Client/Server with dbExpress
Client Server with dbExpress
Overview
In the last chapter, we examined Delphi's support for database programming, using local files (particularly using the ClientDataSet component, or MyBase) in most of the examples but not focusing on any specific database technology. This chapter moves on to the use of SQL server databases, focusing on client/server development with the BDE and the new dbExpress technology. A single chapter cannot cover this complex topic in detail, so I'll introduce it from the perspective of the Delphi developer and add some tips and hints.
For the examples I'll use InterBase, because this Borland RDBMS (relational database management system), or SQL server, is included in the Professional and higher editions of Delphi; in addition, it is a free and open-source server (although not in all of its versions, as discussed later). I'll discuss InterBase from the Delphi perspective, without delving into its internal architecture. A lot of the information presented also applies to other SQL servers, so even if you've decided not to use InterBase, you may still find it valuable.
The Client Server Architecture
The database applications presented in previous chapters used native components to access data stored in files on the local machine and loaded the entire file in memory. This is an extreme approach. More traditionally, the file is read record by record so that multiple applications can access it at the same time, provided write synchronization mechanisms are used.
When the data is on a remote server, copying an entire table in memory for processing it is time- and bandwidth-consuming, and often also useless. As an example, consider taking a table like EMPLOYEE (part of the InterBase sample database, which ships with Delphi), adding thousands of records to it, and placing it on a networked computer working as a file server. If you want to know the highest salary paid by the company, you can open a dbExpress table component (EmpTable) or a query selecting all the records, and run this code:
EmpTable.Open;
EmpTable.First;
MaxSalary := 0;
while not EmpTable.Eof do
begin
if EmpTable.FieldByName ('Salary').AsCurrency > MaxSalary then
MaxSalary := EmpTable.FieldByName ('Salary').AsCurrency;
EmpTable.Next;
end;
The effect of this approach is to move all the data of the table from the networked computer to the local machine—an operation that might take minutes. In this case, the proper approach is to let the SQL server compute the result directly, fetching only this single piece of information. You can do so using a SQL statement like this:
select Max(Salary) from Employee
| Note |
The previous two code excerpts are part of the GetMax example, which includes code to time the two approaches. Using the Table component on the small Employee table takes about 10 times longer than using the query, even if the InterBase server is installed on the computer running the program. |
To store a large amount of data on a central computer and avoid moving the data to client computers for processing, the only solution is to let the central computer manipulate the data and send back to the client only a limited amount of information. This is the foundation of client/server programming.
In general, you'll use an existing program on the server (an RDBMS) and write a custom client application that connects to it. Sometimes, however, you may want to write both a custom client and a custom server, as in three-tier applications. Delphi support for this type of program—which has been called the Middle-tier Distributed Application Services (MIDAS) architecture and is now dubbed DataSnap—is covered in Chapter 16, "Multitier DataSnap Applications."
The upsizing of an application—that is, the transfer of data from local files to a SQL server database engine—is generally done for performance reasons and to allow for larger amounts of data. Going back to the previous example, in a client/server environment, the query used to select the maximum salary would be computed by the RDBMS, which would send back to the client computer only the final result—a single number. With a powerful server computer (such as a multiprocessor Sun SparcStation), the total time required to compute the result might be minimal.
However, there are other reasons to choose a client/server architecture. Such an architecture:
- Helps you manage a larger amount of data, because you don't want to store hundreds of megabytes in a local file.
- Supports the need for concurrent access to the data by multiple users at the same time. SQL server databases generally use optimistic locking, an approach that allows multiple users to work on the same data and delays the concurrency control until users send back updates.
- Provides data integrity, transaction control, security, access control, backup support, and the like.
- Supports programmability—the possibility of running part of the code (stored procedures, triggers, table views, and other techniques) on the server, thereby reducing the network traffic and the workload of the client computers.
Having said this, we can begin focusing on particular techniques useful for client/server programming. The general goal is to distribute the workload properly between the client and the server and reduce the network bandwidth required to move information back and forth.
The foundation of this approach is good database design, which involves both table structure and appropriate data validation and constraints, or business rules. Enforcing the validation of the data on the server is important, because the integrity of the database is one of the key aims of any program. However, the client side should include data validation as well, to improve the user interface and make the input and the processing of the data more user-friendly. It makes little sense to let the user enter invalid data and then receive an error message from the server, when you can prevent the wrong input in the first place.
Elements of Database Design
Although this is a book about Delphi programming, not databases, I feel it's important to discuss a few elements of good (and modern) database design. The reason is simple: If your database design is incorrect or convoluted, you'll either have to write terribly complex SQL statements and server-side code, or write a lot of Delphi code to access your data, possibly even fighting against the design of the TDataSet class.
Entities and Relations
The classic relational database design approach, based on the entity-relation (E-R) model, involves having one table for every entity you need to represent in your database, with one field for each data element you need plus one field for every one-to-one or one-to-many relation to another entity (or table). For many-to-many relations, you need a separate table.
As an example of a one-to-one relation, consider a table representing a university course. It will have a field for each relevant data element (name and description, room where the course is held, and so on) plus a single field indicating the teacher. The teacher data really should not be stored within the course data, but in a separate table, because it may be referenced from elsewhere.
The schedule for each course can include an undefined number of hours on different days, so they cannot be added in the same table describing the course. Instead, this information must be placed in a separate table that includes all the schedules, with a field referring to the class each schedule is for. In a one-to-many relation like this, many records of the schedule table point to the same one record in the course table.
A more complex situation is required to store information about which student is taking which class. Students cannot be listed directly in the course table, because their number is not fixed, and the classes cannot be stored in the student's data for the same reason. In a similar many-to-many relation, the only approach is to create an extra table representing the relation—it lists references to students and courses.
Normalization Rules
The classic design principles include a series of so-called normalization rules. The goal of these rules is to avoid duplicating data in your database (not only to save space, but mainly to avoid ending up with incongruous data). For example, you don't repeat all the customer details in each order, but refer to a separate customer entity. This way you save memory, and when a customer's details change (for example, because of a change of address), all of the customer's orders reflect the new data. Other tables that relate to the same customer will be automatically updated as well.
Normalization rules imply using codes for commonly repeated values. For example, suppose you have a few different shipment options. Rather than include a string-based description for these options within the orders table, you can use a short numeric code that's mapped to a description in a separate lookup table.
The previous rule, which should not be taken to the extreme, helps you avoid having to join a large number of tables for every query. You can either account for some de-normalization (leaving a short shipment description within the orders table) or use the client program to provide the description, again ending up with a formally incorrect database design. This last option is practical only when you use a single development environment (let's say, Delphi) to access this database.
From Primary Keys to OIDs
In a relational database, records are identified not by a physical position (as in Paradox and other local databases) but by the data within the record. Typically, you don't need the data from every field to identify a record, but only a subset of the data, forming the primary key. If the fields that are part of the primary key must identify an individual record, their value must be different for each possible record of the table.
| Note |
Many database servers add internal record identifiers to tables, but they do so only for internal optimization; this process has little to do with the logical design of a relational database. These internal identifiers work differently in different SQL servers and may change among versions, so you shouldn't rely on them. |
Early incarnations of relational theory dictated the use of logical keys, which means selecting one or more fields that indicate an entity without risk of confusion. This is often easier to say than to accomplish. For example, company names are not generally unique, and even the company name and its location don't provide a complete guarantee of uniqueness. Moreover, if a company changes its name (not an unlikely event, as Borland can teach us) or its location, and you have references to the company in other tables, you must change all those references as well and risk ending up with dangling references.
For this reason, and also for efficiency (using strings for references implies using a lot of space in secondary tables, where references often occur), logical keys have been phased out in favor of physical or surrogate keys:
Physical Key A single field that identifies an element in a unique way. For example, each person in the U.S. has a Social Security Number (SSN), but almost every country has a tax ID or other government-assigned number that identifies each person. The same is typically true for companies. Although these ID numbers are guaranteed to be unique, they can change depending on the country (creating troubles for the database of a company that sells goods abroad) or within a single country (to account for new tax laws). They are also often inefficient, because they can be quite large (Italy, for example, uses a 16-character code—letters and numbers—to identify people).
Surrogate Key A number identifying a record, in the form of a client code, order number, and so on. Surrogate keys are commonly used in database design. However, in many cases, they end up being logical identifiers, with client codes showing up all over the place (not a great idea).
| Warning |
The situation becomes particularly troublesome when surrogate keys also have a meaning and must follow specific rules. For example, companies must number invoices with unique and consecutive numbers, without leaving holes in the numbering sequence. This situation is extremely complex to handle programmatically, if you consider that only the database can determine these unique consecutive numbers when you send it new data. At the same time, you need to identify the record before you send it to the database—otherwise you won't be able to fetch it again. Practical examples of how to solve this situation are discussed in Chapter 15, "Working with ADO." |
OIDs to the Extreme
An extension to the use of surrogate keys is the use of a unique Object Identifier (OID). An OID is either a number or a string with a sequence of numbers and digits; it's added to each record of each table representing an entity (and sometimes to records of tables representing relations). Unlike client codes, invoice numbers, SSNs, or purchase order numbers, OIDs are random: They have no sequencing rule and are never visible to the end user. This means you can use surrogate keys (if your company is used to them) along with OIDs, but all the external references to the table will be based on OIDs.
Another common rule suggested by the promoters of this approach (which is part of the theories supporting object-relational mapping) is the use of system-wide unique identifiers. If you have a table of client companies and a table of employees, you may wonder why you should use a unique ID for such diverse data. The reason is that you'll be able to sell goods to an employee without having to duplicate the employee information in the customer table—you can refer to the employee in your order and invoice. An order is placed by someone identified by an OID, and this OID can refer to many different tables.
Using OIDs and object-relational mapping is an advanced element of the design of Delphi database applications. I suggest that you investigate this topic before embracing medium or large Delphi projects because the benefit can be relevant (after some investment in studying this approach and building some basic support code).
External Keys and Referential Integrity
The keys identifying a record (whatever their type) can be used as external keys in other tables—for example, to represent the various types of relations discussed earlier. All SQL servers can verify these external references, so you cannot refer to a nonexistent record in another table. These referential integrity constraints are expressed when you create a table.
Besides not being allowed to add references to nonexistent records, you're generally prevented from deleting a record if external references to it exist. Some SQL servers go one step further: As you delete a record, instead of denying the operation, they can automatically delete all records that refer to it from other tables.
More Constraints
In addition to the uniqueness of primary keys and the referential constraints, you can generally use the database to impose more validity rules on the data. You can ask for specific columns (such as those referring to a tax ID or a purchase order number) to include only unique values. You can impose uniqueness on the values of multiple columns—for example, to indicate that you cannot hold two classes in the same room at the same time.
In general, simple rules can be expressed to impose constraints on a table, whereas more complex rules generally imply the execution of stored procedures activated by triggers (every time the data changes, for instance, or there is new data).
Again, there is much more to proper database design, but the elements discussed in this section can provide you with a starting point or a good refresher.
| Note |
For more information about SQL's Data Definition Language and Data Manipulation Language, see the chapter "Essential SQL" in the electronic book described in Appendix C, "Free Companion Books on Delphi." |
Unidirectional Cursors
In local databases, tables are sequential files whose order either is the physical order or is defined by an index. By contrast, SQL servers work on logical sets of data that aren't related to a physical order. A relational database server handles data according to the relational model: a mathematical model based on set theory.
For this discussion, it's important for you to know that in a relational database, the records (sometimes called tuples) of a table are identified not by position but exclusively through a primary key, based on one or more fields. Once you've obtained a set of records, the server adds to each of them a reference to the following record; thus you can move quickly from a record to the following one, but moving back to the previous record is extremely slow. For this reason, it is common to say that an RDBMS uses a unidirectional cursor. Connecting such a table or query to a DBGrid control is practically impossible, because doing so would make browsing the grid backward terribly slow.
Some database engines keep the data already retrieved in a cache, to support full bidirectional navigation on it. In the Delphi architecture, this role can be played by the ClientDataSet component or another caching dataset. You'll see this process in more detail later, when we focus on dbExpress and the SQLDataset component.
| Note |
The case of a DBGrid used to browse an entire table is common in local programs but should generally be avoided in a client/server environment. It's better to filter out only part of the records and only the fields you are interested in. If you need to see a list of names, return all those starting with the letter A, then those with B, and so on, or ask the user for the initial letter of the name. |
If proceeding backward might result in problems, keep in mind that jumping to the last record of a table is even worse; usually this operation implies fetching all the records! A similar situation applies to the RecordCount property of datasets. Computing the number of records often implies moving them all to the client computer. For this reason, the thumb of the DBGrid's vertical scrollbar works for a local table but not for a remote table. If you need to know the number of records, run a separate query to let the server (and not the client) compute it. For example, you can see how many records will be selected from the EMPLOYEE table if you are interested in those records having a salary field higher than 50,000:
select count(*) from Employee where Salary > 50000
| Tip |
Using the SQL instruction count(*) is a handy way to compute the number of records returned by a query. Instead of the * wildcard, you could use the name of a specific field, as in count(First_Name), possibly combined with either distinct or all, to count only records with different values for the field or all the records having a non-null value. |
Introducing InterBase
Although it has a limited market share, InterBase is a powerful RDBMS. In this section, I'll introduce the key technical features of InterBase without getting into too much detail (because this is a book about Delphi programming). Unfortunately, little is currently published about InterBase. Most of the available material is either in the documentation that accompanies the product or on a few websites devoted to it (your starting points for a search can be www.borland.com/interbase and www.ibphoenix.com).
InterBase was built from the beginning with a modern and robust architecture. Its original author, Jim Starkey, invented an architecture for handling concurrency and transactions without imposing physical locks on portions of the tables, something other well-known database servers can barely do even today. The InterBase architecture is called Multi-Generational Architecture (MGA); it handles concurrent access to the same data by multiple users, who can modify records without affecting what other concurrent users see in the database.
