Working with ADO
Overview
Since the mid-1980s, database programmers have been on a quest for the "holy grail" of database independence. The idea is to use a single API that applications can use to interact with many different sources of data. The use of such an API would release developers from dependence on a single database engine and allow them to adapt to the world's changing demands. Vendors have produced many solutions to this goal, the two most notable early solutions being Microsoft's Open Database Connectivity (ODBC) and Borland's Integrated Database Application Programming Interface (IDAPI), more commonly known as the Borland Database Engine (BDE).
Microsoft started to replace ODBC with OLE DB in the mid-1990s with the success of the Component Object Model (COM). However, OLE DB is what Microsoft would class a system-level interface and is intended to be used by system-level programmers. It is very large, complex, and unforgiving. It makes greater demands on the programmer and requires a higher level of knowledge in return for lower productivity. ActiveX Data Objects (ADO) is a layer on top of OLE DB and is referred to as an application-level interface. It is considerably simpler than OLE DB and more forgiving. In short, it is designed for use by application programmers.
As you saw in Chapter 14, "Client/Server with dbExpress," Borland has also replaced the BDE with a newer technology called dbExpress. ADO shares greater similarities with the BDE than with the lightweight dbExpress technology. BDE and ADO support navigation and manipulation of datasets, transaction processing, and cached updates (called batch updates in ADO), so the concepts and issues involved in using ADO are similar to those of the BDE.
| Note |
I wish to acknowledge and thank Guy Smith-Ferrier for originally writing this chapter for Mastering Delphi 6. Guy is a programmer, author, and speaker. He is the author of several commercial software products and countless internal systems for independent and blue-chip companies alike. He has written many articles for The Delphi Magazine and for others on topics beyond Delphi, and he has spoken at numerous conferences in North America and Europe. Guy lives in England with his wife, his son, and his cat. |
In this chapter we will look at ADO. We will also discuss dbGo—a set of Delphi components initially called ADOExpress, but renamed in Delphi 6 because Microsoft objects to the use of the term ADO in third-party product names. It is possible to use ADO in Delphi without using dbGo. By importing the ADO type library, you can gain direct access to the ADO interfaces; this is how Delphi programmers used ADO before the release of Delphi 5. However, this path bypasses Delphi's database infrastructure and ensures that you are unable to make use of other Delphi technologies such as the data-aware controls or DataSnap. This chapter uses dbGo for all of its examples, not only because it is readily available and supported but also because it is a very viable solution. Regardless of your final choice, you will find the information here useful.
| Note |
Alternatively, you can turn to Delphi's active third-party market for other ADO component suites such as Adonis, AdoSolutio, Diamond ADO, and Kamiak. |
Microsoft Data Access Components (MDAC)
ADO is part of a bigger picture called Microsoft Data Access Components (MDAC). MDAC is an umbrella for Microsoft's database technologies and includes ADO, OLE DB, ODBC, and RDS (Remote Data Services). Often you will hear people use the terms MDAC and ADO interchangeably, but incorrectly. Because ADO is only distributed as part of MDAC, we talk of ADO versions in terms of MDAC releases. The major releases of MDAC have been versions 1.5, 2.0, 2.1, 2.5, and 2.6. Microsoft releases MDAC independently and makes it available for free download and virtually free distribution (there are distribution requirements, but most Delphi developers will have no trouble meeting them). MDAC is also distributed with most Microsoft products that have database content. Delphi 7 ships with MDAC 2.6.
There are two consequences of this level of availability. First, it is highly likely that your users will already have MDAC installed on their machines. Second, whatever version your users have, or you upgrade them to, it is also virtually certain that someone—you, your users, or other application software—will upgrade their existing MDAC to the current release of MDAC. You can't prevent this upgrade, because MDAC is installed with such commonly used software as Internet Explorer. Add to this the fact that Microsoft supports only the current release of MDAC and the release before it, and you are arrive at this conclusion: Applications must be designed to work with the current release of MDAC or the release before it.
As an ADO developer, you should regularly check the MDAC pages on Microsoft's website at www.microsoft.com/data. From there you can download the latest version of MDAC for free. While you are on this website, you should take the opportunity to download the MDAC SDK (13 MB) if you do not already have it or the Platform SDK (the MDAC SDK is part of the Platform SDK). The MDAC SDK is your bible: Download it, consult it regularly, and use it to answer your ADO questions. You should treat it as your first port of call when you need MDAC information.
OLE DB Providers
OLE DB providers enable access to a source of data. They are ADO's equivalent to the dbExpress drivers and the BDE SQL Links. When you install MDAC, you automatically install the OLE DB providers shown in Table 15.1:
|
Driver |
Provider |
Description |
|---|---|---|
|
MSDASQL |
ODBC Drivers |
ODBC drivers (default) |
|
Microsoft.Jet.OLEDB.3.5 |
Jet 3.5 |
MS Access 97 databases only |
|
Microsoft.Jet.OLEDB.4.0 |
Jet 4.0 |
MS Access and other databases |
|
SQLOLEDB |
SQL Server |
MS SQL Server databases |
|
MSDAORA |
Oracle |
Oracle databases |
|
MSOLAP |
OLAP Services |
Online Analytical Processing |
|
SampProv |
Sample provider |
Example of an OLE DB provider for CSV files |
|
MSDAOSP |
Simple provider |
For creating your own providers for simple text data |
- The ODBC OLE DB provider is used for backward compatibility with ODBC. As you learn more about ADO, you will discover the limitations of this provider.
- The Jet OLE DB providers support MS Access and other desktop databases. We will return to these providers later.
- The SQL Server provider supports SQL Server 7, SQL Server 2000, and Microsoft Database Engine (MSDE). MSDE is a reduced version of SQL Server, with most of the tools removed and some code added to deliberately degrade performance when there are more than five active connections. MSDE is important because it is free and it is fully compatible with SQL Server.
- The OLE DB provider for OLAP can be used directly but is more often used by ADO Multi-Dimensional (ADOMD). ADOMD is an additional ADO technology designed to provide Online Analytical Processing (OLAP). If you have used Delphi's Decision Cube, Excel's Pivot Tables, or Access's Cross Tabs, then you have used some form of OLAP.
In addition to these MDAC OLE DB providers, Microsoft supplies other OLE DB providers with other products or with downloadable SDKs:
- The Active Directory Services OLE DB provider is included with the ADSI SDK; the AS/400 and VSAM OLE DB provider is included with SNA Server; and the Exchange OLE DB provider is included with Microsoft Exchange 2000.
- The OLE DB provider for Indexing Service is part of Microsoft Indexing Service, a Windows mechanism that speeds up file searches by building catalogs of file information. Indexing Service is integrated into IIS and, consequently, is often used for indexing websites.
- The OLE DB provider for Internet Publishing allows developers to manipulate directories and files using HTTP.
- Still more OLE DB providers come in the form of service providers. As their name implies, OLE DB service providers provide a service to other OLE DB providers and are often invoked automatically as needed without programmer intervention. The Cursor Service, for example, is invoked when you create a client-side cursor, and the Persisted Recordset provider is invoked to save data locally.
MDAC includes many providers that I'll discuss, but many more are available from Microsoft and from the third-party market. It is impossible to reliably list all available OLE DB providers, because the list is so large and changes constantly. In addition to independent third parties, you should consider most database vendors, because the majority now supply their own OLE DB providers. For example, Oracle supplies the ORAOLEDB provider.
| Tip |
A notable omission from the vendors that supply OLE DB providers is InterBase. In addition to accessing it using the ODBC driver, you can use Dmitry Kovalenko's IBProvider (www.lcpi.lipetsk.ru/prog/eng/index.html). Also check Binh Ly's OLE DB Provider Development Toolkit (www.techvanguards.com/products/optk/install.htm ). If you want to write your own OLE DB provider, this tool is easier to use than most. |
Using dbGo Components
Programmers familiar with the BDE, dbExpress, or IBExpress should recognize the set of components that make up dbGo (Table 15.2).
|
dbGo Component |
Description |
BDE Equivalent Component |
|---|---|---|
|
ADOConnection |
Connection to a database |
Database |
|
ADOCommand |
Executes an action SQL command |
No equivalent |
|
ADODataSet |
All-purpose descendant of TDataSet |
No equivalent |
|
ADOTable |
Encapsulation of a table |
Table |
|
ADOQuery |
Encapsulation of SQL SELECT |
Query |
|
ADOStoredProc |
Encapsulation of a stored procedure |
StoredProc |
|
RDSConnection |
Remote Data Services connection |
No equivalent |
The four dataset components (ADODataSet, ADOTable, ADOQuery, and ADOStoredProc) are implemented almost entirely by their immediate ancestor class, TCustomADODataSet. This component provides the majority of dataset functionality, and its descendants are mostly thin wrappers that expose different features of the same component. As such, the components have a lot in common. In general, however, ADOTable, ADOQuery, and ADOStoredProc are viewed as "compatibility" components and are used to aid the transition of knowledge and code from their BDE counterparts. Be warned, though: These compatibility components are similar to their counterparts but not identical. You will find differences in any application except the most trivial. ADODataSet is the component of choice partly because of its versatility but also because it is closer in appearance to the ADO Recordset interface upon which it is based. Throughout this chapter, I'll use all the dataset components to give you the experience of using each.
