Data Retrieval in MySQL Cluster
MySQL Cluster has four different methods of retrieving data with different performance characteristics: primary key access, unique key access, ordered index access, and full table scans.
Primary Key Access
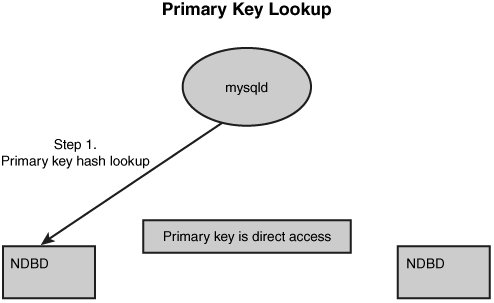
When a query is going to use the primary key, it does so using a normal hash lookup. The MySQL server forms a hash of the primary key, and then, using the same algorithm for partitioning, it knows exactly which data node contains the data and fetches it from there, as shown in Figure 5.1. This process is identical, no matter how many data nodes are present.
Figure 5.1. Primary key access.
Unique Key Access
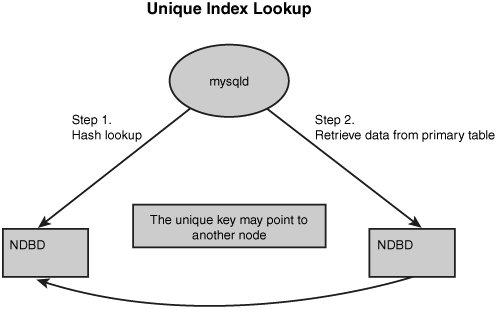
When a query is going to use a unique key, it again does a hash lookup. However, in this case, it is a two-step process, as shown in Figure 5.2. The query first uses a hash on the UNIQUE value to look up the PRIMARY KEY value that corresponds to the row. It does this by using the value as the primary key into the hidden table. Then, when it has the primary key from the base table, it is able to retrieve the data from the appropriate place. For response time purposes, a UNIQUE access is approximately double the response time of a primary key lookup because it has to do two primary key lookups to get the row.
Figure 5.2. Unique key access.
Ordered Index Access
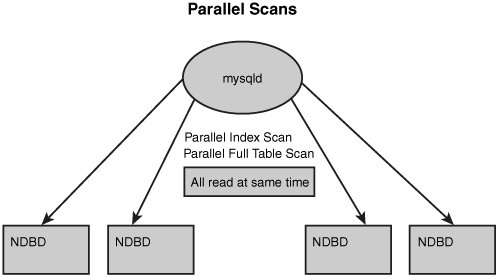
To access an ordered index, the MySQL server does what is a called a parallel index scan, as shown in Figure 5.3. Essentially, this means that it has to ask every single data node to look through the piece of the index that the data node has locally. The nodes do this in parallel, and the MySQL server combines the results as they are returned to the server from the data nodes.
Due to the parallel nature of the scanning, this can, in theory, have a better response time than doing a local query. This is not always true, however, as it depends on many different things.
An ordered index scan causes more network traffic and is more expensive than a PRIMARY KEY or UNIQUE KEY lookup. However, it can resolve a lot of queries that cannot be resolved by using a hash lookup.
Full Table Scan
The final method for resolving a query is through the use of a full table scan. MySQL Cluster can do this in two different ways, depending on the version and startup options you use for the MySQL server:
- Full table scan without condition pushdown This first option is the slower, less efficient method. In this method, all the data in the table is fetched back to the MySQL server, which then applies a WHERE clause to the data. As you can imagine, this is a very expensive operation. If you have a table that is 2GB in size, this operation results in all 2GB of data crossing the network every time you do a full table scan. This method is the only one available in MySQL 4.1. It is also the default method in MySQL 5.0.
