Tuning Table Access
When retrieving data from a table, MySQL can basically follow one of two paths to locating the relevant rows:
- Read every row in the table concerned (a full table scan), and return only those rows that match the WHERE clause criteria.
- Use an index to find a subset of rows, and return the rows that match the WHERE clause criteria.
Unless we need to retrieve a substantial proportion of the rows from a table, we probably want to use an index. It should not come as a big surprise, therefore, that much of this section will address creating the best indexes for our queries.
20.1.1. Index Lookup Versus Full Table Scan
A common mistake made by those new to SQL tuning is to assume that it is always better to use an index to retrieve data. Typically, an index lookup requires three or four logical reads for each row returned. If we only have to traverse the index tree a few times, then that will be quicker than reading every row in that table. However, traversing the index tree for a large number of rows in the table could easily turn out to be more expensive than simply reading every row directly from the table.
For this reason, we generally want to use an index only when retrieving a small proportion of the rows in the table. The exact break-even point will depend on your data, your indexes, and maybe even your server configuration, but we have found that a reasonable rule of thumb is to use an index when retrieving no more 5-10% of the rows in a table.
To illustrate this point, consider a scenario in which we are trying to generate sales totals over a particular period of time. To get sales totals for the previous week, for example, we might execute a statement such as the following:
SELECT SUM( s.sale_value ),COUNT(*) FROM sales s WHERE sale_date>date_sub(curdate( ),INTERVAL 1 WEEK);
Since we have sales data for many years, we would guess that an index on sales_date would be effective in optimizing this queryand we would be right.
On the other hand, suppose that we want to get the sales totals for the preceding year. The query would look like this:
SELECT SUM( s.sale_value ),COUNT(*) FROM sales s WHERE sale_date>date_sub(curdate( ),INTERVAL 1 YEAR);
It is not immediately obvious that an index-driven retrieval would result in the best query performance; it depends on the number of years of data in the table and the relative volume of data for the preceding year. Luckily, MySQL will, in most situations, make a good determination in such cases, provided that you have given MySQL a good set of indexes with which to work.
The MySQL optimizer predicts when to use an index based on the percentage of data from the table it expects to retrieve given our WHERE clause. The optimizer chooses to use the index for small intervals, while relying on a full table scan for large intervals. This basic algorithm works well when the volume of data is evenly distributed for the different indexed values. However, if the data is not evenly distributed, or if the statistics on table sizing are inaccurate, then the MySQL optimizer may make a less than perfect decision.
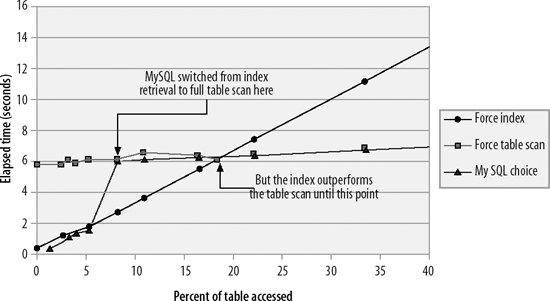
Figure 20-1 shows the elapsed time for retrieving various proportions of rows when forcing an index scan or a full table scan, or when allowing the MySQL optimizer to make that decision. In this example, MySQL switched from an index scan to a full table scan when the rows returned represented approximately 7% of the total. However, in this case, the index outperformed the table scan until about 17% of the rows were retrieved. So although MySQL made the correct decision in most cases, there were a few cases where forcing an index lookup would have improved performance.
Figure 20-1. Full table scan versus indexed lookup
|

There are a number of circumstances in which MySQL might not pick the best possible index. One of these circumstances is when the data is "skewed." In the preceding example, sales were fairly evenly distributed over a five-year period. However, in the real world this is unlikely to be truesales will be greater during certain periods (Christmas, perhaps) and we might hope that sales would increase over time. This "skewed" table data can make it harder for the MySQL optimizer to make the best decision.
If you think that your data may be skewed and that MySQL may choose a table scan or index inappropriately, you can use the USE INDEX, FORCE INDEX, or IGNORE INDEX optimizer hints , as appropriate, to force or suppress the index. Take care to only use these hints when absolutely necessary, as they can also prevent the MySQL optimizer from selecting the best plan if used inappropriately. These hints are explained in more detail later, in the section "Manually Choosing an Index."