A Practical Example
Enough theory: Let's see some action. Drop an ADOTable onto a form. To indicate the database to connect to, ADO uses connection strings. You can type in a connection string by hand if you know what you are doing. In general, you'll use the connection string editor (the property editor of the ConnectionString property), shown in Figure 15.1.
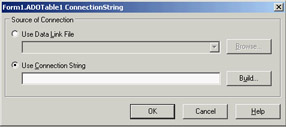
Figure 15.1: Delphi's connection string editor
This editor adds little value to the process of entering a connection string, so you can click Build to go straight to Microsoft's connection string editor, shown in Figure 15.2.
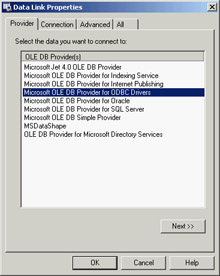
Figure 15.2: The first page of Microsoft's connec-tion string editor
This is a tool you need to understand. The first tab shows the OLE DB providers and service providers installed on your computer. The list will vary according to the version of MDAC and other software you have installed. In this example, select the Jet 4.0 OLE DB provider. Double-click Jet 4.0 OLE DB Provider, and you will be presented with the Connection tab. This page varies according to the provider you select; for Jet, it asks you for the name of the database and your login details. You can choose an Access MDB file installed by Borland with Delphi 7: the dbdemos.mdb file available in the shared data folder (by default, C:Program FilesCommon FilesBorland SharedDatadbdemos.mdb). Click the Test Connection button to test the validity of your selections.
The Advanced tab handles access control to the database; here you specify exclusive or read-only access to the database. The All tab lists all the parameters in the connection string. The list is specific to the OLE DB provider you selected on the first page. (You should make a mental note of this page, because it contains many parameters that are the answers to many problems.) After closing the Microsoft connection string editor you'll see in the Borland ConnectionString property editor the value that will be returned to the ConnectionString property (here split on multiple lines for readability):
Provider=Microsoft.Jet.OLEDB.4.0; Data Source=C:Program FilesCommon FilesBorland SharedDatadbdemos.mdb; Persist Security Info=False
Connection strings are just strings with many parameters delimited by semicolons. To add, edit, or delete any of these parameter values programmatically, you must write your own routines to find the parameter in the list and amend it appropriately. A simpler approach is to copy the string into a Delphi string list and use its name/value pairs capability: This technique will be demonstrated in the JetText example covered in the section "Text Files through Jet."
Now that you have set the connection string, you can select a table. Drop down the list of tables using the TableName property in the Object Inspector. Select the Customer table. Add a DataSource component and a DBGrid control and connect them all together; you are now using ADO in an actual—though trivial—program (available in the source code as FirstAdoExample). To see the data, set the Active property of the dataset to True or open the dataset in the FormCreate event (as in the example) to avoid design-time errors if the database is not available.
| Tip |
If you are going to use dbGo as your primary database access technology, you might want to move the DataSource component to the ADO page of the Component Palette to avoid moving back and forth between the ADO page and the Data Access page. If you use both ADO and another database technology, then you can simulate installing DataSource on multiple pages by creating a Component Template for a DataSource and installing it on the ADO page. |
The ADOConnection Component
When you use an ADOTable component this way, it creates its own connection component behind the scenes. You do not have to accept the default connection it creates. In general, you should create your own connection using the ADOConnection component, which has the same purpose as the dbExpress SQLConnection component and the BDE Database component. It allows you to customize the login procedure, control transactions, execute action commands directly, and reduce the number of connections in an application.
Using an ADOConnection is easy. Place one on a form and set its ConnectionString property the same way you would for the ADOTable. Alternatively, you can double-click an ADOConnection component (or use a specific item of its Component Editor, in its shortcut menu) to invoke the connection string editor directly. With the ConnectionString set to the proper database, you can disable the login dialog box by setting LoginPrompt to False. To use the new connection in the previous example, set the Connection property of ADOTable1 to ADOConnection1. You will see ADOTable1's ConnectionString property reset because the Connection and ConnectionString properties are mutually exclusive. One of the benefits of using an ADOConnection is that the connection string is centralized instead of scattered throughout many components. Another, more important, benefit is that all the components that share the ADOConnection share a single connection to the database server. Without your own ADOConnection, each ADO dataset has a separate connection.
Data Link Files
So, an ADOConnection allows you to centralize the definition of a connection string within a form or data module. However, even though this is a worthwhile step forward from scattering the same connection string throughout all ADO datasets, it still suffers from a fundamental flaw: If you use a database engine that defines the database in terms of a filename, then the path to the database file(s) is hard-coded in the EXE. This makes for a fragile application. To overcome this problem, ADO uses Data Link files.
A Data Link file is a connection string in an INI file. For example, Delphi's installation adds to the system the dbdemos.udl file, with the following text:
[oledb] ; Everything after this line is an OLE DB initstring Provider=Microsoft.Jet.OLEDB.4.0; Data Source=C:Program FilesCommon FilesBorland SharedDatadbdemos.mdb
Although you can give a Data Link file any extension, the recommended extension is .UDL. You can create a Data Link using any text editor, or you can right-click in Windows Explorer, select New, select Text Document, rename the file with a .UDL extension (assuming extensions are displayed in your configuration of Explorer), and then double-click the file to invoke the Microsoft connection string editor.
When you select a file in the Connection editor, the ConnectionString property will be set to 'FILE NAME =' followed by the actual filename, as demonstrated by the DataLinkFile example. You can place your Data Link files anywhere on the hard disk, but if you are looking for a common, shared location, then you can use the DataLinkDir function in the ADODB Delphi unit. If you haven't altered MDAC's defaults, DataLinkDir will return the following:
C:Program FilesCommon FilesSystemOLE DBData Links
Dynamic Properties
Imagine that you are responsible for designing a new database middleware architecture. You have to reconcile two opposing goals of a single API for all databases and access to database-specific features. You could take the approach of designing an interface that is the sum of all the features of every database ever created. Each class would have every property and method imaginable, but it would only use the properties and methods it had support for. It doesn't take much discussion to realize that this isn't a good solution. ADO has to solve these apparently mutually exclusive goals, and it does so using dynamic properties.
Almost all ADO interfaces and their corresponding dbGo components have a property called Properties that is a collection of database-specific properties. These properties can be accessed by their ordinal position, like this:
ShowMessage(ADOTable1.Properties[1].Value);
But they are more usually accessed by name:
ShowMessage(ADOConnection1.Properties['DBMS Name'].Value);
Dynamic properties depend on the type of object and also on the OLE DB providers. To give you an idea of their importance, a typical ADO Connection or Recordset has approximately 100 dynamic properties. As you will see throughout this chapter, the answers to many ADO questions lie in dynamic properties.
| Tip |
An important event related to the use of dynamic properties is OnRecordsetCreate, which was introduced in a Delphi 6 update and is available in Delphi 7. OnRecordsetCreate is called immediately after the recordset has been created, but before it is opened. This event is useful when you're setting dynamic properties that can be set only when the recordset is closed. |
Getting Schema Information
In ADO, you can retrieve schema information using the ADOConnection component's OpenSchema method. This method accepts four parameters:
- The kind of data OpenSchema should return. It is a TSchemaInfo value: a set of 40 values including those for retrieving a list of tables, indexes, columns, views, and stored procedures.
- A filter to place on the data before it is returned. You will see an example of this parameter in a moment.
- A GUID for a provider-specific query. This parameter is used only if the first parameter is siProviderSpecific.
- An ADODataSet into which the data is returned. This parameter illustrates a common theme in ADO: Any method that needs to return more than a small amount of data will return its data as a Recordset, or, in Delphi terms, an ADODataSet.
To use OpenSchema, you need an open ADOConnection. The following code (part of the OpenSchema example) retrieves a list of primary keys for every table into an ADODataSet:
ADOConnection1.OpenSchema(siPrimaryKeys, EmptyParam, EmptyParam, ADODataSet1);
Each field in a primary key has a single row in the result set. So, a table with a composite key of two fields has two rows. The two EmptyParam values indicate that these parameters are given empty values and are ignored. The result of this code is shown in Figure 15.3, after resizing the grid with some custom code.
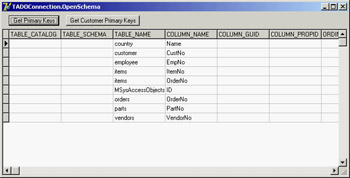
Figure 15.3: The OpenSchema example retrieves the primary keys of the database tables.
When EmptyParam is passed as the second parameter, the result set includes all information of the requested type for the entire database. For many kinds of information, you will want to filter the result set. You can, of course, apply a traditional Delphi filter to the result set using the Filter and Filtered properties or the OnFilterRecord event. However, doing so applies the filter on the client side in this example. Using the second parameter, you can apply a more efficient filter at the source of the schema information. The filter is specified as an array of values. Each element of the array has a specific meaning relevant to the kind of data being returned. For example, the filter array for primary keys has three elements: the catalog (catalog is ANSI-speak for the database), the schema, and the table name. This example returns a list of primary keys for the Customer table:
var Filter: OLEVariant; begin Filter := VarArrayCreate([0, 2], varVariant); Filter[2] := 'CUSTOMER'; ADOConnection1.OpenSchema( siPrimaryKeys, Filter, EmptyParam, ADODataSet1); end;
| Note |
You can retrieve the same information using ADOX, and this warrants a brief comparison between OpenSchema and ADOX. ADOX is an additional ADO technology that allows you to retrieve and update schema information. It is ADO's equivalent to SQL's Data Definition Language (DDL—CREATE, ALTER, DROP) and Data Control Language (DCL—GRANT, REVOKE). ADOX is not directly supported in dbGo, but you can import the ADOX type library and use it successfully in Delphi applications. Unfortunately, ADOX is not as universally implemented as OpenSchema so there are greater gaps. To just retrieve information and not update it, OpenSchema is usually a better choice. |
Using the Jet Engine
Now that you have some of the MDAC and ADO basics under your belt, let's take a moment out to look at the Jet engine. This engine is of great interest to some and of no interest to others. If you're interested in Access, Paradox, dBase, text, Excel, Lotus 1-2-3, or HTML, then this section is for you. If you have no interest in any of these formats, you can safely skip this section.
