Uses Style
2.2.1 Overview
The uses style of the module viewtype comes about when the depends-on relation is specialized to uses. An architect may employ this style to constrain the implementation of the architecture. This style tells developers what other modules must exist in order for their portion of the system to work correctly. This powerful style enables incremental development and the deployment of useful subsets of full systems.
2.2.2 Elements, Relations, and Properties
Table 2.2 summarizes the discussion of the characteristics of the uses style. The elements of this style are the modules as in the module viewtype. We define a specialization of the depends-on relation to be the uses relation, whereby one module requires the correct implementation of another module for its own correct functioning. This view makes explicit how the functionality is mapped to an implementation by showing relationships among the code-based elements: which elements use which other elements to achieve their functions.
2.2.3 What the Uses Style Is For and What It's Not For
This style is useful for planning incremental development, system extensions and subsets, debugging and testing, and gauging the effects of specific changes.
2.2.4 Notations for the Uses Style
Informal Notations
Informally, the uses relation is conveniently documented as a matrix, with the modules listed as rows and columns. A mark in element (x,y) indicates that module x uses module y. The finest-grained modules in the decomposition hierarchy should be the ones listed, as fine-grained information is needed to produce incremental subsets.
| Elements | Module as defined by the module viewtype. |
| Relations | The uses relation, which is a refined form of the depends-on relation. Module A uses module B if A depends on the presence of a correctly functioning B in order to satisfy its own requirements. |
| Properties of elements | As defined by the module viewtype. |
| Properties of relations | The uses relation may have a property that describes in more detail what kind of uses one module makes of another. |
| Topology | The uses style has no topological constraints. However, if loops in the relation contain many elements, the ability of the architecture to be delivered in incremental subsets will be impaired. |
The uses relation can also be documented as a two-column table, with using elements on the left and the elements they use listed on the right. Alternatively, informal graphical notations can show the relation by using the usual box-and-line diagram with a key. For defining subsets, a tabularthat is, nongraphicalnotation is preferred. It is easier to look up the detailed relations in a table than to find them in a diagram, which will rapidly grow too cluttered to be useful except in trivial cases.
UML
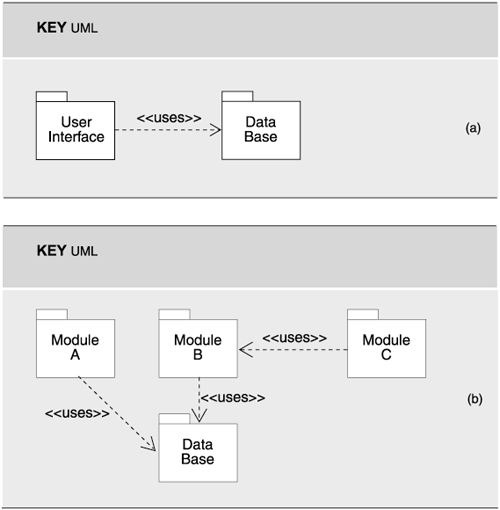
The uses style is easily represented in UML. The UML subsystem construct (see the graphic on page 64) can be used to represent modules; the uses relation is depicted as a dependency with the stereotype <>. In Figure 2.3(a), the User Interface module is an aggregate module with a uses dependency on the DataBase module. When a module is an aggregate, the decomposition requires that any uses relation involving the aggregate module be mapped to a submodule using that relation. In Figure 2.3(b), the User Interface module is decomposed into modules A, B, and C. At least one of the modules must depend on the DataBase module; otherwise, the decomposition is not consistent.
Figure 2.3. (a) The User Interface module is an aggregate module with a uses dependency on the DataBase module. We use UML Package notation to represent modules and the specialized form of depends-on arrow to indicate a uses relation. (b) Here is a variation of Figure 2.3(a) in which the User Interface module has been decomposed into modules A, B, and C. At least one of the modules must depend on the DataBase module or the decomposition would not be consistent.
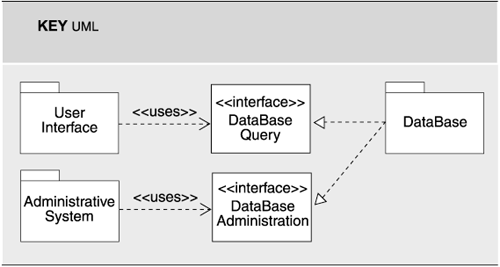
The convention for showing interfaces explicitly and separate from elements that realize them can also be shown in a uses view. In Figure 2.4, the DataBase module has two interfaces, which are used by the User Interface and the Administrative System modules, respectively.
Figure 2.4. UML can be used to represent the uses view and show interfaces explicitly. Here, the DataBase module has two interfaces, which are used by the User Interface and the Administrative System modules, respectively. The lollipop notation for interfaces would also work well here.
2.2.5 Relation to Other Styles
The uses style also goes hand in hand with the layered style, with the allowed-to-use relation governing. An allowed-to-use relation usually comes first and contains coarse-grained directives defining the degrees of freedom for implementers. Once implementation choices have been made, the uses view emerges and governs the production of incremental subsets.