- Full table scan with condition pushdown There is an option in MySQL 5.0 called engine_condition_pushdown. If this option is turned on, the MySQL server can attempt to do a more optimized method for the full table scan. In this case, the WHERE clause that you are using to filter the data is sent to each of the data nodes. Each of the data nodes can then apply the condition before it sends the data back across the network. This generally reduces the amount of data being returned and can speed up the query over the previous method by a great deal. Imagine that you have a table with 2 million rows, but you are retrieving only 10 rows, based on the WHERE condition. With the old method, you would send 2 million rows across the network; with the new method, you would only have to send the 10 rows that match across the network. This reduces the network traffic by almost 99.9999%. As you can imagine, this is normally the preferred method.
Figure 5.3. Ordered index access.
To enable the engine_condition_pushdown option, you need to set it in the MySQL configuration file:
[mysqld] ndbcluster engine_condition_pushdown=1
You can also set it dynamically by using either the SET GLOBAL or SET SESSION command, like this:
SET SESSION engine_condition_pushdown=1; SET GLOBAL engine_condition_pushdown=0;
SET GLOBAL applies to all future connections. SET SESSION applies to only the current connection. Keep in mind that if you want to have the value survive across a MySQL server, you should restart and then change the configuration file.
You can verify that the engine_condition_pushdown variable is currently on by using the SHOW VARIABLES command:
mysql> show variables like 'engine%'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | engine_condition_pushdown | ON | +---------------------------+-------+ 1 row in set (0.00 sec)
EXPLAIN After this variable has been set, you can ensure that it is actually working by using the EXPLAIN command. If it is working, you see the ExTRa option called "Using where with pushed condition":
mysql> SELECT * FROM country WHERE name LIKE '%a%'G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: country type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 239 Extra: Using where with pushed condition 1 row in set (0.00 sec)
Using EXPLAIN
The EXPLAIN command is the key to knowing which of the access methods are being used and how MySQL is resolving your query.
To use EXPLAIN, all you have to do is prefix your SELECT statement with the keyword EXPLAIN, as in the following example:
Note
Note that these examples use the world database, which is freely available from the documentation section of http://dev.mysql.com.
If you want to try out these exact examples, you can download and install the world database and switch all the tables to NDB by using ALTER TABLE. Remember to create the database world on all SQL nodes.
mysql>EXPLAIN SELECT * FROM Country, City WHERE Country.capital = City.id AND Country.region LIKE 'Nordic%'G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: Country type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 239 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: City type: eq_ref possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: world.Country.Capital rows: 1 Extra: 2 rows in set (0.00 sec)
There is a lot of information here, so let's examine what it all means.
The first significant thing we need to examine is the order in which the rows come back. The order is the order in which MySQL is going to read the tables. This order does not normally depend on the order in which they are listed in the query. For inner joins and some outer joins, MySQL rearranges the tables into any order it feels will make your query faster.
The next thing that is important is the Type column. It tells how MySQL is going to read the table. This ties in to the previous section about table access methods. Some of the possible retrieval types and what they correspond to for MySQL Cluster are listed in Table 5.1.
|
EXPLAIN type |
Cluster Access Method |
Description |
|---|---|---|
|
Const |
Primary key, unique key |
MySQL knows there is at most one matching row. MySQLcan read that row and optimize the table from the query. This is a very good access method. |
|
eq_ref |
Primary key, unique key |
This is a join on a unique column. It is a very fast join method. |
|
Ref |
Ordered index |
This is a scan using a non-unique index. |
|
Range |
Ordered index |
This is a retrieve range of data based on non-equality (that is, less than, BETWEEN, LIKE). |
|
ALL |
Full table scan |
MySQL will read the entire table. |
The next two columns in EXPLAIN are possible_keys and key. These columns indicate which indexes MySQL is using and also which indexes it sees are possible but decides not to use to resolve your query. Due to the lack of index statistics, as mentioned previously in this chapter, you might consider suggesting one of the other possible indexes with USE INDEX to see if it is any faster with a different one.