It's also worth noting that it is sometimes possible to resolve a query using an index aloneprovided that the index contains all of the columns from the table that are referenced in both the SELECT and WHERE clauses. In this case, the index can be used in place of the table, and can perform very efficiently, even when retrieving a very large proportion (or all) of the rows in the table. See the section "Covering indexes " later in this chapter for more details.
20.1.2. How MySQL Chooses Between Indexes
In the above examples, MySQL switched between an index and a full table scan as the number of rows to be retrieved increased. This is a pretty neat trickjust how did MySQL work this out?
When you send a SQL statement to the MySQL server, MySQL has to parse the statement, which involves all of the following: verify that the SQL syntax is correct; ensure that the user has the necessary authority to run the statement; and determine the exact nature of the data to be retrieved. As part of this process, MySQL determines if any of the indexes defined on the table would help optimize the query.
The MySQL optimizer has a general sense of the "selectivity" of an indexhow many rows an average index lookup will returnand of the size of the table. The optimizer examines the index to work out how many rows will have to be used given the values in the WHERE clause and the range of values in the index. MySQL then calculates the relative overhead of using the index and compares this value to the overhead of scanning the full contents of the table.
For most queries, this simple but effective strategy allows MySQL to choose between a full table scan and an indexed lookup, or to choose between multiple candidate indexes.
20.1.3. Manually Choosing an Index
You can add hints to your SQL statement to influence how the optimizer will choose between various indexing options. You should only do this if you have determined that MySQL is not making the optimal decision on index utilization. These hints can appear after the table name within the FROM clause. The three hints are:
USE INDEX( list_of_indexes)
Tells MySQL to consider only the indexes listed (i.e., to ignore all other indexes)
IGNORE INDEX( list_of_indexes)
Tells MySQL to ignore any of the listed indexes when determining the execution plan
FORCE INDEX( list_of_indexes)
Tells MySQL to use one of the listed indexes even if it has determined that a full table scan would be more efficient
For instance, to force the use of an index named sales_i_date, we could write a query as follows:
SELECT SUM( s.sale_value ),count(*) FROM sales s FORCE INDEX(sales_i_date) WHERE sale_date>date_sub(curdate( ),INTERVAL 1 WEEK);
20.1.4. Prefixed ("Partial") Indexes
MySQL allows you to create an index based on the first few characters of a column. For instance, the following statement creates an index based on the first four bytes of the customer's address:
CREATE INDEX i_cust_name_l4 on customers(address1(4));
Partial indexes generally use less storage than "full" indexes, and in some cases may actually improve performance, since a smaller index is more likely to fit into the MySQL memory cache. However, we encourage you to create partial indexes with great care. A very short partial index may actually be worse than no index at all. For very long columns, the partial index might be as good as the full indexit all depends on how many bytes you need to read to get an exact match on the column concerned.
For instance, consider searching for a customer by address, as follows:
SELECT * FROM customers WHERE address1 = '1000 EXCEPTIONABLE STREET';
There might be plenty of customers that have an address starting with '1000'. Many fewer will have an address starting with '1000 E', and by the time we extend the search to '1000 EX', we might be matching only a single customer. As we extend the length of the partial index, it becomes more "selective" and more likely to match the performance of a full index.
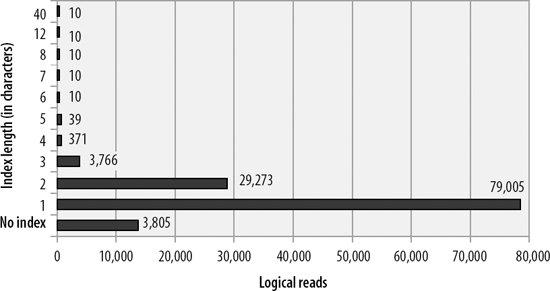
Figure 20-2 shows the results of doing the above search for various prefix lengths. For this data, prefix lengths of 1 or 2 are worse than no index at all; a length of 3 is slightly better than no index; while lengths greater than 3 are quite effective. Once the length hits 6, no further increase in the length of the prefix increased the effectiveness of the index. Remember that the optimum length for your prefixed index depends entirely on the data item you are searching forin this case, short prefixes did not work well because most addresses started with street numbers that were not very selective. For more selective datasurname for instanceprefixed indexes could be much more effective.
