Layered Style
2.4.1 Overview
Layering, like all module styles, reflects a division of the software into units. In this case, the units are layers; each layer represents a virtual machine. Furthermore, there are constraints on the relationship among the virtual machines. The layered view of architecture, shown with a layer diagram, is one of the most commonly used views in software architecture, is poorly defined, and is often misunderstood. Because true layered systems have good properties of modifiability and portability, architects have an incentive to show their systems as layered, even if they are not.
DEFINITIONA virtual machine is an abstract computing device; typically, it is a program that acts as an interface between other software and actual hardware (or another virtual machine). |
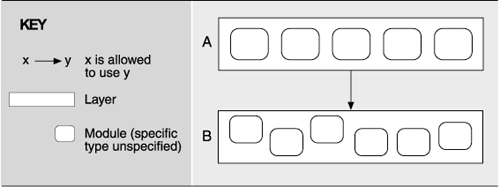
Layers completely partition a set of software, and each partition constitutes a virtual machinewith a public interfacethat provides a cohesive set of services. But that's not all. The following figure, which is intentionally vague about what the units are and how they interact, shows three divisions of softwareand you'll have to take our word that each division is a virtual machinebut none of them constitutes a layering. What's missing?
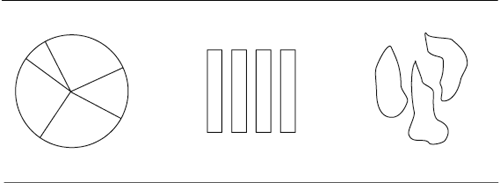
Layering has one more fundamental property: The virtual machines are created to interact according to a strict ordering relation. Herein lies the conceptual heart of layers. If (A,B) is in this relation, we say that layer B is beneath layer A, and that means that the implementation of layer A is allowed to use any of the public facilities of the virtual machine provided by layer B.
DEFINITIONUnit A is said to use unit B if A's correctness depends on a correct implementation of B being present. |
By use and used, we mean something very specific, but the definition has some loopholes. If A is implemented using the facilities in B, is it implemented using only B? Maybe or maybe not. Some layering schemes allow a layer to use the public facilities of any lower layer, not just the nearest lower layer. Other layering schemes have so-called layers that are collections of utilities and can be used by any layer. But no architecture that can be validly called layered allows a layer to use, without restriction, the facilities of a higher layer. Allowing unrestricted upward usage destroys the desirable properties that layering brings to an architecture; this will be discussed shortly. Usage in layers generally flows downward. A small number of well-defined special cases may be permitted, but these should be few and regarded as exceptions to the rule. Hence, the following architectural view resembles a layering but is not:
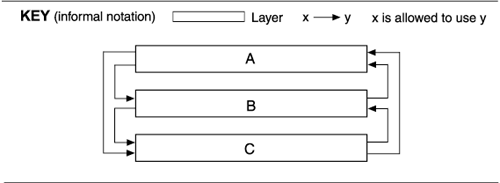
Figures like the preceding show why layers have been a source of ambiguity for so long, for architects have been calling such diagrams layered when they are not. There is more to layers than the ability to draw separate parts on top of each other.
In many layered systems, modules of a lower layer will sometimes have to useand therefore must be allowed to usemodules in a higher layer, and these usages will have to be accommodated by the architecture. In other cases, modules in a very high layer might be required to directly use modules in a very low layer where normally only next-lower-layer uses are allowed. The layer diagram or an accompanying document will have to show these exceptions. The case of software in a higher layer using modules in a lower but not the next-lower layer is called layer bridging. If many of these are present, the system is poorly structured, at least with respect to the portability and modifiability goals that layering helps to achieve. Systems with upward usages are not, strictly according to the definition, layered. However, in such cases, the layered style represents a close approximation to reality and also conveys the ideal design that the architect was trying to achieve.
Layers are intended to provide a virtual machine, and one use of a virtual machine is to promote portability. For this reason, it is important to scrutinize the interface of a layer to ensure that portability concerns are addressed. The interface should not expose functions that are dependent on a particular platform; these functions should be hidden behind a more abstract interface that is independent of platform.