The next column of significance is the rows column. This column tells how many rows MySQL thinks it will have to read from the table for each previous combination of rows. However, this number generally isn't all that accurate because NDB does not give accurate statistics to MySQL. Normally, if you are using an index, you will see 10 listed as the rows, regardless of how many rows actually match. If you are doing a full table scan, you will also see 100 if ndb_use_exact_count is turned off. If ndb_use_exact_count is enabled, the rows column correctly gives the number of rows in the table that need to be scanned.
The final column listed is the Extra column. This column can list any additional information about how the query is going to be executed. The first important value that can show up here is Using where with pushed condition. As mentioned previously, this means that NDB is able to send out the WHERE condition to the data nodes in order to filter data for a full table scan. A similar possible value is Using where. This value indicates that the MySQL server isn't able to send the filtering condition out to the data nodes. If you see this, you can attempt to get the MySQL server to send it out in order to possibly speed up the query.
The first thing you can do is ensure that the engine_condition_pushdown variable is set. You can view whether it is set by using the SHOW VARIABLES option:
mysql> EXPLAIN SELECT * FROM Country WHERE code LIKE '%a%'G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: Country type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 239 Extra: Using where 1 row in set (0.14 sec) mysql> show variables like 'engine_condition_pushdown'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | engine_condition_pushdown | OFF | +---------------------------+-------+ 1 row in set (0.01 sec) root@world~> set session engine_condition_pushdown=1; Query OK, 0 rows affected (0.00 sec) mysql> explain SELECT * FROM Country WHERE code LIKE '%a%'G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: Country type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 239 Extra: Using where with pushed condition 1 row in set (0.00 sec)
The second method you can attempt is to rewrite the query into something that can be pushed down. In order to be able to push down a WHERE condition, it has to follow these rules:
- Any columns used must not be used in expressions (that is, no calculations or functions on them).
- The comparison must be one of the supported types. Supported types include the following:
- =,!=,>,>=,<,<=,IS NULL, and IS NOT NULL
- Combinations of the preceding types (for example, BETWEEN, IN())
- AND and OR are allowed.
The following is an example of how to rewrite a query to make use of the condition pushdown:
mysql> explain SELECT * FROM Country WHERE population/1.2 < 1000 OR code LIKE '%a%' G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: Country type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 239 Extra: Using where 1 row in set (0.09 sec) mysql> explain SELECT * FROM Country WHERE population < 1000/1.2 OR code LIKE '%a%' G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: Country type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 239 Extra: Using where with pushed condition 1 row in set (0.00 sec)
Notice that in the second explain, the query was rewritten to put the population column used all by itself on one side. That allowed the condition to be pushed down, which will potentially enable the full table scan to be many times faster.
Installation
- Installation
- Before You Begin with MySQL Cluster
- Installing MySQL-Max
- Retrieving the Latest Snapshot from BitKeeper
- Ensuring That MySQL Cluster Works
- Auto-discovery of Databases
- Startup Phases
- Restarting a Cluster
- Testing Your Cluster
- Upgrading MySQL Cluster
- Obtaining, Installing, and Configuring MySQL Cluster on Other Platforms
- RAM Usage
- Adding Tables
- Common Errors While Importing Tables
Configuration
- Configuration
- The Structure of config.ini
- Management Nodes
- Storage Nodes
- SQL Nodes
- Using Multiple Management Nodes
Backup and Recovery
Security and Management
- Security and Management
- Security for MySQL Cluster
- Managing MySQL Cluster
- Running MySQL in a Chrooted Environment
Performance
- Performance
- Performance Metrics
- MySQL Cluster Performance
- Benchmarking
- Indexes
- Query Execution
- Data Retrieval in MySQL Cluster
- Physical Factors
- High-Speed Interconnects
Troubleshooting
Common Setups
A MySQL Cluster Binaries
B Management Commands
- B Management Commands
- Displaying the Status of the Cluster/Controlling Nodes
- Logging Commands
- Miscellaneous Commands
C Glossary of Cluster Terminology
Index
EAN: 2147483647
Pages: 93
