Tuning Subqueries
A subquery is a SQL statement that is embedded within the WHERE clause of another statement. For instance, Example 21-1 uses a subquery to determine the number of customers who are also employees.
Example 21-1. SELECT statement with a subquery
SELECT COUNT(*) FROM customers WHERE (contact_surname, contact_firstname,date_of_birth) IN (select surname,firstname,date_of_birth FROM employees) |
We can identify the subquery through the DEPENDENT SUBQUERY tag in the Select type column of the EXPLAIN statement output, as shown here:
Explain plan ------------ ID=1 Table=customers Select type=PRIMARY Access type=ALL Rows=100459 Key= (Possible= ) Ref= Extra=Using where ID=2 Table=employees Select type=DEPENDENT SUBQUERY Access type=ALL Rows=1889 Key= (Possible= ) Ref= Extra=Using where
The same query can also be rewritten as an EXISTS subquery, as in Example 21-2.
Example 21-2. SELECT statement with an EXISTS subquery
SELECT count(*) FROM customers WHERE EXISTS (SELECT 'anything' FROM employees where surname=customers.contact_surname AND firstname=customers.contact_firstname AND date_of_birth=customers.date_of_birth) Short Explain ------------- 1 PRIMARY select(ALL) on customers using no key Using where 2 DEPENDENT SUBQUERY select(ALL) on employees using no key |
Note that the EXPLAIN output for the EXISTS subquery is identical to that of the IN subquery. This is because MySQL rewrites IN-based subqueries as EXISTS-based syntax before execution. The performance of subqueries will, therefore, be the same, regardless of whether you use the EXISTS or the IN operator.
21.1.1. Optimizing Subqueries
When MySQL executes a statement that contains a subquery in the WHERE clause, it will execute the subquery once for every row returned by the main or "outer" SQL statement. It therefore follows that the subquery had better execute very efficiently: it is potentially going to be executed many times. The most obvious way to make a subquery run fast is to ensure that it is supported by an index. Ideally, we should create a concatenated index that includes every column referenced within the subquery.
For our example query in the previous example, we should create an index on all the employees columns referenced in the subquery:
CREATE INDEX i_customers_name ON customers (contact_surname, contact_firstname, date_of_birth)
We can see from the following EXPLAIN output that MySQL makes use of the index to resolve the subquery. The output also includes the Using index clause, indicating that only the index is usedthe most desirable execution plan for a subquery.
Short Explain ------------- 1 PRIMARY select(ALL) on employees using no key Using where 2 DEPENDENT SUBQUERY select(index_subquery) on customers using i_customers_name Using index; Using where
Figure 21-1 shows the relative performance of both the EXISTS and IN subqueries with and without an index.
Figure 21-1. Subquery performance with and without an index
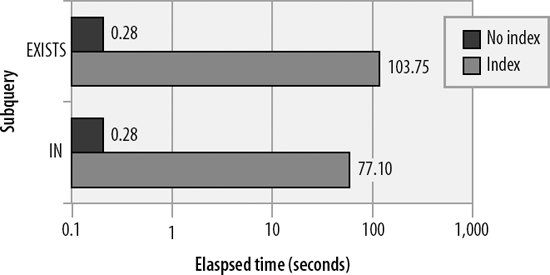
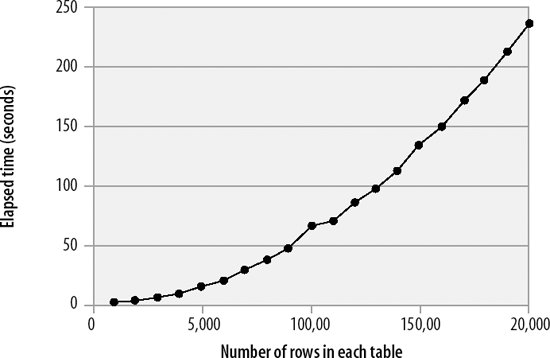
Not only will an indexed subquery outperform a nonindexed subquery, but the un-indexed subquery will also degrade exponentially as the number of rows in each of the tables increases. (The response time will actually be proportional to the number of rows returned by the outer query times the number of rows accessed in the subquery.) Figure 21-2 shows this exponential degradation.
|

21.1.2. Rewriting a Subquery as a Join
Many subqueries can be rewritten as joins. For instance, our example subquery could have been expressed as a join, as shown in Example 21-3.
