Shared-Data Style
4.2.1 Overview
In the shared-data style, the pattern of interaction is dominated by the exchange of persistent data. The data has multiple accessors and at least one shared-data store for retaining persistent data.
Database systems and knowledge-based systems are examples of this style. One feature of a shared-data style is the method by which the data consumer discovers that data of interest is available. If the shared-data store informs data consumers of the arrival of interesting data, the shared-data style is called a blackboard. If the consumer has responsibility for retrieving data, the shared-data style is called a repository. In modern systems, these distinctions have been blurred, as many database management systems that were originally repositories now provide a triggering mechanism that turns them into blackboards.
4.2.2 Elements, Relations, and Properties
The shared-data style, summarized in Table 4.2, is organized around one or more shared-data stores, which store data that other components may read and write. Component types include shared-data stores and data accessors. The general computational model associated with shared-data systems is that data accessors perform calculations that require data from the data store and writing results to one or more data stores. That data can be viewed and acted on by other data accessors. In a pure shared-data system, data accessors interact only through the shared-data store(s). However, many shared-data systems also allow direct interactions between nonstore elements. The data-store components of a shared-data system provide shared access to data, support data persistence, manage concurrent access to data, provide fault tolerance, support access control, and handle the distribution and caching of data values.
The stylistic specializations differ along two dimensions: the nature of stored data and the control model. In the blackboard style, data accessors are sometimes called knowledge sources, and the shared-data store is called the blackboard. The computational model for such systems is that knowledge sources are "triggered," or invoked, when certain kinds of data appear in the database. The computation of a triggered knowledge source will typically change the data in the blackboard, thereby triggering the actions of other knowledge sources. Blackboard systems differ in how the data is structured within the blackboard and in the mechanisms for prioritizing the invocation of knowledge sources when more than one is triggered.
| Elements |
|
| Relations | Attachment relation determines which data accessors are connected to which data repositories. |
| Computational model | Communication between data accessors is mediated by a shared-data store. Control may be initiated by the data accessors or the data store. |
| Properties | Same as defined by the C&C viewtype and refined as follows: types of data stored, data performance-oriented properties, data distribution. |
| Topology | Data accessors are attached to connectors that are attached to the data store(s). |
One of the first systems to employ the blackboard style was a speech-understanding system called Hearsay II [Nii 1986]. A more modern variation is provided by "tuple spaces," as exemplified by Linda and JavaSpaces. A tuple space is a repository that contain tuples, or lists of values. Clients communicate with one another by releasing dataa tupleinto tuple space. Clients can also register to be notified of changes in a tuple space. Other forms of such triggered databases are sometimes called continuous-query databases.
A particular portion of a system will be either a blackboard or a pure repository, depending on where the initiative lies in accessing data. Trigger mechanisms are common in systems that use work-flow management to inform data accessors of the modification of particular types of data making that use a blackboard. In other portions of such systems, the data accessor is responsible for initiating a query. Thus, it is important to identify those data accessors that can initiate a query and those that are triggered by actions on particular data. If data accessors are triggered by the respository, the circumstances under which the triggers are activated are important to document.
4.2.3 What the Shared-Data Style Is For and What It's Not For
The shared-data style is used whenever various data items have multiple accessors and persistence. Use of this style has the effect of decoupling the producer of the data from the consumers of the data; hence, this style supports modifiability, as the producers do not have direct knowledge of the consumers.
Analyses associated with this style usually center on performance, security, privacy, reliability, and compatibility with, for example, existing repositories and their data. In particular, when a system has more than one data store, a key architectural concern is the mapping of data and computation to the data stores and their local data accessors. For example, distributing data or providing redundant copies may improve performance but often at the cost of added complexity and a decrease in reliability and security.
4.2.4 Relation to Other Styles
This style has aspects in common with the client-server style, especially the n-tiered client-server form. In information management applications that use this style, the data store is often a relational database, providing relational queries and updates using client-server interactions. In other cases, the data store and its associated servers may provide an object-oriented data model, in which object methods become the main form of interaction with the data. Enterprise JavaBeans is a good example of an architectural framework in this style.
The publish-subscribe style is similar to the blackboard style except it lacks persistence of the data.