The Jet database engine is usually associated with Microsoft Access databases, and this is its forte. However, the Jet engine is also an all-purpose desktop database engine, and this lesser-known attribute is where much of its strength lies. Because using the Jet engine with Access is its default mode and is straightforward, this section mostly covers use of non-Access formats, which are not so obvious.
| Note |
The Jet engine has been included in some (but not all) versions of MDAC. It is not included in version 2.6. There has been a long debate about whether programmers using a non-Microsoft development tool have the right to distribute the Jet engine. The official answer is positive, and the Jet engine is available as a free download (in addition to being |
There are two Jet OLE DB providers: the Jet 3.51 OLE DB provider and the Jet 4.0 OLE DB provider. The Jet 3.51 OLE DB provider uses the Jet 3.51 engine and supports Access 97 databases only. If you intend to use Access 97 and not Access 2000, then you will get better performance using this OLE DB provider in most situations than using the Jet 4.0 OLE DB provider.
The Jet 4.0 OLE DB provider supports Access 97, Access 2000, and Installable Indexed Sequential Access Method (IISAM) drivers. Installable ISAM drivers are those written specifically for the Jet engine to support access to ISAM formats such as Paradox, dBase, and text, and it is this facility that makes the Jet engine so useful and versatile. The complete list of ISAM drivers installed on your machine depends on what software you have installed. You can find this list by looking in the Registry at
HKEY_LOCAL_MACHINESoftwareMicrosoftJet4.0ISAM Formats
However, the Jet engine includes drivers for Paradox, dBase, Excel, text, and HTML.
Paradox through Jet
The Jet engine expects to be used with Access databases. To use it with any database other than Access, you need to tell it which IISAM driver to use. This is a painless process that involves setting the Extended Properties connection string argument in the connection string editor. Let's work through a quick example.
Add an ADOTable component to a form and invoke the connection string editor. Select the Jet 4.0 OLE DB Provider. Select the All page, locate the Extended Properties property, and double-click it to edit its value.
Enter Paradox 7.x in the Property Value, as illustrated in Figure 15.4, and click OK. Now go back to the Connection tab and enter the name of the directory containing the Paradox tables directly, because the Browse button won't help you (it lets you enter a filename, not a folder name). At this point you can select a table in the ADOTable's TableName and open it either at design time or at run time. You are now using Paradox through ADO, as demonstrated by the JetParadox example.
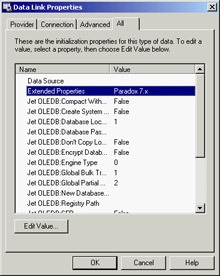
Figure 15.4: Setting extended properties
I have some bad news for Paradox users: Under certain circumstances, you will need to install the BDE in addition to the Jet engine. Jet 4.0 requires the BDE in order to be able to update Paradox tables, but it doesn't require the BDE just to read them. The same is true for most releases of the Paradox ODBC Driver. Microsoft has received justified criticism about this point and has made a new Paradox IISAM available that does not require the BDE; you can get these updated drivers from Microsoft Technical Support.
| Note |
As you learn more about ADO, you will discover how much it depends on the OLE DB provider and the RDBMS (relational database management system) in question. Although you can use ADO with a local file format, as demonstrated in this and following examples, the general suggestion is to install a local SQL engine whenever possible. Access and MSDE are good choices if you have to use ADO; otherwise you might want to consider InterBase or Firebird as alternatives, as discussed in Chapter 14. |
Excel through Jet
Excel is easily accessed using the Jet OLE DB provider. Once again, you set the Extended Properties property to Excel 8.0. Assume that you have an Excel spreadsheet called ABCCompany.xls with a sheet called Employees, and you want to open and read this file using Delphi. With a little knowledge of COM, you can do so by automating Excel. However, the ADO solution is considerably easier to implement and doesn't require Excel to be available on the computer.
| Tip |
You can also read an Excel file using the XLSReadWrite component (available from www.axolot.com). It doesn't require Excel to be available on the computer or the time to start it (like OLE Automation techniques do). |
Ensure that your spreadsheet is not open in Excel, because ADO requires exclusive access to the file. Add an ADODataSet component to a form. Set its ConnectionString to use the Jet 4.0 OLE DB provider and set Extended Properties to Excel 8.0. In the Connection tab, set the database name to the full file and path specification of the Excel spreadsheet (or use a relative path if you plan to deploy the file along with the program).
The ADODataSet component works by opening or executing a value in its CommandText property. This value might be the name of a table, a SQL statement, a stored procedure, or the name of a file. You specify how this value is interpreted by setting the CommandType property. Set CommandType to cmdTableDirect to indicate that the value in CommandText is the name of a table and that all columns should be returned from this table. Select CommandText in the Object Inspector, and you will see a drop-down arrow. Drop down the arrow and a single pseudo-table will be displayed: Employees$. (Excel workbooks are suffixed with a $.)
Add a DataSource and a DBGrid and connect them altogether, and you'll obtain the output of the JetExcel example, shown in Figure 15.5 at design time. By default it would be a little difficult to view the data in the grid, because each column has a width of 255 characters. You can change the field display size either by adding columns to the grid and changing their Width properties or by adding persistent fields and changing their Size or DisplayWidth properties.
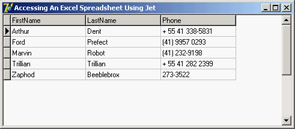
Figure 15.5: ABCCompany.xls in Delphi—a small tribute to Douglas Adams
Notice that you cannot keep the dataset open at design time and run the program, because the Excel IISAM driver opens the XLS file is in exclusive mode. Close the dataset and add to the program a line of code to open it at startup. When you run the program, you will notice another limitation of this IISAM driver: You can add new rows and edit existing rows, but you cannot delete rows.
Incidentally, you could have used either an ADOTable or an ADOQuery component, instead of the ADODataSet, but you need to be aware of how ADO treats symbols in things like table names and field names. If you use an ADOTable and drop down the list of tables, you will see the Employees$ table as you expect. Unfortunately, if you attempt to open the table, you will receive an error. The same is true for SELECT * FROM Employees$ in a TADOQuery. The problem lies with the dollar sign in the table name. If you use characters such as dollar signs, dots, or, more importantly, spaces in a table name or field name, then you must enclose the name in square brackets (for example, [Employees$]).
Text Files through Jet
One of the most useful IISAM drivers that comes with the Jet engine is the Text IISAM. This driver allows you to read and update text files of almost any structured format. We will begin with a simple text file and then cover the variations.
Assume you have a text file called NightShift.TXT that contains the following text:
CrewPerson ,HomeTown Neo ,Cincinnati Trinity ,London Morpheus ,Milan
Add an ADOTable component to a form, set its ConnectionString to use the Jet 4.0 OLE DB provider, and set Extended Properties to Text. The Text IISAM provider considers a directory a database, so you need to enter as the database name the directory that contains the NightShift.TXT file. In the Object Inspector and drop down the list of tables in the TableName property. You will notice that the dot in the filename has been converted to a hash, as in NightShift#TXT. Set Active to True, add a DataSource and a DBGrid and connect them altogether, and you will see the contents of the text file in a grid.
| Warning |
If your computer's settings are such that the decimal separator is a comma instead of a period (so that 1,000.00 is displayed as 1.000,00), then you will need to either change your Regional Settings (Start ® Settings ® Control Panel ® Regional Settings ® Numbers) or take advantage of SCHEMA.INI, described shortly. |
The grid indicates that the widths of the columns are 255 characters. You can change these values just as you did in the JetExcel program by adding persistent fields or columns to the grid and then setting the relevant width property. Alternatively, you can define the structure of the text file more specifically using SCHEMA.INI.
In the JetText example, the database folder is determined at run time depending on the folder hosting the program. To modify the connection string at run time, first load it into a string list (after converting the separators) and then use the Values property to change only one of the elements of the connection string. This is the code from the example:
procedure TForm1.FormCreate(Sender: TObject); var sl: TStringList; begin sl := TStringList.Create; sl.Text := StringReplace (ADOTable1.ConnectionString, ';', sLineBreak, [rfReplaceAll]); sl.Values ['Data Source'] := ExtractFilePath (Application.ExeName); ADOTable1.ConnectionString := StringReplace (sl.Text, sLineBreak, ';', [rfReplaceAll]); ADOTable1.Open; sl.Free; end;
Text files come in all shapes and sizes. Often you do not need to worry about the format of a text file because the Text IISAM takes a peek at the first 25 rows to see whether it can determine the format for itself. It uses this information and additional information in the Registry to decide how to interpret the file and how to behave. If you have a file that doesn't match a regular format the Text IISAM can determine, then you can provide this information using a SCHEMA.INI file located in the same directory as the text files to which it refers. This file contains schema information, also called metadata, about any or all of the text files in the same directory. Each text file is given its own section, identified by the name of the text file, such as [NightShift.TXT].