Figure 20-2. Performance of "partial" indexes of various lengths
20.1.5. Concatenated Indexes
A concatenated indexoften called a composite indexis an index that is created on multiple columns. For instance, if we frequently retrieve customers by name and date of birth, we might create an index as follows:
CREATE INDEX i_customers_first_surname_dob ON customers(contact_surname, contact_firstname,date_of_birth);
There is very little chance that two customers would have the same first name, surname, and date of birth, so use of this index would almost always take us to a single, correct customer. If you find that you frequently need to query against the same set of multiple columns' values on a table, then a concatenated index based on those columns should help you optimize your queries.
|
For instance, to optimize the following query, we should probably create a concatenated index on customer_id, product_id, and sales_rep_id:
SELECT count(*), SUM(quantity) FROM sales WHERE customer_id=77 AND product_id=90 AND sales_rep_id=61;
This index would be defined as follows:
CREATE INDEX I_sales_cust_prod_rep ON sales(customer_id,product_id,sales_rep_id);
We can use a concatenated index to resolve queries where only some of the columns in the index are specified, provided that at least one of the "leading" columns in the index is included.
For instance, if we create an index on (surname,firstname,date_of_birth), we can use that index to search on surname or on surname and firstname, but we cannot use it to search on date_of_birth. Given this flexibility, organize the columns in the index in an order that will support the widest range of queries. Remember that you can rarely afford to support all possible indexes because of the overhead indexes add to DML operationsso make sure you pick the most effective set of indexes.
|
20.1.5.1. Merging multiple indexes
While a concatenated index on all the columns in the WHERE clause will almost always provide the best performance, sometimes the sheer number of column combinations will prevent us from creating all of the desirable concatenated indexes.
For instance, consider the sales table in our sample database. We may want to support queries based on any combination of customer_id, product_id, and sales_rep_idthat would only require four indexes. Add another column and we would need at least six indexes. All of these indexes take up space in the database andperhaps worseslow down inserts, updates, and deletes. Whenever we insert or delete a row, we have to insert or delete the index entry as well. If we update an indexed column, we have to update the index as well.
If you can't create all of the necessary indexes, do not despair. MySQL 5.0 can merge multiple indexes quite effectively. So instead of creating a concatenated index on the three columns, we could create indexes on each of the columns concerned. MySQL will merge rows retrieved from each index to find only those rows matching all conditions.
Index merges can be identified by the index_merge access type in the EXPLAIN statement output. All the indexes being merged will be listed in the keys column, and the Extra column will include a Using intersect clause with the indexes being merged listed. Example 20-1 shows the EXPLAIN output for a query that performs an index merge.
Example 20-1. Example of an index merge
SELECT count(*), SUM(quantity) FROM sales WHERE customer_id=77 AND product_id=90 AND sales_rep_id=61 Explain plan ------------ ID=1 Table=sales Select type=SIMPLE Access type=index_merge Rows=1 Possible keys=i_sales_customer,i_sales_product,i_sales_rep Key=i_sales_rep,i_sales_customer,i_sales_product Length=9 Ref= Extra=Using intersect(i_sales_rep, i_sales_customer,i_sales_product); Using where |
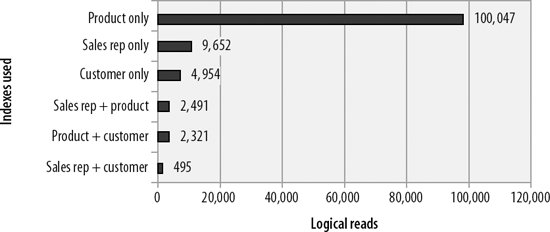
Not all index merges are equal; just as indexes on different columns will have different performance characteristics (due to their selectivity), different combinations of merged indexes will yield the best result. Figure 20-3 shows the performance for the three possible single-column indexes created to support our example query, and shows the performance of each possible merge of two indexes. As you can see, the best result was obtained by merging the two most selective indexes.
Figure 20-3. Comparison of various single-column indexes and index merge performance
20.1.5.2. Covering indexes
Creating a covering index is a very powerful technique for squeezing the last drop of performance from your indexes. If there are only a few columns in the SELECT clause that are not also in the WHERE clause, you can consider adding these columns to the index. MySQL will then be able to resolve the query using the index alone, avoiding the I/Os involved in retrieving the rows from the table. Such an index is sometimes called a covering index.
For our previous example, if we add the quantity column to the index, our query can be resolved from the index alone. In the EXPLAIN output, the ExTRa column will include the tag Using index to indicate that the step was resolved using only the index, as in Example 20-2.