Figure 21-2. Exponential degradation in nonindexed subqueries
Example 21-3. Subquery rewritten as a join
SELECT count(*) FROM customers JOIN employees ON (employees.surname=customers.contact_surname AND employees.firstname=customers.contact_firstname AND employees.date_of_birth=customers.date_of_birth) |
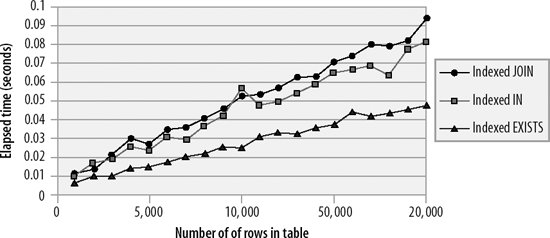
Subqueries sometimes result in queries that are easier to understand, and when the subquery is indexed, the performance of both types of subqueries and the join is virtually identical, although, as described in the previous section, EXISTS has a small advantage over IN. Figure 21-3 compares the three solutions for various sizes of tables.
Figure 21-3. IN, EXISTS, and JOIN solution scalability (indexed query)
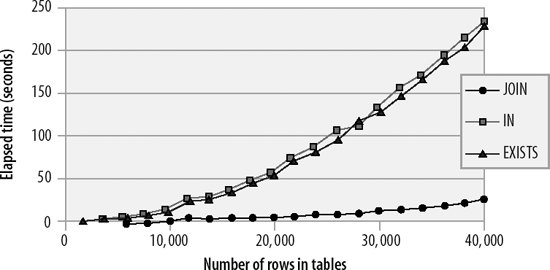
However, when no index exists to support the subquery or the join, then the join will outperform both IN and EXISTS subqueries. It will also degrade less rapidly as the number of rows to be processed increases. This is because of the MySQL join optimizations. Figure 21-4 shows the performance characteristics of the three solutions where no index exists.
Figure 21-4. Comparison of nonindexed JOIN, IN, and EXISTS performance
|
21.1.3. Using Subqueries in Complex Joins
Although a subquery, in general, will not outperform an equivalent join, there are occasions when you can use subqueries to obtain more favorable execution plans for complex joins especially when index merge operations are concerned.
Let's look at an example. You have an application that from time to time is asked to report on the quantity of sales made to a particular customer by a particular sales rep. The SQL might look like Example 21-4.
Example 21-4. Complex join SQL
SELECT COUNT(*), SUM(sales.quantity), SUM(sales.sale_value) FROM sales JOIN customers ON (sales.customer_id=customers.customer_id) JOIN employees ON (sales.sales_rep_id=employees.employee_id) JOIN products ON (sales.product_id=products.product_id) WHERE customers.customer_name='INVITRO INTERNATIONAL' AND employees.surname='GRIGSBY' AND employees.firstname='RAY' AND products.product_description='SLX'; |
We already have an index on the primary key columns for customers, employees, and products, so MySQL uses these indexes to join the appropriate rows from these tables to the sales table. In the process, it eliminates all of the rows except those that match the WHERE clause condition:
Short Explain ------------- 1 SIMPLE select(ALL) on sales using no key 1 SIMPLE select(eq_ref) on employees using PRIMARY Using where 1 SIMPLE select(eq_ref) on customers using PRIMARY Using where 1 SIMPLE select(eq_ref) on products using PRIMARY Using where
This turns out to be a fairly expensive query, because we have to perform a full scan of the large sales table. What we probably want to do is to retrieve the appropriate primary keys from products, customers, and employees using the WHERE clause conditions, and then look up those keys (quickly) in the sales table. To allow us to quickly find these primary keys, we would create the following indexes:
CREATE INDEX i_customer_name ON customers(customer_name); CREATE INDEX i_product_description ON products(product_description); CREATE INDEX i_employee_name ON employees(surname, firstname);
To enable a rapid sales table lookup, we would create the following index:
CREATE INDEX i_sales_cust_prod_rep ON sales(customer_id,product_id,sales_rep_id);
Once we do this, our execution plan looks like this:
Short Explain ------------- 1 SIMPLE select(ref) on customers using i_customer_name Using where; Using index 1 SIMPLE select(ref) on employees using i_employee_name Using where; Using index 1 SIMPLE select(ref) on products using i_product_description Using where; Using index 1 SIMPLE select(ref) on sales using i_sales_cust_prod_rep Using where
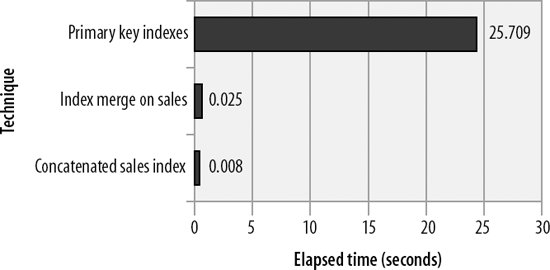
Each step is now based on an index lookup, and the sales lookup is optimized through a fast concatenated index. The execution time reduces from about 25 seconds (almost half a minute) to about 0.01 second (almost instantaneous).