Because the ordering relationship among layers has to do with "implementation allowed to use," the lower the layer, the fewer the facilities available to it. That is, the "worldview" of lower layers tends to be smaller and more focused on the computing platforms. Lower layers tend to be built using knowledge of the computers, communications channels, distribution mechanisms, process dispatchers, and the like. These areas of expertise are largely independent of the particular application that runs on them, meaning that they will not need to be modified if the application changes. Conversely, higher layers tend to be more independent of the platform; they can afford to be, because the existence of the lower layers has given them that freedom. The higher layers can afford to be more concerned only with details of the application.
Layers cannot be derived by examining source code. The source code may disclose what uses what, but the relation in layers is allowed to use. As a trivial example, you can tell by code inspection that a "double" operation was implemented using multiplication by 2, but you cannot tell from the code whether
- It would have been equally acceptable to implement double(x) by adding x to itself or by performing a binary left shiftthat is, what double(x) was allowed to use
- Addition, double, and multiplication are in the same or different layers
A layer may provide services that are not used by other modules. This occurs when the layer was designed to be more general than is strictly necessary for the application in which it finds itself. This in turn often occurs when the layer is imported from another application, purchased as a commercial product, or designed to be used for subsequent applications. This result, of course, can occur in styles other than the layered style.
2.4.2 Elements, Relations, and Properties
Table 2.4 summarizes the discussion of the characteristics of the layered style.
| Elements | Layers. |
| Relations | Allowed to use, which is a specialization of the module viewtype's generic depends-on relation. P1 is said to use P2 if P1's correctness depends on a correct implementation of P2 being present. |
| Properties of elements |
|
| Properties of relations | As for the module viewtype. |
| Topology | If layer A is above layer B, then layer B cannot be above layer A. Every piece of software is allocated to exactly one layer. |
Elements
The elements of a layered diagram are layers. A layer is a cohesive collection of modules, each of which may be invoked or accessed. Each layer should represent a virtual machine. This definition admits many possibilities: from classes to assembly language subroutines to shared data. A requirement is that the units have an interface by which their services can be triggered or initiated or accessed.
Relations
The relation among layers is allowed to use. For two layers having this relation, any module in the first is allowed to use any module in the second. Module A is said to use module B if A's correctness depends on B being correct and present.
The endgame of a layer diagram is to define the binary relation allowed to use among modules. Just as y = f(x) is mathematical shorthand for enumerating all the ordered pairs that are in the function f, a layer diagram is notational shorthand for enumerating all the ordered pairs (A,B) such that A is allowed to use B. A clean layer diagram is a sign of a well-structured relation; a layer diagram that is not clean will be rife with exceptions and appear chaotic.
Properties
Layers have the following properties, which should be documented in the element catalog accompanying the layer diagram.
- Name: Each layer is given a name.
- Contents: The catalog for a layer's view lists the software units contained by each layer. This document assigns each module to exactly one layer. Layers typically have labels that are descriptive but vague, such as "network communications layer" or "business rules layer"; a catalog is needed that lists the complete contents of every layer.
- The software a layer is allowed to use: Is a layer allowed to use only the layer below, any lower layer, or some other? Are modules in a layer permitted to use other modules in the same layer? This part of the documentation must also explain exceptions, if any, to the usage rules implied by the geometry. Exceptions may be upward, allowing something in a lower layer to use something above, or downward, either prohibiting a specific usage otherwise allowed by the geometry or allowing downward usage that "skips" intermediate layers normally required. Exceptions should be precisely described.
- Cohesion: An explanation is required of how the layer provides a functionally cohesive virtual machine. A layer provides a cohesive set of services, meaning that the services as a group would likely be useful as a group in a context other than the one in which they were developed.
Suppose that module P1 is allowed to use module P2. Should P2 be in a lower layer than P1, or should they be in the same layer? Layers are not a function of just who uses what, but are the result of a conscious design decision that allocates modules to layers, based on such considerations as coupling, cohesion, and the likelihood of changes. In general, P1 and P2 should be in the same layer if they are likely to be ported to a new application together or if together they provide different aspects of the same virtual machine to a usage community.
The preceding is an operational definition of cohesion. The cohesion explanation can also serve as a portability guide, describing the changes that can be made to each layer without affecting other layers.
2.4.3 What the Layered Style Is For and What It's Not For
Layers help to bring quality attributes of modifiability and portability to a software system. A layer is an application of the principle of information hiding: in this case, the virtual machine. The theory is that a change to a lower layer can be hidden behind its interface and will not impact the layers above it. As with all such theories, both truth and caveats are associated with it. The truth is that this technique has been used with great success to support portability. Machine, operating system, or other low-level dependencies are hidden within a layer; as long as the interface for the layer does not change, the upper levels that depend only on the interface will work successfully.
