traffic will use). You should not deploy uRPF on interfaces that contain asymmetrically routed traffic, or legitimate traffic will be dropped.
For a service provider or a very large enterprise customer, there is an additional option called uRPF loose mode. (The previous mode is sometimes called strict mode.) Loose mode allows a packet to forward as long as there is a return route to the source somewhere in the FIB. This has the result of blocking the entire bogon list. I say "larger enterprise" here because you generally need the entire Border Gateway Protocol (BGP) routing table on your router before this is useful; otherwise, any spoofed packet will have an entry for the FIB because of the default route. When you have the entire BGP routing table on a device, you usually don't need a default route. The command for loose-mode uRPF looks like this:
IOS(config-if)# ip verify unicast source reachable-via any
There is also an allow-default flag that can be set, depending on whether you want the default route to be considered a valid route when making the uRPF decision.
NAT
Few technologies have generated as much discussion among security communities as NAT. The idea of translating private addresses to public addresses is seen by many as a good way for organizations without their own IP ranges to get on the Internet. Rather than address their internal network with the addresses provided by their ISP (thus making changing ISPs very difficult), they simply choose to translate RFC 1918 addresses as they leave the network. If you want a simple rule to follow, never use NAT in a security role. NAT is fine for its intended purpose: address translation. But if you have places in your network where your security relies on NAT, you probably need to reevaluate your design. If you agree with me and understand why, feel free to skip the rest of this section; if not, read on.
NAT can be done in three main ways: static translation is when an internal IP address corresponds to a specific external IP address. This is generally done for publicly accessible servers that must be reachable from the outside on a predictable IP address. One-to-one NAT, or basic NAT, is when an IP address inside corresponds to a single address on the outside selected from a pool. One day a system might get 192.0.2.10; another day it might get .11. Finally, many-to-one NAT (sometimes called port address translation [PAT] or NAT overload) is when a large number of private addresses can be translated to a single public IP address. This is a very popular use of NAT for organizations with limited public address space. All of their internal users can use a small number of public IP addresses.
There is little debate about the security benefits of the first two NAT options (static and one-to-one): simply put, there is none. Because each internal address corresponds to a single public address, an attacker would merely need to attack the public address to have that attack translated to the private address. Where the discussion comes in is about the benefits of many-to-one NAT. Although their numbers seem to be declining, there are some who believe that many-to-one NAT is a valuable security tool. The basic premise is this: when you are using many-to-one NAT, the NAT system keeps track of user connections from the inside to the outside by changing the source port number at Layer 4 (L4). When the return traffic comes back destined for that port number/IP address (with the right source IP address and port number), the NAT system translates the destination port number/IP address to the internal private host and sends the traffic.
This type of protection falls into the security-through-obscurity category outlined in Chapter 1, "Network Security Axioms." An attacker could do a number of things that would not be stopped by NAT:
- Send a Trojan application by e-mail (or a compromised web page) that opens a connection from the private host to the attacking host.
- Send data with the correct port number and IP address (with the right spoofed source port and IP address). This would require some trial and error on the part of the attacker, but it cannot be discounted in the event that the attacker is going after your network specifically.
- Allow outside connections. Although this isn't so much an attacker action, there are many applications on a host that open periodic connections with hosts on the Internet. NAT has no way of blocking connections from the inside out.
The specifics of when, where, and why to use NAT are general networking design issues, not security related. From a security perspective, I would have no reservations using public addresses for all of a network and not using NAT at all.
TIP
For teleworkers and home users, sometimes NAT might be the only network-level security technology available. In these cases, many-to-one NAT is certainly better than no network security technology. However, it is better to properly secure the hosts on a network and have no NAT than to have NAT without any host security protections.
Part I. Network Security Foundations
Network Security Axioms
- Network Security Axioms
- Network Security Is a System
- Business Priorities Must Come First
- Network Security Promotes Good Network Design
- Everything Is a Target
- Everything Is a Weapon
- Strive for Operational Simplicity
- Good Network Security Is Predictable
- Avoid Security Through Obscurity
- Confidentiality and Security Are Not the Same
- Applied Knowledge Questions
Security Policy and Operations Life Cycle
- Security Policy and Operations Life Cycle
- You Cant Buy Network Security
- What Is a Security Policy?
