Examples of Interface Documentation
Following are a few examples of interface documentation. For each, we point out what it does and does not show.
7.6.1 SCR-Style Interface
The first example comes from a U.S. Navy software engineering demonstration project, called the Software Cost Reduction (SCR) project. One of the project goals was to demonstrate model software architecture documentation, including interfaces. The example shown here is for a module generator. The interface is shown for both the generator and the generated elements. The generated module lets actors create and manipulate tree data structures with characteristics determined by the generation step.
In the SCR style, each interface document begins with an introduction that identifies the element and provides a brief account of its function.
TREE.1: Introduction
This module provides facilities for manipulating ordered trees. A complete discussion of ordered trees (hereafter simply called trees) appears in [Knuth]; for the purposes of this specification, the following definitions will suffice:
A tree is a finite non-empty set T of nodes partitioned into disjoint non-empty subsets { {R}, T1, . . . , Tn }, n>=0, where R is the root of T and each subset Ti is itself a tree (a subtree of R). The root of each Ti is a child of R, and R is its parent. The children of R (siblings of one another) are ordered, being numbered from 1 to n, with child 1 the eldest and child n the youngest. Every node also stores a value.
The size of the tree T is the number of nodes in T. The degree of a node is the number of children it has; a node of degree 0 is a leaf. The level of a node in a tree is defined with respect to the tree's root: the root is at level 1, and the children of a level N node are at level N+1. The height (sometimes also called depth) of a tree is the maximum level of any node in the tree.
Using the facilities defined in section TREE.2.1, a user provides (1) a name N for a type whose variables can hold values that denote tree nodes, and (2) the type D of values that a tree node can hold. This generates a submodule that defines the type N and implements the operations on variables of type N specified in section TREE.2.2. These operations include creating, deleting, and linking nodes, and fetching and storing the datum associated with each node.
SCR-style interfaces do not include a usage guide per se, but note how the introduction explains basic concepts and talks about how the element can be used.
The next part of an SCR interface is a table that specifies the syntax of the resources and provides a quick-reference summary of those resources: in this case, methodlike routines called access programs. The programs are named, their parameters are defined, and the exceptions detected by each are listed. Parameters are noted as I (input), O (output), I-OPT (optional input), or O-RET (returned as function results). This quick-reference summary, called an Interface Overview, provides the signature for the resources in a language-independent fashion.
TREE.2: Interface Overview (excerpt)
| TREE.2.1: Generator access program | |||
|---|---|---|---|
| Program Name | Parameter Type | Parameter Info | Exceptions |
| ++gen++ | p1: id; I | value for !! | %%bad capacity%% |
| p2: name; I | value for !! | %%bad id%% | |
| p3: typename; I | value for !! | %%bad max fanout%% | |
| p4: integer; I | value for !! | %%bad name%% | |
| p5: integer; I | value for !! | %%bad typename%% | |
| p6: string; I-OPT | exception handler command | %%cannot write%% | |
| p7: integer; O-RET | return code | %%conflict%% | |
| %%io error%% | |||
| %%recursive%% | |||
| %%system error%% | |||
| %%too long%% | |||
| TREE.2.2: Access programs of generated module | |||
|---|---|---|---|
| Program Name | Parameter Type | Parameter Info | Exceptions |
| Programs that inquire about the universe of nodes | |||
| +g_avail+ | p1: integer; O_RET | !+avail+! | None |
| Programs that affect the structure of trees | |||
| +add_first+ | p1: !!; I | reference node | %not a node% |
| +add_last+ | p2: !!; I | node to adopt | %already a child% |
| %is root of tree% | |||
| %too many children% | |||
At this point, the syntax of the resources has been specified. Semantics are provided in two ways. First, for programs that simply return the result of a querycalled get programs and prefixed with gthe returned argument is given a name, and its value is defined in the term dictionary. These programs have no effect on the future behavior of the element. Second, each of the other programs has an entry in an "effects" section to explain its results. You can think of this section as a precondition/postcondition approach to specifying semantics, except that the preconditions are implied by the exceptions associated with each resource. That is, the precondition is that the state described by the exception does not exist. In the following, note how each statement of effects is observable; that is, you could write a program to test the specification. For example, an effect of calling +s_datum+(p1,p2) is that an immediately following call to +g_datum+(p1) returns p2.