The caveat is that interface means more than just the API (application programming interface) containing program signatures. An interface embodies all the assumptions that an external entityin this case, a layermay make. Changes in a lower layer that affect, say, a performance assumption will leak through its interface and may affect a higher layer.
A common misconception is that layers introduce additional runtime overhead. Although this may be true for naive implementations, sophisticated compile/link/load facilities can reduce additional overhead.
We have already mentioned that in some contexts, a layer may contain unused services. These unused services may needlessly consume a runtime resource, such as memory to store the unused code or a thread that is never launched. If these resources are in short supply, a sophisticated compile/link/load facility that eliminates unused code will be helpful.
Layers are part of the blueprint role that architecture plays for constructing the system. Knowing the layers in which their software resides, developers know what services they can rely on in the coding environment. Layers might define work assignments for development teams, although not always.
Layers are part of the communication role played by architecture. In a large system, the number of modules and the dependencies among them rapidly expand. Organizing the modules into layers with interfaces is an important tool for managing complexity and communicating the structure to developers.
Finally, layers help with the analysis role played by architecture. They support the analysis of the impact of changes to the design by enabling some determination of the scope of changes.
2.4.4 Notations for the Layered Style
Informal Notations
Stack
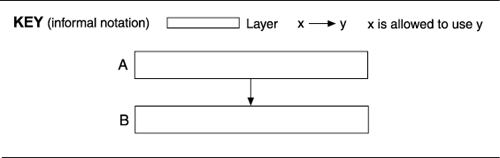
Layers are almost always drawn as a stack of rectangles. The allowed-to-use relation is denoted by geometric adjacency and is read from the top down, like this:

Layering is thus one of the few architectural styles in which connection among components is shown by geometric adjacency and not an explicit symbology, such as an arrow, although arrows can be used, like this:
Segmented Layers
Sometimes layers are divided into segments denoting a finer-grained aggregation of the modules. Often, this occurs when a preexisting set of units, such as imported components or components from separate teams, share the same allowed-to-use relation. When this happens, it is incumbent on the creator of the diagram to specify what usage rules are in effect among the segments. Many usage rules are possible, but they must be made explicit. Segmented layers essentially make the allowed-to-use relation a partial ordering of the elements. The following diagram specifies that A is allowed to use B and C, which are in turn allowed to use D and each other.
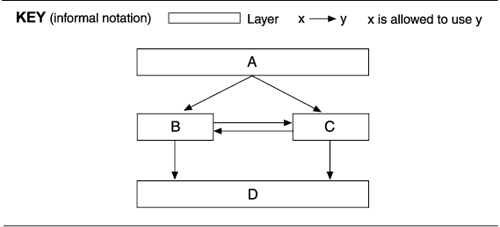
From the strict point of view of layers, the preceding diagram is completely equivalent to the following, where layer BC is the union of the contents of layers B and C:
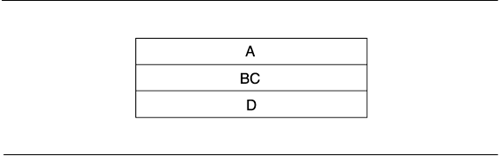
The allowed-to-use relation depicted by the two diagrams is the same. The decomposition of the middle layer into B and C brings to the diagram additional information that has nothing to do with layering; perhaps B and C have been developed by separate teams or represent separate modules or will run on different processors.
Rings
The most common notational variation is to show layers as a set of concentric circles, or rings. The innermost ring corresponds to the lowest layer; the outermost ring, the highest layer. A ring may be subdivided into sectors, meaning the same thing as the corresponding layer being subdivided into parts.
There is no semantic difference between a layer diagram that uses a stack of rectangles and one that uses rings paradigm, except when segmented layers have restrictions on the allowed-to-use relation within the layer. We now discuss this special case.
In the following figure, assume that ring segments that touch are allowed to use one another and that layer segments that touch are allowed to use one another.