- Security System Development and Operations Overview
- References
- Applied Knowledge Questions
Secure Networking Threats
- Secure Networking Threats
- The Attack Process
- Attacker Types
- Vulnerability Types
- Attack Results
- Attack Taxonomy
- References
- Applied Knowledge Questions
Network Security Technologies
- Network Security Technologies
- The Difficulties of Secure Networking
- Security Technologies
- Emerging Security Technologies
- References
- Applied Knowledge Questions
Part II. Designing Secure Networks
Device Hardening
- Device Hardening
- Components of a Hardening Strategy
- Network Devices
- NIDS
- Host Operating Systems
- Applications
- Appliance-Based Network Services
- Rogue Device Detection
- References
- Applied Knowledge Questions
General Design Considerations
- General Design Considerations
- Physical Security Issues
- Layer 2 Security Considerations
- IP Addressing Design Considerations
- ICMP Design Considerations
- Routing Considerations
- Transport Protocol Design Considerations
- DoS Design Considerations
- References
- Applied Knowledge Questions
Network Security Platform Options and Best Deployment Practices
Common Application Design Considerations
- Common Application Design Considerations
- DNS
- HTTP/HTTPS
- FTP
- Instant Messaging
- Application Evaluation
- References
- Applied Knowledge Questions
Identity Design Considerations
- Identity Design Considerations
- Basic Foundation Identity Concepts
- Types of Identity
- Factors in Identity
- Role of Identity in Secure Networking
- Identity Technology Guidelines
- Identity Deployment Recommendations
- References
- Applied Knowledge Questions
IPsec VPN Design Considerations
- IPsec VPN Design Considerations
- VPN Basics
- Types of IPsec VPNs
- IPsec Modes of Operation and Security Options
- Topology Considerations
- Design Considerations
- Site-to-Site Deployment Examples
- IPsec Outsourcing
- References
- Applied Knowledge Questions
Supporting-Technology Design Considerations
- Supporting-Technology Design Considerations
- Content
- Load Balancing
- Wireless LANs
- IP Telephony
- References
- Applied Knowledge Questions
Designing Your Security System
- Designing Your Security System
- Network Design Refresher
- Security System Concepts
- Impact of Network Security on the Entire Design
- Ten Steps to Designing Your Security System
- Applied Knowledge Questions
Part III. Secure Network Designs
Edge Security Design
- Edge Security Design
- What Is the Edge?
- Expected Threats
- Threat Mitigation
- Identity Considerations
- Network Design Considerations
- Small Network Edge Security Design
- Medium Network Edge Security Design
- High-End Resilient Edge Security Design
- Provisions for E-Commerce and Extranet Design
- References
- Applied Knowledge Questions
Campus Security Design
- Campus Security Design
- What Is the Campus?
- Campus Trust Model
- Expected Threats
- Threat Mitigation
- Identity Considerations
- Network Design Considerations
- Small Network Campus Security Design
- Medium Network Campus Security Design
- High-End Resilient Campus Security Design
- References
- Applied Knowledge Questions
Teleworker Security Design
- Teleworker Security Design
- Defining the Teleworker Environment
- Expected Threats
- Threat Mitigation
- Identity Considerations
- Network Design Considerations
- Software-Based Teleworker Design
- Hardware-Based Teleworker Design
- Design Evaluations
- Applied Knowledge Questions
Part IV. Network Management, Case Studies, and Conclusions
Secure Network Management and Network Security Management
- Secure Network Management and Network Security Management
- Utopian Management Goals
- Organizational Realities
- Protocol Capabilities
- Tool Capabilities
- Secure Management Design Options
- Network Security Management Best Practices
- References
- Applied Knowledge Questions
Case Studies
- Case Studies
- Introduction
- Real-World Applicability
- Organization
- NetGamesRUs.com
- University of Insecurity
- Black Helicopter Research Limited
- Applied Knowledge Questions
Conclusions
- Conclusions
- Introduction
- Management Problems Will Continue
- Security Will Become Computationally Less Expensive
- Homogeneous and Heterogeneous Networks
- Legislation Should Garner Serious Consideration
- IP Version 6 Changes Things
- Network Security Is a System
References
Appendix A. Glossary of Terms
Appendix B. Answers to Applied Knowledge Questions
Appendix C. Sample Security Policies
INFOSEC Acceptable Use Policy
Password Policy
Guidelines on Antivirus Process
Index
EAN: 2147483647
Pages: 249