TREE.2.2.2 Effects (excerpt)
Note: Because +g_first+, +g_last+, and +g_is_null_node+ are defined completely in terms of other programs, the effects on these three programs are not listed below; they follow directly from the effects given on the programs in terms of which they are defined.
+add_first++g_num+(p1) = 1+'+g_num+'(p1) +g_nth+(p1,1) = p2 For all i: integer such that (1 1==> ( +g_next+(p2) = '+g_nth+'(p1,1) and +g_prev+('+g_nth+'(p1,1)) = p2 ) +g_parent+(p2) = p1 For all n: !!, '+g_is_in_tree+'(p1,n) ==> ( +g_size+(n) = '+g_size+'(n) + +g_size+(p2) and For all k: !!, '+g_is_in_tree+'(k,p2) ==> +g_is_in_tree+(k,n) )
An SCR-style interface continues with a set of dictionaries that explain, respectively, the data types used, semantic terms introduced, exceptions detected, and configuration parameters provided. Configuration parameters represent the element's variability. Bracket notation lets a reader quickly identify which dictionary contains a term's definition: $data type literal$, !+semantic term+!, %exception%, and #configuration parameter#.
| TREE.3: Locally defined data types (excerpt) | |
|---|---|
| Type | Definition |
| integer | common type as defined in [CONV] |
| !! | The set of values of this type is a secret of this module. |
| TREE.4: Dictionary (excerpt) | |
|---|---|
| Term | Definition |
| !+avail+! | The number of new nodes that can be created without an intervening call to +destroy_tree+. Initially = #max_num_nodes#. |
| !+equal+! | p1 and p2 denote the same node (that is, p1 and p2 contain the same value). Assignment of a to b makes a and b denote the same node. |
| TREE.5: Exceptions dictionary (excerpt) | |
|---|---|
| Exception | Definition |
| %already a child% | +g_is_node+(+g_parent+(p2)). |
| %is root of tree% | +g_is_in_tree+(p1,p2). |
| %not a node% | For some input parameter pj of type !!, ~+g_is_node+(pj). |
| %too many children% | For +add_first/last+: +g_num+(p1) = #max_num_children#. |
| For +ins_next/prev+: +g_num+(+g_parent+(p1)) = #max_num_children# | |
| TREE.6: System configuration parameters (excerpt) | |
|---|---|
| Parameter | Definition |
| ##max_capacity## | The maximum value of #max_num_nodes# for any generated submodule. |
| ##max_max_fanout## | The maximum value of #max_num_children# for any generated submodule. |
| #max_num_children# | The maximum number of children that any node can have ( = !!). |
| #max_num_nodes# | The maximum number of nodes that can exist at a time ( = !!). |
Following the dictionaries, an SCR-style interface includes background information: design issues and rationale, implementation notes, and a set of so-called basic assumptions that summarize what the designer assumed would be true about all elements realizing this interface. Those assumptions form the basis of a design review for the interface.
TREE.7: Design Issues (excerpt)
- How much terminology to define in the introduction.
Several terms (leaf, level, depth) are defined in the introduction but not used anywhere else in this specification. These terms have been defined here only because they are expected to prove useful in the specifications of modules that use trees.
- How to indicate a nonexistent node.
How is the fact that a node has no parent, nth child, or older or younger sibling to be communicated to users of the module? Two alternatives were considered: (a) have the access programs that give the parent, and so on, of a node return a special value analogous to a null pointer; (b) have additional access programs for determining these facts.
Option (a) was chosen because (1) it allows a more compact interface with no less capability, (2) it allows a user to make a table of nodes, some entries of which are empty, much more conveniently, and (3) it has the minor advantage of resembling the common linked implementation of trees, and thus may be viewed as more natural.