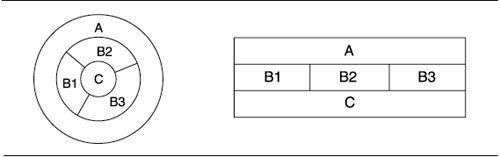
There is no way to "unfold" the ring diagram to produce a stack diagram, such as the one on the right, with exactly the same meaning, because circular arrangements allow more adjacencies than do linear arrangements. (In the layer diagram, B1 and B3 are separate; in the ring diagram they are adjacent. Cases like this are the only ones in which a ring diagram can show a geometric adjacency that a stack picture cannot.
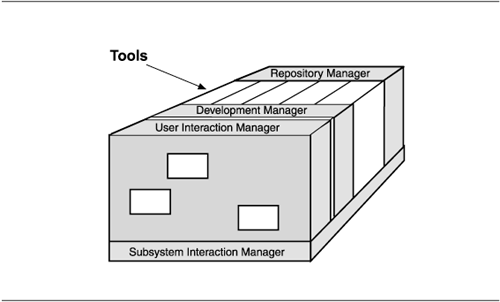
Segmented Layers, 3-D Toaster Models
Sometimes, layers are shown as three-dimensional models to emphasize that segments in one or more layers can be easily replaced or interchanged. Sometimes these are called toaster models because the interchangeable pieces are shown in the shape and orientation of pieces of bread dropped into slots, as in a toaster:
Layers with a Sidecar
Many architectures called layered look something like the following:
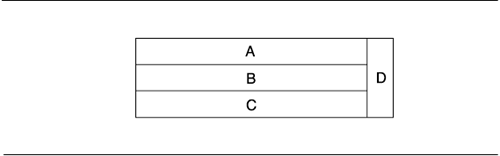
This type of notation could mean one of two things: (1) Modules in D can use modules in A, B, or C. (2) Modules in A, B, or C can use modules in D. (Technically, the diagram might mean that both are true, although this would arguably be a poor layered architecture.) It is incumbent on the creator of the diagram to specify which usage rules pertain. A variation like this makes sense only for single-level usage rules in the main stack, that is, when A can use only B and nothing below. Otherwise, D could simply be made the topmostor bottommost, depending on the caselayer in the main stack, and the "sidecar" geometry would be unnecessary.
Contents
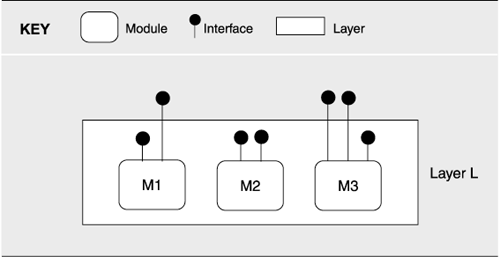
The modules that constitute a layer can be shown graphically, as follows:
Interfaces
Sometimes, the rectangles in a stack are shown with thick horizontal edges denoting the interface to the layer. This is intended to convey the restriction that interlayer usage occurs only via interface facilities and not directly to any layer's "internals." If a layer's contents are so depicted, a lollipop scheme, such as the one in Figure 2.9, which is similar to Figure 1.1(b) on page 45, can be used to indicate which modules' interfaces make up the interface to the layer.
Figure 2.9. Notation to show which interfaces of which internal modules constitute the interfaces of layers
Size and Color
Sometimes, layers are colored to denote which team is responsible for them or to denote another distinguishing feature. Size is sometimes used to give a vague idea of the relative size of the modules constituting the various layers. If they carry meaning, size and color should be explained in the key accompanying the layer diagram.
UML
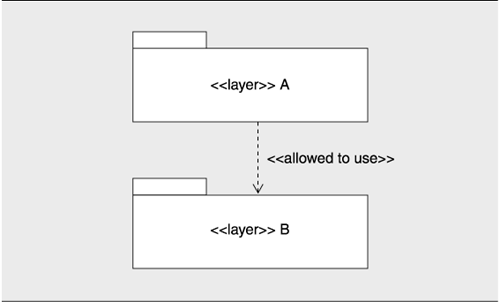
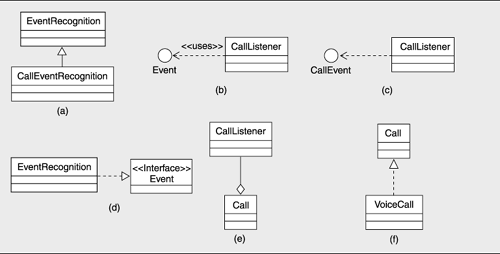
Sadly, UML has no built-in primitive corresponding to a layer. However, nonsegmented layers can be represented in UML using packages, as shown in Figure 2.10. A package is a general-purpose mechanism for organizing elements into groups. UML has predefined kinds of packages for systems and subsystems. We can introduce an additional package for layers by defining it as a stereotype of package. A layer can be shown as a UML package with the dependency between packages "allowed to use." We can designate a layer by using the package notation, with the stereotype name <> preceding the name of the layer or by introducing a new visual form, such as a shaded rectangle.
