Buffer Overflows
Programmers have a difficult job. Faced with tight deadlines and the need to get products to market quickly, security might be the last thing on their minds. The first series of tests are probably performed by the programmers and quality engineers to get an idea of how applications will function. Beta testing comes next and might be performed internally and externally by prospective users, but after that it's off to market. There might still be some bugs, but these things can be caught by the consumers and patched in subsequent versions or updates.
That scenario would sound unbelievable if this were about the airline business or implantable medical devices, but it is common practice in the world of software. Most of us have grown accustomed to hearing that a new buffer overflow has been announced by Microsoft or other software vendor. A review of the National Vulnerability Database shows that in the first six months of 2005, 331 buffer overflows were reported. This is not a small problem.
What Is a Buffer Overflow?
|
Objective:
|
What are buffer overflows? Well, they are really too much of a good thing. Usually we don't complain when we get more of something than we ask for, but buffer overflows give us just that. If you have ever tried to pour a liter of your favorite soda into a 12 ounce cup, you know what an overflow is. Buffers work in much the same way Buffers have a finite amount of space allocated for any one task. As an example, if you have allocated a 24 character buffer and then attempt to stuff 32 characters into it, you're going to have a real problem.
A buffer is a temporary data storage area whose length is defined in the program that creates it or by the operating system. Ideally, programs should be written to check that you cannot stuff 32 characters into a 24 character buffer. However, this type of error checking does not always occur. Error checking is really nothing more than making sure that buffers receive the type and amount of information required. For example, I once did a pen test for an organization that had a great e-commerce website. The problem was that on the order entry page, you could enter a negative value. Instead of ordering 20 of an item, the page would accept 20. This type of functionality could add some quick cash to the unethical hacker's pocket! Although this isn't a specific example of buffer overflow, it is a good example of the failure to perform error checking. These types of problems can lead to all types of security breaches, as values will be accepted by applications no matter what the format. Most of the time, this might not even be a problem. After all, most end users are going to input the types of information they are prompted for. But, do not forget the hacker; he is going to think outside the box. The hacker will say, "What if I put more numbers than the program asks for?" The result might be that too long a string of data overflows into the area of memory following what was reserved for the buffer. This might cause the program to crash, or the information might be interpreted as instructions and executed. If this happens, almost anything is possible, including opening a shell command to executing customized code.
Why Are Programs Vulnerable?
Programs are vulnerable for a variety of reasons, although primarily because of poor error checking. The easiest way to prevent buffer overflows is to stop accepting data when the buffer is filled. This task can be accomplished by adding boundary protection. C is particularly vulnerable to buffer overflows because it has many functions that do not properly check for boundaries. For those of you familiar with C, you probably remember coding a program similar to the one seen here:
#include
int main( void )
{
printf("%s", "Hello, World!");
return 0;
}
This simple "Hello World!" program might not be vulnerable, but it doesn't take much more than this for a buffer overflow to occur. Table 11.1 lists functions in the C language that are vulnerable to buffer overflows.
|
Function |
Description |
|---|---|
|
Strcpy |
Copies the content pointed by src to dest, stopping after the terminating null-character is copied. |
|
Fgets |
Gets line from file pointer. |
|
Strncpy |
Copies 'n' bytes from one string to another; might overflow the dest buffer. |
|
Gets |
Reads a line from the standard input stream stdin and stores it in a buffer. |
|
Strcat |
Appends src string to dest string. |
|
Memmove |
Moves one buffer to another. |
|
Scanf |
Reads data from the standard input (stdin) and stores it into the locations given by arguments. |
|
Memcpy |
Copies num bytes from the src buffer to memory location pointed by destination. |
Exam Alert
C programs are especially susceptible to buffer overflow attacks.
It's not just these functions that get programmers in trouble, it's also the practice of making assumptions. It is really easy to do, because everyone assumes that the user will enter the right kind of data or the right amount. That might typically be the case, but what if too much or the wrong type of data were entered? The following example shows what happens if we set up some code to hold 24 characters, but then try to stuff 32 characters in.
void func1(void)
{
int I; char buffer[24];
for(1=0;i<32;i++)
buffer[i]='Z'
return;
}
If this code were run, it would most likely produce a segmentation fault because it attempts to stuff 32 "Zs" into a buffer designed for only 24. A segmentation fault occurs because our program is attempting to access memory locations that it is not allowed to access. If an attacker attempts only to crash the program, this is enough for him to accomplish that goal. After all, the loss of availability represents a major threat to the security of a system or network. If the attacker wants to take control of the vulnerable program, he will need to take this a step further. Having an understanding of buffer overflow attacks is required. Now, it's not just C that is vulnerable. Really high-level programming languages, such as Perl, are more immune to this problem. However, the C language provides little protection against such problems. Assembly language also provides little protection. Even if most of your program is written in another language, many library routines are written in C or C++, so you might not have as complete a protection from buffer overflows as you'd think.