Thereafter you can specify the format of the file; the names, types, and sizes of columns; any special character sets to use; and any special column formats (such as date/time or currency). Let's assume that you change your NightShift.TXT file to the following format:
Neo |Cincinnati Trinity |London Morpheus |Milan
In this example, the column names are not included in the text file, and the delimiter is a vertical bar. An associated SCHEMA.INI file might look something like the following:
[NightShift.TXT] Format=Delimited(|) ColNameHeader=False Col1=CrewPerson Char Width 10 Col2=HomeTown Char Width 30
Regardless of whether you use a SCHEMA.INI file, you will encounter two limitations of the Text IISAM: Rows cannot be deleted, and rows cannot be edited.
Importing and Exporting
The Jet engine is particularly adept at importing and exporting data. The process of exporting data is the same for each export format and consists of executing a SELECT statement with a special syntax. Let's begin with an example of exporting data from the Access version of the DBDemos database back to a Paradox table. You will need an active ADOConnection, called ADOConnection1 in the JetImportExport example, which uses the Jet engine to open the database. The following code exports the Customer table to a Paradox Customer.db file:
SELECT * INTO Customer IN "C: mp" "Paradox 7.x;" FROM CUSTOMER
Let's look at the pieces of this SELECT statement. The INTO clause specifies the new table that will be created by the SELECT statement; this table must not already exist. The IN clause specifies the database to which the new table is added; in Paradox, this is a directory that already exists. The clause immediately following the database is the name of the IISAM driver to be used to perform the export. You must include the trailing semicolon at the end of the driver name. The FROM clause is a regular part of any SELECT statement. In the sample program, the operation is executed through the ADOConnection component and uses the program's folder instead of a fixed one:
ADOConnection1.Execute ('SELECT * INTO Customer IN "' +
CurrentFolder + '" "Paradox 7.x;" FROM CUSTOMER');
All export statements follow these same basic clauses, although IISAM drivers have differing interpretations of what a database is. Here, you export the same data to Excel:
ADOConnection1.Execute ('SELECT * INTO Customer IN "' +
CurrentFolder + 'dbdemos.xls" "Excel 8.0;" FROM CUSTOMER');
A new Excel file called dbdemos.xls is created in the application's current directory. A workbook called Customer is added, containing all the data from the Customer table in dbdemos.mdb.
This last example exports the same data to an HTML file:
ADOConnection1.Execute ('SELECT * INTO [Customer.htm] IN "' +
CurrentFolder + '" "HTML Export;" FROM CUSTOMER');
In this case, the database is the directory, as it was for Paradox but not for Excel. The table name must include the .htm extension and, therefore, it must be enclosed in square brackets. Notice that the name of the IISAM driver is HTML Export, not just HTML, because this driver can only be used for exporting to HTML.
The last IISAM driver we'll look at in this investigation of the Jet engine is the partner to HTML Export: HTML Import. Add an ADOTable to a form, set its ConnectionString to use the Jet 4.0 OLE DB provider, and set Extended Properties to HTML Import. Set the database name to the name of the HTML file created by the export a few moments ago—that is, Customer.htm. Now set the TableName property to Customer. Open the table—you have just imported the HTML file. Bear in mind, though, that if you attempt to update the data, you'll receive an error because this driver is intended for import only. Finally, if you create your own HTML files containing tables and want to open these tables using this driver, then remember that the name of the table is the value of the caption tag of the HTML table.
Working with Cursors
Two properties of ADO datasets have a fundamental impact on your application and are inextricably linked with each other: CursorLocation and CursorType. If you want to understand your ADO dataset behavior, you must understand these two properties.
Cursor Location
The CursorLocation property allows you to specify what is in control of the retrieval and update of your data. You have two choices: client (clUseClient) or server (clUseServer). Your choice affects your dataset's functionality, performance, and scalability.
A client cursor is managed by the ADO Cursor Engine. This engine is an excellent example of an OLE DB service provider: It provides a service to other OLE DB providers. The ADO Cursor Engine manages the data from the client side of the application. All data in the result set is retrieved from the server to the client when the dataset is opened. Thereafter, the data is held in memory, and updates and manipulation are managed by the ADO Cursor Engine. This is similar to using the ClientDataSet component in a dbExpress application. One benefit is that manipulation of the data, after the initial retrieval, is considerably faster. Furthermore, because the manipulation is performed in memory, the ADO Cursor Engine is more versatile than most server-side cursors and offers extra facilities. I'll examine these benefits later, as well as other technologies that depend on client-side cursors (such as disconnected and persistent recordsets).
A server-side cursor is managed by the RDBMS. In a client/server architecture based on a database such as SQL Server, Oracle, or InterBase, this means the cursor is managed physically on the server. In a desktop database such as Access or Paradox, the "server" location is a logical location, because the database is running on the desktop. Server-side cursors are often faster to load than client-side cursors because not all the data is transferred to the client when the dataset is opened. This behavior also makes them more suitable for very large result sets where the client has insufficient memory to hold the entire result set in memory. Often you can determine what kinds of features will be available to you with each cursor location by thinking through how the cursor works. Locking is a good example of how features determine the cursor type; I will discuss locking in more detail later. (To place a lock on a record requires a server-side cursor, because there must be a conversation between the application and the RDBMS.)
Another issue that will affect your choice of cursor location is scalability. Server-side cursors are managed by the RDBMS; in a client/server database, this will be located on the server. As more users use your application, the load on the server increases with each server-side cursor. A greater workload on the server means that the RDBMS becomes a bottleneck more quickly, so the application is less scalable. You can achieve better scalability by using client-side cursors. The initial hit on opening the cursor is often heavier, because all the data is transferred to the client, but the maintenance of the open cursor can be lower. As you can see, many conflicting issues are involved in choosing the correct cursor location for your datasets.
Cursor Type
Your choice of cursor location directly affects your choice of cursor type. To all intents and purposes there are four cursor types, but one value is unused: a cursor type that means unspecified. Many values in ADO signify an unspecified value, and I will cover them all here and explain why you won't have much to do with them. They exist in Delphi because they exist in ADO. ADO was primarily designed for Visual Basic and C programmers. In these languages, you use objects directly without the assistance dbGo provides. As such, you can create and open recordsets, as they are called in ADO-speak, without having to specify every value for every property. The properties for which a value has not been specified have an unspecified value. However, in dbGo you use components. These components have constructors, and these constructors initialize the properties of the components. So, from the moment you create a dbGo component, it will usually have a value for every property. As a consequence, you have little need for the unspecified values in many enumerated types.
Cursor types affect how your data is read and updated. As I mentioned, there are four choices: forward-only, static, keyset, and dynamic. Before we get too involved in all the permutations of cursor locations and cursor types, you should be aware that there is only one cursor type available for client-side cursors: the static cursor. All other cursor types are available only to server-side cursors. I'll return to the subject of cursor type availability after we have looked at the various cursor types, in increasing order of expense:
Forward-Only Cursor The forward-only cursor is the least expensive cursor type, and therefore the type with the best performance. As the name implies, the forward-only cursor lets you navigate forward. The cursor reads the number of records specified by CacheSize (default of 1); each time it runs out of records, it reads another CacheSize set. Any attempt to navigate backward through the result set beyond the number of records in the cache results in an error. This behavior is similar to that of a dbExpress dataset. A forward-only cursor is not suitable for use in the user interface where the user can control the direction through the result set. However, it is eminently suitable for batch operations, reports and stateless Web applications, because these situations start at the top of the result set and work progressively toward the end, and then the result set is closed.
Static Cursor A static cursor works by reading the complete result set and providing a window of CacheSize records into the result set. Because the complete result set has been retrieved by the server, you can navigate both forward and backward through the result set. However, in exchange for this facility, the data is static—updates, insertions, and deletions made by other users cannot be seen, because the cursor's data has already been read.
Keyset Cursor A keyset cursor is best understood by breaking keyset into the two words key and set. Key, in this context, refers to an identifier for each row. Often this will be a primary key. A keyset cursor, therefore, is a set of keys. When the result set is opened, the complete list of keys for the result set is read. If, for example, the dataset was a query like SELECT * FROM CUSTOMER, then the list of keys would be built from SELECT CUSTID FROM CUSTOMER. This set of keys is held until the cursor is closed. When the application requests data, the OLE DB provider reads the rows using the keys in the set of keys. Consequently, the data is always up to date. If another user changes a row in the result set, then the changes will be seen when the data is reread. However, the set of keys is static; it is read only when the result set is first opened. If another user adds new records, these additions will not be seen. Deleted records become inaccessible, and changes to primary keys (you don't let your users change primary keys, do you?) are also inaccessible.
Dynamic Cursor The most expensive cursor type, a dynamic cursor is almost identical to a keyset cursor. The sole difference is that the set of keys is reread when the application requests data that is not in the cache. Because the default for ADODataSet.CacheSize is 1, such requests occur frequently. You can imagine the additional load this behavior places on the DBMS and the network, and why this is the most expensive cursor. However, the result set can see and respond to additions and deletions made by other users.