Note that (a) may mimic (b) quite simply; comparing the result of the returned value with the special null value is equivalent to node has a parent, eldest child, or whatever. If the set of values of type !! is defined to include a null value, then (b) may also mimic (a), since (b) is then a superset of (a).
- How to move from node to node.
"Moving from node to node" consists of getting the node that bears the desired relation to the first node. Several ways of accessing siblings were considered:
- Sequentially, allowing moves to the next or previous sibling in the sequence.
- By an index, allowing moves to the nth of the sequence of siblings.
- Sequentially, but allowing moves of more than one sibling at a time.
Option (c) seemed of marginal utility and was thus not included. Option (b) was included for generality. Although (a) is not strictly necessary if (b) is available, (a) was nevertheless also included because (a) can usually be implemented in a considerably more efficient manner.
TREE.8: Implementation Notes: none
TREE.9: Assumptions (excerpt)
- The children of a node must be ordered.
- It suffices that construction of trees be possible by a combination of creation of trees consisting of single nodes and attachment of trees as subtrees of nodes.
- For our purposes, the following manipulations of trees are sufficient: (1) replication of a tree, (2) addition of a subtree at either end of the list of subtrees of a node, (3) insertion of a subtree before or after a subtree in the list of subtrees of a node, (4) disassociation of a subtree from the tree that contains it.
Not shown in this example is an efficiency guide that lists the time requirements of each resource, the SCR analog to the quality attribute characteristics that we prescribe in our outline for an interface. Other quality attrtributes could be described here as well. The one piece of interface information that SCR-style interface specifications do not provide is what the element requires.
7.6.2 IDL
A small sample interface specified in OMG IDL is shown in Figure 7.8. The interface is for an element that manages a bank account.
Figure 7.8. An example of IDL for an element in a banking application (Bass, Clements, and Kazman 1998, p. 177). The element provides resources to manage a financial account. An account has attributes of "balance" and "owner." Operations provided are deposit and withdraw.

Although syntax is specified unambiguously in this type of documentation, semantic information is largely missing. For example, can a user make arbitrary withdrawals? Withdrawals only up to the current account balance? Up to a daily limit? Up to a minimum balance? If any of these restrictions is true, what happens if it's violated? Is the maximum permissible amount withdrawn, or is the transaction as a whole canceled? IDL by itself is inadequate when it comes to fully documenting an interface, primarily because IDL offers no language constructs for discussing the semantics of an interface; without expression of the semantics, ambiguities and misunderstandings will abound.
7.6.3 Custom Notation
The High Level Architecture (HLA) was developed by the U.S. Department of Defense (DoD) to provide a common architecture for distributed modeling and simulation. To facilitate intercommunication, HLA allows simulations and simulators, called federates, to interact with each other via an underlying software infrastructure known as the Runtime Infrastructure (RTI). The interface between federates and an RTI is defined in IEEE standard 1516.1 (IEEE 2000b).
The RTI provides services to federates in a way that is analogous to how a distributed operating system provides services to applications. The interface specification defines the services provided by the RTI and used by the federates.
This is an example in which the focus is on defining an interface that will be realized by a number of different elements. HLA was designed to facilitate interoperability among simulations built by various parties. Hence, simulations can be built by combining elements that represent different players into what is called a federation. Any element that realizes the HLA interface is a viable member of the simulation and will be able to interact meaningfully with other simulation elements that are representing other active parties.
Because of the need to ensure meaningful cooperation among elements that are built with little knowledge of one another, a great deal of effort went into specifying not just the syntax of the interface but also the semantics. The extract from the HLA Interface Specification presented in Figure 7.9 describes a single resource, a method, of the interface. Lists of preconditions and postconditions are associated with the resource, and the overview provides a context for the resource and explains its use within the context of the full HLA interface. The resource, a method, is called Negotiated Attributed Ownership Divestiture.
Figure 7.9. Example of documentation for an interface resource, taken from the HLA (IEEE 2000b, p. 104)

The full HLA interface specification contains more than 140 resources like the one in Figure 7.9, and the majority have some interaction with other resources. For example, using some resources will cause the preconditions of the presented resource to no longer be true with respect to specific arguments. There are a number of such restrictions on the order in which the resources can be used.
