Database Modeling
Four Information Levels
A database is essentially a set of facts about an application domain. An application domain is also known as a "Universe of Discourse " (a term coined by the 19th century mathematician Augustus De Morgan), since it corresponds to those aspects of the world that we wish to talk or discourse about. The information content of an application domain may be viewed at four different levels: conceptual, logical, physical, and external.
The external level deals with the user interface. Here is where we design how information is presented to various user groups, and what operations they are allowed to perform. For example, Figure 2-1 displays two instances of a screen form that allows users to view and edit basic information about patients . Here, asterisks indicate mandatory fields: each patient must have a patient number and a name .
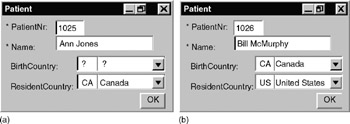
Figure 2-1: Sample forms for two patients.
If known, a patient's country of birth and/or country of residence may be entered. Drop-down list boxes enable the user to choose from a list of countries (both country codes and country names are provided) that is displayed when the cursor is placed in the field. A question mark indicates that no selection has been made, so this detail is unknown to the system. Many alternate user interfaces may be used for this task, but a treatment of user interface design is outside the scope of this book.
Forms like this might be implemented using in-memory "business objects" that have been coded in a programming language such as Java or C#. The design of such transient models is also outside the scope of this book. What is in scope is the design of persistent models (i.e., databases) for storing such information. Such databases may be specified at conceptual, logical, or physical levels.
At the conceptual level, the information is specified naturally, using language and concepts easily understood by non-technical domain experts. For example, The Patient identified by patient number "1025" resides in the Country identified by the country code "CA." At this high level of communication, ORM provides the best approach.
At the logical level, you specify the information in terms of data structures supported by a logical data model. For this purpose, we choose the relational data model invented in 1969 by Dr. E. F. Codd. For example, the residence fact mentioned above might be stored in a resident Country attribute of a Patient table. Using VEA, you can also display this information in an ER style notation. At this level, VEA allows you to specify portable data types that can be mapped to a variety of physical data types depending on the target database platform. At the physical level, we choose a target database management system (DBMS) for implementing the logical model. In this book, we restrict our attention to relational DBMSs, such as Microsoft SQL Server, IBM's DB2, or Oracle. For example, using SQL Server 2000 we might choose to store resident Country values using the physical data type char(2).
The rest of this chapter summarizes the main, top level ideas behind conceptual and logical database design, using the Patient example in Figure 2-1 to illustrate the concepts. As you are probably more familiar with logical database modeling, we'll start with that before moving on to conceptual modeling. The main purpose of this chapter is to provide a quick review of the basic concepts underlying database design. For a thorough grounding in these concepts, you should refer to other books (e.g., Halpin, 2001).
Designing Databases at the Logical Level
A relational database is so-called because all its facts are stored in relations (tables), comprised of sets of tuples (rows). Care is required in designing the relation schemes (table structures) used to store the facts. For example, suppose we try to store all the facts on the patient forms in Figure 2-1 in a single table. The table scheme for this design is shown in Figure 2-2, using the default relational notation supported by VEA.
|
Patient |
|
|---|---|
|
PK |
patientNr |
|
patientName |
|
Figure 2-2: A poorly designed table scheme for capturing the data in Figure 2-1.
The table name "Patient" is shown at the top, and the names of its attributes ( columns ) are listed vertically below. Each table must have a primary key, which is a set of one or more columns whose values uniquely determine a single row of the table. In this case, the patientNr column is the primary key, as shown by the "PK" notation and the underline. Mandatory columns are displayed in bold type, and can contain only actual values. Optional columns are displayed in non-bold type, and may contain null values, indicating that an actual value is unknown to the system.
As you probably realized, this table design is flawed. Intuitively, relationships between country codes and country names are facts about countries , not patients, so they should not be bundled into a table about patients . This error is easily exposed by populating the table scheme with the sample data from Figure 2-2, as shown below.