Understanding Buffer Overflow Attacks
For a buffer overflow attack to be successful, the objective is to overwrite some control information to change the flow of the control program. Smashing the stack is the most widespread type of buffer overflow attack. One of the first in-depth papers ever written on this was by Aleph One, "Smashing the Stack for Fun and Profit." It was originally published by Phrack magazine and can be found at www.insecure.org/stf/smashstack.txt.
As discussed previously, buffer overflows occur when a program puts more data into a buffer than it can hold. Buffers are used because of the need to hold data and variables while a program runs. RAM is much faster than a hard drive or floppy disks, so it's the storage option of choice. Therefore, when a program is executed, a specific amount of memory is assigned to each variable. The amount of memory reserved depends on the type of data the variable is expected to hold. The memory is set aside to hold those variables until the program needs them. These variables can't just be placed anywhere in memory. There has to be some type of logical order. That function is accomplished by the stack. The stack is a reserved area of memory where the program saves the return address when a call instruction is received. When a return instruction is encountered, the processor restores the current address on the stack to the program counter. Data, such as the contents of the registers, can also be saved on the stack. The push instruction places data on the stack, and the pop instruction removes it. A typical program might have many stacks created and destroyed as programs can have many subroutines. Each time a subroutine is created, a stack is created. When the subroutine is finished, a return pointer must tell the program how to return control to the main program.
How is the stack organized? Many computerized functions are built around a first in first out (FIFO) structure; however, stacks are not. Stacks are organized in a last in first out structure (LIFO). For example, if you planned to move and had to pack all your dishes into a box, you would start placing them in one by one. After you arrive at your new home, the last plate you placed in the box would be the first one you would take out. To remove the bottom plate, all others would have to be pulled off the stack first. That's how stacks work. Placing a plate in the box would be known as a push; removing a plate from the box is a pop. Figure 11.1 shows the structure of the stack.
Figure 11.1. Normal operation of a stack.
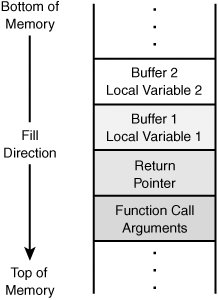
In Figure 11.1, notice that the function call arguments are placed at the bottom of the stack. That's because of the LIFO structure of the stack. The first thing placed on the stack is the last thing removed. When the subroutine finishes, the last item of business will be to retrieve the return pointer off the stack where it can return control to the calling program. Therefore, a pointer is really just an object whose value denotes the address in memory of some other object. Without this pointer or if the value in this location were overwritten, the subroutine would not be capable of returning control to the calling program. If an attacker can place too much information on the stack or change the value of the return pointer, he can successfully smash the stack. The next paragraph provides more detail.
For an attacker to do anything more than crash the program, he will need to be able to precisely tweak the pointer. Here is why. If the attacker understands how the stack works and can precisely feed the function the right amount of data, he can get the function to do whatever he wants, such as opening a command shell. Tweaking the pointer is no small act. The attacker must precisely tune the type and amount of data that is fed to the function. The buffer will need to be loaded with attacker's code. This code can be used to run a command or execute a series of low level instructions. As the code is loaded onto the stack, the attacker must also overwrite the location of the return pointer. This is key as then the attacker can redirect the pointer to run the code in the buffer rather than returning control to the calling program. This is illustrated in Figure 11.2.
Figure 11.2. Smashed stack.
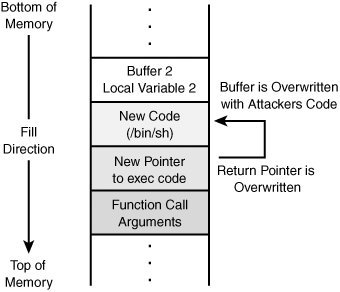
Another key point in this is when you stop to consider the access at which the program operates. For example, if the program that is attacked with the buffer overflow runs as root, system, or administrator, so is the code that the attacker executes. This can result in full control of the system in one quick swipe. Although it might sound easy, there are a number of things that must be accomplished to make this work in real life. These include
- Know the exact address of the stack
- Know the size of the stack
- Make the return pointer point to the attacker's code for execution
With these items taken care of and a little knowledge of assembly language, buffer overflow attacks are relatively easy to accomplish. Even if you don't know the exact address on the stack, it's still possible to accomplish a buffer overflow with the help of a NOP (No Operation), which is a one byte long assembly language instruction that performs no operation. In assembly language, a NOP is represented by the hex value 0X90. A small section of assembly code is shown here with several NOPs and some other functions, such as MOV and SUB.