Ask and Ye Shall Not Receive
Now that you know about cursor locations and cursor types, a word of warning: Not all combinations of cursor location and cursor type are possible. Usually, this limitation is imposed by the RDBMS and/or the OLE DB provider as a result of the functionality and architecture of the database. For example, client cursors always force the cursor type to static. You can see behavior this for yourself. Add an ADODataSet component to a form, set its ConnectionString to any database, and set the ClientLocation property to clUseCursor and the CursorType property to ctDynamic. Now set Active to True and keep your eye on the CursorType; it changes to ctStatic. You learn an important lesson from this example: What you ask for is not necessarily what you get. Always check your properties after opening a dataset to see the actual effect of your requests.
Each OLE DB provider will make different changes according to different requests and circumstances, but here are a few examples to give you an idea of what to expect:
- The Jet 4.0 OLE DB provider changes most cursor types to keyset.
- The SQL Server OLE DB provider often changes keyset and static to dynamic.
- The Oracle OLE DB provider changes all cursor types to forward-only.
- The ODBC OLE DB provider makes various changes according to the ODBC driver in use.
No Record Count
ADO datasets sometimes return –1 for their RecordCount. A forward-only cursor cannot know how many records are in the result set until it reaches the end, so it returns –1 for the RecordCount. A static cursor always knows how many records are in the result set, because it reads the entire set when it is opened, so it returns the number of records in its result set. A keyset cursor also knows how many records are in the result set, because it has to retrieve a fixed set of keys when the result set is opened, so it also returns a useful value for RecordCount. A dynamic cursor does not reliably know how many records are in the result set, because it is regularly rereading the set of keys, so it returns –1. You can avoid using RecordCount altogether and execute SELECT COUNT(*) FROM tablename, but the result will be an accurate reflection of the number of records in the database table—which is not necessarily the same as the number of records in the dataset.
Client Indexes
One of the many benefits of client-side cursors is the ability to create local, or client, indexes. Assuming you have an ADO client-side dataset for the DBDemos Customer table, which has a grid attached to it, set the dataset's IndexFieldNames property to CompanyName. The grid will immediately show that the data is in CompanyName order. There is an important point here: In order to index the data, ADO did not have to reread the data from its source. The index was created from the data in memory. So, not only is the index created as quickly as possible, but the network and the DBMS are not overloaded by transferring the same data over and over in different orders.
The IndexFieldNames property has more potential. Set it to Country;CompanyName and you will see the data ordered first by country and then, within country, by company name. Now set IndexFieldNames to CompanyName DESC. Be sure to write DESC in capitals (and not desc or Desc). The data is now sorted in descending order.
This simple but powerful feature allows you to solve one of the great bugbears of database developers. Users ask the inevitable, and quite reasonable, question, "Can I click the columns of the grid to sort my data?" Answers like replacing grids with non–data-aware controls such as ListView that have the sorting built into the control or like trapping the DBGrid's OnTitleClick event and reissuing the SQL SELECT statement after including an appropriate ORDER BY clause are far from satisfactory.
If you have the data cached on the client side (as you've also seen in the use of the ClientDataSet component), you can use a client index computed in memory. Add the following OnTitleClick event to the grid (the code is available in the ClientIndexes example):
procedure TForm1.DBGrid1TitleClick(Column: TColumn); begin if ADODataSet1.IndexFieldNames = Column.Field.FieldName then ADODataSet1.IndexFieldNames := Column.Field.FieldName + ' DESC' else ADODataSet1.IndexFieldNames := Column.Field.FieldName end;
This simple event checks to see whether the current index is built on the same field as the column. If it is, then a new index is built on the column, but in descending order. If not, then a new index is built on the column. When the user clicks the column for the first time, it is sorted in ascending order; when it is clicked for the second time, it is sorted in descending order. You could extend this functionality to allow the user to Ctrl+click several column titles to build up more complicated indexes.
| Note |
All of this can be achieved using ClientDataSet, but that solution is not as elegant because ClientDataSet does not support the DESC keyword so you have to create an index collection item to obtain a descending index, something that requires more code. Moreover when changing an ascending index to a descending version, the ClientDataSet will rebuild the index, performing an unnecessary and possibly slow operation. |
Cloning
ADO is crammed with features. You can argue that feature-rich can translate into footprint-rich, but it also translates into more powerful and reliable applications. One such powerful feature is cloning. A cloned recordset is a new recordset that has all the same properties as the original from which it is cloned. First I'll explain how you can create and use a clone, and then I'll explain why clones are so useful.
| Note |
The ClientDataSet also supports cloning; this feature was not discussed in Chapter 13, "Delphi's Database Architecture." |
You can clone a recordset (or, in dbGo-speak, a dataset) using the Clone method. You can clone any ADO dataset, but you will use ADOTable in this example. The DataClone example (see Figure 15.6) uses two ADOTable components, one hooked to database data and the other empty. Both datasets are hooked to a DataSource and grid. A single line of code, executed when the user clicks a button, clones the dataset:
ADOTable2.Clone(ADOTable1);
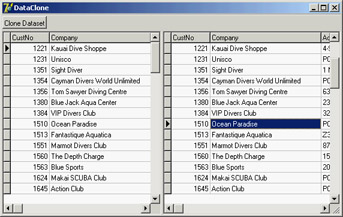
Figure 15.6: The form of the DataClone example, with two copies of a dataset (the original and a clone)
This line clones ADOTable1 and assigns the clone to ADOTable2. In the program, you'll see a second view of the data. The two datasets have their own record pointers and other status information, so the clone does not interfere with its original copy. This behavior makes clones ideal for operating on a dataset without affecting the original data. Another interesting feature is that you can have multiple different active records, one for each of the clones— functionality you cannot achieve in Delphi with a single dataset.
| Tip |
A recordset must support bookmarks in order to be cloned, so forward-only and dynamic cursors cannot be cloned. You can determine whether a recordset supports bookmarks using the Supports method (for example, ADOTable1 .Supports([coBookMark])). One of the useful side effects of clones is that the bookmarks created by one clone are usable by all other clones. |
Transaction Processing
As we saw in section "Using Transactions" of Chapter 14, transaction processing allows developers to group individual updates to a database into a single logical unit of work.
ADO's transaction processing support is controlled with the ADOConnection component, using the BeginTrans, CommitTrans, and RollbackTrans methods, which have effects similar to those of the corresponding dbExpress and BDE methods. To investigate ADO transaction processing support, you will build a test program called TransProcessing. The program has an ADOConnection component with the ConnectionString set to the Jet 4.0 OLE DB provider and the dbdemos.mdb file. It has an ADOTable component hooked to the Customer table and a DataSource and DBGrid for displaying the data. Finally, it has three buttons to execute the following commands:
ADOConnection1.BeginTrans; ADOConnection1.CommitTrans; ADOConnection1.RollbackTrans;
With this program, you can make changes to the database table and then roll them back, and they will be rolled back as expected. I emphasize this point because transaction support varies depending on the database and on the OLE DB provider you are using. For example, if you connect to Paradox using the ODBC OLE DB provider, you will receive an error indicating that the database or the OLE DB provider is not capable of beginning a transaction. You can find out the level of transaction processing support you have using the Transaction DDL dynamic property of the connection:
if ADOConnection1.Properties['Transaction DDL'].Value > DBPROPVAL_TC_NONE then ADOConnection1.BeginTrans;
If you are trying to access the same Paradox data using the Jet 4.0 OLE DB provider, you won't receive an error but you also won't be able to roll back your changes, due to limitations of the OLE DB provider.
Another strange difference becomes evident when you're working with Access: If you use the ODBC OLD DB provider, you'll be able to use transactions—but not nested transactions. Opening a transaction when another is active will result in an error. Using the Jet engine, however, Access supports nested transactions.
Nested Transactions
Using the TransProcessing program, you can try this test:
- Begin a transaction.
- Change the ContactName of the Around The Horn record from Thomas Hardy to Dick Solomon.
- Begin a nested transaction.
- Change the ContactName of the Bottom-Dollar Markets record from Elizabeth Lincoln to Sally Solomon.
- Roll back the inner transaction.
- Commit the outermost transaction.
The net effect is that only the change to the Around The Horn record is permanent. If, however, the inner transaction had been committed and the outer transaction rolled back, then the net effect would have been that none of the changes were permanent (even the changes in the inner transaction). This is as you would expect, with the only limit being that Access supports five levels of nested transactions.
ODBC does not support nested transactions, the Jet OLE DB provider supports up to five levels of nested transactions, and the SQL Server OLE DB provider doesn't support nesting at all. You might get a different result depending on the version of SQL server or the driver, but the documentation and my experiments with the servers seem to indicate that this is the case. Apparently only the outermost transaction decides whether all the work is committed or rolled back.
ADOConnection Attributes
There is another issue you should consider if you intend to use nested transactions. The ADOConnection component has an Attributes property that determines how the connection should behave when a transaction is committed or rolled back. It is a set of TXActAttributes that, by default, is empty. TXActAttributes contains only two values: xaCommitRetaining and xaAbortRetaining (this value is often mistakenly written as xaRollbackRetaining—a more logical name for it). When xaCommitRetaining is included in Attributes and a transaction is committed, a new transaction is automatically started. When xaAbortRetaining is included in Attributes and a transaction is rolled back, a new transaction is automatically started. Thus if you include these values in Attributes, a transaction will always be in progress, because when you end one transaction another will always be started.