Example 20-2. Using a covering index
SELECT count(*), SUM(quantity) FROM sales WHERE customer_id=77 AND product_id=90 AND sales_rep_id=61 Explain plan ------------ ID=1 Table=sales Select type=SIMPLE Access type=ref Rows=1 Possible keys=i_sales_cust_prod_rep_quant Key=i_sales_cust_prod_rep_quant Length=27 Ref=const,const,const Extra=Using index |
For queries that retrieve only a single row, the savings gained by covering indexes are probably going to be hard to notice. However, when scanning multiple rows from a table, the cost savings add up rapidly. In fact, it is often quicker to use a covering index to return all the rows from a table than to perform a full table scan. Remember that for normal indexed retrieval, the (very rough) rule of thumb is that the index probably isn't worth using unless you are accessing maybe 10% of the rows in the table. However, a covering index might be appropriate even if all of the rows are being read.
|
20.1.6. Comparing the Different Indexing Approaches
Figure 20-4 summarizes the performance of the various options for resolving our sample query (retrieving sales totals for a specific sales rep, customer, and product). Even for this simple query, there is a wide range of indexing options; in fact, we did not try every possible indexing option. For example, we didn't try a concatenated index on product_id + sales_rep_id.
There are a several key lessons to be learned from these examples:
Not all index plans are equal
Novice SQL programmers are often satisfied once they see that the EXPLAIN output shows that an index is being used. However, there is a huge difference between the performance provided by the "best" and the "worst" index (in this example, the worst index was more than 10,000 times more expensive than the best index!).
Concatenated indexes rule
The best possible index for any particular table access with more than one column in the WHERE clause will almost always be a concatenated index.
Think about over-indexing
If the SELECT list contains only a few columns beyond those in the WHERE clause, it is probably worth adding these to the index.
Remember that indexes come at a cost
Indexes are often essential to achieve decent query performance, but they will slow down every INSERT and DELETE and many UPDATE operations. You need to make sure that every index is "paying its way" by significantly improving query performance.
Rely on merge joins to avoid huge numbers of concatenated indexes
If you have to support a wide range of column combinations in the WHERE clause, create concatenated indexes to support the most common queries, and single-column indexes that can be merged to support less common combinations.
Figure 20-4. Comparison of different indexing techniques when retrieving sales total for specific product, customer, and sales rep

20.1.7. Avoiding Accidental Table Scans
There are a few circumstances in which MySQL might perform a full table scan even if a suitable index exists and perhaps even after you instruct MySQL to use an index with the FORCE INDEX hint. The three main reasons for such "accidental" table scans are:
- You modify an indexed column in the WHERE clause with a function or an operator.
- You are searching for a substring within an indexed column.
- You are using only some of the columns within a concatenated index, and the order of columns in the index does not support searching on the columns you have specified.
Let's look at each situation in the following sections.
20.1.7.1. Accidentally suppressing an index using a function
One of the most common causes for what might appear to be an inexplicable refusal by MySQL to use an index is some kind of manipulation of the query column.
For instance, let's suppose that we are trying to find all customers that are older than 55 (we might want to target them for a specific sales campaign). We have an index on date_of_birth and the index is certainly selective, but MySQL does not use the index, as shown in Example 20-3.
Example 20-3. Index suppressed by function on query column
SELECT * FROM customers WHERE (datediff(curdate( ),date_of_birth)/365.25) >55 Short Explain ------------- 1 SIMPLE select(ALL) on customers using no key Using where |
The problem here is that by enclosing the date_of_birth column within the DATEDIFF function, we prevent MySQL from looking up values in the index. If we rewrite the query so that the functions are applied to the search value rather than the search column, we see that the index can be used, as shown in Example 20-4.
Example 20-4. Applying a function to the search value does not suppress the index
SELECT * FROM customers WHERE date_of_birth < date_sub(curdate( ),interval 55 year) Short Explain ------------- 1 SIMPLE select(range) on customers using i_customer_dob Using where |
|
20.1.7.2. Accidentally suppressing an index using a substring
Another way to suppress an index on a column is to search on a nonleading substring of the column. For instance, indexes can be used to find the leading segments of a column, as shown in Example 20-5.
Example 20-5. Indexes can be used to search for a leading portion of a string
SELECT * FROM customers WHERE customer_name like 'HEALTHCARE%' Short Explain ------------- 1 SIMPLE select(range) on customers using i_customer_name Using where |
But we can't use the index to find text strings in the middle of the column, as demonstrated in Example 20-6.