This approach naturally maps to the Repeatable Read transaction isolation mode, in which a user within a transaction keeps seeing the same data regardless of changes made and committed by other users. Technically, the server handles this situation by maintaining a different version of each accessed record for each open transaction. Even though this approach (also called versioning) can lead to larger memory consumption, it avoids most physical locks on the tables and makes the system much more robust in case of a crash. MGA also pushes toward a clear programming model—Repeatable Read—which other well-known SQL servers don't support without losing most of their performance.
In addition to the MGA at the heart of InterBase, the server has many other technical advantages:
- A limited footprint, which makes InterBase the ideal candidate for running directly on client computers, including portables. The disk space required by InterBase for a minimal installation is well below 10 MB, and its memory requirements are also incredibly limited.
- Good performance on large amounts of data.
- Availability on many different platforms (including 32-bit Windows, Solaris, and Linux), with totally compatible versions. Thus the server is scalable from very small to huge systems without notable differences.
- A very good track record, because InterBase has been in use for 15 years with few problems.
- A language complaint with the ANSI SQL standard.
- Advanced programming capabilities, including positional triggers, selectable stored procedures, updateable views, exceptions, events, generators, and more.
- Simple installation and management, with limited administrative headaches.
A Short History of InterBase
Jim Starkey wrote InterBase for his Groton Database Systems company (hence the .gds extension still used for InterBase files). The company was later bought by Ashton-Tate, which was then acquired by Borland. Borland handled InterBase directly for a while and then created an InterBase subsidiary, which was later re-absorbed into the parent company.
Beginning with Delphi 1, an evaluation copy of InterBase has been distributed with the development tool, spreading the database server among developers. Although it doesn't have a large piece of the RDBMS market, which is dominated by a handful of players, InterBase has been chosen by a few relevant organizations, from Ericsson to the U.S. Department of Defense, from stock exchanges to home banking systems.
More recent events include the announcement of InterBase 6 as an open-source database (December 1999), the effective release of source code to the community (July 2000), and the release of the officially certified version of InterBase 6 by Borland (March 2001). Between these events came announcements of the spin-off of a separate company to run the consulting and support business in addition to the open-source database. A group of former InterBase developers and managers (who had left Borland) formed IBPhoenix (www.ibphoenix.com) with the plan of supporting InterBase users.
At the same time, independent groups of InterBase experts started the Firebird open-source project to further extend InterBase. The project is hosted on SourceForge at the address sourceforge.net/projects/ firebird/. For some time, SourceForge also hosted a Borland open-source project, but later the company announced it would continue to support only its proprietary version, dropping its open-source effort. So, the picture is now clearer. If you want a version with a traditional license (costing a fraction of most competing professional SQL servers), stick with Borland; but if you prefer an open-source, totally free model, go with the Firebird project (and eventually buy professional support from IBPhoenix).
Using IBConsole
In past versions of InterBase, you could use two primary tools to interact directly with the program: the Server Manager application, which could be used to administer both a local and a remote server; and Windows Interactive SQL (WISQL). Version 6 includes a much more powerful front-end application, called IBConsole. This full-fledged Windows program (built with Delphi) allows you to administer, configure, test, and query an InterBase server, whether local or remote.
IBConsole is a simple and complete system for managing InterBase servers and their databases. You can use it to look into the details of the database structure, modify it, query the data (which can be useful to develop the queries you want to embed in your program), back up and restore the database, and perform any other administrative tasks.
As you can see in Figure 14.1, IBConsole allows you to manage multiple servers and databases, all listed in a single configuration tree. You can ask for general information about the database and list its entities (tables, domains, stored procedures, triggers, and everything else), accessing the details of each. You can also create new databases and configure them, back up the files, update the definitions, check what's going on and who is currently connected, and so on.
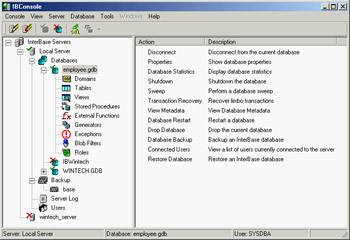
Figure 14.1: IBConsole lets you manage, from a single computer, InterBase databases hosted by multiple servers.
The IBConsole application allows you to open multiple windows to look at detailed information, such as the tables window shown in Figure 14.2. In this window, you can see lists of the key properties of each table (columns, triggers, constraints, and indexes), see the raw metadata (the SQL definition of the table), access permissions, look at the data, modify the data, and study the table's dependencies. Similar windows are available for each of the other entities you can define in a database.
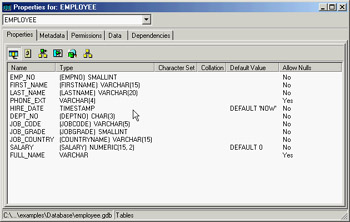
Figure 14.2: IBConsole can open separate windows to show you the details of each entity—in this case, a table.
IBConsole embeds an improved version of the original Windows Interactive SQL application (see Figure 14.3). You can type a SQL statement in the upper portion of the window (without any help from the tool, unfortunately) and then execute the SQL query. As a result, you'll see the data, but also the access plan used by the database (which an expert can use to determine the efficiency of the query) and statistics about the operation performed by the server.
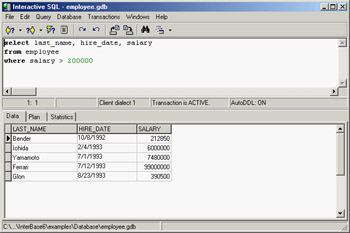
Figure 14.3: IBConsole's Interactive SQL window lets you try in advance the queries you plan to include in your Delphi programs.
This has been a minimal description of IBConsole, which is a powerful tool (and the only one Borland includes with the server other than command-line tools). IBConsole is not the most complete tool in its category, though. Quite a few third-party InterBase management applications are more powerful, although they are not all stable or user-friendly. Some InterBase tools are shareware programs, and others are free. Two examples out of many are InterBase Workbench (www.upscene.com) and IB_WISQL (done with and part of InterBase Objects, www.ibobjects.com).
InterBase Server Side Programming
At the beginning of this chapter, I underlined the fact that one of the objectives of client/ server programming—and one of its problems—is the division of the workload between the computers involved. When you activate SQL statements from the client, the burden falls on the server to do most of the work. However, you should try to use select statements that return a large result set, to avoid jamming the network.
In addition to accepting DDL (Data Definition Language) and DML (Data Manipulation Language), most RDBMS servers allow you to create routines directly on the server using the standard SQL commands plus their own server-specific extensions (which generally are not portable). These routines typically come in two forms: stored procedures and triggers.
Stored Procedures
Stored procedures are like the global functions of a Delphi unit and must be explicitly called by the client side. Stored procedures are generally used to define routines for data maintenance, to group sequences of operations you need in different circumstances, or to hold complex select statements.
Like Delphi procedures, stored procedures can have one or more typed parameters. Unlike Delphi procedures, they can have more than one return value. As an alternative to returning a value, a stored procedure can also return a result set—the result of an internal select statement or a custom fabricated one.
The following is a stored procedure written for InterBase; it receives a date as input and computes the highest salary among the employees hired on that date:
create procedure MaxSalOfTheDay (ofday date) returns (maxsal decimal(8,2)) as begin select max(salary) from employee where hiredate = :ofday into :maxsal; end
Notice the use of the into clause, which tells the server to store the result of the select statement in the maxsal return value. To modify or delete a stored procedure, you can later use the alter procedure and drop procedure commands.
Looking at this stored procedure, you might wonder what its advantage is compared to the execution of a similar query activated from the client. The difference between the two approaches is not in the result you obtain but in its speed. A stored procedure is compiled on the server in an intermediate and faster notation when it is created, and the server determines at that time the strategy it will use to access the data. By contrast, a query is compiled every time the request is sent to the server. For this reason, a stored procedure can replace a very complex query, provided it doesn't change too often.
From Delphi, you can activate a stored procedure with the following SQL code:
select *
from MaxSalOfTheDay ('01/01/2003')
Triggers (and Generators)
Triggers behave more or less like Delphi events and are automatically activated when a given event occurs. Triggers can have specific code or call stored procedures; in both cases, the execution is done completely on the server. Triggers are used to keep data consistent, checking new data in more complex ways than a check constraint allows, and to automate the side effects of some input operations (such as creating a log of previous salary changes when the current salary is modified).
Triggers can be fired by the three basic data update operations: insert, update, and delete. When you create a trigger, you indicate whether it should fire before or after one of these three actions.
As an example of a trigger, you can use a generator to create a unique index in a table. Many tables use a unique index as a primary key. InterBase doesn't have an AutoInc field. Because multiple clients cannot generate unique identifiers, you can rely on the server to do this. Almost all SQL servers offer a counter you can call to ask for a new ID, which you should later use for the table. InterBase calls these automatic counters generators, and Oracle calls them sequences. Here is the sample InterBase code:
create generator cust_no_gen; ... gen_id (cust_no_gen, 1);
The gen_id function extracts the new unique value of the generator passed as the first parameter; the second parameter indicates how much to increase (in this case, by one).
At this point you can add a trigger to a table (an automatic handler for one of the table's events). A trigger is similar to the event handler of the Table component, but you write it in SQL and execute it on the server, not on the client. Here is an example:
create trigger set_cust_no for customers before insert position 0 as begin new.cust_no = gen_id (cust_no_gen, 1); end
This trigger is defined for the customers table and is activated each time a new record is inserted. The new symbol indicates the new record you are inserting. The position option indicates the order of execution of multiple triggers connected to the same event. (Triggers with the lowest values are executed first.)
Inside a trigger, you can write DML statements that also update other tables, but watch out for updates that end up reactivating the trigger and create endless recursion. You can later modify or disable a trigger by calling the alter trigger or drop trigger statement.
Triggers fire automatically for specified events. If you have to make many changes in the database using batch operations, the presence of a trigger can slow the process. If the input data has already been checked for consistency, you can temporarily deactivate the trigger. These batch operations are often coded in stored procedures, but stored procedures generally cannot issue DDL statements like those required for deactivating and reactivating the trigger. In this situation, you can define a view based on a select * from table command, thus creating an alias for the table. Then you can let the stored procedure do the batch processing on the table and apply the trigger to the view (which should also be used by the client program).
The dbExpress Library
Nowadays, the mainstream access to a SQL server database in Delphi is provided by the dbExpress library. As mentioned in Chapter 13, "Delphi's Database Architecture," this is not the only possibility but is certainly the mainstream approach. The dbExpress library, first introduced in Kylix and Delphi 6, allows you to access different servers (InterBase, Oracle, DB2, MySql, Informix, and now Microsoft SQL Server). I provided a general overview of dbExpress compared with other solutions in Chapter 13, so here I'll skip the introductory material and focus on technical elements.
| Note |
The inclusion of a driver for Microsoft SQL Server is the most important update to dbExpress provided by Delphi 7. It is not implemented by interfacing the vendor library natively, like other dbExpress drivers, but by interfacing Microsoft's OLEDB provider for SQL Server. (I'll talk more about OLEDB providers in Chapter 15.) |
Working with Unidirectional Cursors
The motto of dbExpress could be "fetch but don't cache." The key difference between this library and BDE or ADO is that dbExpress can only execute SQL queries and fetch the results with a unidirectional cursor. As you've just seen, in unidirectional database access, you can move from one record to the next, but you cannot get back to a previous record of the dataset (unless by reopening the query and fetching all the records again minus one, an incredibly slow operation that dbExpress blocks). This is because the library doesn't store the data it has retrieved in a local cache, but only passes it from the database server to the calling application.
Using a unidirectional cursor might sound like a limitation, and it is—in addition to having problems with navigation, you cannot connect a database grid to a dataset. However, a unidirectional dataset is good for the following:
- You can use a unidirectional dataset for reporting purposes. In a printed report, but also an HTML page or an XML transformation, you move from record to record, produce the output, and that's it—no need to return to past records and, in general, no user interaction with the data. Unidirectional datasets are probably the best option for web and multitier architectures.
- You can use a unidirectional dataset to feed a local cache, such as the one provided by a ClientDataSet component. At this point, you can connect visual components to the in-memory dataset and operate on it with all the standard techniques, including the use of visual grids. You can freely navigate and edit the data in the in-memory cache, but also control it far better than with the BDE or ADO.
It's important to notice that in these circumstances, avoiding the caching of the database engine saves time and memory. The library doesn't have to use extra memory for the cache and doesn't need to waste time storing data (and duplicating information). Over the last couple of years, many programmers moved from BDE-based cached updates to the ClientDataSet component, which provides more flexibility in managing the content of the data and updating information they keep in memory. However, using a ClientDataSet on top of the BDE (or ADO) exposes you to the risk of having two separate caches, which wastes a lot of memory.
Another advantage of using the ClientDataSet component is that its cache supports editing operations, and the updates stored in this cache can be applied to the original database server by the DataSetProvider component. This component can generate the proper SQL update statements, and can do so in a more flexible way than the BDE (although ADO is powerful in this respect). In general, the provider can also use a dataset for the updates, but this isn't directly possible with the dbExpress dataset components.
Platforms and Databases
A key element of the dbExpress library is its availability for both Windows and Linux, in contrast to the other database engines available for Delphi (BDE and ADO), which are available only for Windows. However, some of the database-specific components, such as InterBase Express, are also available on multiple platforms.