Most programmers prefer to be in greater control of their transactions and not to allow them to be automatically started, so these values are not commonly used. However, they have a special relevance to nested transactions. If you nest a transaction and set Attributes to [xaCommitRetaining, xaAbortRetaining], then the outermost transaction can never be ended. Consider this sequence of events:
- An outer transaction is started.
- An inner transaction is started.
- The inner transaction is committed or rolled back.
- A new inner transaction is automatically started as a consequence of the Attributes property.
The outermost transaction can never be ended, because a new inner transaction will be started when one ends. The conclusion is that the use of the Attributes property and the use of nested transactions should be considered mutually exclusive.
Lock Types
ADO supports four different approaches to locking your data for update: ltReadOnly, ltPessimistic, ltOptimistic, and ltBatchOptimistic (there is also an ltUnspecified option, but for the reasons mentioned earlier, we will ignore unspecified values). The four approaches are made available through the dataset's LockType property. In this section I will provide an overview of the four approaches, and in subsequent sections we will take a closer look at them.
The ltReadOnly value specifies that data is read-only and cannot be updated. As such, there is effectively no locking control required, because the data cannot be updated.
The ltPessimistic and ltOptimistic values offer the same pessimistic and optimistic locking control as the BDE. One important benefit that ADO offers over the BDE in this respect is that the choice of locking control remains yours. If you use the BDE, the decision to use pessimistic or optimistic locking is made for you by your BDE driver. If you use a desktop database such as dBase or Paradox, then the BDE driver uses pessimistic locking; if you use a client/server database such as InterBase, SQL Server, or Oracle, the BDE driver uses optimistic locking.
Pessimistic Locking
The words pessimistic and optimistic in this context refer to the developer's expectation of conflict between user updates. Pessimistic locking assumes that there is a high probability that users will attempt to update the same records at the same time and that a conflict is likely. In order to prevent such a conflict, the record is locked when the edit begins. The record lock is maintained until the update is completed or cancelled. A second user who attempts to edit the same record at the same time will fail in their attempt to place their record lock and will receive a "Could not update; currently locked" exception.
This approach to locking will be familiar to developers who have worked with desktop databases such as dBase and Paradox. The benefit is that the user knows that if they can begin editing a record, then they will succeed in saving their update. The disadvantage of pessimistic locking is that the user is in control of when the lock is placed and when it is removed. If the user is skilled with the application, then this lock could be as short as a couple of seconds. However, in database terms, a couple of seconds is an eternity. On the other hand, the user might begin an edit and go to lunch, and the record would be locked until the user returns. As a consequence, most proponents of pessimistic locking guard against this eventuality by using a Timer or other such device to time out locks after a certain amount of keyboard and mouse inactivity.
Another problem with pessimistic locking is that it requires a server-side cursor. Earlier we looked at cursor locations and saw that they have an impact on the availability of the different cursor types. Now you can see that cursor locations also have an impact on locking types. Later in this chapter, we will discuss more benefits of client-side cursors; if you choose to take advantage of these benefits, then you'll be unable to use pessimistic locking.
Pessimistic locking is an area of dbGo that changed in Delphi 6 (compared to Delphi 5). This section describes the way pessimistic locking works in versions 6 and 7. To highlight how it works, I've built the PessimisticLocking example. It is similar to other examples in this chapter, but the CursorLocation property is set to clUseServer and the LockType property is set to ltPessimistic. To use it, run two copies from Windows Explorer and attempt to edit the same record in both running instances of the program: You will fail because the record is locked by another user.
Updating the Data
One of the reasons people use the ClientDataSet component (or turn to cached updates in the BDE) is to make a SQL join updatable. Consider the following SQL equi-join:
SELECT * FROM Orders, Customer WHERE Customer.CustNo=Orders.CustNo
This statement provides a list of orders and the customers that placed those orders. The BDE considers any SQL join to be read-only because inserting, updating, and deleting rows in a join is ambiguous. For example, should the insert of a row into the previous join result in a new product and also a new supplier, or just a new product? The ClientDataSet/Provider architecture allows you to specify a primary update table (and advanced features actually not covered in the book) and also customize the updates' SQL, as we partially saw in Chapter 14 and we'll further explore in Chapter 16, "Multitier DataSnap Applications."
ADO supports an equivalent to cached updates called batch updates, which are similar to the BDE approach. In the next section we will take a closer look at ADO's batch updates, what they can offer you, and why they are so important. However, in this section you won't need them to solve the problem of updating a join, because in ADO, joins are naturally updatable.
For example, the JoinData example is built around an ADODataset component that uses the previous SQL join. If you run it, you can edit one of the fields and save the changes (by moving off the record). No error occurs, because the update has been applied successfully. ADO, compared to the BDE, has taken a more practical approach to the problem. In an ADO join, each field object knows which underlying table it belongs to. If you update a field in the Products table and post the change, then a SQL UPDATE statement is generated to update the field in the Products table. If you change a field in the Products table and a field in the Suppliers table, then two SQL UPDATE statements are generated, one for each table.
The insertion of a row into a join follows a similar behavior. If you insert a row and enter values for the Products table only, then a SQL INSERT statement is generated for the Products table. If you enter values for both tables, two SQL INSERT statements are generated, one for each table. The order in which the statements are executed is important, because the new product might relate to the new supplier, so the new supplier is inserted first.
The biggest problem with the ADO solution can be seen when a row in a join is deleted. The deletion attempt will appear to fail. The exact message you see depends on the version of ADO you are using and the database, but it will be along the lines that you cannot delete the row because other records relate to it. The error message can be confusing. In the current scenario, the error message implies that a product cannot be deleted because there are records that relate to the product, but the error occurs whether the product has any related records or not. The explanation can be found by following the same logic for deletions as for insertions. Two SQL DELETE statements are generated: one for the Suppliers table and then another for the Products table. Contrary to appearances, the DELETE statement for the Products table succeeds. It is the DELETE statement for the Suppliers table that fails, because the supplier cannot be deleted while it still has dependent records.
| Tip |
If you are curious about the SQL statements that are generated, and you use SQL Server, you can see these statements using SQL Server Profiler. |
Even if you understand how this process works, it's helpful to look at this problem through the users' eyes. From their point of view, when users delete a row in the grid, I would wager that 99 percent of them intend to delete just the product—not both the product and the supplier. Fortunately, you can achieve this result using another dynamic property—in this case, the Unique Table dynamic property. You can specify that deletes refer to just the Products table and not to Suppliers using the following line of code:
ADOQuery1.Properties['Unique Table'].Value := 'Products';
This value cannot be assigned at design time, so the next best alternative is to place this line in the form's OnCreate event.
Batch Updates
When you use batch updates, any changes you make to your records can be made in memory; later, the entire "batch" of changes can be submitted as one operation. This approach offers some performance benefits, but there are more practical reasons why this technology is a necessity: The user might not be connected to the database at the time they make their updates. This would be the case in a briefcase application (which we will return to in the section "The Briefcase Model"), but it can also be the case in web applications that use another ADO technology, Remote Data Services (RDS).
You can enable batch updates in any ADO dataset by setting LockType to ltBatchOptimistic before the dataset is opened. In addition, you will need to set the CursorLocation to clUseClient, because batch updates are managed by ADO's cursor engine. Hereafter, changes are all made to a delta (a list of changes). The dataset looks to all intents and purposes as if the data has changed, but the changes have only been made in memory; they have not been applied to the database. To make the changes permanent, use UpdateBatch (equivalent to cached updates' ApplyUpdates):
ADODataSet1.UpdateBatch;
To reject the entire batch of updates, use either CancelBatch or CancelUpdates. There are many similarities in method and property names between ADO batch updates, BDE cached updates, and ClientDataSet. UpdateStatus, for example, can be used exactly the same way as for cached updates to identify records according to whether they have been inserted, updated, deleted, or unmodified. This approach is particularly useful for highlighting records in different colors in a grid or showing their status on a status bar. Some differences between the syntaxes are slight, such as changing RevertRecord to CancelBatch(arCurrent); others require more effort.
One useful cached update feature that is not present in ADO batch updates is the dataset's UpdatesPending property. This property is true if changes have been made but not yet applied.
It's particularly useful in a form's OnCloseQuery event:
procedure TForm1.FormCloseQuery(
Sender: TObject; var CanClose: Boolean);
begin
CanClose := True;
if ADODataSet1.UpdatesPending then
CanClose := (MessageDlg('Updates are still pending' #13 +
'Close anyway?', mtConfirmation, [mbYes, mbNo], 0) = mrYes);
end;
However, with a little knowledge and ingenuity you can implement a suitable ADOUpdatesPending function. The necessary knowledge is that ADO datasets have a property called FilterGroup, which is a kind of filter. Unlike a dataset's Filter property, which filters the data based on a comparison of the data against a condition, FilterGroup filters based on the status of the record. One such status is fgPendingRecords, which includes all records that have been modified but not yet applied. So, to allow the user to look through all the changes they have made so far, you need only execute two lines:
ADODataSet1.FilterGroup := fgPendingRecords; ADODataSet1.Filtered := True;
Naturally, the result set will now include the records that have been deleted. The effect you will see is that the fields are left blank, which is not very helpful because you don't know which record has been deleted. (This was not the behavior in the first version of ADOExpress, which displayed the field values of deleted records.)