Example 20-6. Indexes can't be used to find nonleading substrings
SELECT * FROM customers WHERE customer_name LIKE '%BANK%' Short Explain ------------- 1 SIMPLE select(ALL) on customers using no key Using where |
|
20.1.7.3. Creating concatenated indexes with a poor column order
Another time we might experience an accidental table scan is when we expect a concatenated index to support the query, but we are not specifying one of the leading columns of the index. For instance, suppose that we created an index on customers as follows:
CREATE INDEX i_customer_contact ON customers(contact_firstname, contact_surname)
It might seem natural to create this index with firstname before surname, but that is usually a poor choice, since concatenated indexes can only be used if the leading columns appear in the query, and it is more common to search on surname alone than on firstname alone.
For instance, the index can support a query to find a customer by contact_firstname:
SELECT * FROM customers WHERE contact_firstname='DICK' Short Explain ------------- 1 SIMPLE select(ref) on customers using i_customer_contact Using where
But MySQL cannot use the index if only contact_surname is specified:
SELECT * FROM customers WHERE contact_surname='RADFORD' Short Explain ------------- 1 SIMPLE select(ALL) on customers using no key Using where
We probably should have created the index as (contact_surname,contact_firstname) if we need to support searching by surname only. If we want to support searching whenever either the surname or the firstname appears alone, then we will need an additional index.
|
20.1.8. Optimizing Necessary Table Scans
We don't necessarily want to avoid a full table scan at all cost. For instance, we might choose not to create an index to support a unique query that only runs once every month if that index would degrade UPDATE and INSERT statements that are being executed many times a second.
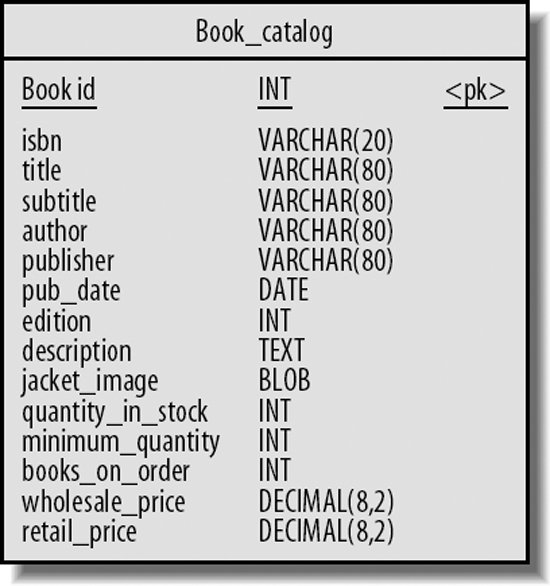
Furthermore, sometimes the nature of our queries leaves no alternative to performing a full table scan. For instance, consider an online book store that maintains a database of books in stock. One of the key tables might contain a row for each individual book, as shown in Figure 20-5.
Figure 20-5. Single-table book catalog
Every day, an inventory report is run that summarizes inventory and outstanding orders. The core of the report is the SQL shown in Example 20-7.
Example 20-7. SQL for inventory report example
SELECT publisher, SUM(quantity_in_stock) on_hand_quantity, SUM(quantity_in_stock*wholesale_price) on_hand_value, SUM(books_on_order) books_on_order, SUM(books_on_order*wholesale_price) order_value FROM book_catalog GROUP BY publisher Short Explain ------------- 1 SIMPLE select(ALL) on book_catalog using no key Using temporary; Using filesort |
There is no WHERE clause to optimize with an index, so (we might think) there is no alternative to a full table scan. Nevertheless, the person who determines whether or not we get a raise this year strongly encourages us to improve the performance of the query. So what are we going to do?
If we must read every row in the table, then the path to improved performance is to decrease the size of that table. There are at least two ways of doing this:
- Move any large columns not referenced in the query to another table (provided that this doesn't degrade other critical queries).
- Create an index based on all of the columns referenced in the query. MySQL can then use the index alone to satisfy the query.
Let's consider splitting the table as a first option. We can see in Figure 20-5 that the book_catalog table contains both a BLOB column containing a picture of the book's cover and a TEXT column containing the publisher's description of the book. Both of these columns are large and do not appear in our query. Furthermore, it turns out that these columns are never accessed by a full table scanthe only time the description and cover picture are accessed is when a customer pulls up the details for a single book on the company's web site.
It therefore may make sense to move the BLOB and TEXT columns to a separate table. They can be quickly retrieved via index lookup when required, while their removal will make the main table smaller and quicker to scan. The new two-table schema is shown in Figure 20-6.