2.2.6 Example of the Uses Style
The following, taken from Appendix A, is a small excerpt of a uses view's primary presentation. The notation is textual, using the two-column format described earlier. Like most primary presentations, this one names only the elements; they are defined in the view's supporting documentation (not shown here).
| SDPS Element | Uses This Element | ||
|---|---|---|---|
| Science Data Processing Segment | |||
| Ingest Subsystem | |||
| INGST CSCI | ADSRV CSCI in the Interoperability Subsystem | ||
| STMGT CSCI in the Data Server Subsystem | |||
| SDSRV CSCI in the Data Server Subsystem | |||
| DCCI CSCI in the Communications Subsystem | |||
| [etc.] | other CSCIs within the Ingest Subsystem | ||
| Data Server Subsystem | |||
| DDIST CSCI | MCI CSCI in the System Management Subsystem | ||
| DCCI CSCI in the Communications Subsystem | |||
| STMGT CSCI in the Data Server Subsystem | |||
| INGST CSCI in the Ingest Subsystem | |||
| [etc.] | other CSCIs within the Data Server Subsystem | ||
| [etc.] | other subsystems within the Science Data Processing Segment | ||
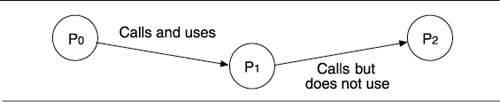
[1] Or perhaps it calls a program whose name was bound by a parameter at system-generation time or a program whose name it looks up via a name server. Many schemes are possible.
[2] Of course, calls and other depends-on relations must be given their due. If a program in the subset calls, includes, or inherits from another program but doesn't use it, the compiler is still going to expect that program to be present. But if it isn't used, there need not be a correct implementation of it: a simple stub, possibly returning a pro forma result, will do just fine.
Software Architectures and Documentation
- P.1. The Role of Architecture
- P.2. Uses of Architecture Documentation
- P.3. Interfaces
- P.4. Views
- P.5. Viewtypes and Styles
- P.6. Seven Rules for Sound Documentation
- P.7. Summary Checklist
- P.8. Discussion Questions
- P.9. For Further Reading
Part I. Software Architecture Viewtypes and Styles
The Module Viewtype
- Overview
- Elements, Relations, and Properties of the Module Viewtype
- What the Module Viewtype Is For and What Its Not For
- Notations for the Module Viewtype
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Module Viewtype
- Styles of the Module Viewtype
- Decomposition Style
- Uses Style
- Generalization Style
- Layered Style
- Summary Checklist
- Discussion Questions
- For Further Reading
The Component-and-Connector Viewtype
- Overview
- Elements, Relations, and Properties of the C&C Viewtype
- What the C&C Viewtype Is For and What Its Not For
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Component-and-Connector Viewtype
- Styles of the Component-and-Connector Viewtype
- The Pipe-and-Filter Style
- Shared-Data Style
- Publish-Subscribe Style
- Client-Server Style
- Peer-to-Peer Style
- Communicating-Processes Style
- Notations for C&C Styles
- Summary Checklist
- Discussion Questions
- For Further Reading
The Allocation Viewtype and Styles
- Overview
- Elements, Relations, and Properties of the Allocation Viewtype
- Deployment Style
- Implementation Style
- Work Assignment Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Part II. Software Architecture Documentation in Practice
- Part II. Software Architecture Documentation in Practice
- ECS Architecture Documentation Roadmap
- ECS System Overview
- ECS Software Architecture View Template
- Mapping Between Views
- Directory
- Architecture Glossary and Acronym List
- Module Decomposition View
- Module Uses View
- Module Generalization View
- Module Layered View
- C&C Pipe-and-Filter View
- C&C Shared-Data View
- C&C Communicating-Processes View
- Allocation Deployment View
- Allocation Implementation View
- Allocation Work Assignment View
Advanced Concepts
- Advanced Concepts
- Chunking Information: View Packets, Refinement, and Descriptive Completeness
- Using Context Diagrams
- Combined Views
- Documenting Variability and Dynamism
- Creating and Documenting a New Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Software Interfaces
- Overview
- Interface Specifications
- A Standard Organization for Interface Documentation
- Stakeholders of Interface Documentation
- Notation for Interface Documentation
- Examples of Interface Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Behavior
- Beyond Structure
- Where to Document Behavior
- Why to Document Behavior
- What to Document
- How to Document Behavior: Notations and Languages
- Summary Checklist
- Discussion Questions
- For Further Reading
Choosing the Views
- Choosing the Views
- Stakeholders and Their Documentation Needs
- Making the Choice
- Two Examples
- Summary Checklist
- Discussion Questions
- For Further Reading
Building the Documentation Package
- Building the Documentation Package
- One Document or Several?
- Documenting a View
- Documentation Beyond Views
- Validating Software Architecture Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Other Views and Beyond
- Other Views and Beyond
- Overview
- Rational Unified Process/Kruchten 4+1
- UML
- Siemens Four Views
- C4ISR Architecture Framework
- ANSI/IEEE-1471-2000
- Data Flow and Control Flow
- RM-ODP
- Where Architecture Documentation Ends
- A Final Word
- For Further Reading
- Appendix A. Excerpts from a Software Architecture Documentation Package
- Volume I ECS Software Architecture Documentation Beyond Views
Rationale, Background, and Design Constraints
References
EAN: 2147483647
Pages: 152