When you use dbExpress, you are provided with a common framework, which is independent of the SQL database server you are planning to use. dbExpress comes with drivers for MySQL, InterBase, Oracle, Informix, Microsoft SQL Server, and IBM DB2.
| Note |
It is possible to write custom drivers for the dbExpress architecture. This is documented in detail in the paper "dbExpress Draft Specification," published on the Borland Community website. At the time of this writing, this document is at http://community.borland.com/article/0,1410,22495,00.html. You'll probably be able to find third-party drivers. For example, there is a free driver that bridges dbExpress and ODBC. A complete list is hosted in the article at http://community.borland.com/article/0,1410, 28371,00.html. |
Driver Versioning Troubles and Embedded Units
Technically, the dbExpress drivers are available as separate DLLs you have to deploy along with your program. This was the case with Delphi 6 and is still the case with Delphi 7. The problem is, these DLLs' names haven't changed. So, if you install a Delphi 7 compiled application on a machine that has the dbExpress drivers found in Delphi 6, the application will apparently work, open a connection to the server, and then fail when retrieving data. At that point you'll see the error "SQL Error: Error mapping failed." This is not a good hint that there is a version mismatch in the dbExpress driver!
To verify this problem, look at whether the DLL has any version information—it was missing from the Delphi 6 drivers. To make your applications more robust, you can provide a similar check within your code, accessing the version information using the related Windows APIs:
function GetDriverVersion (strDriverName: string): Integer; var nInfoSize, nDetSize: DWord; pVInfo, pDetail: Pointer; begin // the default, in case there is no version information Result := 6; // read version information nInfoSize := GetFileVersionInfoSize (pChar(strDriverName), nDetSize); if nInfoSize > 0 then begin GetMem (pVInfo, nInfoSize); try GetFileVersionInfo (pChar(strDriverName), 0, nInfoSize, pVInfo); VerQueryValue (pVInfo, '', pDetail, nDetSize); Result := HiWord (TVSFixedFileInfo(pDetail^).dwFileVersionMS); finally FreeMem (pVInfo); end; end; end;
This code snippet is taken from the DbxMulti example discussed later. The program uses it to raise an exception if the version is incompatible:
if GetDriverVersion ('dbexpint.dll') <> 7 then
raise Exception.Create (
'Incompatible version of the dbExpress driver "dbexpint.dll" found');
If you try to put the driver found in Delphi 6's bin folder in the application folder, you'll see the error. You'll have to modify this extra safety check to account for updated versions of the drivers or libraries, but this step should help you avoid the installation troubles dbExpress meant to solve in the first place.
You also have an alternative: You can statically link the dbExpress drivers' code into your application. To do so, include a given unit (like dbexpint.dcu or dbexpora.dcu) in your program, listing it in one of the uses statements.
| Warning |
Along with one of these units you need to include the MidasLib unit and link the code of the MIDAS.DLL into your program. If you fail to do so, the linker of Delphi 7 will stop showing an internal error, which is rather pointless information. Notice also that the embedded dbExpress drivers don't work properly with the international character set. |
The dbExpress Components
The VCL components used to interface the dbExpress library encompass a group of dataset components plus a few ancillary ones. To differentiate these components from other database-access families, the components are prefixed with the letters SQL, underlining the fact that they are used for accessing RDBMS servers.
These components include a database connection component, a few dataset components (a generic one; three specific versions for tables, queries, and stored procedures; and one encapsulating a ClientDataSet component), and a monitor utility.
The SQLConnection Component
The TSQLConnection class inherits from the TCustomConnection component. It handles database connections, the same as its sibling classes (the Database, ADOConnection, and IBConnection components).
| Tip |
Unlike other component families, in dbExpress the connection is compulsory. In the dataset components, you cannot specify directly which database to use, but can only refer to a SQLConnection. |
The connection component uses the information available in the drivers.ini and connections.ini files, which are dbExpress's only two configuration files (these files are saved by default under Common FilesBorland SharedDBExpress). The drivers.ini file lists the available dbExpress drivers, one for each supported database. For each driver there is a set of default connection parameters. For example, the InterBase section reads as follows:
[Interbase] GetDriverFunc=getSQLDriverINTERBASE LibraryName=dbexpint.dll VendorLib=GDS32.DLL BlobSize=-1 CommitRetain=False Database=database.gdb Password=masterkey RoleName=RoleName ServerCharSet=ASCII SQLDialect=1 Interbase TransIsolation=ReadCommited User_Name=sysdba WaitOnLocks=True
The parameters indicate the dbExpress driver DLL (the LibraryName value), the entry function to use (GetDriverFunc), the vendor client library, and other specific parameters that depend on the database. If you read the entire drivers.ini file, you'll see that the parameters are really database-specific. Some of these parameters don't make a lot of sense at the driver level (such as the database to connect to), but the list includes all the available parameters, regardless of their usage.
The connections.ini file provides the database-specific description. This list associates settings with a name, and you can enter multiple connection details for every database driver. The connection describes the physical database you want to connect to. As an example, this is the portion for the default IBLocal definition:
[IBLocal] BlobSize=-1 CommitRetain=False Database=C:Program FilesCommon FilesBorland SharedDataemployee.gdb DriverName=Interbase Password=masterkey RoleName=RoleName ServerCharSet=ASCII SQLDialect=1 Interbase TransIsolation=ReadCommited User_Name=sysdba WaitOnLocks=True
As you can see by comparing the two listings, this is a subset of the driver's parameters. When you create a new connection, the system will copy the default parameters from the driver; you can then edit them for the specific connection—for example, providing a proper database name. Each connection relates to the driver for its key attributes, as indicated by the DriverName property. Notice also that the database referenced here is the result of my editing, corresponding to the settings I'll use in most examples.
It's important to remember that these initialization files are used only at design time. When you select a driver or a connection at design time, the values of these files are copied to corresponding properties of the SQLConnection component, as in this example:
object SQLConnection1: TSQLConnection ConnectionName = 'IBLocal' DriverName = 'Interbase' GetDriverFunc = 'getSQLDriverINTERBASE' LibraryName = 'dbexpint.dll' LoginPrompt = False Params.Strings = ( 'BlobSize=-1' 'CommitRetain=False' 'Database=C:Program FilesCommon FilesBorland SharedDataemployee.gdb' 'DriverName=Interbase' 'Password=masterkey' 'RoleName=RoleName' 'ServerCharSet=ASCII' 'SQLDialect=1' 'Interbase TransIsolation=ReadCommited' 'User_Name=sysdba' 'WaitOnLocks=True') VendorLib = 'GDS32.DLL' end
At run time, your program will rely on the properties to have all the required information, so you don't need to deploy the two configuration files along with your programs. In theory, the files will be required if you want to change the DriverName or ConnectionName properties at run time. However, if you want to connect your program to a new database, you can set the relevant properties directly.
When you add a new SQLConnection component to an application, you can proceed in different ways. You can set up a driver using the list of values available for the DriverName property and then select a predefined connection by selecting one of the values available in the ConnectionName property. This second list is filtered according to the driver you've already selected. As an alternative, you can begin by selecting the ConnectionName property directly; in this case it includes the entire list.
Instead of hooking up an existing connection, you can define a new one (or see the details of the existing connections) by double-clicking the SQLConnection component and launching the dbExpress Connection Editor (see Figure 14.4). This editor lists on the left all the predefined connections (for a specific driver or all of them) and allows you to edit the connection properties using the grid on the right. You can use the toolbar buttons to add, delete, rename, and test connections, and to open the read-only dbExpress Drivers Settings window (also shown in Figure 14.4).
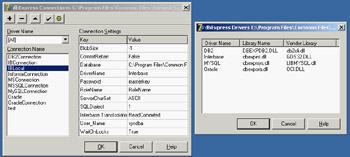
Figure 14.4: The dbExpress Connection Editor with the dbExpress Drivers Settings dialog box
In addition to letting you edit the predefined connection settings, the dbExpress Connection Editor allows you to select a connection for the SQLConnection component by clicking the OK button. Note that if you change any settings, the data is immediately written to the configuration files—clicking the Cancel button doesn't undo your editing!
To define access to a database, editing the connection properties is certainly the suggested approach. This way, when you need to access the same database from another application or another connection within the same application, all you need to do is select the connection. However, because this operation copies the connection data, updating the connection doesn't automatically refresh the values within other SQLConnection components referring to the same named connection: You must reselect the connection to which these other components refer.
What really matters for the SQLConnection component is the value of its properties. Driver and vendor libraries are listed in properties you can freely change at design time (although you'll rarely want to do this), whereas the database and other database-specific connection settings are specified in the Params properties. This is a string list including information such as the database name, the username and password, and so on. In practice, you could set up a SQLConnection component by setting up the driver and then assigning the database name directly in the Params property, forgetting about the predefined connection. I'm not suggesting this as the best option, but it is certainly a possibility; the predefined connections are handy, but when the data changes, you still have to manually refresh every SQLConnection component.
To be complete, I have to mention that there is an alternative. You can set the LoadParamsOnConnect property to indicate that you want to refresh the component parameters from the initialization files every time you open the connection. In this case, a change in the predefined connections will be reloaded when you open the connection, at either design time or run time. At design time, this technique is handy (it has the same effect as reselecting the connection); but using it at run time means you'll also have to deploy the connections.ini file, which can be a good idea or inconvenient, depending on your deployment environment.
The only property of the SQLConnection component that is not related to the driver and database settings is LoginPrompt. Setting it to False allows you to provide a password among the component settings and skip the login request dialog box, both at design time and at run time. Although this is handy for development, it can reduce the security of your system. Of course, you should also use this option for unattended connections, such as on a web server.
The dbExpress Dataset Components
The dbExpress component's family provides four different dataset components: a generic dataset, a table, a query, and a stored procedure. The latter three components are provided for compatibility with the equivalent BDE components and have similarly named properties. If you don't have to port existing code, you should generally use the general SQLDataSet component, which lets you execute a query and also access a table or a stored procedure.
The first important thing to notice is that all these datasets inherit from a new special base class, TCustomSQLDataSet. This class and its derived classes represent unidirectional datasets, with the key features I've already described. In practice, this means that the browse operations are limited to calling First and Next; Prior, Last, Locate, the use of bookmarks, and all other navigational features are disabled.
| Note |
Technically, some of the moving operations call the CheckBiDirectional internal function and eventually raise an exception. CheckBiDirectional refers to the public IsUnidirectional property of the TDataSet class, which you can eventually use in your own code to disable operations that are illegal on unidirectional datasets. |
In addition to having limited navigational capabilities, these datasets have no editing support, so a lot of methods and events common to other datasets are not available. For example, there is no AfterEdit or BeforePost event.
As I mentioned earlier, of the four dataset components for dbExpress, the fundamental one is TSQLDataSet, which can be used both to retrieve a dataset and to execute a command. The two alternatives are activated by calling the Open method (or setting the Active property to True) and by calling the ExecSQL method.
The SQLDataSet component can retrieve an entire table, or it can use a SQL query or a stored procedure to read a dataset or issue a command. The CommandType property determines one of the three access modes. The possible values are ctQuery, ctStoredProc, and ctTable, which determine the value of the CommandText property (and also the behavior of the related property editor in the Object Inspector). For a table or stored procedure, the CommandText property indicates the name of the related database element, and the editor provides a drop-down list containing the possible values. For a query, the CommandText property stores the text of the SQL command, and the editor provides a little help in building the SQL query (in case it is a SELECT statement). You can see the editor in Figure 14.5.
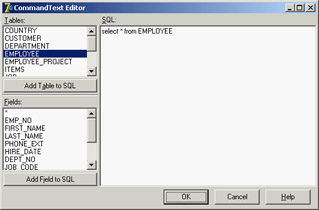
Figure 14.5: The CommandText Editor used by the SQLDataSet com-ponent for queries
When you use a table, the component will generate a SQL query for you, because dbExpress targets only SQL databases. The generated query will include all the fields of the table, and if you specify the SortFieldNames property, it will include a sort by directive.
The three specific dataset components offer similar behavior, but you specify the SQL query in the SQL string list property, the stored procedure in the StoredProcName property, and the table name in the TableName property (as in the three corresponding BDE components).
The Delphi 7 SimpleDataSet Component
The SimpleDataSet component is new in Delphi 7. It is a combination of four existing components: SQLConnection, SQLDataSet, DataSetProvider, and ClientDataSet. The component is meant to be a helper—you need only one component instead of four (which must also be connected). The component is basically a client dataset with two compound components (the two dbExpress ones), plus a hidden provider. (The fact that the provider is hidden is odd, because it is created as a compound component.)
The component allows you to modify the properties and events of the compound components (besides the provider) and replace the internal connection with an external one, so that multiple datasets share the same database connection. In addition to this issue, the component has other limitations, including difficulty manipulating the dataset fields of the data access dataset (which is important for setting key fields and can affect the way updates are generated) and unavailability of some provider events. So, other than for simple applications, I don't recommend using the SimpleDataSet component.
| Note |
Delphi 6 shipped with an even simpler and more limited component called SQLClientDataSet. Similar components were available for the BDE and IBX data access technologies. Now Borland has indicated that all these components are obsolete. However, the directory DemosDbSQLClientDataset contains a copy of the original component, and you can install it in Delphi 7 for compatibility purposes. But just as the SimpleDataSet component is somewhat limited, I found the SQLClientDataSet component totally unusable. |
The SQLMonitor Component
The final component in the dbExpress group is SQLMonitor, which is used to log requests sent from dbExpress to the database server. This monitor lets you see the commands sent to the database and the low-level responses you receive, monitoring the client/server traffic at a low level.
The TimeStamp Field Type
Along with dbExpress, Delphi 6 introduced the TSQLTimeStampField field type, which is mapped to the time stamp data type that many SQL servers have (InterBase included). A time stamp is a record-based representation of a date or time, and it's quite different from the floating-point representation used by the TDateTime data type. A time stamp is defined as follows:
TSQLTimeStamp = packed record Year : SmallInt; Month : Word; Day : Word; Hour : Word; Minute : Word; Second : Word; Fractions : LongWord; end;
A time stamp field can automatically convert standard date and time values using the AsDateTime property (as opposed to the native AsSQLTimeStamp property). You can also do custom conversions and further manipulation of time stamps using the routines provided by the SqlTimSt unit, including functions like DateTimeToSQLTimeStamp, SQLTimeStampToStr, and VarSQLTimeStampCreate.