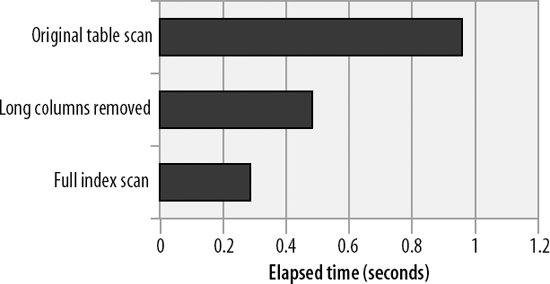
Removing the BLOB and TEXT columns reduced the size of the table by about 60% and more than halved the time required to perform a full table scan (see Figure 20-7).
Another option to consider when faced with a seemingly unavoidable full table scan is to create an index on the columns concerned and resolve the query with an index
Figure 20-6. Two-column book schema
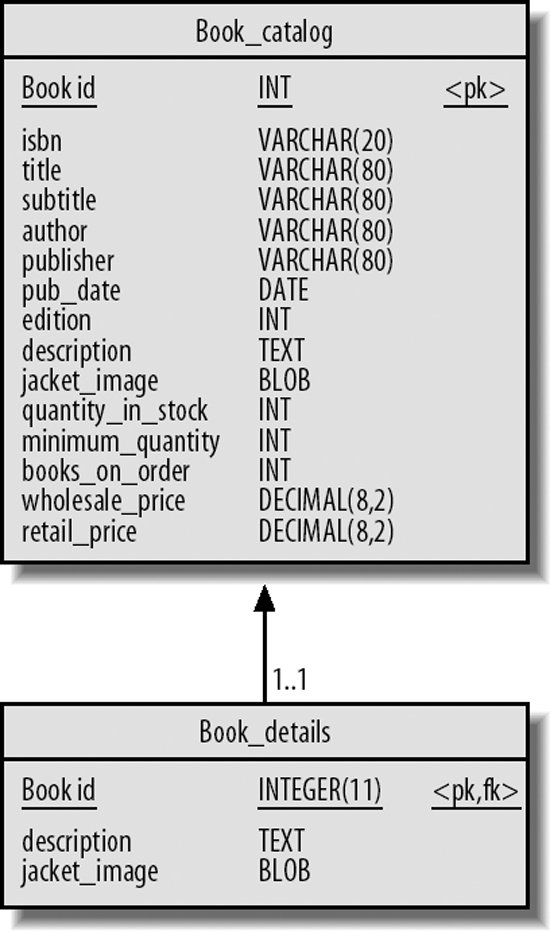
Figure 20-7. Optimizing a full table scan by removing long columns or using a full index scan
scan rather than a table scan. The index is likely to be smaller than the table. For our example report, we could create an index as follows:
CREATE INDEX i_book_inventory ON book_catalog (publisher,quantity_in_stock,wholesale_price,books_on_order)
The EXPLAIN output (which follows) shows that now only the index is used to resolve the query (as shown by the Using index note in the Extra column), and, as we can see in Figure 20-7, this results in even better performance than removing the large columns from the original table.
SELECT publisher, SUM(quantity_in_stock) on_hand_quantity, SUM(quantity_in_stock*wholesale_price) on_hand_value, SUM(books_on_order) books_on_order, SUM(books_on_order*wholesale_price) order_value FROM book_catalog GROUP BY publisher Short Explain ------------- 1 SIMPLE select(index) on book_catalog using i_book_inventory Using index
One of the reasons that the index performs so well in this case is that MySQL uses the index to optimize the GROUP BY clause. Previous examples all created and sorted temporary tables (shown by Using temporary;using filesort in the EXPLAIN output). Because the leading column of the index was publisher, and because this column is also the column to be sorted to support the GROUP BY clause, no sort was required. We'll discuss the topic of optimizing GROUP BY and ORDER BY using indexes in detail in the next chapter.
20.1.9. Using Merge or Partitioned Tables
Sometimes we are faced with queries that retrieve a proportion of the table that is too high to be optimized by an index, but that is still only a fraction of that table's total. For instance, we might want to optimize a query that retrieves sales data for a particular year. An index to support such a query might return too high a percentage of rows in the table and actually take longer than a full table scan.
One possible way to optimize this scenario is to create a separate table for each year's sales, so that we are able to retrieve data for a particular year from the particular table, thus avoiding the overhead of scanning all of our sales data.
