Content Category
The content category includes the file and directory content data. This section describes where UFS stores file and directory content and how to analyze it.
Overview
UFS uses fragments and blocks to store file and directory content. A fragment is a group of consecutive sectors, and a block is a group of consecutive fragments. Every fragment has an address, starting with 0. A block is addressed using the address of the first fragment in the block. The first block and fragment start with the first sector of the file system. The minimum size of a UFS block is 4,096 bytes, and the maximum number of fragments per block is eight. An example of the block and fragment relationship is shown in Figure 16.6 where block 64, which contains fragments 64 to 71, is fully allocated to a file, and fragments 74 and 75 in block 72 are allocated to a file. The other fragments in block 72 can be allocated to other files.
Figure 16.6. Two UFS blocks with 8 fragments in each. One block is allocated, and two fragments of the other are allocated to a file.

The motivation for having two types of data units is to allow files to allocate large amounts of consecutive data while not wasting space in the last block. Investigators frequently utilize the large amounts of wasted slack space at the end of a file, but UFS tries to minimize the amount of wasted space.
With UFS, if a file can fill an entire block, it will be allocated a full block. When the final data are being written, only enough fragments for the data are allocated. When the file grows in size and can fill an entire block, it will be moved to one if needed.
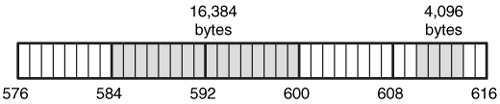
Consider an example file system with 8,192 byte blocks and 1,024 byte fragments. A file that is 20,000 bytes in size will need 2 blocks and 4 fragments. This can be seen in Figure 16.7 where the two blocks start in fragments 584 and 592. This can store 16,384 bytes of the file, and the remaining 3,616 bytes are stored in fragments 610 to 613. The first two fragments in this block are used by another file.
Figure 16.7. A 20,000-byte file is stored in two 8,192-byte blocks and four 1,024 byte fragments.
The allocation status of a block or fragment is determined using one of two bitmaps. One has a bit for each fragment, and the other has a bit for each block, and they should contain nearly the same information, but the block bitmap allows the system to more quickly find consecutive blocks when allocating a large file. The UFS bitmaps are opposite of normal bitmaps because they are "free" bitmaps. Therefore, when the bit is 1, the block or fragment is available. If the bit is a 0, the block or fragment is being used.
The bitmaps are stored inside of a cylinder group's group descriptor data structure, which we previously examined. Therefore, before we determine the allocation status of a block, we will need to determine in which group it is located. This is easy because all we need to do is divide the fragment address by the number of fragments per cylinder group.
To determine the bit in the bitmap for a specific block, we calculate the starting block address of the group and subtract that value from our block address. Refer to Chapter 14 for an example of this. The UFS block and fragment bitmaps are discussed in more detail in Chapter 17.
The dstat tool in TSK shows us the allocation status of a UFS fragment and gives us the cylinder group that it is a part of. An example from our UFS1 image is shown here:
# dstat -f openbsd openbsd.dd 288 Fragment: 288 Allocated Group: 0
Allocation Algorithms
The designers of UFS have spent a lot of time researching allocation strategies and have focused on making block allocation efficient. Similar work has likely occurred with the commercial file systems, but the work has not been published, and my basic testing might not have shown the full extent of their algorithms. In this section, I will give an overview of the documented BSD allocation strategies but would recommend the Design and Implementation of the 4.4 BSD Operating System or Design and Implementation of the FreeBSD Operating System books for anyone who wants more details. While there is a documented allocation strategy, there is no requirement that an OS must follow it. They are free to allocate in any method they want.
The first consideration when allocating a block or fragment is the cylinder group. If the OS is allocating blocks for a new file and there are available blocks in the cylinder group of the inode, blocks from that cylinder group are used. If it is an existing file, restrictions might be placed on how many blocks any file can have in a single group, so a new group might need to be selected. For example, many of the OSes will restrict how many blocks a file or directory can allocate in a single group. The restriction is typically placed at 25% or 33% of the total number of blocks. When that value is reached, a new group is selected. Solaris has a similar strategy where it allocates the first 12 blocks (i.e., the direct blocks in the inode) for a file in one cylinder group and then allocates the remaining blocks in other groups.
After the cylinder group has been selected, the OS will allocate blocks based on how many data are being written. If the size of the file is unknown or if it slowly increases, blocks will be added one by one using a next-available strategy. This has historically involved taking the rotational delay of the disk into consideration to find the optimal location for the next block, but now the next consecutive block is used. If the size is known, the data are broken up into chunks, which are typically the size of 16 blocks. Blocks are allocated for each of these chunks using a first-available strategy. Therefore, if you have an 8,192-byte block size, each chunk will be 128 KB. This value can be configured in the file system and is set in the superblock.
For the final data in the file, fragments will be allocated instead of a full block. The OS will look for consecutive fragments that have enough space for the data. The consecutive fragments cannot cross a block boundary, and the bookkeeping information in the file system provides a list of where fragments of a given length can be found. A first-available strategy is used when allocating the final fragments.
When a file is extended and it already has fragments, the OS first tries to extend the existing fragments. If this is not possible, a new set of fragments or a full block is allocated and the data are moved. If the file has 12 full blocks, fragments are generally no longer used. Full blocks are allocated when the file is extended.
The superblock defines how many blocks should remain free at any given time. The free blocks are reserved so that a system administrator can login and clean up the file system, but an OS might choose to not enforce the limit.
The BSD and Solaris systems that I tested will all wipe the unused sectors in a fragment. Therefore, there will not be any data from a deleted file in the slack space of an allocated fragment.
Analysis Techniques
We analyze data in the content category by locating a block or fragment, viewing the contents, and identifying its allocation status. To locate the data, we need its fragment or block address. The sizes of a block and fragment are given in the superblock, and we simply advance from the start of the file system until we reach the specific address. The block address corresponds to the address of the first fragment in the block.
To determine the allocation status of any fragment, we must first determine the cylinder group in which it is located. This is done by dividing the block address by the number of fragments in a group. The group descriptor for the group is located using the offset value from the superblock and adding it to the base address for the group. The group descriptor will contain the fragment bitmap.
To extract all unallocated fragments in the file system, we cycle through each group and examine each fragment bitmap. Any fragment that is not allocated is extracted for analysis. Fragments and blocks that are used to store superblocks, inode tables, group descriptors, and the cylinder group summary area are considered allocated even though they are not allocated to a file.
Analysis Considerations
The design and allocation strategies of UFS provide some benefit and challenges for investigators. On the plus side, blocks should be localized to their inode, which could make file recovery easier, and if deleted data are in a group that has little activity, it could exist for longer than deleted data in other groups. Also on the plus side is that clusters of consecutive blocks are allocated when possible so that fragmentation is reduced, which could help carving tools.
One of the down sides of UFS is the final fragment. It is common for the final data in a file to exist in some other part of the cylinder group because it needed only one fragment. This can make carving more difficult. On the other hand, the fragments might allow more data to be recovered than with ExtX, which wiped all bytes in a block. UFS will wipe only the fragments allocated, so parts of a block will still exist after some of it has been reallocated.
Very large files that need to be recovered, such as a large e-mail file, could be difficult because they might have taken up more than 25% of the cylinder group and the remainder moved to another group. Further, Solaris uses a new cylinder group after allocating the first 12 blocks of the file, which prevents carving tools from working. Of course, the OS that created the file system might not have been following every rule of UFS and did not use these allocation principles.
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