A Few dbExpress Demos
Let's look at a demonstration that highlights the key features of these components and shows how to use the ClientDataSet to provide caching and editing support for the unidirectional datasets. Later, I'll show you an example of native use of the unidirectional query, with no caching and editing support required.
The standard visual application based on dbExpress uses this series of components:
- The SQLConnection component provides the connection with the database and the proper dbExpress driver.
- The SQLDataSet component, which is hooked to the connection (via the SQLConnection property), indicates which SQL query to execute or table to open (using the CommandType and CommandText properties discussed earlier).
- The DataSetProvider component, connected with the dataset, extracts the data from the SQLDataSet and can generate the proper SQL update statements.
- The ClientDataSet component reads from the data provider and stores all the data (if its PacketRecords property is set to –1) in memory. You'll need to call its ApplyUpdates method to send the updates back to the database server (through the provider).
- The DataSource component allows you to surface the data from the ClientDataSet to the visual data-aware controls.
As I mentioned earlier, the picture can be simplified by using the SimpleDataSet component, which replaces the two datasets and the provider (and possibly even the connection). The SimpleDataSet component combines most of the properties of the components it replaces.
Using a Single Component or Many Components
For this first example, drop a SimpleDataSet component on a form and set the connection name of its Connection subcomponent. Set the CommandType and CommandText properties to specify which data to fetch, and set the PacketRecords property to indicate how many records to retrieve in each block.
These are the key properties of the component in the DbxSingle example:
object SimpleDataSet1: TSimpleDataSet Connection.ConnectionName = 'IBLocal' Connection.LoginPrompt = False DataSet.CommandText = 'EMPLOYEE' DataSet.CommandType = ctTable end
As an alternative, the DbxMulti example uses the entire sequence of components:
object SQLConnection1: TSQLConnection ConnectionName = 'IBLocal' LoginPrompt = False end object SQLDataSet1: TSQLDataSet SQLConnection = SQLConnection1 CommandText = 'select * from EMPLOYEE' end object DataSetProvider1: TDataSetProvider DataSet = SQLDataSet1 end object ClientDataSet1: TClientDataSet ProviderName = 'DataSetProvider1' end object DataSource1: TDataSource DataSet = ClientDataSet1 end
Both examples include some visual controls: a grid and a toolbar based on the action manager architecture.
Applying Updates
In every example based on a local cache, like the one provided by the ClientDataSet and SimpleDataSet components, it's important to write the local changes back to the database server. This is typically accomplished by calling the ApplyUpdates method. You can either keep the changes in the local cache for a while and then apply multiple updates at once, or you can post each change right away. In these two examples, I've gone for the latter approach, attaching the following event handler to the AfterPost (fired after an edit or an insert operation) and AfterDelete events of the ClientDataSet components:
procedure TForm1.DoUpdate(DataSet: TDataSet); begin // immediately apply local changes to the database SQLClientDataSet1.ApplyUpdates(0); end;
If you want to apply all the updates in a single batch, you can do so either when the form is closed or when the program ends, or you can let a user perform the update operation by selecting a specific command, possibly using the corresponding predefined action provided by Delphi 7. We'll explore this approach when discussing the update caching support of the ClientDataSet component in more detail later in this chapter.
Monitoring the Connection
Another feature I've added to the DbxSingle and DbxMulti examples is the monitoring capability offered by the SQLMonitor component. In the example, the component is activated as the program starts. In the DbxSingle example, because the SimpleDataSet embeds the connection, the monitor cannot be hooked to it at design time, but only when the program starts:
procedure TForm1.FormCreate(Sender: TObject); begin SQLMonitor1.SQLConnection := SimpleDataSet1.Connection; SQLMonitor1.Active := True; SimpleDataSet1.Active := True; end;
Every time a tracing string is available, the component fires the OnTrace event to let you choose whether to include the string in the log. If the LogTrace parameter of this event is True (the default value), the component logs the message in the TraceList string list and fires the OnLogTrace event to indicate that a new string has been added to the log.
The component can also automatically store the log into the file indicated by its FileName property, but I haven't used this feature in the example. All I've done is handle the OnTrace event, copying the entire log in the memo with the following code (producing the output shown in Figure 14.6):
procedure TForm1.SQLMonitor1Trace(Sender: TObject; CBInfo: pSQLTRACEDesc; var LogTrace: Boolean); begin Memo1.Lines := SQLMonitor1.TraceList; end;
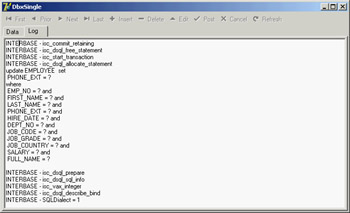
Figure 14.6: A sample log obtained by the SQLMonitor in the DbxSingle example
Controlling the SQL Update Code
If you run the DbxSingle program and change, for example, an employee's telephone number, the monitor will log this update operation:
update EMPLOYEE set PHONE_EXT = ? where EMP_NO = ? and FIRST_NAME = ? and LAST_NAME = ? and PHONE_EXT = ? and HIRE_DATE = ? and DEPT_NO = ? and JOB_CODE = ? and JOB_GRADE = ? and JOB_COUNTRY = ? and SALARY = ? and FULL_NAME = ?
By setting the SimpleDataSet's properties there is no way to change how the update code is generated (which happens to be worse than with the SQLClientDataSet component, which had the UpdateMode you could use to tweak the update statements).
In the DbxMulti example, you can use the UpdateMode property of the DataSetProvider component, setting the value to upWhereChanged or upWhereKeyOnly. In this case you'll get the following two statements, respectively:
update EMPLOYEE set PHONE_EXT = ? where EMP_NO = ? and PHONE_EXT = ? update EMPLOYEE set PHONE_EXT = ? where EMP_NO = ?
| Tip |
This result is much better than in Delphi 6 (without the patches applied), in which this operation caused an error because the key field was not properly set. |
If you want more control over how the update statements are generated, you need to operate on the fields of the underlying dataset, which are available also when you use the all-in-one SimpleDataSet component (which has two field editors, one for the base ClientDataset component it inherits from and one for the SQLDataSet component it embeds). I have made similar corrections in the DbxMulti example, after adding persistent fields for the SQLDataSet component and modifying the provider options for some of the fields to include them in the key or exclude them from updates.
| Note |
We'll discuss this type of problem again when we examine the details of the ClientDataSet component, the provider, the resolver, and other technical details later in this chapter and in Chapter 16. |
Accessing Database Metadata with SetSchemaInfo
All RDBMS systems use special-purpose tables (generally called system tables) for storing metadata, such as the list of the tables, their fields, indexes, and constraints, and any other system information. Just as dbExpress provides a unified API for working with different SQL servers, it also provides a common way to access metadata. The SQLDataSet component has a SetSchemaInfo method that fills the dataset with system information. This SetSchemaInfo method has three parameters:
SchemaType Indicates the type of information requested. Values include stTables, stSysTables, stProcedures, stColumns, and stProcedureParams.
SchemaObject Indicates the object you are referring to, such as the name of the table whose columns you are requesting.
SchemaPattern A filter that lets you limit your request to tables, columns, or procedures starting with the given letters. This is handy if you use prefixes to identify groups of elements.
For example, in the SchemaTest program, a Tables button reads into the dataset all of the connected database's tables:
ClientDataSet1.Close; SQLDataSet1.SetSchemaInfo (stTables, '', ''); ClientDataSet1.Open;
The program uses the usual group of dataset provider, client dataset, and data source component to display the resulting data in a grid, as you can see in Figure 14.7. After you're retrieved the tables, you can select a row in the grid and click the Fields button to see a list of the fields of this table:
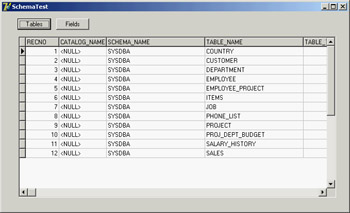
Figure 14.7: The SchemaTest example allows you to see a database's tables and the columns of a given table.
SQLDataSet1.SetSchemaInfo (stColumns, ClientDataSet1['Table_Name'], ''); ClientDataSet1.Close; ClientDataSet1.Open;
In addition to letting you access database metadata, dbExpress provides a way to access its own configuration information, including the installed drivers and the configured connections. The unit DbConnAdmin defines a TConnectionAdmin class for this purpose, but the aim of this support is limited to dbExpress add-on utilities for developers (end users aren't commonly allowed to access multiple databases in a totally dynamic way).
| Tip |
The DbxExplorer demo included in Delphi shows how to access both dbExpress administration files and schema information. Also check the help file under "The structure of metadata datasets" within the section "Developing database applications." |
A Parametric Query
When you need slightly different versions of the same SQL query, instead of modifying the text of the query itself each time, you can write a query with a parameter and change the value of the parameter. For example, if you decide to have a user choose the employees in a given country (using the employee table), you can write the following parametric query:
select * from employee where job_country = :country
In this SQL clause, :country is a parameter. You can set its data type and startup value using the editor of the SQLDataSet component's Params property collection. When the Params collection editor is open, as shown in Figure 14.8, you see a list of the parameters defined in the SQL statement; you can set the data type and the initial value of these parameters in the Object Inspector.
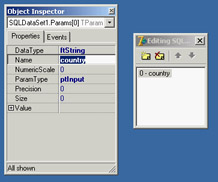
Figure 14.8: Editing a query component's collection of parameters
The form displayed by this program, called ParQuery, uses a combo box to provide all the available values for the parameters. Instead of preparing the combo box items at design time, you can extract the available contents from the same database table as the program starts. This is accomplished using a second query component, with this SQL statement:
select distinct job_country from employee
After activating this query, the program scans its result set, extracting all the values and adding them to the list box:
procedure TQueryForm.FormCreate(Sender: TObject); begin SqlDataSet2.Open; while not SqlDataSet2.EOF do begin ComboBox1.Items.Add (SqlDataSet2.Fields [0].AsString); SqlDataSet2.Next; end; ComboBox1.Text := CombBox1.Items[0]; end;
The user can select a different item in the combo box and then click the Select button (Button1) to change the parameter and activate (or re-activate) the query:
procedure TQueryForm.Button1Click(Sender: TObject); begin SqlDataSet1.Close; ClientDataSet1.Close; Query1.Params[0].Value := ListBox1.Items [Listbox1.ItemIndex]; SqlDataSet1.Open; ClientDataSet1.Open; end;
This code displays the employees from the selected country in the DBGrid, as you can see in Figure 14.9. As an alternative to using the elements of the Params array by position, you should consider using the ParamByName method, to avoid any problem in case the query gets modified over time and the parameters end up in a different order.
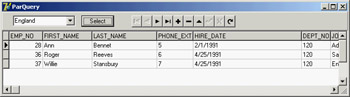
Figure 14.9: The ParQuery example at run time
By using parametric queries, you can usually reduce the amount of data moved over the wire from the server to the client and still use a DBGrid and the standard user interface common in local database applications.
| Tip |
Parametric queries are generally also used to obtain master-detail architectures with SQL queries—at least, this is what Delphi tends to do. The DataSource property of the SQLDataSet component, automatically replaces parameter values with the fields of the master dataset having the same name as the parameter. |
When One Way Is Enough Printing Data
You have seen that one of the key elements of the dbExpress library is that it returns unidirectional datasets. In addition, you can use the ClientDataSet component (in one of its incarnations) to store the records in a local cache. Now, let's discuss an example in which a unidirectional dataset is all you need.
Such a situation is common in reporting—that is, producing information for each record in sequence without needing any further access to the data. This broad category includes producing printed reports (via a set of reporting components or using the printer directly), sending data to another application such as Microsoft Excel or Word, saving data to files (including HTML and XML formats), and more.
I don't want to delve into HTML and XML, so I'll present an example of printing—nothing fancy and nothing based on reporting components, just a way to produce a draft report on your monitor and printer. For this reason, I've used Delphi's most straightforward technique to produce a printout: assigning a file to the printer with the AssignPrn RTL procedure.
The example, called UniPrint, has a unidirectional SQLDataSet component hooked to an InterBase connection and based on the following SQL statement, which joins the employee table with the department table to display the name of the department where each employee works:
select d.DEPARTMENT, e.FULL_NAME, e.JOB_COUNTRY, e.HIRE_DATE from EMPLOYEE e inner join DEPARTMENT d on d.DEPT_NO = e.DEPT_NO
To handle printing, I've written a somewhat generic routine, requiring as parameters the data to print, a progress bar for status information, the output font, and the maximum format size of each field. The entire routine uses file-print support and formats each field in a fixed-size, left-aligned string, to produce a columnar type of report. The call to the Format function has a parametric format string that's built dynamically using the size of the field.
