Tuning Joins
So far we have looked at tuning SQL queries against a single table only. Let's move on to tuning SQL queries that join rows from two or more tables.
20.2.1. How MySQL Joins Tables
MySQL currently joins tables using a fairly simple technique with a complicated-sounding name. The MySQL manual refers to the join algorithm as single-sweep multi-join. In essence, when MySQL joins two tables, it will read the rows from the first table andfor each rowsearch the second table for matching rows. Further details can be found in the MySQL Internals Manual; see http://dev.mysql.com/doc/internals/en/index-merge-overview.html.
20.2.2. Joins Without Indexes
The basic join algorithm is not very well suited to joining multiple tables unless there are indexes to support the join.[*] Performance might be adequate for very small tables, but as table sizes increase, the join overhead will increase rapidly. Even worse, the join overhead will increase almost exponentially.
[*] We are hoping to see a join algorithm that can perform adequately in the absence of indexesthe hash join algorithmin MySQL 5.2.
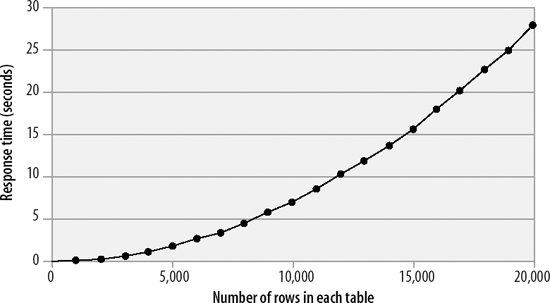
Figure 20-8 shows how response time increases for nonindexed joins as the size of each table increases. This semi-exponential degradation is extremely undesirable: if we extrapolate the response time curve for larger tables, we predict that it would take 20 minutes to join two tables of 100,000 rows, 20 hours to join two tables with 1 million rows each, and 81 days to join two tables of 10 million rows each! This is definitely not the way you want your applications to perform as your database grows in size.
Figure 20-8. Table size versus elapsed time for nonindexed joins
20.2.3. Joins with Indexes
To get predictable and acceptable performance for our join, we need to create indexes to support the join. Generally, we will want to create concatenated indexes based on any columns in a table that might be used to join that table to another table. However, we don't need an index on the first (or "driving") table's columns; that is, if we are joining customers to sales, in that order, then our index needs to be on saleswe don't need an index on both tables.
Creating an index on the join column not only reduces execution time, but also prevents an exponential increase in response time as the tables grow in size. Figure 20-9 shows how the response time increases as the number of rows increases when there is an index to support the join. Not only is performance much better (about 0.1 second compared to more than 25 seconds for two tables of 20,000 rows), but the increase in response time is far more predictable. Extrapolating the response time for the indexed join, we can predict that joining two tables of 10 million rows each could be achieved in only 40 secondscompared to 81 days for the nonindexed join.[*]
[*] Joining two very large tables may involve other types of overhead, such as passing the data back to the client and fitting the tables in memory, but the overhead of actually performing the join with the index will be massively less than that of the unindexed join.
|

Figure 20-9. Response time versus table size for an indexed join

20.2.4. Join Order
By far, the most important factor in the optimization of MySQL joins is to ensure that each successive join is supported by an index. Beyond that, we should:
- Ensure that any rows to be eliminated by WHERE clause conditions are done so as early as possible in the join.
- Pick an optimal join order. A good rule of thumb is to join tables from smallest to largest.
Generally, the MySQL optimizer can be relied upon to pick a good join order. However, if we need to change the join order, we can use the STRAIGHT_JOIN hint to ensure that the tables are joined in the order in which they appear in the FROM clause. For instance, the following use of STRAIGHT_JOIN ensures that the join order is from the smallest table (ta_1000) to the largest (ta_5000):
SELECT STRAIGHT_JOIN count(*) FROM ta_1000 JOIN ta_2000 USING (sales_id) JOIN ta_3000 USING (sales_id) JOIN ta_4000 USING (sales_id) JOIN ta_5000 USING (sales_id);
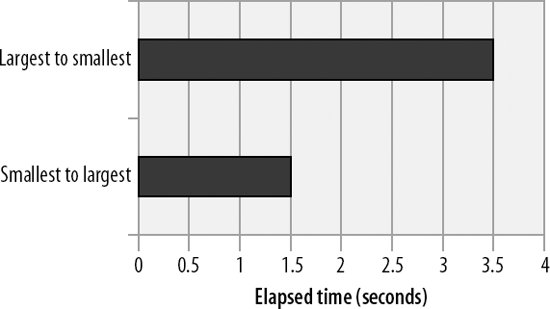
Figure 20-10 shows the difference in elapsed time when joining tables in either ascending or descending order of table size. Joining from smallest to largest is about twice as fast as joining from largest to smallest.