To facilitate an understanding of the implicit protocol of usage among the resources, the HLA interface specification presents a summary of this information. Figure 7.10 depicts the constraints on the order of use of a specific set of the resources. This type of summary information is valuable in providing both an introduction to the complexities of an interface and a concise reminder to those already familiar with the interface. Without the summary, users would have to carefully read all the preconditions and postconditions of the 140 resources to reveal the restrictions. This is not trivial, and it is unrealistic to expect every user of the interface document to go through this kind of exercise.
Figure 7.10. This statechart shows the constraints on the order of use of a specific set of resources. Statecharts like this show an entire protocol in which a resource is used. The method described earlier is in the top center, highlighted in a circle. This shows the states during which the method can be invoked, and the state that is entered when it is invoked (IEEE 2000b, p. 97).
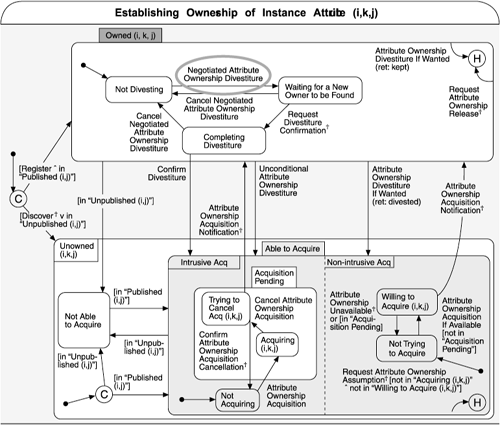
Note that the one thing that the IDL example presented very clearlythe syntax of the resourcesis lacking in what has been shown so far in the HLA example. In fact, the HLA interface documentation distinguishes between what it calls an "abstract interface document" (Figure 7.9) and a number of different programming language representations of the interface, each of which is specified in a manner similar to the IDL example.
This separation is an example of how an interface document can be packaged into units that are appropriate for different stakeholders. The semantic specification is sufficient for architects examining the HLA for potential use. Developers of elements implementing the interface, on the other hand, need both the semantic specification and one or more of the programming language representations for syntactic information.
FOR MORE INFORMATIONStatecharts are described in Section 8.5.2. |
7.6.4 XML
Extensible Markup Language (XML) is a language for describing documents of structured information. As such, XML can be used to document the information that will be exchanged across an interface. Data elements can be defined as XML documents. A sample data element, a personal record, follows:
John Doe
123 Main St. anywhere somewhere 12345 US
In this example, person is the root-level element of the XML document and contains elements firstName, lastName, and address, which in turn is made up of five other elements.
Using XML to exchange information at runtime offers several benefits:
- All information is textual, making it easily readable by humans and portable across platforms.
- It is possible to include a description of what constitutes a valid document in an XML document itself; alternatively, a reference, identified by a uniform resource indicator (URI), to such a description can be supplied.
- Actors exchanging information via XML need not conform to exactly the same version of an interface. It is a simple task for one actor to read the subset of an XML document that it understands and ignore the rest of the document.
- Tool support, such as browsers and parsers, is readily available for a variety of commonly used programming languages.
Document type declarations (DTDs) or schemas can be used to document the types of elements allowed within a document and to constrain the order in which those elements can be arranged. Either form can be used for runtime validity checking or as a simple documentation aid.
However, DTDs provide only syntactic interface documentation at best. Just as when producing IDL-based interface documentation, the burden of specifying semantic information is left to the documenter of an XML interface. XML contains no effective language constructs for conveying semantic information.
The Simple Object Access Protocol (SOAP) describes a framework wherein XML documents are exchanged by actors as a means of implementing an RPC mechanism. The exact documents that are exchanged are left to be defined as part of any application using SOAP. So, although the standard does provide a bit of semantic information in terms of the role that the XML documents serverequests and responsesit is still up to the documenter to provide application semantics to each document type, for example, what an "execute" document instructs an actor to do and what the permissible responses are.