Patient ( patientNr , patientName, birthCtryCode, birthCtryName, resCtryCode, resCtryName) 1025 Ann Jones ? ? CA Canada 1026 Bill McMurphy CA Canada US United States
Here, the table is set out horizontally, and some column names are abbreviated to fit in the space available. Null values are denoted by "?" Each row of a relational table contains one or more facts. The (CA, Canada) entries on the first row denote the fact that the country with the code "CA" has the name "Canada." But this same fact is represented by the (CA, Canada) entries on the next row. Since the same fact is stored twice, we have redundancy .
Although controlled redundancy may sometimes be used to improve performance, redundancy in a logical model is generally bad, mainly because it makes it much more difficult to avoid data entry errors. For example, unless we take pains to prevent it, we may associate different country names (e.g., "Canada," "Cameroon," "Cambodia") with the same country code ˜CA on different rows of the Patient table above, making the database inconsistent .
For users whose only access to the database is via the form template shown in Figure 2-1 this error is avoided, since the form provides read-only access to the country code-name facts in the drop-down list. However the database administrator who enters these facts into the database in the first place has no such protection. Moreover, such a table scheme would be very awkward for entering such facts in advance, since it requires patient details as well. In short, the table is badly designed.
One way to spot problems with the table design in Figure 2-2 is to realize that it contains functional dependencies unrelated to the primary key. For example, each birth country code must have only one birth country name, and each resident country code must have only one resident country name. The lack of enforcement of these dependencies is what gives rise to possible inconsistencies (e.g., a country code having more than one country name).
If you are designing a logical database model directly, you can use normalization theory to avoid such problems. Normalization by decomposition specifies rules about what kinds of conditions are required for a relation is to conform to a given normal form . The higher the normal form, the more protected the table is from data entry errors. The most important normal forms are summarized in Table 2-1.
|
Normal Form |
Definition |
|---|---|
|
1NF (First Normal Form) |
All attributes are single-valued and fixed. |
|
2NF (Second Normal Form) |
In 1NF, and every nonkey attribute is functionally dependent on the whole of a key (not just part of it) |
|
3NF (Third Normal Form) |
In 2NF, and its nonkey attributes are mutually independent. Hence there are no transitively derived dependencies. |
|
BCNF (Boyce-Codd Normal Form) |
All its elementary functional dependencies begin at whole keys. |
|
4NF (Fourth Normal Form) |
In BCNF, and all its nontrivial dependencies are functional (single-valued) dependencies. |
|
5NF (Fifth Normal Form) |
For each nontrivial join dependency, each projection includes a key of the original table. |
The table scheme in Figure 2-2 is in first normal form (1NF) because it has a fixed number of attributes, each of which can hold only atomic values (not collections of values). It is also in second normal form (2NF), because each of its attributes is functionally dependent on the whole of the primary key (patientNr).
Given any attributes or attribute-sets X and Y of a table scheme, we say that X functionally determines Y (written X ’ Y ) if and only if, for each value of X there is at most one value of Y (for any given population of the table scheme). A nonkey attribute is neither a key nor part of a composite key. The table scheme in Figure 2-1 has functional dependencies between some of its nonkey attributes. For example, birthCountryCode ’ birthCountryName, and residentCountryCode ’ residentCountryName . There are also functional dependencies in the opposite direction (from country names to country codes). Hence the table scheme is not in third normal form (3NF).
To obtain third normal form, the embedded functional dependencies must be removed by decomposing the table into multiple tables. In this case, we should remove the country name columns from the original table, and store the relationship between country codes and country names in a separate table, as shown in Figure 2-3.
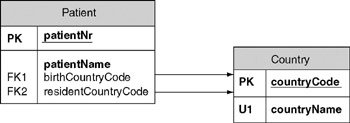
Figure 2-3: A normalized table design for capturing the data in Figure 2-1.