Figure 2.10. A simple representation of layers in UML
The allowed-to-use relation can be represented as a stereotype of UML access dependency, one of the existing dependencies between packages. This dependency permits the elements of one package to reference the elements of another package.
- An element within a package is allowed to access other elements within the package.
- If a package accesses another package, all elements defined with public visibility in the accessed package are visible within the importing package.
- Access dependencies are not transitive. If package 1 can access package 2 and package 2 can access package 3, it does not automatically follow that package 1 can access package 3.
If the allowed-to-use relation is loop free, you may wish to add the additional constraint that the defined dependency is antisymmetric. This dependency stipulates that if A is allowed to use B, we know that B is not allowed to use A.
UML's mechanism to define the visibility of classes and packages can be used to define the interface to a layer. The mechanism is to prefix the name of the package with + for publicwhich is the default# for protected, and for not visible outside the package. By appropriate tagging, then, we can define a layer's interface to be a subset of the interfaces of its elements.
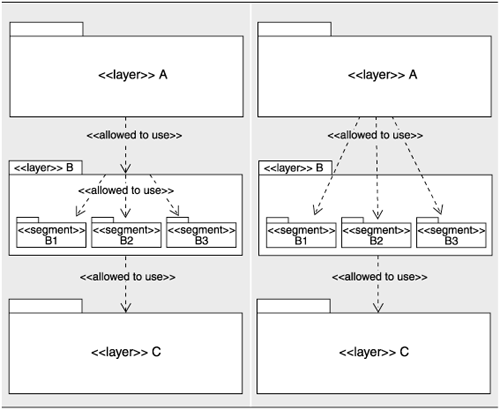
Figure 2.11 shows alternatives for representing segmented layers in UML. Architects should be aware of the following problems when using UML packages to represent layers:
- Elements can be owned bythat is, appear inonly a single package. If an element needs to be a member of a layer and a subsystem, for example, packages cannot be used to represent both; recall that UML represents subsystems with a stereotyped package.
- It is not clear how to represent callbacks with UML. Callbacks are a common method of interaction between modules in different layers.
Figure 2.11. Documenting segmented layers in UML. The segments must be explicitly included in the dependencies. If segments in a layer are allowed to use each other, then <> dependencies must be added among them as well (not shown). The two alternatives shown in this figure are equivalent.
2.4.5 Relation to Other Styles
Layer diagrams are often confused with other architectural styles when information orthogonal to the allowed-to-use relation is introduced without conscious decision.
- Module decomposition: There is a tendency to regard layers as identical to modules in a decomposition view. A layer may in fact be a module, but it is not necessarily always so. One reason this one-to-one mapping often fails is that modules are decomposed into other modules, whereas layers are not decomposed into smaller layers. Segmented layers are often introduced to show mappings to modules. If a module spans layers, colors or fill patterns are often used (see Figure 2.12).
Figure 2.12. A diagram showing layers and modules from a decomposition view
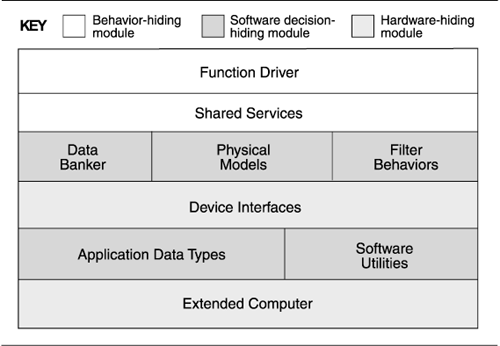
In this example, once again borrowing from the A-7E architecture described previously, the mapping between layers and modules is not one-to-one. In this architecture, the criterion for partitioning into modules was the encapsulation of likely changes. The shading of the elements denotes the coarsest-grain decomposition of the system into modules; that is, Function Driver and Shared Services are both submodules of the behavior-hiding module. Hence, in this system, layers correspond to parts of highest-level modules. It's also easy to imagine a case in which a module constitutes a part of a layer.