|
Figure 20-10. Table size and join order
20.2.5. A Simple Join Example
Based on our discussions so far, here is a summary of the most important rules for optimizing MySQL joins:
- Ensure that every join is supported by an index.
- Eliminate rows as early as possible in the join sequence.
- Join tables from smallest to largest.
Let's apply these rules to a simple example.
Consider the case in which we are listing all sales for a particular customer. The query looks like this:
SELECT SUM(sale_value) FROM sales JOIN customers ON (sales.customer_id=customers.customer_id) WHERE customer_name='LARSCOM INC'
With just the primary key indexes in place, the EXPLAIN output looks like this:
Short Explain ------------- 1 SIMPLE select(ALL) on sales using no key 1 SIMPLE select(eq_ref) on customers using PRIMARY Using where
This execution plan satisfies our first rule: an index (the primary key customer_id of customers) is used to join sales to customers.
However, our second ruleeliminating rows as early as possible in the join sequenceis violated: all of the sales rows are read first, even though only some of those sales (those for a particular customer) are needed. Furthermore, we are joining the larger table sales (2.5 million rows) to the smaller table customers (100,000 rows).
So, what we need to achieve is an efficient join from customers to sales. This means indexing the sales.customer_id column so that we can find sales for a particular customer. The following index should do the trick:
CREATE INDEX i_sales_customer ON sales(customer_id)
The execution plan now looks like this:
Short Explain ------------- 1 SIMPLE select(ALL) on customers using no key Using where 1 SIMPLE select(ref) on sales using i_sales_customer Using where
This is better, but we could improve matters further if we did not have to do the full scan on customers. Adding the following index will let us obtain the desired customer more efficiently:
CREATE INDEX i_customer_name ON customers(customer_name)
Once this is done, the execution plan looks like this:
Short Explain ------------- 1 SIMPLE select(ref) on customers using i_customer_name Using where; Using index 1 SIMPLE select(ref) on sales using i_sales_customer Using where
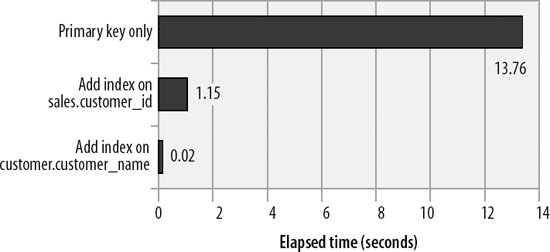
This is the optimal execution plan for this query. The desired customer is found quickly by the index, and then matching sales for that customer are found using the i_sales_customer index. Figure 20-11 shows the performance improvements gained by our optimizations.
Figure 20-11. Optimization of a simple join
Part I: Stored Programming Fundamentals
Introduction to MySQL Stored Programs
- Introduction to MySQL Stored Programs
- What Is a Stored Program?