The primary key declaration in the Country table captures the functional dependencies from country codes to country names. The "U1" mark on the countryName column declares that these values in this column are unique (each country name refers to only one country). This captures the functional dependencies from country names to country codes.
The "FK1" and "FK2" marks in the Patient table declare that birthCountryCode and residentCountryCode are foreign keys (each of their column values must be included in the primary key column of some table). The arrows from the Patient table to the Country table display the connections from the foreign keys in the Patient table to the primary key of the Country table. The sample population shown below illustrates these foreign key constraints: each birth or resident country code in the Patient table is also a country code in the Country table. The country table has two candidate keys ( underlined ). Here a double underline is used to dinstinguish the "primary key."
Patient ( patientNr , patientName, birthCountryCode, residentCountryCode) 1025 Ann Jones ? CA 1026 Bill McMurphy CA US Country ( countryCode , countryName) AU Australia CA Canada US United States ... ...
Note that the foreign key connections between the tables denote constraints, not facts. For example, the fact that Ann Jones resides in Canada is stored in the patientName and residentCountryCode columns of the Patient table. The foreign key reference from the residentCountryCode column to the countryCode column of the Patient table merely ensures that resident country codes are legal country codes. Using VEA, you can redisplay the schema of Figure 2-3 in an ER-like notation, such as IDEF1X, and you can supply relationship names (e.g., "was born in," "resides in") for the foreign key references. But you cannot use these foreign key connections to actually store the birth and residency facts. These facts must still be stored in columns of the Patient table. The relational data model requires all facts to be stored in tables. In pure ER modeling, the Patient table would be replaced by an entity type Patient with just two attributes (patientNr and patientName), and the birth and residency facts would be captured by relationships between the Patient and Country entity types. Since VEA does not support pure ER modeling of this kind, its ER modeling solution is classified as logical modeling rather than conceptual modeling.
To obtain a correct database design for the Patient form, it was sufficient to use third normal form, because the Patient and Country tables are actually also in fifth normal form (5NF). There are many cases however where 3NF tables are still open to redundancy or update anomalies, and further decomposition is required to reshape them into 5NF tables. We have no space here to provide a full coverage of normalization theory. For a concise but thorough treatment of normalization by decomposition, see section 12.6 of Halpin, 2001. One advantage of using the ORM solution is that VEA can automatically generate 5NF table schemas from correct ORM models. So if you use ORM, there is no need to concern yourself with normalization theory.
Designing Databases at the Conceptual Level
For any given application, the domain experts who understand the meaning of the underlying information and business rules are often non-technical. Since these subject matter experts are the only reliable source for validating whether you have modeled the information correctly, you should communicate your model to them at the conceptual level, using concepts and language that they easily understand. Object-Role Modeling (ORM) enables you to do this using natural language sentences from which VEA can automatically generate a database model for implementation.
ORM also provides a rich, graphical notation that enables you as a modeler to visualize the semantic connections and business rules within a conceptual model. Although domain experts often find this notation easy to use, it is not necessary for them to see the graphical notation at all. If you wish, you may specify the model completely in natural language, making use of VEA's verbalization and reporting features to validate the model with the domain experts. How to do this is explained later in the book. For now, we content ourselves with a brief overview of conceptual modeling, using the Patient form example to illustrate some of the key ideas.
Besides its textual and graphical notations, ORM includes a design procedure to help you construct a conceptual model. An early step in this design procedure is to verbalize sample information in terms of elementary facts. For example, the form shown in Figure 2-1(b) contains five facts, which might be verbalized as follows :
The Patient with patient number 1026 has the PatientName 'Bill McMurphy.' The Patient with patient number 1026 was born in the Country with code 'CA.' The Patient with patient number 1026 resides in the Country with code 'CA.' The Country with code 'CA' has the CountryName 'Canada.' The Country with code 'US' has the CountryName 'United States.'