- Tiers: Layers are often confused with the tiers in an n-tier client-server architecture, such as is shown in the following figure:
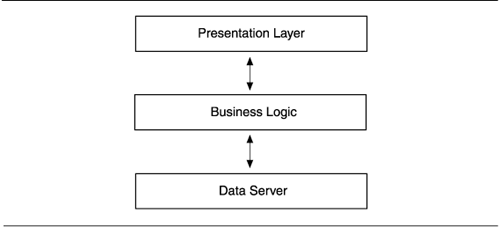
Although the figure above looks like a layer diagram, and a careless author may have used "layers" and "tiers" interchangeably, this diagram expresses concerns very different from layers. Allocation to machines in a distributed environment, data flow among elements, and the presence and use of communication channels all tend to be expressed in tier pictures, and these are indiscernible in layer diagrams. Note the two-way arrows. Whatever relations are being expressed hereand as always, a key should tell usthey're bidirectional, or symmetric, and we know that's bad news in a layer diagram. Further, assignment of a module to one of these elements is based on runtime efficiency: locality of processing, maintaining the ability to do useful work in case of network or server failure, not overloading the server, wise use of network bandwidth, and so on. In contrast, layers are about the ease of making changes and building subsets.
Layers are not tiers, which in fact belong in a hybrid view combining styles in the component-and-connector and allocation viewtypes. Even in an architecture in which layers and tiers have a one-to-one correspondence, you should still plan on documenting them separately, as they serve different concerns.
- Module "uses" style: Because layers express the allowed-to-use relation, there is a close correspondence to the uses style. It is likely, but not always the case, that if an architect chooses to include one style in the documentation suite, the other style will be included as well. Of course, no uses relation is allowed to violate the allowed-to-use relation. If incremental development or the fielding of subsets is a goal, the architect will begin with a broad allowed-to-use specification to guide the developers during implementation. That specification should permit any subset of interest to be built efficiently and without having to include scores of superfluous programs. Later, actual uses can be documented.
- Subsystems: Layers cross conceptual paths with the concept of subsystem. The air traffic control system shown on page 63 was depicted using a segmented layers diagram; we reproduce it here, adding layer labels:
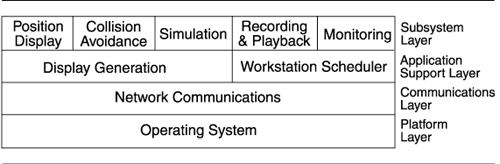
In this context, a subsystem consists of a segment from the top layer and any segments of any lower layers it's allowed to use.
2.4.6 Examples of the Layered Style
Figure 2.13 shows the primary presentation of a layered view from the NASA ECS system. The use of the layered approach allows for the design of the application architecture independently of the communication architecture. The ECS system architecture is layered, in that higher-layer services are allowed to use services in the layers below. Each layer can be thought of as an aggregation of services that form a specific service-layer class. These classes are evolving around market-driven segmentation, such as flight operations segment (FOS) and science data processing segment (SDPS). The segmentations are being grouped around the user disciplines most likely to use the services. This coupling of technical service descriptions with market-driven forces helps to encourage vendor development of products based on these services in specific horizontal or vertical market segments. The ECS architecture will be able to take advantage of all these points during the design process, including, but not limited to, standards and COTS selection.
Figure 2.13. A layered view from the ECS system documented in Appendix A. Here, software in a layer is allowed to use software in any layer it touches from above. For example, software in the Application Domain layer is allowed to use software in the Datalink/Physical layer but is not allowed to use software in the Network layer. Such rules of interpretation need to be explained in supporting documentation.
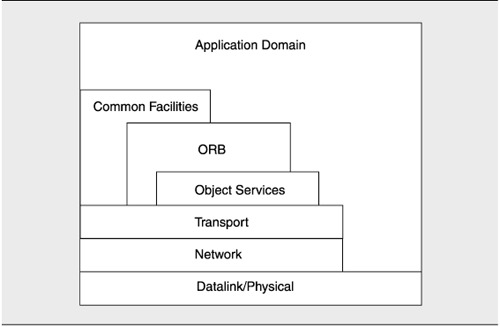
The application domain layer contains all the subsystems' services of two out of the three segments in which the ECS is decomposed: FOS and SDPS. Three service classes are shown in the three intermediate layers of Figure 2.13: the object services, the object request broker (ORB) [OMG 93], and the common facility. From an OSI [ISO 93] perspective, these service classes could be related to layers 5 to 7: the session, presentation, and application layers, respectively. These three layers constitute the communication subsystem. The set of services within this subsystem are functionally dependent on the services provided by the internetworking subsystem. The set of services provided by these layers are the fundamental communications interfaces for the FOS and the SDPS.