The ingenuity you need in order to solve the UpdatesPending problem involves clones, discussed earlier. The ADOUpdatesPending function will set the FilterGroup to restrict the dataset to only those changes that have not yet been applied. All you need to do is see whether there are any records in the dataset once the FilterGroup has been applied. If there are, then some updates are pending. However, if you do this with the actual dataset, then the setting of the FilterGroup will move the record pointer, and the user interface will be updated. The best solution is to use a clone:
function ADOUpdatesPending(ADODataSet: TCustomADODataSet): boolean; var Clone: TADODataSet; begin Clone := TADODataSet.Create(nil); try Clone.Clone(ADODataSet); Clone.FilterGroup := fgPendingRecords; Clone.Filtered := True; Result := not (Clone.BOF and Clone.EOF); Clone.Close; finally Clone.Free; end; end;
In this function, you clone the original dataset, set the FilterGroup, and check to see whether the dataset is at both beginning of the file and also the end of the file. If it is, then no records are pending.
Optimistic Locking
Earlier we looked at the LockType property and saw how pessimistic locking works. In this section, we'll look at optimistic locking, not only because it is the preferred locking type for medium- to high-throughput transactions, but also because it is the locking scheme employed by batch updates.
Optimistic locking assumes there is a low probability that users will attempt to update the same records at the same time and that a conflict is unlikely. As such, the attitude is that all users can edit any record at any time, and you deal with the consequences of conflicts between different users' updates to the same records when the changes are saved. Thus, conflicts are considered an exception to the rule. This means there are no controls to prevent two users from editing the same record at the same time. The first user to save their changes will succeed; the second user's attempt to update the same record might fail. This behavior is essential for briefcase applications (discussed later in the chapter) and web applications, where there is no permanent connection to the database and, therefore, no way to implement pessimistic locking. In contrast with pessimistic locking, optimistic locking has the additional considerable benefit that resources are consumed only momentarily; therefore, the average resource usage is much lower, making the database more scalable.
Let's consider an example. Assume you have an ADODataSet connected to the Customer table of the dbdemos.mdb database, with LockType set to ltBatchOptimistic, and the contents are displayed in a grid. Assume that you also have a button to call UpdateBatch. Run the program twice (it is the BatchUpdates example if you don't want to rebuild it) and begin editing a record in the first copy of the program. Although for the sake of simplicity I'll demonstrate a conflict using just a single machine, the scenario and subsequent events are unchanged when using multiple machines:
- Choose the Bottom-Dollar Markets company in Canada and change the name to Bottom-Franc Markets.
- Save the change, move off the record to post it, and click the button to update the batch.
- In the second copy of the program, locate the same record and change the company name to Bottom-Pound Markets.
- Move off the record and click the button to update the batch. It will fail.
As with many ADO error messages, the exact message you receive will depend not only on the version of ADO you are using but also on how closely you followed the example. In ADO 2.6, the error message is "Row cannot be located for updating. Some values may have been changed since it was last read." This is the nature of optimistic locking. The update to the record is performed by executing the following SQL statement:
UPDATE CUSTOMER SET CompanyName="Bottom-Pound Markets" WHERE Customer AND CompanyName="Bottom-Dollar Markets"
The number of records affected by this UPDATE statement is expected to be one, because it locates the original record using the primary key and the contents of the CompanyName field as it was when the record was first read. In this example, however, the number of records affected by the UPDATE statement is zero. This result can occur only if the record has been deleted, the record's primary key has changed, or the field that you are changing was changed by someone else. Hence, the update fails.
If the "second user" had changed the ContactName field and not the CompanyName field, then the UPDATE statement would have looked like this:
UPDATE CUSTOMER SET ContactName="Liz Lincoln" WHERE Customer AND ContactName="Elizabeth Lincoln"
In the example scenario, this statement would have succeeded because the other user didn't change the primary key or the contact name. This behavior is similar to the BDE with the update where changed update mode. The UpdateMode property of the BDE in ADO is replaced by the Update Criteria dynamic property of a dataset. The following list shows the possible values that can be assigned to this dynamic property:
|
Constant |
Locate Records By |
|---|---|
|
adCriteriaKey |
Primary key columns only |
|
adCriteriaAllCols |
All columns |
|
adCriteriaUpdCols |
Primary key columns and changed columns only |
|
adCriteriaTimeStamp |
Primary key columns and a timestamp column only |
Don't fall into the trap of thinking that one of these settings is better than another for your whole application. In practice, your choice of setting will be influenced by the contents of each table. Say that the Customer table has just CustomerID, Name, and City fields. In this case, the update of any one of these fields is logically not mutually exclusive with the update of any of the other fields, so a good choice for this table would be adCriteriaUpdCols (the default). If, however, the Customer table included a PostalCode field, then the update of a PostalCode field would be mutually exclusive with the update of the City field by another user (because if the city changes, then so should the postal code, and possibly vice versa). In this case, you could argue that adCriteriaAllCols would be a safer solution.
Another issue to be aware of is how ADO deals with errors during the update of multiple records. Using the BDE's cached updates and ClientDataSet, you can use the OnUpdateError event to handle each update error as the error occurs and resolve the problem before moving on to the next record. In ADO, you cannot establish such a dialog. You can monitor the progress and success or failure of the updating of the batch using the dataset's OnWillChangeRecord and OnRecordChangeComplete, but you cannot revise the record and resubmit it during this process as you can with the BDE and ClientDataSet. There's more: If an error occurs during the update process, the updating does not stop. It continues to the end, until all updates have been applied or have failed. This process can produce an unhelpful and incorrect error message. If more than one record cannot be updated, or the single record that failed is not the last record to be applied, then the error message in ADO 2.6 is "Multiple-step OLE DB operation generated errors. Check each OLE DB status value, if available. No work was done." The last sentence is the problem; it states that "No work was done," but this is incorrect. It is true that no work was done on the record that failed, but other records were successfully applied, and their updates stand.
Resolving Update Conflicts
As a consequence of the nature of applying updates, the approach that you need to take to update the batch is to update the batch, let the individual records fail, and then deal with the failed records once the process is over. You can determine which records have failed by setting the dataset's FilterGroup to fgConflictingRecords:
ADODataSet1.FilterGroup := fgConflictingRecords; ADODataSet1.Filtered := True;
For each failed record, you can inform the user of three critical pieces of information about each field using the following TField properties:
|
Property |
Description |
|---|---|
|
NewValue |
The value this user changed it to |
|
CurValue |
The new value from the database |
|
OldValue |
The value when first read from the database |
Users of the ClientDataSet component will be aware of the handy ReconcileErrorForm dialog, which wraps up the process of showing the user the old and new records and allows them to specify what action to take. Unfortunately, there is no ADO equivalent to this form, and TReconcileErrorForm has been written with ClientDataSet so much in mind that it is difficult to convert it for use with ADO datasets.
I'll point out one last gotcha about using these TField properties: They are taken straight from the underlying ADO Field objects to which they refer. This means, as is common in ADO, that you are at the mercy of your chosen OLE DB provider to support the features you hope to use. All is well for most providers, but the Jet OLE DB provider returns the same value for CurValue as it does for OldValue. In other words, if you use Jet, you cannot determine the value to which the other user changed the field unless you resort to your own measures. Using the OLEDB provider for SQL Server, however, you can access the CurValue only after calling the Resync method of the dataset with the AffectRecords parameter set to adAffectGroup and ResyncValues set to adResyncUnderlyingValues, as in the following code:
adoCustomers.FilterGroup := fgConflictingRecords; adoCustomers.Filtered := true; adoCustomers.Recordset.Resync(adAffectGroup, adResyncUnderlyingValues);
Disconnected Recordsets
This knowledge of batch updates allows you to take advantage of the next ADO feature: disconnected recordsets. A disconnected recordset is a recordset that has been disconnected from its connection. This feature is impressive because the user cannot tell the difference between a regular recordset and a disconnected one; their feature sets and behavior are almost identical. To disconnect a recordset from its connection, you must set the CursorLocation to clUseClient and the LockType to ltBatchOptimistic. You then tell the dataset that it no longer has a connection:
ADODataSet1.Connection := nil;
Hereafter, the recordset will continue to contain the same data, support the same navigational features, and allow records to be added, edited, and deleted. The only relevant difference is that you cannot update the batch because you need to be connected to the server to update the server. You can reconnect the connection (and use UpdateBatch) as follows:
ADODataSet1.Connection := ADOConnection1;
This feature is also available to the BDE and other database technologies by switching over to ClientDataSets, but the beauty of the ADO solution is that you can build your entire application using dbGo dataset components and be unaware of disconnected recordsets. When you discover this feature and want to take advantage of it, you can continue to use the same components you always used.
You might want to disconnect your recordsets for two reasons:
- To keep the total number of connections lower
- To create a briefcase application
I'll discuss keeping down the number of connections in this section and return to briefcase
applications later.
Most regular client/server business applications open tables and maintain a permanent connection to their database while the table is open. However, there are usually only two reasons to be connected to the database: to retrieve data and to update data. Suppose you change your regular client/server application so that after the table is opened and the data is retrieved, the dataset is disconnected from the connection and the connection is dropped; your user will be none the wiser, and the application will not need to maintain an open database connection. The following code shows the two steps:
ADODataSet1.Connection := nil; ADOConnection1.Connected := False;
The only other point at which a connection is required is when the batch of updates needs to be applied. The update code looks like this:
ADOConnection1.Connected := True; ADODataSet1.Connection := ADOConnection1; try ADODataSet1.UpdateBatch; finally ADODataSet1.Connection := nil; ADOConnection1.Connected := False; end;
If you followed this approach throughout the application, the average number of open connections at any one time would be minimal—the connections would be open only for the brief time they were required. The consequence of this change is scalability; the application can cope with significantly more simultaneous users than an application that maintains an open connection. The downside is that reopening the connection can be a lengthy process on some (but not all) database engines, so the application will be slower to update the batch.