Separate tables for each year would make application code fairly awkward; the programmer would need to know which table to use for a given query, and we would have to provide some way to retrieve data for all years when necessary. To avoid this problem, MyISAM offers merge tables. A MyISAM merge table is a logical table that comprises multiple real tables that are UNIONed together. You can insert into a merge table (provided that the INSERT_METHOD is not set to NO), and you can query from it as you would a normal table.
For instance, we could create separate sales tables for each year, as shown in Example 20-8.
Example 20-8. Creating MyISAM merge tables
CREATE TABLE SALES2000 TYPE=MYISAM AS SELECT * FROM sales WHERE sale_date BETWEEN '2000-01-01' AND '2000-12-31'; CREATE TABLE SALES2001 TYPE=MYISAM AS SELECT * FROM sales WHERE sale_date BETWEEN '2001-01-01' AND '2001-12-31'; . . . Create other "year" tables . . . CREATE TABLE all_sales (sales_id INT(8) NOT NULL PRIMARY KEY, . . . Other column definitions . . . Gst_flag NUMERIC(8,0)) TYPE=MERGE UNION=(sales_pre_2000,sales2001,sales2002, sales2003,sales2004,sales2005,sales2006) INSERT_METHOD=LAST ; |
If we need to obtain sales data for a particular year, we can do so fairly quickly by accessing one of the merge table's constituents directly. For queries that span year boundaries, we can access the merge table itself. We also have the advantage of being able to purge old rows very quickly by rebuilding the merge table without the unwanted years and then dropping the old table.
However, you should bear in mind that when you access the merge table directly, you will experience an additional overhead as MySQL merges the individual tables into a logical whole. This means that scanning the merge table will take substantially longer than scanning a single table containing all of the necessary data.
In MySQL 5.1 (which is alpha as we finalize this chapter), we can create a partitioned table to provide a similar solution to merge tables , as well as to provide other management and performance advantages. Example 20-9 shows the syntax for creating a MySQL 5.1 partitioned table that is similar to the MyISAM merge table created in the previous example.
Example 20-9. Creating MySQL 5.1 partitioned tables
CREATE TABLE sales_partitioned ( sales_id INTEGER NOT NULL, customer_id INTEGER NOT NULL, product_id INTEGER NOT NULL, sale_date DATE NOT NULL, quantity INTEGER NOT NULL, sale_value DECIMAL (8,0) NOT NULL ) ENGINE=InnoDB PARTITION BY RANGE (YEAR(sale_date)) ( PARTITION p_sales_pre2000 VALUES LESS THAN (2000), PARTITION p_sales_2000 VALUES LESS THAN (2001), PARTITION p_sales_2001 VALUES LESS THAN (2002), PARTITION p_sales_2002 VALUES LESS THAN (2003), PARTITION p_sales_2003 VALUES LESS THAN (2004), PARTITION p_sales_2004 VALUES LESS THAN (2005), PARTITION p_sales_2005 VALUES LESS THAN (2006), PARTITION p_sales_2006 VALUES LESS THAN (2007) ) ; |
If we issue a query that requires data from only one of the partitions, MySQL will be able to eliminate unnecessary partitions from the scan, allowing us to rapidly retrieve information for an individual year. Partitioned tables offer a host of other performance advantages, such as rapid purging of stale data, parallel processing of large result sets, and easier distribution of I/O across multiple disk devices. Partitioning is one of the major new features of MySQL 5.1.
Part I: Stored Programming Fundamentals
Introduction to MySQL Stored Programs
- Introduction to MySQL Stored Programs
- What Is a Stored Program?