The lowermost three layers are the physical/datalink, network, and transport layers. These system components are part of the internetworking subsystem. The services provided by the internetworking subsystem are functionally independent of any other services outside themselves. The transport services rely solely on the network services that, in turn, rely on the datalink/physical services.
|

|
Software Architectures and Documentation
- P.1. The Role of Architecture
- P.2. Uses of Architecture Documentation
- P.3. Interfaces
- P.4. Views
- P.5. Viewtypes and Styles
- P.6. Seven Rules for Sound Documentation
- P.7. Summary Checklist
- P.8. Discussion Questions
- P.9. For Further Reading
Part I. Software Architecture Viewtypes and Styles
The Module Viewtype
- Overview
- Elements, Relations, and Properties of the Module Viewtype
- What the Module Viewtype Is For and What Its Not For
- Notations for the Module Viewtype
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Module Viewtype
- Styles of the Module Viewtype
- Decomposition Style
- Uses Style
- Generalization Style
- Layered Style
- Summary Checklist
- Discussion Questions
- For Further Reading
The Component-and-Connector Viewtype
- Overview
- Elements, Relations, and Properties of the C&C Viewtype
- What the C&C Viewtype Is For and What Its Not For
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Component-and-Connector Viewtype
- Styles of the Component-and-Connector Viewtype
- The Pipe-and-Filter Style
- Shared-Data Style
- Publish-Subscribe Style
- Client-Server Style
- Peer-to-Peer Style
- Communicating-Processes Style
- Notations for C&C Styles
- Summary Checklist
- Discussion Questions
- For Further Reading
The Allocation Viewtype and Styles
- Overview
- Elements, Relations, and Properties of the Allocation Viewtype
- Deployment Style
- Implementation Style
- Work Assignment Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Part II. Software Architecture Documentation in Practice
- Part II. Software Architecture Documentation in Practice
- ECS Architecture Documentation Roadmap
- ECS System Overview
- ECS Software Architecture View Template
- Mapping Between Views
- Directory
- Architecture Glossary and Acronym List
- Module Decomposition View
- Module Uses View
- Module Generalization View
- Module Layered View
- C&C Pipe-and-Filter View
- C&C Shared-Data View
- C&C Communicating-Processes View
- Allocation Deployment View
- Allocation Implementation View
- Allocation Work Assignment View
Advanced Concepts
- Advanced Concepts
- Chunking Information: View Packets, Refinement, and Descriptive Completeness
- Using Context Diagrams
- Combined Views
- Documenting Variability and Dynamism
- Creating and Documenting a New Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Software Interfaces
- Overview
- Interface Specifications
- A Standard Organization for Interface Documentation
- Stakeholders of Interface Documentation
- Notation for Interface Documentation
- Examples of Interface Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Behavior
- Beyond Structure
- Where to Document Behavior
- Why to Document Behavior
- What to Document
- How to Document Behavior: Notations and Languages
- Summary Checklist
- Discussion Questions
- For Further Reading
Choosing the Views
- Choosing the Views
- Stakeholders and Their Documentation Needs
- Making the Choice
- Two Examples
- Summary Checklist
- Discussion Questions
- For Further Reading
Building the Documentation Package
- Building the Documentation Package
- One Document or Several?
- Documenting a View
- Documentation Beyond Views
- Validating Software Architecture Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Other Views and Beyond
- Other Views and Beyond
- Overview
- Rational Unified Process/Kruchten 4+1
- UML
- Siemens Four Views
- C4ISR Architecture Framework
- ANSI/IEEE-1471-2000
- Data Flow and Control Flow
- RM-ODP
- Where Architecture Documentation Ends
- A Final Word
- For Further Reading
- Appendix A. Excerpts from a Software Architecture Documentation Package
- Volume I ECS Software Architecture Documentation Beyond Views
Rationale, Background, and Design Constraints
References
EAN: 2147483647
Pages: 152
