Tuning Subqueries in the FROM Clause
It is possible to include subqueries within the FROM clause of a SQL statement. Such subqueries are sometimes called unnamed views , derived tables , or inline views .
For instance, consider the query in Example 21-10, which retrieves a list of employees and department details for employees older than 55 years.
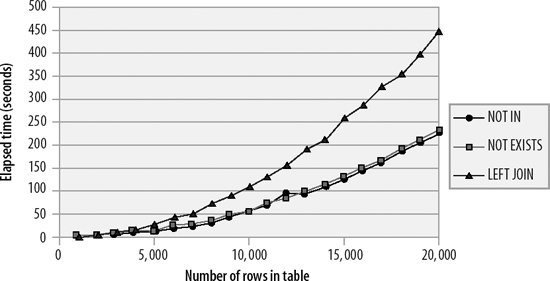
Figure 21-7. Scalability of various anti-join techniques (no index)
Example 21-10. Example SQL suitable for rewrite with an inline view
SELECT departments.department_name,employee_id,surname,firstname FROM departments JOIN employees USING (department_id) WHERE employees.date_of_birth |
This query is well optimizedan index on date of birth finds the customers, and the primary key index is used to find the department name on the departments table. However, we could write this query using inline views in the FROM clause, as shown in Example 21-11.
Example 21-11. SQL rewritten with an inline view
SELECT departments.department_name,employee_id,surname,firstname FROM (SELECT * FROM departments ) departments JOIN (SELECT * FROM employees) employees USING (department_id) WHERE employees.date_of_birthderived2> using no key 1 PRIMARY select(ALL) on using no key Using where 3 DERIVED select(ALL) on employees using no key 2 DERIVED select(ALL) on departments using no key |
This execution plan is somewhat different from those we have looked at in previous examples, and it warrants some explanation. The first two steps indicate that a join was performed between two "derived" tablesour subqueries inside the FROM clause. The next two steps show how each of the derived tables was created. Note that the name of the table, for instanceindicates the ID of the step that created it. So we can see from the plan that was created from a full table scan of departments.
Derived tables are effectively temporary tables created by executing the SQL inside the subquery. You can imagine that something like the following SQL is being executed to create the table:
CREATE TEMPORARY TABLE derived2 AS SELECT * FROM departments
Simply by using subqueries in the FROM clause, we have substantially weakened MySQL's chances of implementing an efficient join. MySQL must first execute the subqueries' statements to create the derived tables and then join those two derived tables. Derived tables have no indexes, so this particular rewrite could not take advantage of the indexes that were so effective in our original query (shown in Example 21-10). In this case, both the index to support the WHERE clause and the index supporting the join were unusable.
We could improve the query by moving the WHERE clause condition on employees into the subquery, as shown in Example 21-12.
Example 21-12. Rewritten SQL using an inline view
SELECT departments.department_name,employee_id,surname,firstname FROM (SELECT * FROM departments ) departments JOIN (SELECT * FROM employees WHERE employees.date_of_birth derived3> using no key 1 PRIMARY select(ALL) on <derived2> using no key Using where 3 DERIVED select(range) on employees using i_employee_dob Using where 4 DERIVED select(ALL) on departments using no key |
This plan at least allows us to use an index to find the relevant customers, but still prevents the use of an index to join those rows to the appropriate department.
|

21.3.1. Using Views
A view can be thought of as a "stored query". A view definition essentially creates a named definition for a SQL statement that can then be referenced as a table in other SQL statements. For instance, we could create a view on the sales table that returns only sales for the year 2004, as shown in Example 21-13.
Example 21-13. View to return sales table data for 2004
CREATE OR REPLACE VIEW v_sales_2004 (sales_id,customer_id,product_id,sale_date, quantity,sale_value,department_id,sales_rep_id,gst_flag) AS SELECT sales_id,customer_id,product_id,sale_date, quantity,sale_value,department_id,sales_rep_id,gst_flag FROM sales WHERE sale_date BETWEEN '2004-01-01' AND '2004-12-31' |
The CREATE VIEW syntax includes an ALGORITHM clause, which defines how the view will be processed at runtime:
CREATE [ALGORITHM = {UNDEFINED | MERGE
| TEMPTABLE}] VIEW viewname
The view algorithm may be set to one of the following:
TEMPTABLE
MySQL will process the view in very much the same way as a derived tableit will create a temporary table using the SQL associated with the view, and then use that temporary table wherever the view name is referenced in the original query.
MERGE
MySQL will attempt to merge the view SQL into the original query in an efficient manner.
UNDEFINED
Allows MySQL to choose the algorithm, which results in MySQL using the MERGE technique when possible.
Because the TEMPTABLE algorithm uses temporary tableswhich will not have associated indexesits performance will often be inferior to native SQL or to SQL that uses a view defined with the MERGE algorithm.