4.2.5 Example of the Shared-Data Style
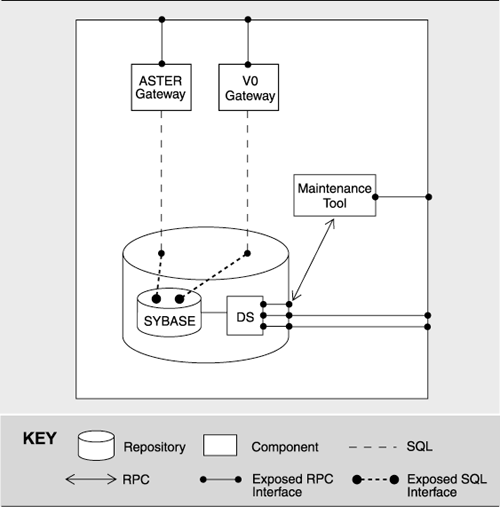
Figure 4.3, taken from Appendix A, shows part of a shared-data view of the ECS system.
Figure 4.3. The primary repository of the ECS system. The gateways and maintenance tool are data accessors; SYBASE and DS are components of the data repository.
Software Architectures and Documentation
- P.1. The Role of Architecture
- P.2. Uses of Architecture Documentation
- P.3. Interfaces
- P.4. Views
- P.5. Viewtypes and Styles
- P.6. Seven Rules for Sound Documentation
- P.7. Summary Checklist
- P.8. Discussion Questions
- P.9. For Further Reading
Part I. Software Architecture Viewtypes and Styles
The Module Viewtype
- Overview
- Elements, Relations, and Properties of the Module Viewtype
- What the Module Viewtype Is For and What Its Not For
- Notations for the Module Viewtype
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Module Viewtype
- Styles of the Module Viewtype
- Decomposition Style
- Uses Style
- Generalization Style
- Layered Style
- Summary Checklist
- Discussion Questions
- For Further Reading
The Component-and-Connector Viewtype
- Overview
- Elements, Relations, and Properties of the C&C Viewtype
- What the C&C Viewtype Is For and What Its Not For
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Component-and-Connector Viewtype
- Styles of the Component-and-Connector Viewtype
- The Pipe-and-Filter Style
- Shared-Data Style
- Publish-Subscribe Style
- Client-Server Style
- Peer-to-Peer Style
- Communicating-Processes Style
- Notations for C&C Styles
- Summary Checklist
- Discussion Questions
- For Further Reading
The Allocation Viewtype and Styles
- Overview
- Elements, Relations, and Properties of the Allocation Viewtype
- Deployment Style
- Implementation Style
- Work Assignment Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Part II. Software Architecture Documentation in Practice
- Part II. Software Architecture Documentation in Practice
- ECS Architecture Documentation Roadmap
- ECS System Overview
- ECS Software Architecture View Template
- Mapping Between Views
- Directory
- Architecture Glossary and Acronym List
- Module Decomposition View
- Module Uses View
- Module Generalization View
- Module Layered View
- C&C Pipe-and-Filter View
- C&C Shared-Data View
- C&C Communicating-Processes View
- Allocation Deployment View
- Allocation Implementation View
- Allocation Work Assignment View
Advanced Concepts
- Advanced Concepts
- Chunking Information: View Packets, Refinement, and Descriptive Completeness
- Using Context Diagrams
- Combined Views
- Documenting Variability and Dynamism
- Creating and Documenting a New Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Software Interfaces
- Overview
- Interface Specifications
- A Standard Organization for Interface Documentation
- Stakeholders of Interface Documentation
- Notation for Interface Documentation
- Examples of Interface Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Behavior
- Beyond Structure
- Where to Document Behavior
- Why to Document Behavior
- What to Document
- How to Document Behavior: Notations and Languages
- Summary Checklist
- Discussion Questions
- For Further Reading
Choosing the Views
- Choosing the Views
- Stakeholders and Their Documentation Needs
- Making the Choice
- Two Examples
- Summary Checklist
- Discussion Questions
- For Further Reading
Building the Documentation Package
- Building the Documentation Package
- One Document or Several?
- Documenting a View
- Documentation Beyond Views
- Validating Software Architecture Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Other Views and Beyond
- Other Views and Beyond
- Overview
- Rational Unified Process/Kruchten 4+1
- UML
- Siemens Four Views
- C4ISR Architecture Framework
- ANSI/IEEE-1471-2000
- Data Flow and Control Flow
- RM-ODP
- Where Architecture Documentation Ends
- A Final Word
- For Further Reading
- Appendix A. Excerpts from a Software Architecture Documentation Package
- Volume I ECS Software Architecture Documentation Beyond Views
Rationale, Background, and Design Constraints
References
EAN: 2147483647
Pages: 152