Connection Pooling
All this talk about dropping and reopening connections brings us to the subject of connection pooling. Connection pooling—not to be confused with session pooling—allows connections to a database to be reused once you have finished with them. This process happens automatically; if your OLE DB provider supports it and it is enabled, no action is necessary for you to take advantage of connection pooling.
There is a single reason to pool your connections: performance. The problem with database connections is that it can take time to establish a connection. In a desktop database such as Access, this time is typically brief. However, in a client/server database such as Oracle used on a network, this time could be measured in seconds. It makes sense to promote the reuse of such an expensive (in performance terms) resource.
With ADO connection pooling enabled, ADO Connection objects are placed in a pool when the application "destroys" them. Subsequent attempts to create an ADO connection will automatically search the connection pool for a connection with the same connection string. If a suitable connection is found, it is reused; otherwise, a new connection is created. The connections themselves stay in the pool until they are reused, the application closes, or they time out. By default, connections will time out after 60 seconds, but from MDAC 2.5 onward you can set this time-out period using the HKEY_CLASSES_ROOTCLSID SPTimeout Registry key. The connection pooling process occurs seamlessly, without the intervention or knowledge of the developer. This process is similar to the BDE database pooling under Microsoft Transaction Server (MTS) and COM+, with the important exception that ADO performs its own connection pooling without the aid of MTS or COM+.
By default, connection pooling is enabled on all MDAC OLE DB providers for relational databases (including SQL Server and Oracle), with the notable exception of the Jet OLE DB provider. If you use ODBC, you should choose between ODBC connection pooling and ADO connection pooling, but you should not use both. From MDAC 2.1 on, ADO connection pooling is enabled and ODBC is disabled.
| Note |
Connection pooling does not occur on Windows 95 regardless of the OLE DB provider. |
To be comfortable with connection pooling, you need to see the connections being pooled and timed out. Unfortunately, no adequate ADO connection pool spying tools are available at the time of this writing; but you can use SQL Server's Performance Monitor, which can accurately spy on SQL Server database connections.
You can enable or disable connection pooling either in the Registry or in the connection string. The key in the Registry is OLEDB_SERVICES, which can be found at HKEY_CLASSES_ROOTCLSID. It is a bit mask that allows you to disable several OLE DB services, including connection pooling, transaction enlistment, and the cursor engine. To disable connection pooling using the connection string, include ";OLE DB Services=-2" at the end of the connection string. To enable connection pooling for the Jet OLE DB provider, you can include ";OLE DB Services=-1" at the end of the connection string, which enables all OLE DB services.
Persistent Recordsets
The persistent recordset is a useful feature that contributes to the briefcase model (discussed in the next section). Persistent recordsets allow you to save the contents of any recordset to a local file, which can be loaded later. In addition to aiding with the briefcase model, this feature allows developers to create true single-tier applications—you can deploy a database application without having to deploy a database. This makes for a very small footprint on your client's machine.
You can "persist" your datasets using the SaveToFile method:
ADODataSet1.SaveToFile('Local.ADTG');
This method saves the data and its delta in a file on your hard disk. You can reload this file using the LoadFromFile method, which accepts a single parameter indicating the file to load. The format of the file is Advanced Data Table Gram (ADTG), which is a proprietary Microsoft format. It does, however, have the advantage of being very efficient. If you prefer, you can save the file as XML by passing a second parameter to SaveToFile:
ADODataSet1.SaveToFile('Local.XML', pfXML);
However, ADO does not have a built-in XML parser (as the ClientDataSet does), so it must use the MSXML parser. Your user must either install Internet Explorer 5 or later or download the MSXML parser from the Microsoft website.
If you intend to persist your files locally in XML format, be aware of a few disadvantages:
- Saving and loading XML files is slower than saving and loading ADTG files.
- ADO's XML files (and XML files in general) are significantly larger than their ADTG counterparts (XML files are typically twice as large as their ADTG counterparts).
- ADO's XML format is specific to Microsoft, like most companies' XML implementations. This means the XML generated in ADO is not readable by the ClientDataSet and vice versa. Fortunately this problem can be overcome using Delphi's XMLTransform component, which can be used to translate between different XML structures.
If you intend to use these features solely for single-tier applications and not as part of the briefcase model, then you can use an ADODataSet component and set its CommandType to cmdFile and its CommandText to the name of the file. Doing so will save you the effort of calling LoadFromFile manually. However, you will still have to call SaveToFile. In a briefcase application this approach is too limiting, because the dataset can be used in two different modes.
The Briefcase Model
Using this knowledge of batch updates, disconnected recordsets, and persistent recordsets, you can take advantage of the briefcase model. The idea behind the briefcase model is that your users want to be able to use your application while they are on the road—they want to take the same application they use on their office desktops and use it on their laptops at client sites. Traditionally, the problem with this scenario is that when your users are at client sites, they are not connected to the database server, because the database server is running on the network back at their office. Consequently, there is no data on the laptop (and the data cannot be updated anyway).
This is where your newfound understanding comes in handy. Assume the application has been written; the user has requested a new briefcase enhancement, and you have to retrofit it into your existing application. You need to add a new option for your users to allow them to prepare the briefcase application by executing SaveToFile for every table in the database. The result is a collection of ADTG or XML files that mirror the contents of the database. These files are then copied to the laptop, where a copy of the application has previously been installed.
The application needs to be sensitive to whether it is running locally or connected to the network. You can determine this by attempting to connect to the database and seeing whether the connection fails, by detecting the presence of a local briefcase file, or by creating a flag of your own design. If the application is running in briefcase mode, then it needs to use LoadFromFile for each table instead of setting Connected to True for the ADOConnections and Active to True for the ADO datasets. Thereafter, the briefcase application needs to use SaveToFile instead of UpdateBatch whenever data is saved. When the user returns to the office, they need to follow an update process that loads each table from its local file, connects the dataset to the database, and applies the changes using UpdateBatch.
| Tip |
To see a complete implementation of the briefcase model, refer to the BatchUpdates example mentioned earlier. |
A Word on ADO NET
ADO.NET is part of Microsoft's new .NET architecture—the company's redesign of application development tools to better suit the needs of web development. ADO.NET is a significant evolution of ADO. It looks at the problems of web development and addresses shortcomings of ADO's solution. The problem with ADO's solution is that it is based on COM. For one- and two-tier applications, COM imposes few problems, but in the world of web development, it is unacceptable as a transport mechanism. COM suffers from three primary problems that limit its use in web development: It (mostly) runs only on Windows, the transmission of recordsets from one process requires COM marshalling, and COM calls cannot penetrate corporate firewalls. ADO.NET's solution to all these problems is to use XML.
Some other redesign issues focus on breaking the ADO recordset into separate classes. The resulting classes are adept at solving a single problem instead of multiple problems. For example, the ADO.NET class currently called DataSetReader is similar to a read-only, forward-only, server-side recordset and, as such, is best suited to reading a result set very quickly. A DataTable is most like a disconnected, client-side recordset. A DataRelation shares similarities with the MSDataShape OLE DB provider. You can see that your knowledge of how ADO works is of great benefit in understanding the basic principles of ADO.NET.
What s Next?
This chapter described ActiveX Data Objects (ADO) and dbGo, the set of Delphi components for accessing the ADO interfaces. You've seen how to take advantage of Microsoft Data Access Components (MDAC) and various server engines, and I've described some of the benefits and hurdles you'll encounter in using ADO.
Chapter 16 will take you into the world of Delphi's DataSnap architecture, which is used to develop custom client and server applications in a three-tier environment. You can do this using ADO, but because this is a book about Delphi I prefer to show you the native solution to the problem. After we delve into DataSnap, we will continue examining Delphi's database architecture by covering the development of custom data-aware controls and dataset components.
Part I - Foundations
- Delphi 7 and Its IDE
- The Delphi Programming Language
- The Run-Time Library
- Core Library Classes
- Visual Controls
- Building the User Interface
- Working with Forms
Part II - Delphi Object-Oriented Architectures
- The Architecture of Delphi Applications
- Writing Delphi Components
- Libraries and Packages
- Modeling and OOP Programming (with ModelMaker)
- From COM to COM+
Part III - Delphi Database-Oriented Architectures
- Delphis Database Architecture
- Client/Server with dbExpress
- Working with ADO
- Multitier DataSnap Applications
- Writing Database Components
- Reporting with Rave
Part IV - Delphi, the Internet, and a .NET Preview
- Internet Programming: Sockets and Indy
- Web Programming with WebBroker and WebSnap
- Web Programming with IntraWeb
- Using XML Technologies
- Web Services and SOAP
- The Microsoft .NET Architecture from the Delphi Perspective
- Delphi for .NET Preview: The Language and the RTL
- Appendix A Extra Delphi Tools by the Author
- Appendix B Extra Delphi Tools from Other Sources
- Appendix C Free Companion Books on Delphi
EAN: 2147483647
Pages: 279