|
As we noted in the previous chapter, we can't always create all of the concatenated indexes that we might need to support all possible queries on a table. In this case, we may want to perform an "index merge" of multiple single-column indexes. However, MySQL will not normally perform an index merge when optimizing a join.
In this case, to get an index merge join, we can try to rewrite the join using subqueries, as shown in Example 21-5.
Example 21-5. Complex join SQL rewritten to support index merge
SELECT COUNT(*), SUM(sales.quantity), SUM(sales.sale_value) FROM sales WHERE product_id= (SELECT product_id FROM products WHERE product_description='SLX') AND sales_rep_id=(SELECT employee_id FROM employees WHERE surname='GRIGSBY' AND firstname='RAY') AND customer_id= (SELECT customer_id FROM customers WHERE customer_name='INVITRO INTERNATIONAL'); |
The EXPLAIN output shows that an index merge will now occur, as shown in Example 21-6.
Example 21-6. EXPLAIN output for an index merge SQL
Short Explain ------------- 1 PRIMARY select(index_merge) on sales using i_sales_rep,i_sales_cust Using intersect(i_sales_rep,i_sales_cust); Using where 4 SUBQUERY select(ref) on customers using i_customer_name 3 SUBQUERY select(ref) on employees using i_employee_name 2 SUBQUERY select(ref) on products using i_product_description |
The performance of the index merge solution is about 0.025 secondslower than the concatenated index but still about 1,000 times faster than the initial join performance. This is an especially useful technique if you have a STAR schema (one very large table that contains the "facts," with foreign keys pointing to other, smaller "dimension" tables).
Figure 21-5 compares the performance of the three approaches. Although an index merge is not quite as efficient as a concatenated index, you can often satisfy a wider range of queries using an index merge, since this way you need only create indexes on each column, not concatenated indexes on every possible combination of columns.
|
Figure 21-5. Optimizing a complex join with subqueries and index merge
Part I: Stored Programming Fundamentals
Introduction to MySQL Stored Programs
- Introduction to MySQL Stored Programs
- What Is a Stored Program?