- A Quick Tour
- Resources for Developers Using Stored Programs
- Some Words of Advice for Developers
- Conclusion
MySQL Stored Programming Tutorial
- MySQL Stored Programming Tutorial
- What You Will Need
- Our First Stored Procedure
- Variables
- Parameters
- Conditional Execution
- Loops
- Dealing with Errors
- Interacting with the Database
- Calling Stored Programs from Stored Programs
- Putting It All Together
- Stored Functions
- Triggers
- Calling a Stored Procedure from PHP
- Conclusion
Language Fundamentals
- Language Fundamentals
- Variables, Literals, Parameters, and Comments
- Operators
- Expressions
- Built-in Functions
- Data Types
- MySQL 5 Strict Mode
- Conclusion
Blocks, Conditional Statements, and Iterative Programming
- Blocks, Conditional Statements, and Iterative Programming
- Block Structure of Stored Programs
- Conditional Control
- Iterative Processing with Loops
- Conclusion
Using SQL in Stored Programming
- Using SQL in Stored Programming
- Using Non-SELECT SQL in Stored Programs
- Using SELECT Statements with an INTO Clause
- Creating and Using Cursors
- Using Unbounded SELECT Statements
- Performing Dynamic SQL with Prepared Statements
- Handling SQL Errors: A Preview
- Conclusion
Error Handling
- Error Handling
- Introduction to Error Handling
- Condition Handlers
- Named Conditions
- Missing SQL:2003 Features
- Putting It All Together
- Handling Stored Program Errors in the Calling Application
- Conclusion
Part II: Stored Program Construction
Creating and Maintaining Stored Programs
- Creating and Maintaining Stored Programs
- Creating Stored Programs
- Editing an Existing Stored Program
- SQL Statements for Managing Stored Programs
- Getting Information About Stored Programs
- Conclusion
Transaction Management
- Transaction Management
- Transactional Support in MySQL
- Defining a Transaction
- Working with Savepoints
- Transactions and Locks
- Transaction Design Guidelines
- Conclusion
MySQL Built-in Functions
- MySQL Built-in Functions
- String Functions
- Numeric Functions
- Date and Time Functions
- Other Functions
- Conclusion
Stored Functions
- Stored Functions
- Creating Stored Functions
- SQL Statements in Stored Functions
- Calling Stored Functions
- Using Stored Functions in SQL
- Conclusion
Triggers
Part III: Using MySQL Stored Programs in Applications
Using MySQL Stored Programs in Applications
- Using MySQL Stored Programs in Applications
- The Pros and Cons of Stored Programs in Modern Applications
- Advantages of Stored Programs
- Disadvantages of Stored Programs
- Calling Stored Programs from Application Code
- Conclusion
Using MySQL Stored Programs with PHP
- Using MySQL Stored Programs with PHP
- Options for Using MySQL with PHP
- Using PHP with the mysqli Extension
- Using MySQL with PHP Data Objects
- Conclusion
Using MySQL Stored Programs with Java
- Using MySQL Stored Programs with Java
- Review of JDBC Basics
- Using Stored Programs in JDBC
- Stored Programs and J2EE Applications
- Using Stored Procedures with Hibernate
- Using Stored Procedures with Spring
- Conclusion
Using MySQL Stored Programs with Perl
- Using MySQL Stored Programs with Perl
- Review of Perl DBD::mysql Basics
- Executing Stored Programs with DBD::mysql
- Conclusion
Using MySQL Stored Programs with Python
- Using MySQL Stored Programs with Python
- Installing the MySQLdb Extension
- MySQLdb Basics
- Using Stored Programs with MySQLdb
- A Complete Example
- Conclusion
Using MySQL Stored Programs with .NET
- Using MySQL Stored Programs with .NET
- Review of ADO.NET Basics
- Using Stored Programs in ADO.NET
- Using Stored Programs in ASP.NET
- Conclusion
Part IV: Optimizing Stored Programs
Stored Program Security
- Stored Program Security
- Permissions Required for Stored Programs
- Execution Mode Options for Stored Programs
- Stored Programs and Code Injection
- Conclusion
Tuning Stored Programs and Their SQL
- Tuning Stored Programs and Their SQL
- Why SQL Tuning Is So Important
- How MySQL Processes SQL
- SQL Tuning Statements and Practices
- About the Upcoming Examples
- Conclusion
Basic SQL Tuning
- Basic SQL Tuning
- Tuning Table Access
- Tuning Joins
- Conclusion
Advanced SQL Tuning
- Advanced SQL Tuning
- Tuning Subqueries
- Tuning Anti-Joins Using Subqueries
- Tuning Subqueries in the FROM Clause
- Tuning ORDER and GROUP BY
- Tuning DML (INSERT, UPDATE, DELETE)
- Conclusion
Optimizing Stored Program Code
- Optimizing Stored Program Code
- Performance Characteristics of Stored Programs
- How Fast Is the Stored Program Language?
- Reducing Network Traffic with Stored Programs
- Stored Programs as an Alternative to Expensive SQL
- Optimizing Loops
- IF and CASE Statements
- Recursion
- Cursors
- Trigger Overhead
- Conclusion
Best Practices in MySQL Stored Program Development
EAN: 2147483647
Pages: 208