In Listing 14.1 you can see the code of the core PrintOutDataSet method, which uses three nested try/finally blocks to release all the resources properly:
Listing 14.1: The Core Method of the UniPrint Example
procedure PrintOutDataSet (data: TDataSet;
progress: TProgressBar; Font: TFont; toFile: Boolean; maxSize: Integer = 30);
var
PrintFile: TextFile;
I: Integer;
sizeStr: string;
oldFont: TFontRecall;
begin
// assign the output to a printer or a file
if toFile then
begin
SelectDirectory ('Choose a folder', '', strDir);
AssignFile (PrintFile,
IncludeTrailingPathDelimiter(strDir) + 'output.txt');
end
else
AssignPrn (PrintFile);
// assign the printer to a file
AssignPrn (PrintFile);
Rewrite (PrintFile);
// set the font and keep the original one
oldFont := TFontRecall.Create (Printer.Canvas.Font);
try
Printer.Canvas.Font := Font;
try
data.Open;
try
// print header (field names) in bold
Printer.Canvas.Font.Style := [fsBold];
for I := 0 to data.FieldCount - 1 do
begin
sizeStr := IntToStr (min (data.Fields[i].DisplayWidth, maxSize));
Write (PrintFile, Format ('%-' + sizeStr + 's',
[data.Fields[i].FieldName]));
end;
Writeln (PrintFile);
// for each record of the dataset
Printer.Canvas.Font.Style := [];
while not data.EOF do
begin
// print out each field of the record
for I := 0 to data.FieldCount - 1 do
begin
sizeStr := IntToStr (min (data.Fields[i].DisplayWidth, maxSize));
Write (PrintFile, Format ('%-' + sizeStr + 's',
[data.Fields[i].AsString]));
end;
Writeln (PrintFile);
// advance ProgressBar
progress.Position := progress.Position + 1;
data.Next;
end;
finally
// close the dataset
data.Close;
end;
finally
// reassign the original printer font
oldFont.Free;
end;
finally
// close the printer/file
CloseFile (PrintFile);
end;
end;
The program invokes this routine when you click the Print All button. It executes a separate query (select count(*) from EMPLOYEE), which returns the number of records in the employee table. This query is necessary to set up the progress bar (the unidirectional dataset has no way of knowing how many records it will retrieve until it has reached the last one). Then it sets the output font, possibly using a fixed-width font, and calls the PrintOutDataSet routine:
procedure TNavigator.PrintAllButtonClick(Sender: TObject); var Font: TFont; begin // set ProgressBar range EmplCountData.Open; try ProgressBar1.Max := EmplCountData.Fields[0].AsInteger; finally EmplCountData.Close; end; Font := TFont.Create; try Font.Name := 'Courier New'; Font.Size := 9; PrintOutDataSet (EmplData, ProgressBar1, Font, cbFile.Checked); finally Font.Free; end; end;
The Packets and the Cache
The ClientDataSet component reads data in packets containing the number of records indicated by the PacketRecords property. The default value of this property is –1, which means the provider will pull all the records at once (this is reasonable only for a small dataset). Alternatively, you can set this value to zero to ask the server for only the field descriptors and no data, or you can use any positive value to specify a number.
If you retrieve only a partial dataset, then as you browse past the end of the local cache, if the FetchOnDemand property is set to True (the default value), the ClientDataSet component will get more records from its source. This property also controls whether BLOB fields and nested datasets of the current records are fetched automatically (these values might not be part of the data packet, depending on the dataset provider's Options value).
If you turn off this property, you'll need to fetch more records manually by calling the GetNextPacket method until the method returns zero. (You call FetchBlobs and FetchDetails for these other elements.)
| Warning |
Notice, by the way, that before you set an index for the data, you should retrieve the entire dataset (either by going to its last record or by setting the PacketRecords property to –1). Otherwise you'll have an odd index based on partial data. |
Manipulating Updates
One of the core ideas behind the ClientDataSet component is that it is used as a local cache to collect input from a user and then send a batch of update requests to the database. The component has both a list of the changes to apply to the database server, stored in the same format used by the ClientDataSet (accessible though the Delta property), and a complete update log that you can manipulate with a few methods (including an Undo capability).
| Tip |
In Delphi 7, the ClientDataSet component's ApplyUpdates and Undo operations are also accessible through predefined actions. |
The Status of the Records
The component lets you monitor what's going on within the data packets. The UpdateStatus method returns one of the following indicators for the current record:
type TUpdateStatus = (usUnmodified, usModified, usInserted, usDeleted);
To easily check the status of every record in the client dataset, you can add a string-type calculated field to the dataset (I've called it ClientDataSet1Status) and compute its value with the following OnCalcFields event handler:
procedure TForm1.ClientDataSet1CalcFields(DataSet: TDataSet); begin ClientDataSet1Status.AsString := GetEnumName (TypeInfo(TUpdateStatus), Integer (ClientDataSet1.UpdateStatus)); end;
This method (based on the RTTI GetEnumName function) converts the current value of the TUpdateStatus enumeration to a string, with the effect you can see in Figure 14.10.
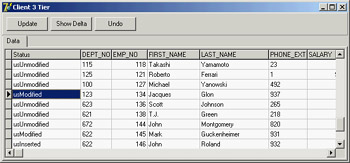
Figure 14.10: The CdsDelta program displays the status of each record of a ClientDataSet.
Accessing the Delta
Beyond examining the status of each record, the best way to understand which changes have occurred in a given ClientDataSet (but haven't been uploaded to the server) is to look at the delta—the list of changes waiting to be applied to the server. This property is defined as follows:
property Delta: OleVariant;
The format used by the Delta property is the same as that used for the data of a client dataset. You can add another ClientDataSet component to an application and connect it to the data in the Delta property of the first client dataset:
if ClientDataSet1.ChangeCount > 0 then begin ClientDataSet2.Data := ClientDataSet1.Delta; ClientDataSet2.Open;
In the CdsDelta example, I've added a data module with the two ClientDataSet components and a source of data: a SQLDataSet mapped to InterBase's EMPLOYEE demo table. Both client datasets have the extra status calculated field, with a slightly more generic version than the code discussed earlier, because the event handler is shared between them.
| Tip |
To create persistent fields for the ClientDataSet hooked to the delta (at run time), I've temporarily connected it at design time to the main ClientDataSet's provider. The delta's structure is the same as the dataset it refers to. After creating the persistent fields, I removed the connection. |
The application's form has a page control with two pages, each of which has a DBGrid, one for the data and one for the delta. Code hides or shows the second tab depending on the existence of data in the change log, as returned by the ChangeCount method, and updates the delta when the corresponding tab is selected. The core of the code used to handle the delta is similar to the previous code snippet, and you can study the example source code on the CD to see more details.
Figure 14.11 shows the change log of the CdsDelta application. Notice that the delta dataset has two entries for each modified record (the original values and the modified fields) unless this is a new or deleted record, as indicated by its status.
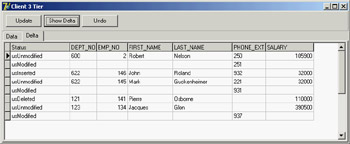
Figure 14.11: The CdsDelta example allows you to see the temporary update requests stored in the Delta property of the ClientDataSet.
| Tip |
You can filter the delta dataset (or any other ClientDataSet) depending on its update status, using the StatusFilter property. This property allows you to show new, updated, and deleted records in separate grids or in a grid filtered by selecting an option in a TabControl. |
Updating the Data
Now that you have a better understanding of what goes on during local updates, you can try to make this program work by sending the local update (stored in the delta) back to the database server. To apply all the updates from a dataset at once, pass –1 to the ApplyUpdates method.
If the provider (or the Resolver component inside it) has trouble applying an update, it triggers the OnReconcileError event. This can take place because of a concurrent update by two different people. We tend to use optimistic locking in client/server applications, so this should be regarded as a normal situation.
The OnReconcileError event allows you to modify the Action parameter (passed by reference), which determines how the server should behave:
procedure TForm1.ClientDataSet1ReconcileError(DataSet: TClientDataSet; E: EReconcileError; UpdateKind: TUpdateKind; var Action: TReconcileAction);
This method has three parameters: the client dataset component (in case there is more than one client dataset in the current application), the exception that caused the error (with the error message), and the kind of operation that failed (ukModify, ukInsert, or ukDelete). The return value, which you'll store in the Action parameter, can be any one of the following:
type TReconcileAction = (raSkip, raAbort, raMerge, raCorrect, raCancel, raRefresh);
raSkip Specifies that the server should skip the conflicting record, leaving it in the delta (this is the default value).
raAbort Tells the server to abort the entire update operation and not try to apply the remaining changes listed in the delta.
raMerge Tells the server to merge the client data with the data on the server, applying only the modified fields of this client (and keeping the other fields modified by other clients).
raCorrect Tells the server to replace its data with the current client data, overriding all field changes already made by other clients.
raCancel Cancels the update request, removing the entry from the delta and restoring the values originally fetched from the database (thus ignoring changes made by other clients).
raRefresh Tells the server to dump the updates in the client delta and to replace them with the values currently on the server (thus keeping the changes made by other clients).
To test a collision, you can launch two copies of the client application, change the same record in both clients, and then post the updates from both. We'll do this later to generate an error, but let's first see how to handle the OnReconcileError event.
Handling this event is not too difficult, but only because you'll receive a little help. Because building a specific form to handle an OnReconcileError event is common, Delphi provides such a form in the Object Repository (available with the File ® New ® Other menu command of the Delphi IDE). Go to the Dialogs page and select the Reconcile Error Dialog item. This unit exports a function you can use directly to initialize and display the dialog box, as I've done in the CdsDelta example:
procedure TDmCds.cdsEmployeeReconcileError (DataSet: TCustomClientDataSet; E: EReconcileError; UpdateKind: TUpdateKind; var Action: TReconcileAction); begin Action := HandleReconcileError(DataSet, UpdateKind, E); end;
| Warning |
As the source code of the Reconcile Error Dialog unit suggests, you should use the Project Options dialog to remove this form from the list of automatically created forms (if you don't, an error will occur when you compile the project). Of course, you need to do this only if you haven't set up Delphi to skip the automatic form creation. |
The HandleReconcileError function creates the dialog box form and shows it, as you can see in the code provided by Borland:
function HandleReconcileError(DataSet: TDataSet; UpdateKind: TUpdateKind; ReconcileError: EReconcileError): TReconcileAction; var UpdateForm: TReconcileErrorForm; begin UpdateForm := TReconcileErrorForm.CreateForm(DataSet, UpdateKind, ReconcileError); with UpdateForm do try if ShowModal = mrOK then begin Result := TReconcileAction(ActionGroup.Items.Objects[ ActionGroup.ItemIndex]); if Result = raCorrect then SetFieldValues(DataSet); end else Result := raAbort; finally Free; end; end;
The Reconc unit, which hosts the Reconcile Error dialog (a window titled Update Error to be more understandable by end-users of your programs), contains more than 350 lines of code, so I can't describe it in detail. However, you should be able to understand the source code by studying it carefully. Alternatively, you can use it without caring how everything works.
The dialog box will appear in case of an error, reporting the requested change that caused the conflict and allowing the user to choose one of the possible TReconcileAction values. You can see this form at run time in Figure 14.12.
Figure 14.12: The Reconcile Error dialog provided by Delphi in the Object Repository and used by the CdsDelta example
| Tip |
When you call ApplyUpdates, you start a complex update sequence, which is discussed in more detail in Chapter 16 for multitier architectures. In short, the delta is sent to the provider, which fires the OnUpdateData event and then receives a BeforeUpdateRecord event for every record to update. These are two chances you have to look at the changes and force specific operations on the database server. |
Using Transactions
Whenever you are working with a SQL server, you should use transactions to make your applications more robust. You can think of a transaction as a series of operations that are considered a single, "atomic" whole that cannot be split.
An example may help to clarify the concept. Suppose you have to raise the salary of each employee of a company by a fixed rate, as you did in the Total example in Chapter 13. A typical program would execute a series of SQL statements on the server, one for each record to update. If an error occurred during the operation, you might want to undo the previous changes. If you consider the operation "raise the salary of each employee" as a single transaction, it should either be completely performed or completely ignored. Or, consider the analogy with financial transactions—if an error causes only part of the operation to be performed, you might end up with a missed credit or with some extra money.
Working with database operations as transactions serves a useful purpose. You can start a transaction and do several operations that should all be considered parts of a single larger operation; then, at the end, you can either commit the changes or roll back the transaction, discarding all the operations done up to that moment. Typically, you might want to roll back a transaction if an error occurred during its operations.
There is another important element to underline: Transactions also serve a purpose when reading data. Until data is committed by a transaction, other connections and/or transactions should not see it. Once the data is committed from a transaction, others should see the change when reading the data—that is, unless you need to open a transaction and read the same data over and over for data analysis or complex reporting operations. Different SQL servers allow you to read data in transaction according to some or all of these alternatives, as you'll see when we discuss transaction isolation levels.
Handling transactions in Delphi is simple. By default, each edit/post operation is considered a single implicit transaction, but you can alter this behavior by handling the operations explicitly. Use the following three methods of the dbExpress SQLConnection component (other database connection components have similar methods):
StartTransaction Marks the beginning of a transaction
Commit Confirms all the updates to the database done during the transaction
Rollback Returns the database to its state prior to starting the transaction
You can also use the InTransaction property to check whether a transaction is active. You'll often use a try block to roll back a transaction when an exception is raised, or you can commit the transaction as the last operation of the try block, which is executed only when there is no error. The code might look like this:
var TD: TTransactionDesc; begin TD.TransactionID := 1; TD.IsolationLevel := xilREADCOMMITTED; SQLConnection1.StartTransaction(TD); try // -- operations within the transaction go here -- SQLConnection1.Commit(TD); except SQLConnection1.Rollback(TD); end;
Each transaction-related method has a parameter describing the transaction it is working with. The parameter uses the record type TTransactionDesc and accounts for a transaction isolation level and a transaction ID. The transaction isolation level is an indication of how the transaction should behave when other transactions make changes to the data. The three predefined values are as follows:
tiDirtyRead Makes the transaction's updates immediately visible to other transactions, even before they are committed. This is the only possibility in a few databases and corresponds to the behavior of databases with no transaction support.
tiReadCommitted Makes available to other transactions only the updates already committed by this transaction. This setting is recommended for most databases, to preserve efficiency.
tiRepeatableRead Hides changes made by every transaction started after the current one, even if the changes have been committed. Subsequent repeat calls within a transaction will always produce the same result, as if the database took a snapshot of the data when the current transaction started. Only InterBase and few other database servers work efficiently with this model.
| Tip |
As a general suggestion, for performance reasons transactions should involve a minimal number of updates (only those strictly related and part of a single atomic operation) and should be kept short in time. You should avoid transactions that wait for user input to complete them, because the user might be temporarily gone, and the transaction might remain active for a long time. Caching changes locally, as the ClientDataSet allows, can help you make the transactions small and fast, because you can open a transaction for reading, close it, and then open a transaction for writing out the entire batch of changes. |
The other field of the TTransactionDesc record holds a transaction ID. It is useful only in conjunction with a database server supporting multiple concurrent transactions over the same connection, like InterBase does. You can ask the connection component whether the server supports multiple transactions or doesn't support transactions at all, using the MultipleTransactionsSupported and TransactionsSupported properties.