Consider the SQL query shown in Example 21-14; it uses the view definition from Example 21-13 and adds some additional WHERE clause conditions. The view WHERE clause, as well as the additional WHERE clauses in the SQL, is supported by the index i_sales_date_prod_cust, which includes the columns customer_id, product_id, and sale_date.
Example 21-14. SQL statement that references a view
SELECT SUM(quantity),SUM(sale_value) FROM v_sales_2004_merge WHERE customer_id=1 AND product_id=1; |
This query could have been written in standard SQL, as shown in Example 21-15.
Example 21-15. Equivalent SQL statement without a view
SELECT SUM(quantity),SUM(sale_value) FROM sales WHERE sale_date BETWEEN '2004-01-01' and '2004-12-31' AND customer_id=1 AND product_id=1 |
Alternately, we could have written the SQL using a derived table approach, as shown in Example 21-16.
Example 21-16. Equivalent SQL statement using derived tables
SELECT SUM(quantity),SUM(sale_value) from (SELECT * FROM sales WHERE sale_date BETWEEN '2004-01-01' AND '2004-12-31') sales WHERE customer_id=1 AND product_id=1; |
We now have four ways to resolve the queryusing a MERGE algorithm view, using a TEMPTABLE view, using a derived table, and using a plain old SQL statement. So which approach will result in the best performance?
Based on our understanding of the TEMPTABLE and MERGE algorithms, we would predict that a MERGE view would behave very similarly to the plain old SQL statement, while the TEMPTABLE algorithm would behave similarly to the derived table approach. Furthermore, we would predict that neither the TEMPTABLE nor the derived table approach would be able to leverage our index on product_id, customer_id, and sale_date, and so both will be substantially slower.
Our predictions were confirmed. The SQLs that used the TEMPTABLE and the derived table approaches generated very similar EXPLAIN output, as shown in Example 21-17. In each case, MySQL performed a full scan of the sales table in order to create a temporary "derived" table containing data for 2004 only, and then performed a full scan of that derived table to retrieve rows for the appropriate product and customer.
Example 21-17. Execution plan for the derived table and TEMPTABLE view approaches
Short Explain ------------- 1 PRIMARY select(ALL) on using no key Using where 2 DERIVED select(ALL) on sales using no key Using where |
An EXPLAIN EXTENDED revealed that the MERGE view approach resulted in a rewrite against the sales table, as shown in Example 21-18.
Example 21-18. How MySQL rewrote the SQL to "merge" the view definition
SELECT sum('prod'.'sales'.'QUANTITY') AS 'SUM(quantity)',
sum('prod'.'sales'.'SALE_VALUE') AS 'SUM(sale_value)'
FROM 'prod'.'sales'
WHERE (('prod'.'sales'.'CUSTOMER_ID' = 1)
AND ('prod'.'sales'.'PRODUCT_ID' = 1)
AND ('prod'.'sales'.'SALE_DATE' between 20040101000000 and 20041231000000))
Short Explain
-------------
1 PRIMARY select(range) on sales using i_sales_cust_prod_date
Using where
|
Figure 21-8 shows the performance of the four approaches. As expected, the MERGE view gave equivalent performance to native SQL and was superior to both the TEMPTABLE and the derived table approaches.
Figure 21-8. Comparison of view algorithm performance
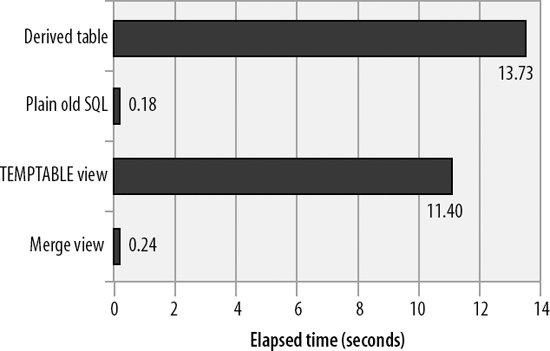
Not all views can be resolved by a MERGE algorithm. In particular, views that include GROUP BY or other aggregate conditions (DISTINCT, SUM, etc.) must be resolved through a temporary table. It is also possible that in some cases the "merged" SQL generated by MySQL might be hard to optimize and that a temporary table approach might lead to better performance.
|
Part I: Stored Programming Fundamentals
Introduction to MySQL Stored Programs
- Introduction to MySQL Stored Programs
- What Is a Stored Program?