This verbalization indicates that there are two entity types (Patient and Country) identified respectively by a number and code, and two value types (PatientName and CountryName). Unlike entities, values (e.g., character strings) are lexical in nature, so they identify themselves . In ORM, the term "object" is used for either an entity or value. The reference schemes for the four object types may be summarized thus:
Patient(Nr); Country(Code); PatientName(); CountryName()
By removing the specific values from the five fact instances, we see that there are four fact types (kinds of fact):
Patient has PatientName. Patient was born in Country. Patient resides in Country. Country has CountryName.
Fact types are comprised of object types, such as Patient and Country, and logical predicates, such as "was born in." The following constraints apply to these fact types:
Each Patient has exactly one PatientName. Each patient was born in at most one Country. Each Patient resides in at most one Country. Each Country has exactly one CountryName. Each CountryName refers to at most one Country.
This completes the specification of the conceptual schema. The next chapter shows you how to enter a schema like this into the VEA tool, and forward engineer it to a relational database.
If desired, you may display an ORM schema in graphical form, as shown in Figure 2-4. Here entity types are displayed as named ellipses, with their reference schemes in parenthesis. Value types are displayed as dotted ellipses. Each part played in a predicate is called a role and is displayed as a role-box. Predicates are displayed as a named sequence of roles, with each role linked to the object type that plays it.
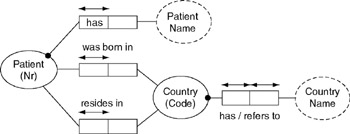
Figure 2-4: ORM schema for the Patient form.
A large dot attached to a role link indicates that the role is mandatory . For example, each patient and each country must have a name . For each fact type, a sample population of fact instances may be provided, with a column in the table for each role. An arrow-tipped bar besides a role is a uniqueness constraint, indicating that entries in the role's associated fact column are unique.
For example, Figure 2-5 includes sample fact populations for two of the fact types. Entries in the resident patient column are unique, in accordance with the uniqueness constraint for its role (each patient resides in only one country). The resident country column includes a duplicate entries for "US," demonstrating the lack of a uniqueness constraint (the same country may have more than one resident). The column entries for the country code-name fact type are both unique, indicating clearly the 1:1 nature of this relationship. Examples like this are very handy for validating constraints with domain experts. Chapter 4 explains how to add such examples to your models.
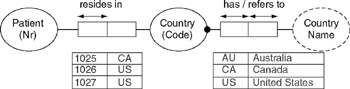
Figure 2-5: Two ORM fact types, with sample populations.
If you are familiar with ER, but not with ORM, you might find some of this discussion rather strange . For example, ORM makes no use of attributes, instead expressing all facts as relationships. This is quite deliberate , and has many advantages. For example, ORM models (and queries based on them) are more stable, because they are immune to changes that reshape attributes into entity types or relationships. Moreover, all facts and rules can be verbalized directly in sentences, and the role-based framework simplifies the expression of many constraints.
Although ORM models tend to consume more space than ER models, they typically reveal more semantics, and you can use VEA to automatically transform ORM models to compact, attribute-based models for relational implementation. For example, you can use VEA to map the ORM schema in Figure 2-4 to the relational schema shown in Figure 2-3. This forward engineering process is introduced in Chapter 3, and explained in detail in Chapter 7.
The Database Life Cycle
VEA's database modeling functions can help both individual database users and large corporate development teams . Individual database users do their own business analysis and database modeling. In a complex business environment many people with a wide range of skills are needed. However, the basic database modeling principles are the same for all environments. In a complex business environment, numerous people may work to define, apply and manage computer systems to meet business needs for efficiency and effectiveness. Tasks such as hardware selection, network management, and budgeting form part of the information systems life cycle.
The database life cycle is a core component of the information systems life cycle. The purpose of the database life cycle is to define database requirements and to manage database solutions to support the information system life cycle objectives. Tasks include managing data, and selecting and managing database products such as database server hardware and RDBMS software.