When the server supports multiple transactions, you must supply each transaction with a unique identifier when calling the StartTransaction method:
var TD: TTransactionDesc; begin TD.TransactionID := GetTickCount; TD.IsolationLevel := xilREADCOMMITTED; SQLConnection1.StartTransaction(TD); SQLDataSet1.TransactionLevel := TD.TransactionID;
You can also indicate which datasets belong to which transaction by setting the TransactionLevel property of each dataset to a transaction ID, as shown in the last statement.
To further inspect transactions and to experiment with transaction isolation levels, you can use the TranSample application. As you can see in Figure 14.13, radio buttons let you choose the various isolation levels and buttons let you work on the transactions and apply updates or refresh data. To get a real idea of the different effects, you should run multiple copies of the program (provided you have enough licenses on your InterBase server).
Figure 14.13: The form of the TranSample application at design time. The radio buttons let you set different transaction isolation levels.
| Note |
InterBase doesn't support the "dirty read" mode, so in the TranSample program you cannot use the last option unless you work with a different server. |
Using InterBase Express
The examples built earlier in this chapter were created with the new dbExpress database library. Using this server-independent approach allows you to switch the database server used by your application, although in practice doing so is often far from simple. If the application you are building will invariably use a given database, you can write programs that are tied directly to the API of the specific database server. This approach will make your programs intrinsically non-portable to other SQL servers.
Of course, you won't generally use these APIs directly, but rather base your development on dataset components that wrap these APIs and fit into Delphi and the architecture of its class library. An example of such a family of components is InterBase Express (IBX). Applications built using these components should work better and faster (even if only marginally), giving you more control over the specific features of the server. For example, IBX provides a set of administrative components specifically built for InterBase 6.
| Note |
I'll examine the IBX components because they are tied to InterBase (the database server discussed in this chapter) and because they are the only set of components available in the standard Delphi installation. Other similar sets of components (for InterBase, Oracle, and other database servers) are equally powerful and well regarded in the Delphi programmers' community. A good example (and an alternative to IBX) is InterBase Objects (www.ibobjects.com). |
IBX Dataset Components
The IBX components include custom dataset components and a few others. The dataset components inherit from the base TDataSet class, can use all the common Delphi data-aware controls, and provide a field editor and all the usual design-time features. You can choose among multiple dataset components. Three IBX datasets have a role and a set of properties similar to the table/query/storedproc components in the dbExpress family:
- IBTable resembles the Table component and allows you to access a single table or view.
- IBQuery resembles the Query component and allows you to execute a SQL query, returning a result set. The IBQuery component can be used together with the IBUpdateSQL component to obtain a live (or editable) dataset.
- IBStoredProc resembles the StoredProc component and allows you to execute a stored procedure.
These components, like the related dbExpress ones, are intended for compatibility with older BDE components you might have used in your applications. For new applications, you should generally use the IBDataSet component, which allows you to work with a live result set obtained by executing a select query. It basically merges IBQuery with IBUpdateSQL in a single component. The three components in the previous list are provided mainly for compatibility with existing Delphi BDE applications.
Many other components in InterBase Express don't belong to the dataset category, but are still used in applications that need to access to a database:
- IBDatabase acts like the DBX SQLConnection component and is used to set up the database connection. The BDE also uses the specific Session component to perform some global tasks done by the IBDatabase component.
- IBTransaction allows complete control over transactions. It is important in InterBase to use transactions explicitly and to isolate each transaction properly, using the Snapshot isolation level for reports and the Read Committed level for interactive forms. Each dataset explicitly refers to a given transaction, so you can have multiple concurrent transactions against the same database and choose which datasets take part in which transaction.
- IBSQL lets you execute SQL statements that don't return a dataset (for example, DDL requests, or update and delete statements) without the overhead of a dataset component.
- IBDatabaseInfo is used for querying the database structure and status.
- IBSQLMonitor is used for debugging the system, because the SQL Monitor debugger provided by Delphi is a BDE-specific tool.
- IBEvents receives events posted by the server.
This group of components provides greater control over the database server than you can achieve with dbExpress. For example, having a specific transaction component allows you to manage multiple concurrent transactions over one or multiple databases, as well as a single transaction spanning multiple databases. The IBDatabase component allows you to create databases, test the connection, and generally access system data, something the Database and Session BDE components don't fully provide.
| Tip |
IBX datasets let you set up the automatic behavior of a generator as a sort of auto-increment field. You do so by setting the GeneratorField property using its specific property editor. An example is discussed later in this chapter in the section "Generators and IDs." |
IBX Administrative Components
The InterBase Admin page of Delphi's Component Palette hosts InterBase administrative components. Although your aim is probably not to build a full InterBase console application, including some administrative features (such as backup handling or user monitoring) can make sense in applications meant for power users.
Most of these components have self-explanatory names: IBConfigService, IBBackupService, IBRestoreService, IBValidationService, IBStatisticalService, IBLogService, IBSecurityService, IBServerProperties, IBInstall, and IBUninstall. I won't build any advanced examples that use these components, because they are more focused toward the development of server management applications than client programs. However, I'll embed a couple of them in the IbxMon example discussed later in this chapter.
Building an IBX Example
To build an example that uses IBX, you'll need to place in a form (or data module) at least three components: an IBDatabase, an IBTransaction, and a dataset component (in this case an IBQuery). Any IBX application requires at least an instance of the first two components. You cannot set database connections in an IBX dataset, as you can do with other datasets. And, at least a transaction object is required even to read the result of a query.
Here are the key properties of these components in the IbxEmp example:
object IBTransaction1: TIBTransaction Active = False DefaultDatabase = IBDatabase1 end object IBQuery1: TIBQuery Database = IBDatabase1 Transaction = IBTransaction1 CachedUpdates = False SQL.Strings = ( 'SELECT * FROM EMPLOYEE') end object IBDatabase1: TIBDatabase DatabaseName = 'C:Program FilesCommon FilesBorland SharedDataemployee.gdb' Params.Strings = ( 'user_name=SYSDBA' 'password=masterkey') LoginPrompt = False SQLDialect = 1 end
Now you can hook a DataSource component to IBQuery1 and easily build a user interface for the application. I had to type in the pathname of the Borland sample database. However, not everyone has the Program Files folder, which depends on the local version of Windows, and the Borland sample data files could be installed elsewhere on the disk. You'll solve these problems in the next example.
| Warning |
Notice that I've embedded the password in the code—a naïve approach to security. Not only can anyone run the program, but someone can extract the password by looking at the hexadecimal code of the executable file. I used this approach so I wouldn't need to keep typing in my password while testing the program, but in a real application you should require your users to do so to ensure the security of their data. |
Building a Live Query
The IbxEmp example includes a query that doesn't allow editing. To activate editing, you need to add an IBUpdateSQL component to the query, even if the query is trivial. Using an IBQuery that hosts the SQL select statement together with an IBUpdateSQL component that hosts the insert, update, and delete SQL statements is a typical approach from BDE applications. The similarities among these components make it easier to port an existing BDE application to this architecture. Here is the code for these components (edited for clarity):
object IBQuery1: TIBQuery Database = IBDatabase1 Transaction = IBTransaction1 SQL.Strings = ( 'SELECT Employee.EMP_NO, Department.DEPARTMENT, Employee.FIRST_NAME, '+ ' Employee.LAST_NAME, Job.JOB_TITLE, Employee.SALARY, Employee.DEPT_NO, '+ ' Employee.JOB_CODE, Employee.JOB_GRADE, Employee.JOB_COUNTRY' 'FROM EMPLOYEE Employee' ' INNER JOIN DEPARTMENT Department' ' ON (Department.DEPT_NO = Employee.DEPT_NO) ' ' INNER JOIN JOB Job' ' ON (Job.JOB_CODE = Employee.JOB_CODE) ' ' AND (Job.JOB_GRADE = Employee.JOB_GRADE) ' ' AND (Job.JOB_COUNTRY = Employee.JOB_COUNTRY) ' 'ORDER BY Department.DEPARTMENT, Employee.LAST_NAME') UpdateObject = IBUpdateSQL1 end object IBUpdateSQL1: TIBUpdateSQL RefreshSQL.Strings = ( 'SELECT Employee.EMP_NO, Employee.FIRST_NAME, Employee.LAST_NAME,'+ 'Department.DEPARTMENT, Job.JOB_TITLE, Employee.SALARY, Employee.DEPT_NO,'+ 'Employee.JOB_CODE, Employee.JOB_GRADE, Employee.JOB_COUNTRY' 'FROM EMPLOYEE Employee' 'INNER JOIN DEPARTMENT Department' 'ON (Department.DEPT_NO = Employee.DEPT_NO)' 'INNER JOIN JOB Job' 'ON (Job.JOB_CODE = Employee.JOB_CODE)' 'AND (Job.JOB_GRADE = Employee.JOB_GRADE)' 'AND (Job.JOB_COUNTRY = Employee.JOB_COUNTRY)' 'WHERE Employee.EMP_NO=:EMP_NO') ModifySQL.Strings = ( 'update EMPLOYEE' 'set' ' FIRST_NAME = :FIRST_NAME,' ' LAST_NAME = :LAST_NAME,' ' SALARY = :SALARY,' ' DEPT_NO = :DEPT_NO,' ' JOB_CODE = :JOB_CODE,' ' JOB_GRADE = :JOB_GRADE,' ' JOB_COUNTRY = :JOB_COUNTRY' 'where' ' EMP_NO = :OLD_EMP_NO') InsertSQL.Strings = ( 'insert into EMPLOYEE' '(FIRST_NAME, LAST_NAME, SALARY, DEPT_NO, JOB_CODE, JOB_GRADE, JOB_COUNTRY)' 'values' '(:FIRST_NAME,:LAST_NAME,:SALARY,:DEPT_NO,:JOB_CODE,:JOB_GRADE,:JOB_COUNTRY)') DeleteSQL.Strings = ( 'delete from EMPLOYEE ' 'where EMP_NO = :OLD_EMP_NO') end
For new applications, you should consider using the IBDataSet component, which sums up the features of IBQuery and IBUpdateSQL. The differences between using the two components and the single component are minimal. Using IBQuery and IBUpdateSQL is a better approach when you're porting an existing application based on the two equivalent BDE components, even if porting the program directly to the IBDataSet component doesn't require much extra work.
In the IbxUpdSql example, I've provided both alternatives so you can test the differences yourself. Here is the skeleton of the DFM description of the single dataset component:
object IBDataSet1: TIBDataSet Database = IBDatabase1 Transaction = IBTransaction1 DeleteSQL.Strings = ( 'delete from EMPLOYEE' 'where EMP_NO = :OLD_EMP_NO') InsertSQL.Strings = ( 'insert into EMPLOYEE' ' (FIRST_NAME, LAST_NAME, SALARY, DEPT_NO, JOB_CODE, JOB_GRADE, ' + ' JOB_COUNTRY)' 'values' ' (:FIRST_NAME, :LAST_NAME, :SALARY, :DEPT_NO, :JOB_CODE, ' + ' :JOB_GRADE, :JOB_COUNTRY)') SelectSQL.Strings = (...) UpdateRecordTypes = [cusUnmodified, cusModified, cusInserted] ModifySQL.Strings = (...) end
If you connect the IBQuery1 or the IBDataSet1 component to the data source and run the program, you'll see that the behavior is identical. Not only do the components have a similar effect; the available properties and events are also similar.
In the IbxUpdSql program, I've also made the reference to the database a little more flexible. Instead of typing in the database name at design time, I've extracted the Borland shared data folder from the Windows Registry (where Borland saves it while installing Delphi). Here is the code executed when the program starts:
uses
Registry;
procedure TForm1.FormCreate(Sender: TObject);
var
Reg: TRegistry;
begin
Reg := TRegistry.Create;
try
Reg.RootKey := HKEY_LOCAL_MACHINE;
Reg.OpenKey('SoftwareBorlandBorland SharedData', False);
IBDatabase1.DatabaseName := Reg.ReadString('Rootdir') + 'employee.gdb';
finally
Reg.Free;
end;
EmpDS.DataSet.Open;
end;
| Note |
For more information about the Windows Registry and INI files, see the related sidebar in Chapter 8, "The Architecture of Delphi Applications." |
Another feature of this example is the presence of a transaction component. As I've said, the InterBase Express components make the use of a transaction component compulsory, explicitly following a requirement of InterBase. Simply adding a couple of buttons to the form to commit or roll back the transaction would be enough, because a transaction starts automatically as you edit any dataset attached to it.