- A Quick Tour
- Resources for Developers Using Stored Programs
- Some Words of Advice for Developers
- Conclusion
MySQL Stored Programming Tutorial
- MySQL Stored Programming Tutorial
- What You Will Need
- Our First Stored Procedure
- Variables
- Parameters
- Conditional Execution
- Loops
- Dealing with Errors
- Interacting with the Database
- Calling Stored Programs from Stored Programs
- Putting It All Together
- Stored Functions
- Triggers
- Calling a Stored Procedure from PHP
- Conclusion
Language Fundamentals
- Language Fundamentals
- Variables, Literals, Parameters, and Comments
- Operators
- Expressions
- Built-in Functions
- Data Types
- MySQL 5 Strict Mode
- Conclusion
Blocks, Conditional Statements, and Iterative Programming
- Blocks, Conditional Statements, and Iterative Programming
- Block Structure of Stored Programs
- Conditional Control
- Iterative Processing with Loops
- Conclusion
Using SQL in Stored Programming
- Using SQL in Stored Programming
- Using Non-SELECT SQL in Stored Programs
- Using SELECT Statements with an INTO Clause
- Creating and Using Cursors
- Using Unbounded SELECT Statements
- Performing Dynamic SQL with Prepared Statements
- Handling SQL Errors: A Preview
- Conclusion
Error Handling
- Error Handling
- Introduction to Error Handling
- Condition Handlers
- Named Conditions
- Missing SQL:2003 Features
- Putting It All Together
- Handling Stored Program Errors in the Calling Application
- Conclusion
Part II: Stored Program Construction
Creating and Maintaining Stored Programs
- Creating and Maintaining Stored Programs
- Creating Stored Programs
- Editing an Existing Stored Program
- SQL Statements for Managing Stored Programs
- Getting Information About Stored Programs
- Conclusion
Transaction Management
- Transaction Management
- Transactional Support in MySQL
- Defining a Transaction
- Working with Savepoints
- Transactions and Locks
- Transaction Design Guidelines
- Conclusion
MySQL Built-in Functions
- MySQL Built-in Functions
- String Functions
- Numeric Functions
- Date and Time Functions
- Other Functions
- Conclusion
Stored Functions
- Stored Functions
- Creating Stored Functions
- SQL Statements in Stored Functions
- Calling Stored Functions
- Using Stored Functions in SQL
- Conclusion
Triggers
Part III: Using MySQL Stored Programs in Applications
Using MySQL Stored Programs in Applications
- Using MySQL Stored Programs in Applications
- The Pros and Cons of Stored Programs in Modern Applications
- Advantages of Stored Programs
- Disadvantages of Stored Programs
- Calling Stored Programs from Application Code
- Conclusion
Using MySQL Stored Programs with PHP
- Using MySQL Stored Programs with PHP
- Options for Using MySQL with PHP
- Using PHP with the mysqli Extension
- Using MySQL with PHP Data Objects
- Conclusion
Using MySQL Stored Programs with Java
- Using MySQL Stored Programs with Java
- Review of JDBC Basics
- Using Stored Programs in JDBC
- Stored Programs and J2EE Applications
- Using Stored Procedures with Hibernate
- Using Stored Procedures with Spring
- Conclusion
Using MySQL Stored Programs with Perl
- Using MySQL Stored Programs with Perl
- Review of Perl DBD::mysql Basics
- Executing Stored Programs with DBD::mysql
- Conclusion
Using MySQL Stored Programs with Python
- Using MySQL Stored Programs with Python
- Installing the MySQLdb Extension
- MySQLdb Basics
- Using Stored Programs with MySQLdb
- A Complete Example
- Conclusion
Using MySQL Stored Programs with .NET
- Using MySQL Stored Programs with .NET
- Review of ADO.NET Basics
- Using Stored Programs in ADO.NET
- Using Stored Programs in ASP.NET
- Conclusion
Part IV: Optimizing Stored Programs
Stored Program Security
- Stored Program Security
- Permissions Required for Stored Programs
- Execution Mode Options for Stored Programs
- Stored Programs and Code Injection
- Conclusion
Tuning Stored Programs and Their SQL
- Tuning Stored Programs and Their SQL
- Why SQL Tuning Is So Important
- How MySQL Processes SQL
- SQL Tuning Statements and Practices
- About the Upcoming Examples
- Conclusion
Basic SQL Tuning
- Basic SQL Tuning
- Tuning Table Access
- Tuning Joins
- Conclusion
Advanced SQL Tuning
- Advanced SQL Tuning
- Tuning Subqueries
- Tuning Anti-Joins Using Subqueries
- Tuning Subqueries in the FROM Clause
- Tuning ORDER and GROUP BY
- Tuning DML (INSERT, UPDATE, DELETE)
- Conclusion
Optimizing Stored Program Code
- Optimizing Stored Program Code
- Performance Characteristics of Stored Programs
- How Fast Is the Stored Program Language?
- Reducing Network Traffic with Stored Programs
- Stored Programs as an Alternative to Expensive SQL
- Optimizing Loops
- IF and CASE Statements
- Recursion
- Cursors
- Trigger Overhead
- Conclusion
Best Practices in MySQL Stored Program Development
EAN: 2147483647
Pages: 208