{
00401078 55 push ebp
00401079 8B EC mov ebp,esp
0040107B 83 EC 08 sub esp,8
00401081 89 55 F8 mov dword ptr [ebp-4],edx
00401084 89 4D FC mov dword ptr [ebp-2],ecx
00401087 90 nop
00401088 90 nop
}
NOP makes it much easier for the attacker to execute the attack. The front of the buffer overflow is padded with NOPs. Somewhere near the center of the buffer overflow is where the attack is placed. At the end of the buffer overflow is the return pointer's new return address. If the attacker is lucky and the return address is anywhere in the NOPs, the NOPs will get executed until they count down to the actual attack code.
Stack smashing isn't the only kind of buffer overflow attack. There are also heap-based buffer overflows. A heap is a memory space that is dynamically allocated. Heap based buffer overflows are different from stack based buffer overflows in that the stack-based buffer overflow depends on overflowing a fixed length buffer.
Common Buffer Overflow Attacks
|
Objective:
|
Now that you know about buffer overflows, you should have some idea of their power. There has been no shortage of programs that have exploited buffer overflows over the years. Some well-known programs include
- The Morris worm Used a buffer overflow in a UNIX program called fingerd.
- Code Red worm Sent specially crafted packets that caused a buffer overflow to computers running Microsoft Internet Information Services (IIS) 5.0. The result was full administrative privileges to the exploit because IIS5 didn't drop administrative privileges after binding to port 80.
- The SQLSlammer worm Compromised machines running Microsoft SQL Server 2000 by sending specially crafted packets to those machines and allowing execution of arbitrary code.
- Microsoft Windows Print Spooler A buffer overflow that allowed full access after sending a buffer overflow of 420 bytes.
- Apache 1.3.20 Sending a long trail of backslashes can cause a buffer overflow that will result in directory listings.
- Microsoft Outlook 5.01 Malformed Email MIME header results in a buffer overflow that allows an attacker to execute upon download from the mail server.
- Remote Procedure Call (RPC) Distributed Component Object Model (DCOM)By sending a specially crafted packet, a remote attacker could cause a buffer overflow in the RCP service to gain full access and execute any code on a target machine.
The examples indicate the extent of this problem. Listing all the buffer overflows that have affected modern computer systems wouldn't be possible in the context of this book. To get some idea of the amount of buffer overflows that have been discovered and to make sure that your programs are properly patched, take a few minutes to visit the up-to-date National Vulnerability Database. It's located at http://nvd.nist.gov.
Preventing Buffer Overflows
|
Objective:
|
Because buffer overflows are such a problem, you can see that any hacker, ethical or not, is going to search for them. The best way to prevent them is to have perfect programs. That isn't really possible, but there are things you can do if the code is being developed in-house, such as
- Audit the code Nothing works better than a good manual audit. The individuals who write the code should not be the ones auditing the code. This should be performed by a different group. These individuals need to be trained to look for poorly written code and potential security problems.
- Use safer functions There are programming languages that offer more support against buffer overflows than C.
- Improved compiler techniques Compilers, such as Java, automatically check if a memory array index is working within the proper bounds.
- Disable stack execution If it's already compiled, disable stack execution. There are even programs, such as StackGuard, that harden a stack against smashing.
Note
A range of software products can be used to defend against buffer overflows, including Return Address Defender (RAD), StackGuard, and Immunix.
You might think that all these recommendations are great; however you're most worried about all the off-the-shelf applications used in your organization. Luckily, there are some basic measures for those applications that can also be taken. Five of these are listed here:
- Turn it off Practice the principle of least privilege. If the application or service is not needed by the employee, group, or customer, turn in off. Denying the attacker access to the vulnerable application prevents the buffer overflow. The deny all rule helps here also. This simply means turn off all services and only give users the minimum of what is needed.
- Patch, patch, and patch again Patching is a continual process. Just because the application you're using today seems secure doesn't mean that it will be next week. Vulnerabilities are constantly discovered. A lot of automated patch management systems are available. If you're not using one, check some out.
- Use a firewall Firewalls have a real role in the defense of the network. Although they might not protect the company from the guy down the hall, they do protect against outside threats. Just because a rule set has been implemented doesn't mean that it works. Test it; that's probably part of what they are paying you for during your ethical hack.
- Test applications Nothing should be taken at its word. Sure, the developer or vendor said it's a great software product, but is it really? Testing should include trying to feed it large or unusual amounts of data.
- Practice the principle of least privilege Can you believe that Internet Information Server (IIS) ran with administrator privileges all the way up to IIS version 5? That is probably what the creator of Code Red thought when he realized his worm only had to buffer overflow IIS to have complete administrative control of the victim. Don't let this happen on your applications. Remember that a key concept of buffer overflows is that the attacker's code runs at the level of control that the program has been granted.