I've also improved the program by adding an ActionList component. This component includes all the standard database actions and adds two custom actions for transaction support: Commit and Rollback. Both actions are enabled when the transaction is active:
procedure TForm1.ActionUpdateTransactions(Sender: TObject); begin acCommit.Enabled := IBTransaction1.InTransaction; acRollback.Enabled := acCommit.Enabled; end;
When executed, they perform the main operation but also need to reopen the dataset in a new transaction (which can also be done by "retaining" the transaction context). CommitRetaining doesn't really reopen a new transaction, but it allows the current transaction to remain open. This way, you can keep using your datasets, which won't be refreshed (so you won't see edits already committed by other users) but will keep showing the data you've modified. Here is the code:
procedure TForm1.acCommitExecute(Sender: TObject); begin IBTransaction1.CommitRetaining; end; procedure TForm1.acRollbackExecute(Sender: TObject); begin IBTransaction1.Rollback; // reopen the dataset in a new transaction IBTransaction1.StartTransaction; EmpDS.DataSet.Open; end;
| Warning |
Be aware that InterBase closes any opened cursors when a transaction ends, which means you have to reopen them and refetch the data even if you haven't made any changes. When committing data, however, you can ask InterBase to retain the transaction context—not to close open datasets—by issuing a CommitRetaining command, as mentioned before. InterBase behaves this way because a transaction corresponds to a snapshot of the data. Once a transaction is finished, you are supposed to read the data again to refetch records that may have been modified by other users. Version 6.0 of InterBase includes a RollbackRetaining command, but I've decided not to use it because in a rollback operation, the program should refresh the dataset data to show the original values on screen, not the updates you've discarded. |
The last operation refers to a generic dataset and not a specific one, because I'm going to add a second alternate dataset to the program. The actions are connected to a text-only toolbar, as you can see in Figure 14.14. The program opens the dataset at startup and automatically closes the current transaction on exit, after asking the user what to do, with the following OnClose event handler:
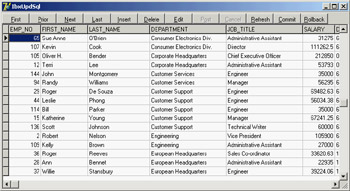
Figure 14.14: The output of the IbxUpdSql example
procedure TForm1.FormClose(Sender: TObject; var Action: TCloseAction);
var
nCode: Word;
begin
if IBTransaction1.InTransaction then
begin
nCode := MessageDlg ('Commit Transaction? (No to rollback)',
mtConfirmation, mbYesNoCancel, 0);
case nCode of
mrYes: IBTransaction1.Commit;
mrNo: IBTransaction1.Rollback;
mrCancel: Action := caNone; // don't close
end;
end;
end;
Monitoring InterBase Express
Like the dbExpress architecture, IBX also allows you to monitor a connection. You can embed a copy of the IBSQLMonitor component in your application and produce a custom log.
You can even write a more generic monitoring application, as I've done in the IbxMon example. I've placed in its form a monitoring component and a RichEdit control, and written the following handler for the OnSQL event:
procedure TForm1.IBSQLMonitor1SQL(EventText: String); begin if Assigned (RichEdit1) then RichEdit1.Lines.Add (TimeToStr (Now) + ': ' + EventText); end;
The if Assigned test can be useful when receiving a message during shutdown, and it is required when you add this code directly inside the application you are monitoring.
To receive messages from other applications (or from the current application), you have to turn on the IBDatabase component's tracing options. In the IbxUpdSql example (discussed in the preceding section, "Building a Live Query"), I turned them all on:
object IBDatabase1: TIBDatabase ... TraceFlags = [tfQPrepare, tfQExecute, tfQFetch, tfError, tfStmt, tfConnect, tfTransact, tfBlob, tfService, tfMisc]
If you run the two examples at the same time, the output of the IbxMon program will list details about the IbxUpdSql program's interaction with InterBase, as you can see in Figure 14.15.
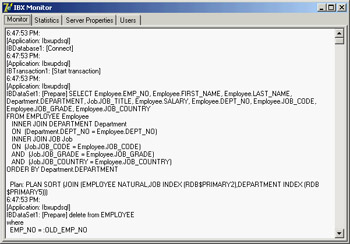
Figure 14.15: The output of the IbxMon example, based on the IBMonitor component
Getting More System Data
In addition to letting you monitor the InterBase connection, the IbxMon example allows you to query some server settings using the various tabs on its page control. The example embeds a few IBX administrative components, showing server statistics, server properties, and all connected users. You can see an example of the server properties in Figure 14.16. The code for extracting the users appears in the following code fragment.
Figure 14.16: The server informa-tion displayed by the IbxMon application
// grab the user's data
IBSecurityService1.DisplayUsers;
// display the name of each user
for i := 0 to IBSecurityService1.UserInfoCount - 1 do
with IBSecurityService1.UserInfo[i] do
RichEdit4.Lines.Add (Format ('User: %s, Full Name: %s, Id: %d',
[UserName, FirstName + ' ' + LastName, UserId]));
Real World Blocks
Up to now, we've discussed specific techniques related to InterBase programming, but we haven't delved into the development of an application and the problems this presents in practice. In the following subsections, I'll discuss a few practical techniques, in no specific order.
Nando Dessena (who knows InterBase much better than I do) and I have used all of these techniques in a seminar discussing the porting of an internal Paradox application to InterBase. The application we discussed in the seminar was large and complex, and I've trimmed it down to only a few tables to make it fit into the space I have for this chapter.
| Tip |
The database discussed in this section is called mastering.gdb. You can find it in the data subfolder of the code folder for this chapter. You can examine it using InterBase Console, possibly after making a copy to a writable drive so that you can fully interact with it. |
Generators and IDs
I mentioned in Chapter 13 that I'm a fan of using IDs extensively to identify the records in each table of a database.
| Note |
I tend to use a single sequence of IDs for an entire system, something often called an Object ID (OID) and discussed in a sidebar earlier in this chapter. In such a case, however, the IDs of the two tables must be unique. Because you might not know in advance which objects could be used in place of others, adopting a global OID allows you more freedom later. The drawback is that if you have lots of data, using a 32-bit integer as the ID (that is, having only 4 billion objects) might not be sufficient. For this reason, InterBase 6 supports 64-bit generators. |
How do you generate the unique values for these IDs when multiple clients are running? Keeping a table with a latest value will create troubles, because multiple concurrent transactions (from different users) will see the same values. If you don't use tables, you can use a database-independent mechanism, including the rather large Windows GUIDs or the so-called high-low technique (the assignment of a base number to each client at startup—the high number—that is combined with a consecutive number—the low number—determined by the client).
Another approach, bound to the database, is the use of internal mechanisms for sequences, indicated with different names in each SQL server. In InterBase they are called generators. These sequences operate and are incremented outside of transactions, so that they provide unique numbers even to concurrent users (remember that InterBase forces you to open a transaction to read data).
You've already seen how to create a generator. Here is the definition for the one in my demo database, followed by the definition of the view you can use to query for a new value:
create generator g_master; create view v_next_id ( next_id ) as select gen_id(g_master, 1) from rdb$database ;
Inside the RWBlocks application, I've added an IBQuery component to a data module (because I don't need it to be an editable dataset) with the following SQL:
select next_id from v_next_id;
The advantage, compared to using the direct statement, is that this code is easier to write and maintain, even if the underlying generator changes (or you switch to a different approach behind the scenes). Moreover, in the same data module, I've added a function that returns a new value for the generator:
function TDmMain.GetNewId: Integer; begin // return the next value of the generator QueryId.Open; try Result := QueryId.Fields[0].AsInteger; finally QueryId.Close; end; end;
This method can be called in the AfterInsert event of any dataset to fill in the value for the ID:
mydataset.FieldByName ('ID').AsInteger := data.GetNewId;
As I've mentioned, the IBX datasets can be tied directly to a generator, thus simplifying the overall picture. Thanks to the specific property editor (shown in Figure 14.17), connecting a field of the dataset to the generator becomes trivial.
Figure 14.17: The editor for the GeneratorField property of the IBX datasets
Notice that both these approaches are much better than the approach based on a server-side trigger, discussed earlier in this chapter. In that case, the Delphi application didn't know the ID of the record sent to the database and so was unable to refresh it. Not having the record ID (which is also the only key field) on the Delphi side means it is almost impossible to insert such a value directly inside a DBGrid. If you try, you'll see that the value you insert gets lost, only to reappear in case of a full refresh.
Using client-side techniques based on the manual code or the GeneratorField property causes no trouble. The Delphi application knows the ID (the record key) before posting it, so it can easily place it in a grid and refresh it properly.
Case Insensitive Searches
An interesting issue with SQL servers in general, not specifically InterBase, has to do with case-insensitive searches. Suppose you don't want to show a large amount of data in a grid (which is a bad idea for a client/server application). You instead choose to let the user type the initial portion of a name and then filter a query on this input, displaying only the smaller resulting record set in a grid. I've done this for a table of companies.
This search by company name will be executed frequently and will take place on a large table. However, if you search using the starting with or like operator, the search will be case sensitive, as in the following SQL statement:
select * from companies where name starting with 'win';
To make a case-insensitive search, you can use the upper function on both sides of the comparison to test the uppercase values of each string, but a similar query will be very slow, because it won't be based on an index. On the other hand, saving the company names (or any other name) in uppercase letters would be silly, because when you print those names, the result will be unnatural (even if common in old information systems).
If you can trade off some disk space and memory for the extra speed, you can use a trick: Add an extra field to the table to store the uppercase value of the company name, and use a server-side trigger to generate it and update it. You can then ask the database to maintain an index on the uppercase version of the name, to speed the search operation even further.
In practice, the table definition looks like this:
create domain d_uid as integer; create table companies ( id d_uid not null, name varchar(50), tax_code varchar(16), name_upper varchar(50), constraint companies_pk primary key (id) );
To copy the uppercase name of each company into the related field, you cannot rely on client-side code, because an inconsistency would cause problems. In a case like this, it is better to use a trigger on the server, so that each time the company name changes, its uppercase version is updated accordingly. Another trigger is used to insert a new company:
create trigger companies_bi for companies active before insert position 0 as begin new.name_upper = upper(new.name); end; create trigger companies_bu for companies active before update position 0 as begin if (new.name <> old.name) then new.name_upper = upper(new.name); end;
Finally, I've added an index to the table with this DDL statement:
create index i_companies_name_upper on companies(name_upper);
With this structure behind the scenes, you can now select all the companies starting with the text of an edit box (edSearch) by writing the following code in a Delphi application:
dm.DataCompanies.Close; dm.DataCompanies.SelectSQL.Text := 'select c.id, c.name, c.tax_code,' + ' from companies c ' + ' where name_upper starting with ''' + UpperCase (edSearch.Text) + ''''; dm.DataCompanies.Open;
| Tip |
Using a prepared parametric query, you might be able to make this code even faster. |
As an alternative, you could create a server-side calculated field in the table definition, but doing so would prevent you from having an index on the field, which speeds up your queries considerably:
name_upper varchar(50) computed by (upper(name))
Handling Locations and People
You might notice that the table describing companies is quite bare. It has no company address, nor any contact information. The reason is that I want to be able to handle companies that have multiple offices (or locations) and list contact information about multiple employees of those companies.
Every location is bound to a company. Notice, though, that I've decided not to use a location identifier related to the company (such as a progressive location number for each company), but rather a global ID for all the locations. This way, I can refer to a location ID (let's say, for shipping goods) without having to also refer to the company ID. This is the definition of the table that stores company locations:
create table locations ( id d_uid not null, id_company d_uid not null, address varchar(40), town varchar(30), zip varchar(10), state varchar(4), phone varchar(15), fax varchar(15), constraint locations_pk primary key (id), constraint locations_uc unique (id_company, id) ); alter table locations add constraint locations_fk_companies foreign key (id_company) references companies (id) on update no action on delete no action;
The final definition of a foreign key relates the id_company field of the locations table with the ID field of the companies table. The other table lists names and contact information for people at specific company locations. To follow the database normalization rules, I should have added to this table only a reference to the location, because each location relates to a company. However, to make it simpler to change the location of a person within a company and to make my queries much more efficient (avoiding an extra step), I've added to the people table both a reference to the location and a reference to the company.
The table has another unusual feature: One of the people working for a company can be set as the key contact. You obtain this functionality with a Boolean field (defined with a domain, because the Boolean type is not supported by InterBase) and by adding triggers to the table so that only one employee of each company can have this flag active:
create domain d_boolean as char(1)
default 'F'
check (value in ('T', 'F')) not null
create table people
(
id d_uid not null,
id_company d_uid not null,
id_location d_uid not null,
name varchar(50) not null,
phone varchar(15),
fax varchar(15),
email varchar(50),
key_contact d_boolean,
constraint people_pk primary key (id),
constraint people_uc unique (id_company, name)
);
alter table people add constraint people_fk_companies
foreign key (id_company) references companies (id)
on update no action on delete cascade;
alter table people add constraint people_fk_locations
foreign key (id_company, id_location)
references locations (id_company, id);
create trigger people_ai for people
active after insert position 0
as
begin
/* if a person is the key contact, remove the
flag from all others (of the same company) */
if (new.key_contact = 'T') then
update people
set key_contact = 'F'
where id_company = new.id_company
and id <> new.id;
end;
create trigger people_au for people
active after update position 0
as
begin
/* if a person is the key contact, remove the
flag from all others (of the same company) */
if (new.key_contact = 'T' and old.key_contact = 'F') then
update people
set key_contact = 'F'
where id_company = new.id_company
and id <> new.id;
end;
Building a User Interface
The three tables discussed so far have a clear master/detail relation. For this reason, the RWBlocks example uses three IBDataSet components to access the data, hooking up the two secondary tables to the main one. The code for the master/detail support is that of a standard database example based on queries, so I won't discuss it further (but I suggest you study the example's source code).