- A Quick Tour
- Resources for Developers Using Stored Programs
- Some Words of Advice for Developers
- Conclusion
MySQL Stored Programming Tutorial
- MySQL Stored Programming Tutorial
- What You Will Need
- Our First Stored Procedure
- Variables
- Parameters
- Conditional Execution
- Loops
- Dealing with Errors
- Interacting with the Database
- Calling Stored Programs from Stored Programs
- Putting It All Together
- Stored Functions
- Triggers
- Calling a Stored Procedure from PHP
- Conclusion
Language Fundamentals
- Language Fundamentals
- Variables, Literals, Parameters, and Comments
- Operators
- Expressions
- Built-in Functions
- Data Types
- MySQL 5 Strict Mode
- Conclusion
Blocks, Conditional Statements, and Iterative Programming
- Blocks, Conditional Statements, and Iterative Programming
- Block Structure of Stored Programs
- Conditional Control
- Iterative Processing with Loops
- Conclusion
Using SQL in Stored Programming
- Using SQL in Stored Programming
- Using Non-SELECT SQL in Stored Programs
- Using SELECT Statements with an INTO Clause
- Creating and Using Cursors
- Using Unbounded SELECT Statements
- Performing Dynamic SQL with Prepared Statements
- Handling SQL Errors: A Preview
- Conclusion
Error Handling
- Error Handling
- Introduction to Error Handling
- Condition Handlers
- Named Conditions
- Missing SQL:2003 Features
- Putting It All Together
- Handling Stored Program Errors in the Calling Application
- Conclusion
Part II: Stored Program Construction
Creating and Maintaining Stored Programs
- Creating and Maintaining Stored Programs
- Creating Stored Programs
- Editing an Existing Stored Program
- SQL Statements for Managing Stored Programs
- Getting Information About Stored Programs
- Conclusion
Transaction Management
- Transaction Management
- Transactional Support in MySQL
- Defining a Transaction
- Working with Savepoints
- Transactions and Locks
- Transaction Design Guidelines
- Conclusion
MySQL Built-in Functions
- MySQL Built-in Functions
- String Functions
- Numeric Functions
- Date and Time Functions
- Other Functions
- Conclusion
Stored Functions
- Stored Functions
- Creating Stored Functions
- SQL Statements in Stored Functions
- Calling Stored Functions
- Using Stored Functions in SQL
- Conclusion
Triggers
Part III: Using MySQL Stored Programs in Applications
Using MySQL Stored Programs in Applications
- Using MySQL Stored Programs in Applications
- The Pros and Cons of Stored Programs in Modern Applications
- Advantages of Stored Programs
- Disadvantages of Stored Programs
- Calling Stored Programs from Application Code
- Conclusion
Using MySQL Stored Programs with PHP
- Using MySQL Stored Programs with PHP
- Options for Using MySQL with PHP
- Using PHP with the mysqli Extension
- Using MySQL with PHP Data Objects
- Conclusion
Using MySQL Stored Programs with Java
- Using MySQL Stored Programs with Java
- Review of JDBC Basics
- Using Stored Programs in JDBC
- Stored Programs and J2EE Applications
- Using Stored Procedures with Hibernate
- Using Stored Procedures with Spring
- Conclusion
Using MySQL Stored Programs with Perl
- Using MySQL Stored Programs with Perl
- Review of Perl DBD::mysql Basics
- Executing Stored Programs with DBD::mysql
- Conclusion
Using MySQL Stored Programs with Python
- Using MySQL Stored Programs with Python
- Installing the MySQLdb Extension
- MySQLdb Basics
- Using Stored Programs with MySQLdb
- A Complete Example
- Conclusion
Using MySQL Stored Programs with .NET
- Using MySQL Stored Programs with .NET
- Review of ADO.NET Basics
- Using Stored Programs in ADO.NET
- Using Stored Programs in ASP.NET
- Conclusion
Part IV: Optimizing Stored Programs
Stored Program Security
- Stored Program Security
- Permissions Required for Stored Programs
- Execution Mode Options for Stored Programs
- Stored Programs and Code Injection
- Conclusion
Tuning Stored Programs and Their SQL
- Tuning Stored Programs and Their SQL
- Why SQL Tuning Is So Important
- How MySQL Processes SQL
- SQL Tuning Statements and Practices
- About the Upcoming Examples
- Conclusion
Basic SQL Tuning
Advanced SQL Tuning
- Advanced SQL Tuning
- Tuning Subqueries
- Tuning Anti-Joins Using Subqueries
- Tuning Subqueries in the FROM Clause
- Tuning ORDER and GROUP BY
- Tuning DML (INSERT, UPDATE, DELETE)
- Conclusion
Optimizing Stored Program Code
- Optimizing Stored Program Code
- Performance Characteristics of Stored Programs
- How Fast Is the Stored Program Language?
- Reducing Network Traffic with Stored Programs
- Stored Programs as an Alternative to Expensive SQL
- Optimizing Loops
- IF and CASE Statements
- Recursion
- Cursors
- Trigger Overhead
- Conclusion
Best Practices in MySQL Stored Program Development
EAN: 2147483647
Pages: 208
