How Clustering Works in Quartz
Each node in a Quartz cluster is a separate Quartz application that is managed independently of the other nodes. This means that you must start and stop each node individually. Unlike clustering in many application servers, the separate Quartz nodes do not communicate with one another or with an administration node. (Future versions of Quartz will be designed so that nodes communicate with one another directly rather than through the database.) Instead, the Quartz applications are made aware of one another through the database tables.
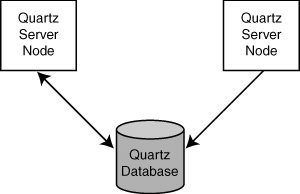
Figure 11.1 shows that each node communicates directly with the database and has no knowledge of others outside the database.
Figure 11.1. Each node in a Quartz cluster is aware of the other instances only via the database.
Quartz Scheduler on Startup in a Cluster
The Quartz Scheduler itself is not cluster-aware, but the JDBC JobStore configured for the Scheduler is. When the Quartz Scheduler is started, it calls the schedulerStarted() method on the JobStore, which, as the name implies, tells the JobStore that the Scheduler has been started. The schedulerStarted() method is implemented in the JobStoreSupport class.
The JobStoreSupport class uses a property setting from the quartz.properties file (discussed shortly) to determine whether the Scheduler instance is participating in a cluster. If a cluster is configured, a new instance of the class ClusterManager is created, initialized, and started. The ClusterManager is an inner class within the JobStoreSupport class. The ClusterManager class, which extends java.lang.Thread, runs periodically and performs a check-in function for the Scheduler instance. When the clusterCheckin() method is called, the JobStoreSupport updates the database table SCHEDULER_STATE for the Scheduler instance. The Scheduler also checks to see if any of the other cluster nodes have failed. The check-in occurs periodically based on a configuration property (discussed shortly).
Detecting Failed Scheduler Nodes
When a Scheduler instance performs the check-in routine, it looks to see if there are other Scheduler instances that didn't check in when they were supposed to. It does this by inspecting the SCHEDULER_STATE table and looking for schedulers that have a value in the LAST_CHECK_TIME column that is older than the property org.quartz.jobStore.clusterCheckinInterval (discussed in the next section). If one or more nodes haven't checked in, the running Scheduler assumes that the other instance(s) have failed.
Recovering Jobs from Failed Instances
When a Scheduler instance fails while it's executing a job, it's possible to get the job re-executed by another, working Scheduler. For this to happen, the job's recoverable property, configured in the JobDetail object, must be set to true.
If the recoverable property is set to false (the default), when a Scheduler fails while running a job, it won't be re-executed; instead, it will be fired by a different Scheduler instance upon the trigger's fire time, if any. How quickly a failed Scheduler instance is detected depends on the check-in interval of each Scheduler. This is discussed in the next section.
Configuring Quartz to Use Clustering |
Scheduling in the Enterprise
- What Is Job Scheduling?
- Why job Scheduling Is Important
- Uses for Job Schedulers in the Enterprise
- Uses for Job Schedulers in NonEnterprise
- Job scheduling Versus Workflow
- What about Alternative Solutions?
Getting Started with Quartz
- Getting Started with Quartz
- History of the Quartz Framework
- Downloading and Installing Quartz
- Building Quartz from Source
- Getting Help from the Quartz Community
- Whos Using Quartz?
Hello, Quartz
- Hello, Quartz
- The Hello, World Quartz Project
- Scheduling the Quartz ScanDirectoryJob
- Scheduling a Quartz Job Declaratively
- Packaging the Quartz Application
Scheduling Jobs
- Scheduling Jobs
- The Quartz Scheduler
- The Quartz SchedulerFactory
- Managing the Scheduler
- Managing Jobs
- Volatility, Durability, and Recoverability
- Quick Java Thread Overview
- Thread Usage in Quartz
- Understanding Quartz Triggers
Cron Triggers and More
- Cron Triggers and More
- Quick Lesson in Cron
- Using the Quartz CronTrigger
- The Cron Expression Format
- Using Start and End Dates with CronTrigger
- Using TriggerUtils with the CronTrigger
- Using CronTriggers in the JobInitializationPlugin
- Cron Expressions Cookbook
- Creating a Fire-Now Trigger
JobStores and Persistence
- JobStores and Persistence
- Job Storage
- Job Storage in Quartz
- Using Memory to Store Scheduler Information
- Using Persistent JobStores
- Using the Database for Job Storage
- Creating the Quartz Database Structure
- Using JobStoreTX
- Configuring a DataSource for JobStoreTX
- Running Quartz with JobStoreTX
- Using Memory to Store Scheduler Information
- Using the JobStoreCMT
- Configuring Datasources for JobStoreCMT
- Improving Performance with Persistent JobStores
- Creating New JobStores
Implementing Quartz Listeners
- Implementing Quartz Listeners
- Listeners as Extension Points
- Implementing a Listener
- Listening for Job Events
- Listening for Trigger Events
- Listening for Scheduler Events
- Using the FileScanListener
- Implementing Listeners in the quartz_jobs.xml File
- Thread Use in Listeners
- Uses of the Quartz Listeners
Using Quartz Plug-Ins
- Using Quartz Plug-Ins
- What Is a Plug-In?
- Creating a Quartz Plug-In
- Registering Your Plug-Ins
- Using Multiple Plug-Ins
- Quartz Utility Plug-Ins
Using Quartz Remotely
- Using Quartz Remotely
- Why RMI with Quartz?
- Brief Overview of Java RMI
- Requirements of RMI
- Creating a Quartz RMI Server
- Using the RMI Registry
- Creating the RMI Client
- Testing the RMI Server and Client
Using Quartz with J2EE
- Using Quartz with J2EE
- If I Have J2EE, Why Do I Need Quartz?
- Using the J2EE Containers DataSource
- Using Other J2EE Resources
- The EJB 2.1 Specification: Finally Some Light
Clustering Quartz
- Clustering Quartz
- What Does Clustering Mean to Quartz?
- How Clustering Works in Quartz
- Configuring Quartz to Use Clustering
- Running the Quartz Cluster Nodes
- Quartz Clustering Cookbook
Quartz Cookbook
Quartz and Web Applications
- Quartz and Web Applications
- Using Quartz Within a Web Application
- Integrating Quartz
- Using Quartz with the Struts Framework
- The QuartzInitializerServlet to the Rescue
- Using a ServletContextListener
- Introducing the Quartz Web Application
Using Quartz with Workflow
- Using Quartz with Workflow
- What Is Workflow?
- Job Chaining in Quartz
- Quick Introduction to OSWorkflow
- Integration of Quartz with OSWorkflow
- Creating a Workflow Job
- Conclusion
Appendix A. Quartz Configuration Reference
- Appendix A. Quartz Configuration Reference
- The Main Quartz Properties
- Configuring the Quartz ThreadPool
- Configuring Quartz Listeners
- Configuring a TriggerListener
- Configuring Quartz Plug-Ins
- Configuring Quartz RMI Settings
- Configuring JobStore Settings
- Configuring the JobStoreTX JobStore
- Configuring JobStoreCMT
- Configuring Quartz Datasources
- Configuring a Datasource Using a Custom ConnectionProvider
EAN: 2147483647
Pages: 148