The database life cycle includes two main components : technology, and data. Computer systems proliferation and low cost desktop systems have created a wide awareness of computer technology. However, data itself is less tangible and is often harder to understand and manage.
The following paragraphs outline the phases in the database life cycle depicted in Figure 2-6. Each phase occurs within the context of the previous phase. The two-way arrows indicate that iteration takes place between adjacent phases. For example, in phase 4, a performance designer defines the physical model in collaboration with the database designer of phase 3. The names such as "business analyst" shown in Figure 2-6 reflect roles and skill sets rather than job titles. It is possible that the same person may perform many of these roles.

Figure 2-6: Database Life Cycle.
The arrows between each box represent transformations that change the appearance of the model whilst retaining its meaning. Ideally, the transformations are reversible. For example you can transform a conceptual model into a logical model and back again without losing semantic information. You can transform a logical model into a physical database structure and back again without losing semantic information.
Phase 1 Define Business Needs
The first phase in the database life cycle defines the desired business results, project feasibility and business performance metrics. Phase 1 provides answers to business questions such as: Why should we build this database? Can this database be built in time to meet the business need? What is the scope of this database? The output is a set of business targets and a development plan.
Phase 2 Define Database Requirements
The second phase defines the scope of the database in terms of a conceptual information model. The business analyst defines a conceptual model in collaboration with domain experts. Phase 2 answers questions such as: What are the facts in the application domain? What things does the application seek to manage? What business rules apply to these things? The output of phase 2 is a transformable conceptual model.
Phase 3 Design Logical Model
During the third phase, you design a logical model that shows tables, columns and relationships. The database designer defines the table structure in collaboration with the business analyst. Phase 3 answers questions such as: What logical schema accurately represents the facts in the application domain? Ideally, the output is a fully normalized logical model.
Phase 4 Design and Build Physical Model
The fourth phase designs and builds a physical database for a specific DBMS in a specific technical environment to meet specific performance criteria. The database performance designer defines the physical database model in collaboration with the database analyst. Phase 4 answers questions such as: What information is needed to create a physical database that meets specific update transaction and query load requirements? What are the key update transactions and queries that require high performance? What performance will be achieved by a specific database product on a specific hardware platform? The output is a physical model adapted to meet the desired business performance using a specified technical solution.
Database performance tuning requires a thorough understanding of the technical characteristics of a specific set of products. A database performance specialist must keep up to date with product changes and maintain an awareness of the complex and changing interactions within a specific technical configuration. Database performance tuning optimizes the interaction between technical components such as the RDBMS product, the computer operating system and the systems hardware.
Phase 5 Maintain Database
This phase covers the post-implementation tasks that are usually done by the database administrator (DBA). For example, a change to a business rule is a semantic change and requires a corresponding change to conceptual, logical, and physical models. However, a change to performance requirements or technology requires changes to the physical model only. A well-designed relational database enjoys the property of data independence, which enables you to change database technology without changing your conceptual or logical models. Data independence protects investment in database application programs and reduces the cost of change.
The rest of this book is focused on the use of VEA to design databases at conceptual, logical, and physical levels. Chapter 17 includes some pragmatic advice on best practices. A useful coverage of database administration procedures and practices may be found in Mullins (2002).
Overview of Database Modeling and the Database Modeling Tool
The Conceptual Modeling Solution (ORM)
- Object Types, Predicates, and Basic Constraints
- ORM Constraints
- Configuring, Manipulating, and Reusing ORM Models
- Mapping ORM Models to Logical Database Models
- Reverse Engineering and Importing to ORM
- Conceptual Model Reports
The Logical Modeling Solution (ER and Relational)
- Creating a Basic Logical Database Model
- Generating a Physical Database Schema
- Editing Logical Models”Intermediate Aspects
- Editing Logical Models”Advanced Aspects
- Reverse Engineering Physical Schemas to Logical Models
- Logical Database Model Reports
Managing Database Projects
EAN: 2147483647
Pages: 150