Each of the datasets has a full set of SQL statements, to make the data editable. Whenever you enter a new detail element, the program hooks it to its master tables, as in the two following methods:
procedure TDmCompanies.DataLocationsAfterInsert(DataSet: TDataSet); begin // initialize the data of the detail record // with a reference to the master record DataLocationsID_COMPANY.AsInteger := DataCompaniesID.AsInteger; end; procedure TDmCompanies.DataPeopleAfterInsert(DataSet: TDataSet); begin // initialize the data of the detail record // with a reference to the master record DataPeopleID_COMPANY.AsInteger := DataCompaniesID.AsInteger; // the suggested location is the active one, if available if not DataLocations.IsEmpty then DataPeopleID_LOCATION.AsInteger := DataLocationsID.AsInteger; // the first person added becomes the key contact // (checks whether the filtered dataset of people is empty) DataPeopleKEY_CONTACT.AsBoolean := DataPeople.IsEmpty; end;
As this code suggests, a data module hosts the dataset components. The program has a data module for every form (hooked up dynamically, because you can create multiple instances of each form). Each data module has a separate transaction so that the various operations performed in different pages are totally independent. The database connection, however, is centralized. A main data module hosts the corresponding component, which is referenced by all the datasets. Each of the data modules is created dynamically by the form referring to it, and its value is stored in the form's dm private field:
procedure TFormCompanies.FormCreate(Sender: TObject); begin dm := TDmCompanies.Create (Self); dsCompanies.Dataset := dm.DataCompanies; dsLocations.Dataset := dm.DataLocations; dsPeople.Dataset := dm.DataPeople; end;
This way, you can easily create multiple instances of a form, with an instance of the data module connected to each of them. The form connected to the data module has three DBGrid controls, each tied to a data module and one of the corresponding datasets. You can see this form at run time, with some data, in Figure 14.18.
Figure 14.18: A form showing companies, office locations, and people (part of the RWBlocks example)
The form is hosted by a main form, which in turn is based on a page control, with the other forms embedded. Only the form connected with the first page is created when the program starts. The ShowForm method I've written takes care of parenting the form to the tab sheet of the page control, after removing the form border:
procedure TFormMain.FormCreate(Sender: TObject); begin ShortDateFormat := 'dd/mm/yyyy'; ShowForm (TFormCompanies.Create (Self), TabCompanies); end; procedure TFormMain.ShowForm (Form: TForm; Tab: TTabSheet); begin Form.BorderStyle := bsNone; Form.Align := alClient; Form.Parent := Tab; Form.Show; end;
The other two pages are populated at run time:
procedure TFormMain.PageControl1Change(Sender: TObject); begin if PageControl1.ActivePage.ControlCount = 0 then if PageControl1.ActivePage = TabFreeQ then ShowForm (TFormFreeQuery.Create (self), TabFreeQ) else if PageControl1.ActivePage = TabClasses then ShowForm (TFormClasses.Create (self), TabClasses); end;
The companies form hosts the search by company name (discussed in the previous section) plus a search by location. You enter the name of a town and get back a list of companies having an office in that town:
procedure TFormCompanies.btnTownClick(Sender: TObject); begin with dm.DataCompanies do begin Close; SelectSQL.Text := 'select c.id, c.name, c.tax_code' + ' from companies c ' + ' where exists (select loc.id from locations loc ' + ' where loc.id_company = c.id and upper(loc.town) = ''' + UpperCase(edTown.Text) + ''' )'; Open; dm.DataLocations.Open; dm.DataPeople.Open; end; end;
The form includes a lot more source code. Some of it is related to closing permission (as a user cannot close the form while there are pending edits not posted to the database), and quite a bit relates to the use of the form as a lookup dialog, as described later.
Booking Classes
Part of the program and the database involves booking training classes and courses. (Although I built this program as a showcase, it also helps me run my own business.) The database includes a classes table that lists all the training courses, each with a title and the planned date. Another table hosts registration by company, including the classes registered for, the ID of the company, and some notes. Finally, a third table lists people who've signed up, each hooked to a registration for his or her company, with the amount paid.
The rationale behind this company-based registration is that invoices are sent to companies, which book the classes for programmers and can receive specific discounts. In this case the database is more normalized, because the people registration doesn't refer directly to a class, but only to the company registration for that class. Here are the definitions of the tables involved (I've omitted foreign key constraints and other elements):
create table classes ( id d_uid not null, description varchar(50), starts_on timestamp not null, constraint classes_pk primary key (id) ); create table classes_reg ( id d_uid not null, id_company d_uid not null, id_class d_uid not null, notes varchar(255), constraint classes_reg_pk primary key (id), constraint classes_reg_uc unique (id_company, id_class) ); create domain d_amount as numeric(15, 2); create table people_reg ( id d_uid not null, id_classes_reg d_uid not null, id_person d_uid not null, amount d_amount, constraint people_reg_pk primary key (id) );
The data module for this group of tables uses a master/detail/detail relationship, and has code to set the connection with the active master record when a new detail record is created. Each dataset has a generator field for its ID, and each has the proper update and insert SQL statements. These statements are generated by the corresponding component editor using only the ID field to identify existing records and updating only the fields in the original table. Each of the two secondary datasets retrieves data from a lookup table (either the list of companies or the list of people). I had to edit the RefreshSQL statements manually to repeat the proper inner join. Here is an example:
object IBClassReg: TIBDataSet Database = DmMain.IBDatabase1 Transaction = IBTransaction1 AfterInsert = IBClassRegAfterInsert DeleteSQL.Strings = ( 'delete from classes_reg' 'where id = :old_id') InsertSQL.Strings = ( 'insert into classes_reg (id, id_class, id_company, notes)' 'values (:id, :id_class, :id_company, :notes)') RefreshSQL.Strings = ( 'select reg.id, reg.id_class, reg.id_company, reg.notes, c.name ' 'from classes_reg reg' 'join companies c on reg.id_company = c.id' 'where id = :id') SelectSQL.Strings = ( 'select reg.id, reg.id_class, reg.id_company, reg.notes, c.name ' 'from classes_reg reg' 'join companies c on reg.id_company = c.id' 'where id_class = :id') ModifySQL.Strings = ( 'update classes_reg' 'set' ' id = :id,' ' id_class = :id_class,' ' id_company = :id_company,' ' notes = :notes' 'where id = :old_id') GeneratorField.Field = 'id' GeneratorField.Generator = 'g_master' DataSource = dsClasses end
To complete the discussion of IBClassReg, here is its only event handler:
procedure TDmClasses.IBClassRegAfterInsert(DataSet: TDataSet);
begin
IBClassReg.FieldByName ('id_class').AsString :=
IBClasses.FieldByName ('id').AsString;
end;
The IBPeopleReg dataset has similar settings, but the IBClasses dataset is simpler at design time. At run time, this dataset's SQL code is dynamically modified, using three alternatives to display scheduled classes (whenever the date is after today's date), classes already started or finished in the current year, and classes from past years. A user selects one of the three groups of records for the table with a tab control, which hosts the DBGrid for the main table (see Figure 14.19).
Figure 14.19: The RWBlocks example form for class registrations
The three alternative SQL statements are created when the program starts, or when the class registrations form is created and displayed. The program stores the final portion of the three alternative instructions (the where clause) in a string list and selects one of the strings when the tab changes:
procedure TFormClasses.FormCreate(Sender: TObject);
begin
dm := TDmClasses.Create (Self);
// connect the datasets to the data sources
dsClasses.Dataset := dm.IBClasses;
dsClassReg.DataSet := dm.IBClassReg;
dsPeopleReg.DataSet := dm.IBPeopleReg;
// open the datasets
dm.IBClasses.Active := True;
dm.IBClassReg.Active := True;
dm.IBPeopleReg.Active := True;
// prepare the SQL for the three tabs
SqlCommands := TStringList.Create;
SqlCommands.Add (' where Starts_On > ''now''');
SqlCommands.Add (' where Starts_On <= ''now'' and ' +
' extract (year from Starts_On ) >= extract(year from current_timestamp)');
SqlCommands.Add (' where extract (year from Starts_On) < ' +
' extract(year from current_timestamp)');
end;
procedure TFormClasses.TabChange(Sender: TObject);
begin
dm.IBClasses.Active := False;
dm.IBClasses.SelectSQL [1] := SqlCommands [Tab.TabIndex];
dm.IBClasses.Active := True;
end;
Building a Lookup Dialog
The two detail datasets of this class registration form display lookup fields. Instead of showing the ID of the company that booked the class, for example, the form shows the company name. You obtain this functionality with an inner join in the SQL statement and by configuring the DBGrid columns so they don't display the company ID. In a local application, or one with a limited amount of data, you could use a lookup field. However, copying the entire lookup dataset locally or opening it for browsing should be limited to tables with about 100 records at most, embedding some search capabilities.
If you have a large table, such as a table of companies, an alternative solution is to use a secondary dialog box to perform the lookup selection. For example, you can choose a company by using the form you've already built and taking advantage of its search capabilities. To display this form as a dialog box, the program creates a new instance of it, shows some hidden buttons already there at design time, and lets the user select a company to refer to from the other table.
To simplify the use of this lookup, which can happen multiple times in a large program, I've added to the companies form a class function that has as output parameters the name and ID of the selected company. An initial ID can be passed to the function to determine its initial selection. Here is the complete code of this class function, which creates an object of its class, selects the initial record if requested, shows the dialog box, and finally extracts the return values:
class function TFormCompanies.SelectCompany (
var CompanyName: string; var CompanyId: Integer): Boolean;
var
FormComp: TFormCompanies;
begin
Result := False;
FormComp := TFormCompanies.Create (Application);
FormComp.Caption := 'Select Company';
try
// activate dialog buttons
FormComp.btnCancel.Visible := True;
FormComp.btnOK.Visible := True;
// select company
if CompanyId > 0 then
FormComp.dm.DataCompanies.SelectSQL.Text :=
'select c.id, c.name, c.tax_code' +
' from companies c ' +
' where c.id = ' + IntToStr (CompanyId)
else
FormComp.dm.DataCompanies.SelectSQL.Text :=
'select c.id, c.name, c.tax_code' +
' from companies c ' +
' where name_upper starting with ''a''';
FormComp.dm.DataCompanies.Open;
FormComp.dm.DataLocations.Open;
FormComp.dm.DataPeople.Open;
if FormComp.ShowModal = mrOK then
begin
Result := True;
CompanyId := FormComp.dm.DataCompanies.FieldByName ('id').AsInteger;
CompanyName := FormComp.dm.DataCompanies.FieldByName ('name').AsString;
end;
finally
FormComp.Free;
end;
end;
Another slightly more complex class function (available with the example's source code, but not listed here) lets you select a person from a given company to register people for classes. In this case, the form is displayed after disallowing searching another company or modifying the company's data.
In both cases, you trigger the lookup by adding an ellipsis button to the column of the DBGrid—for example, the grid column listing the names of companies registered for classes. When this button is clicked, the program calls the class function to display the dialog box and uses its result to update the hidden ID field and the visible name field:
procedure TFormClasses.DBGridClassRegEditButtonClick(Sender: TObject);
var
CompanyName: string;
CompanyId: Integer;
begin
CompanyId := dm.IBClassReg.FieldByName ('id_Company').AsInteger;
if TFormCompanies.SelectCompany (CompanyName, CompanyId) then
begin
dm.IBClassReg.Edit;
dm.IBClassReg.FieldByName ('Name').AsString := CompanyName;
dm.IBClassReg.FieldByName ('id_Company').AsInteger := CompanyId;
end;
end;
Adding a Free Query Form
The program's final feature is a form where a user can directly type in and run a SQL statement. As a helper, the form lists in a combo box the available tables of the database, obtained when the form is created by calling
DmMain.IBDatabase1.GetTableNames (ComboTables.Items);
Selecting an item from the combo box generates a generic SQL query:
MemoSql.Lines.Text := 'select * from ' + ComboTables.Text;
The user (if an expert) can then edit the SQL, possibly introducing restrictive clauses, and then run the query:
procedure TFormFreeQuery.ButtonRunClick(Sender: TObject); begin QueryFree.Close; QueryFree.SQL := MemoSql.Lines; QueryFree.Open; end;
You can see this third form of the RWBlocks program in Figure 14.20. Of course, I'm not suggesting that you add SQL editing to programs intended for all your users—this feature is intended for power users or programmers. I basically wrote it for myself!
Figure 14.20: The free query form of the RWBlocks example is intended for power users.
What s Next?
This chapter has presented a detailed introduction to client/server programming with Delphi. We discussed the key issues and delved a little into interesting areas of client/server programming. After a general introduction, I discussed the use of the dbExpress database library. I also briefly covered the InterBase server and the InterBase Express (IBX) components. At the end of the chapter I presented a real-world example, going beyond the typical examples in the book to focus on a single feature at a time.
There is more I can say about client/server programming in Delphi. Chapter 15 will focus on Microsoft's ADO database engine. It's followed by a chapter on Delphi's multitier architecture, DataSnap; this chapter highlights the use of the dbExpress library and the ClientDataSet component, although in a slightly different context.
Part I - Foundations
- Delphi 7 and Its IDE
- The Delphi Programming Language
- The Run-Time Library
- Core Library Classes
- Visual Controls
- Building the User Interface
- Working with Forms
Part II - Delphi Object-Oriented Architectures
- The Architecture of Delphi Applications
- Writing Delphi Components
- Libraries and Packages
- Modeling and OOP Programming (with ModelMaker)
- From COM to COM+
Part III - Delphi Database-Oriented Architectures
- Delphis Database Architecture
- Client/Server with dbExpress
- Working with ADO
- Multitier DataSnap Applications
- Writing Database Components
- Reporting with Rave
Part IV - Delphi, the Internet, and a .NET Preview
- Internet Programming: Sockets and Indy
- Web Programming with WebBroker and WebSnap
- Web Programming with IntraWeb
- Using XML Technologies
- Web Services and SOAP
- The Microsoft .NET Architecture from the Delphi Perspective
- Delphi for .NET Preview: The Language and the RTL
- Appendix A Extra Delphi Tools by the Author
- Appendix B Extra Delphi Tools from Other Sources
- Appendix C Free Companion Books on Delphi
EAN: 2147483647
Pages: 279