- A Quick Tour
- Resources for Developers Using Stored Programs
- Some Words of Advice for Developers
- Conclusion
MySQL Stored Programming Tutorial
- MySQL Stored Programming Tutorial
- What You Will Need
- Our First Stored Procedure
- Variables
- Parameters
- Conditional Execution
- Loops
- Dealing with Errors
- Interacting with the Database
- Calling Stored Programs from Stored Programs
- Putting It All Together
- Stored Functions
- Triggers
- Calling a Stored Procedure from PHP
- Conclusion
Language Fundamentals
- Language Fundamentals
- Variables, Literals, Parameters, and Comments
- Operators
- Expressions
- Built-in Functions
- Data Types
- MySQL 5 Strict Mode
- Conclusion
Blocks, Conditional Statements, and Iterative Programming
- Blocks, Conditional Statements, and Iterative Programming
- Block Structure of Stored Programs
- Conditional Control
- Iterative Processing with Loops
- Conclusion
Using SQL in Stored Programming
- Using SQL in Stored Programming
- Using Non-SELECT SQL in Stored Programs
- Using SELECT Statements with an INTO Clause
- Creating and Using Cursors
- Using Unbounded SELECT Statements
- Performing Dynamic SQL with Prepared Statements
- Handling SQL Errors: A Preview
- Conclusion
Error Handling
- Error Handling
- Introduction to Error Handling
- Condition Handlers
- Named Conditions
- Missing SQL:2003 Features
- Putting It All Together
- Handling Stored Program Errors in the Calling Application
- Conclusion
Part II: Stored Program Construction
Creating and Maintaining Stored Programs
- Creating and Maintaining Stored Programs
- Creating Stored Programs
- Editing an Existing Stored Program
- SQL Statements for Managing Stored Programs
- Getting Information About Stored Programs
- Conclusion
Transaction Management
- Transaction Management
- Transactional Support in MySQL
- Defining a Transaction
- Working with Savepoints
- Transactions and Locks
- Transaction Design Guidelines
- Conclusion
MySQL Built-in Functions
- MySQL Built-in Functions
- String Functions
- Numeric Functions
- Date and Time Functions
- Other Functions
- Conclusion
Stored Functions
- Stored Functions
- Creating Stored Functions
- SQL Statements in Stored Functions
- Calling Stored Functions
- Using Stored Functions in SQL
- Conclusion
Triggers
Part III: Using MySQL Stored Programs in Applications
Using MySQL Stored Programs in Applications
- Using MySQL Stored Programs in Applications
- The Pros and Cons of Stored Programs in Modern Applications
- Advantages of Stored Programs
- Disadvantages of Stored Programs
- Calling Stored Programs from Application Code
- Conclusion
Using MySQL Stored Programs with PHP
- Using MySQL Stored Programs with PHP
- Options for Using MySQL with PHP
- Using PHP with the mysqli Extension
- Using MySQL with PHP Data Objects
- Conclusion
Using MySQL Stored Programs with Java
- Using MySQL Stored Programs with Java
- Review of JDBC Basics
- Using Stored Programs in JDBC
- Stored Programs and J2EE Applications
- Using Stored Procedures with Hibernate
- Using Stored Procedures with Spring
- Conclusion
Using MySQL Stored Programs with Perl
- Using MySQL Stored Programs with Perl
- Review of Perl DBD::mysql Basics
- Executing Stored Programs with DBD::mysql
- Conclusion
Using MySQL Stored Programs with Python
- Using MySQL Stored Programs with Python
- Installing the MySQLdb Extension
- MySQLdb Basics
- Using Stored Programs with MySQLdb
- A Complete Example
- Conclusion
Using MySQL Stored Programs with .NET
- Using MySQL Stored Programs with .NET
- Review of ADO.NET Basics
- Using Stored Programs in ADO.NET
- Using Stored Programs in ASP.NET
- Conclusion
Part IV: Optimizing Stored Programs
Stored Program Security
- Stored Program Security
- Permissions Required for Stored Programs
- Execution Mode Options for Stored Programs
- Stored Programs and Code Injection
- Conclusion
Tuning Stored Programs and Their SQL
- Tuning Stored Programs and Their SQL
- Why SQL Tuning Is So Important
- How MySQL Processes SQL
- SQL Tuning Statements and Practices
- About the Upcoming Examples
- Conclusion
Basic SQL Tuning
Advanced SQL Tuning
- Advanced SQL Tuning
- Tuning Subqueries
- Tuning Anti-Joins Using Subqueries
- Tuning Subqueries in the FROM Clause
- Tuning ORDER and GROUP BY
- Tuning DML (INSERT, UPDATE, DELETE)
- Conclusion
Optimizing Stored Program Code
- Optimizing Stored Program Code
- Performance Characteristics of Stored Programs
- How Fast Is the Stored Program Language?
- Reducing Network Traffic with Stored Programs
- Stored Programs as an Alternative to Expensive SQL
- Optimizing Loops
- IF and CASE Statements
- Recursion
- Cursors
- Trigger Overhead
- Conclusion
Best Practices in MySQL Stored Program Development
EAN: 2147483647
Pages: 208
- Chapter I e-Search: A Conceptual Framework of Online Consumer Behavior
- Chapter VII Objective and Perceived Complexity and Their Impacts on Internet Communication
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XVII Internet Markets and E-Loyalty