XML is a useful means of representing data used in interfaces and provides a convenient way to specify the resource syntax portion of an interface. But XML does not absolve the documenter of the responsibility to fill in the resource semantics portion.
7 7 Summary Checklist |
Software Architectures and Documentation
- P.1. The Role of Architecture
- P.2. Uses of Architecture Documentation
- P.3. Interfaces
- P.4. Views
- P.5. Viewtypes and Styles
- P.6. Seven Rules for Sound Documentation
- P.7. Summary Checklist
- P.8. Discussion Questions
- P.9. For Further Reading
Part I. Software Architecture Viewtypes and Styles
The Module Viewtype
- Overview
- Elements, Relations, and Properties of the Module Viewtype
- What the Module Viewtype Is For and What Its Not For
- Notations for the Module Viewtype
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Module Viewtype
- Styles of the Module Viewtype
- Decomposition Style
- Uses Style
- Generalization Style
- Layered Style
- Summary Checklist
- Discussion Questions
- For Further Reading
The Component-and-Connector Viewtype
- Overview
- Elements, Relations, and Properties of the C&C Viewtype
- What the C&C Viewtype Is For and What Its Not For
- Relation to Other Viewtypes
- Summary Checklist
- Discussion Questions
- For Further Reading
Styles of the Component-and-Connector Viewtype
- Styles of the Component-and-Connector Viewtype
- The Pipe-and-Filter Style
- Shared-Data Style
- Publish-Subscribe Style
- Client-Server Style
- Peer-to-Peer Style
- Communicating-Processes Style
- Notations for C&C Styles
- Summary Checklist
- Discussion Questions
- For Further Reading
The Allocation Viewtype and Styles
- Overview
- Elements, Relations, and Properties of the Allocation Viewtype
- Deployment Style
- Implementation Style
- Work Assignment Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Part II. Software Architecture Documentation in Practice
- Part II. Software Architecture Documentation in Practice
- ECS Architecture Documentation Roadmap
- ECS System Overview
- ECS Software Architecture View Template
- Mapping Between Views
- Directory
- Architecture Glossary and Acronym List
- Module Decomposition View
- Module Uses View
- Module Generalization View
- Module Layered View
- C&C Pipe-and-Filter View
- C&C Shared-Data View
- C&C Communicating-Processes View
- Allocation Deployment View
- Allocation Implementation View
- Allocation Work Assignment View
Advanced Concepts
- Advanced Concepts
- Chunking Information: View Packets, Refinement, and Descriptive Completeness
- Using Context Diagrams
- Combined Views
- Documenting Variability and Dynamism
- Creating and Documenting a New Style
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Software Interfaces
- Overview
- Interface Specifications
- A Standard Organization for Interface Documentation
- Stakeholders of Interface Documentation
- Notation for Interface Documentation
- Examples of Interface Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Documenting Behavior
- Beyond Structure
- Where to Document Behavior
- Why to Document Behavior
- What to Document
- How to Document Behavior: Notations and Languages
- Summary Checklist
- Discussion Questions
- For Further Reading
Choosing the Views
- Choosing the Views
- Stakeholders and Their Documentation Needs
- Making the Choice
- Two Examples
- Summary Checklist
- Discussion Questions
- For Further Reading
Building the Documentation Package
- Building the Documentation Package
- One Document or Several?
- Documenting a View
- Documentation Beyond Views
- Validating Software Architecture Documentation
- Summary Checklist
- Discussion Questions
- For Further Reading
Other Views and Beyond
- Other Views and Beyond
- Overview
- Rational Unified Process/Kruchten 4+1
- UML
- Siemens Four Views
- C4ISR Architecture Framework
- ANSI/IEEE-1471-2000
- Data Flow and Control Flow
- RM-ODP
- Where Architecture Documentation Ends
- A Final Word
- For Further Reading
- Appendix A. Excerpts from a Software Architecture Documentation Package
- Volume I ECS Software Architecture Documentation Beyond Views
Rationale, Background, and Design Constraints
References
EAN: 2147483647
Pages: 152