Although the items listed here are not guaranteed to prevent buffer overflows, they will make it significantly harder for the attacker. These controls add to the organization's defense in depth.
Viruses and Worms |
Part I: Exam Preparation
The Business Aspects of Penetration Testing
- The Business Aspects of Penetration Testing
- Study Strategies
- Security Fundamentals
- Security Testing
- Hacker and Cracker Descriptions
- Ethical Hackers
- Test PlansKeeping It Legal
- Ethics and Legality
- Summary
- Key Terms
- Apply Your Knowledge
The Technical Foundations of Hacking
- The Technical Foundations of Hacking
- Study Strategies
- The Attackers Process
- The Ethical Hackers Process
- Security and the Stack
- Summary
- Key Terms
- Apply Your Knowledge
Footprinting and Scanning
- Footprinting and Scanning
- Study Strategies
- Determining Assessment Scope
- The Seven-Step Information Gathering Process
- Summary
- Key Terms
- Apply Your Knowledge
Enumeration and System Hacking
- Enumeration and System Hacking
- Study Strategies
- The Architecture of Windows Computers
- Enumeration
- Windows Hacking
- Summary
- Key Terms
- Apply Your Knowledge
Linux and Automated Security Assessment Tools
- Linux and Automated Security Assessment Tools
- Study Strategies
- Linux
- Automated Assessment Tools
- Picking the Right Platform
- Summary
- Key Terms
- Apply Your Knowledge
Trojans and Backdoors
- Trojans and Backdoors
- Study Strategies
- An Overview of TrojansThe History of Trojans
- Covert Communications
- Trojan and Backdoor Countermeasures
- Summary
- Key Terms
- Apply Your Knowledge
Sniffers, Session Hijacking, and Denial of Service
- Sniffers, Session Hijacking, and Denial of Service
- Study Strategies
- Sniffers
- Session Hijacking
- Denial of Service
- Summary
- Key Terms
- Apply Your Knowledge
Web Server Hacking, Web Applications, and Database Attacks
- Web Server Hacking, Web Applications, and Database Attacks
- Study Strategies
- Web Server Hacking
- Web Application Hacking
- Database Overview
- Summary
- Key Terms
- Apply Your Knowledge
Wireless Technologies, Security, and Attacks
- Wireless Technologies, Security, and Attacks
- Study Strategies
- Wireless TechnologiesA Brief History
- Wireless LANs
- Wireless Hacking Tools
- Securing Wireless Networks
- Summary
- Key Terms
- Apply Your Knowledge
IDS, Firewalls, and Honeypots
- IDS, Firewalls, and Honeypots
- Study Strategies
- Intrusion Detection Systems
- Firewalls
- Honeypots
- Summary
- Key Terms
- Apply Your Knowledge
Buffer Overflows, Viruses, and Worms
- Buffer Overflows, Viruses, and Worms
- Study Strategies
- Buffer Overflows
- Viruses and Worms
- Summary
- Key Terms
- Apply Your Knowledge
Cryptographic Attacks and Defenses
- Cryptographic Attacks and Defenses
- Study Strategies
- Functions of Cryptography
- History of Cryptography
- Algorithms
- Hashing
- Digital Signatures
- Steganography
- Digital Certificates
- Public Key Infrastructure
- Protocols, Standards, and Applications
- Encryption Cracking and Tools
- Summary
- Key Terms
- Apply Your Knowledge
Physical Security and Social Engineering
- Physical Security and Social Engineering
- Study Strategies
- Physical Security
- Social Engineering
- Summary
- Key Terms
- Apply Your Knowledge
Part II: Final Review
- Fast Facts
- Ethics and Legality
- Footprinting
- Scanning
- Enumeration
- System Hacking
- Trojans and Backdoors
- Sniffers
- Denial of Service
- Social Engineering
- Session Hijacking
- Hacking Web Servers
- Web Application Vulnerabilities
- Web-Based Password Cracking Techniques
- SQL Injection
- Hacking Wireless Networks
- Virus and Worms
- Physical Security
- Linux Hacking
- Evading Firewalls, IDS, and Honeypots
- Buffer Overflows
- Cryptography
- Penetration Testing
- Certified Ethical Hacker
- Practice Exam Questions
- Answers to Practice Exam Questions
- Glossary
Part III: Appendixes
Appendix A. Using the ExamGear Special Edition Software
- Appendix A. Using the ExamGear Special Edition Software
- Exam Simulation
- Study Tools
- How ExamGear Special Edition Works
- Installing ExamGear Special Edition
- Using ExamGear Special Edition
- Contacting Que Certification
- License
- Software and Documentation
- License Term and Charges
- Title
- Updates
- Limited Warranty and Disclaimer
- Limitation of Liability
- Miscellaneous
- U.S. Government Restricted Rights
EAN: 2147483647
Pages: 247
