MFT Entry Attribute Concepts
An MFT entry has little internal structure and most if it is used to store attributes, which are data structures that store a specific type of data. There are many types of attributes, and each has its own internal structure. For example, there are attributes for a file's name, date and time, and even its contents. This is one of the ways that NTFS is very different from other file systems. Most file systems exist to read and write file content, but NTFS exists to read and write attributes, one of which happens to contain file content.
Consider the previous analogy that described an MFT entry as a large box that is initially empty. Attributes are similar to smaller boxes inside the larger box where the smaller boxes can be any shape that most efficiently stores the object. For example, a hat can be stored in a short-round box, and a poster can be stored in a long-round box.
While each type of attribute stores a different type of data, all attributes have two parts: the header and the content. Figure 11.4 shows an MFT entry with four header and content pairs. The header is generic and standard to all attributes. The content is specific to the type of attribute and can be any size. If we think of our boxes analogy, there is always the same basic information on the outside of each small box, but the shape of each box may be different.
Figure 11.4. Our example MFT entry with the header and content locations specified.
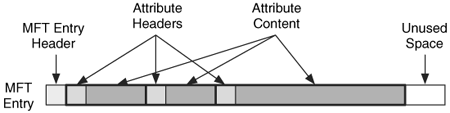
Attribute Headers
The attribute header identifies the type of attribute, its size, and its name. It also has flags to identify if the value is compressed or encrypted. The attribute type is a numerical identifier based on the data type and we will discuss the default attribute types in the "Standard Attribute Types" section. An MFT entry can have multiple attributes of the same type.
Some of the attributes can be assigned a name and it is stored in UTF-16 Unicode in the attribute header. An attribute also has an identifier value assigned to it that is unique to that MFT entry. If an entry has more than one attribute of the same type, this identifier can be used to differentiate between them. The attribute header data structure is given in the "Attribute Header" section of Chapter 13.
Attribute Content
The content of the attribute can have any format and any size. For example, one of the attributes is used to store the content for a file, so it could be several MB or GB in size. It is not practical to store this amount of data in an MFT entry, which is only 1,024 bytes.
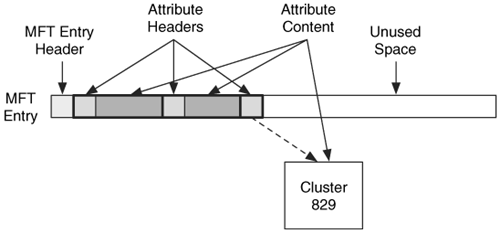
To solve this problem, NTFS provides two locations where attribute content can be stored. A resident attribute stores its content in the MFT entry with the attribute header. This works for only small attributes. A non-resident attribute stores its content in an external cluster in the file system. The header of the attribute identifies if the attribute is resident or non-resident. If an attribute is resident, the content will immediately follow the header. If the attribute is non-resident, the header will give the cluster addresses. In Figure 11.5 we see the example MFT entry that we saw previously, but now its third attribute is too large to fit in the MFT, and it has allocated cluster 829.
Figure 11.5. Our example MFT entry where the third attribute has become too large and became non-resident.
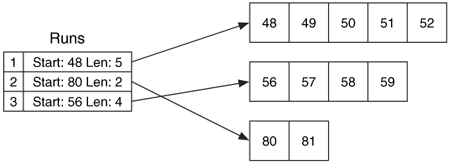
Non-resident attributes are stored in cluster runs, which are consecutive clusters, and the run is documented using the starting cluster address and run length. For example, if an attribute has allocated clusters 48, 49, 50, 51, and 52, it has a run that starts in cluster 48 with a length of 5. If the attribute also allocated clusters 80 and 81, it has a second run that starts in cluster 80 with a length of 2. A third run could start at cluster 56 and have a length of 4. We can see this in Figure 11.6.
Figure 11.6. Example runlist with three runs of allocated clusters.
Throughout this book, we have differentiated between the different types of addresses. For example, we defined the logical file system address as the address assigned to file system data units and the logical file address as relative to the start of a file. NTFS uses different terms for these addresses. The Logical Cluster Number (LCN) is the same as the logical file system address, and the Virtual Cluster Number (VCN) is the same as a logical file address.
NTFS uses VCN-to-LCN mappings to describe the non-resident attribute runs. If we return to our previous example, this attribute's run shows that VCN addresses 0 to 4 map to LCN addresses 48 to 52, VCN addresses 5 to 6 map to LCN addresses 80 to 81, and VCN addresses 7 to 10 map to LCN addresses 56 to 59. The runlist data structure is given in the "Attribute Header" section of Chapter 13.
Standard Attribute Types
So far we have been speaking in general terms about attribute types. Now we are going to look at the basics of some of the standard attributes. Many of these will be discussed in detail in Chapter 12.
As was previously mentioned, a number is defined for each type of attribute, and Microsoft sorts the attributes in an entry using this number. The standard attributes have a default type value assigned to them, but we will later see that it can be redefined in the $AttrDef file system metadata file. In addition to a number, each attribute type has a name, and it has all capital letters and starts with "$." Some of the default attribute types and their identifiers are given in Table 11.2. Not all these attribute types and identifiers will exist for every file. In addition to the more detailed descriptions in Chapter 12, the data structures for many are given in Chapter 13.
|
Type Identifier |
Name |
Description |
|---|---|---|
|
16 |
$STANDARD_INFORMATION |
General information, such as flags; the last accessed, written, and created times; and the owner and security ID. |
|
32 |
$ATTRIBUTE_LIST |
List where other attributes for file can be found. |
|
48 |
$FILE_NAME |
File name, in Unicode, and the last accessed, written, and created times. |
|
64 |
$VOLUME_VERSION |
Volume information. Exists only in version 1.2 (Windows NT). |
|
64 |
$OBJECT_ID |
A 16-byte unique identifier for the file or directory. Exists only in versions 3.0+ and after (Windows 2000+). |
|
80 |
$SECURITY_ DESCRIPTOR |
The access control and security properties of the file. |
|
96 |
$VOLUME_NAME |
Volume name. |
|
112 |
$VOLUME_ INFORMATION |
File system version and other flags. |
|
128 |
$DATA |
File contents. |
|
144 |
$INDEX_ROOT |
Root node of an index tree. |
|
160 |
$INDEX_ALLOCATION |
Nodes of an index tree rooted in $INDEX_ROOT attribute. |
|
176 |
$BITMAP |
A bitmap for the $MFT file and for indexes. |
|
192 |
$SYMBOLIC_LINK |
Soft link information. Exists only in version 1.2 (Windows NT). |
|
192 |
$REPARSE_POINT |
Contains data about a reparse point, which is used as a soft link in version 3.0+ (Windows 2000+). |
|
208 |
$EA_INFORMATION |
Used for backward compatibility with OS/2 applications (HPFS). |
|
224 |
$EA |
Used for backward compatibility with OS/2 applications (HPFS). |
|
256 |
$LOGGED_UTILITY_STREAM |
Contains keys and information about encrypted attributes in version 3.0+ (Windows 2000+). |
Nearly every allocated MFT entry has a $FILE_NAME and a $STANDARD_INFORMATION type attribute. The one exception is non-base MFT entries, which are discussed next. The $FILE_NAME attribute contains the file name, size, and temporal information. The $STANDARD_INFORMATION attribute contains temporal, ownership, and security information. The latter attribute exists for every file and directory because it contains the data needed to enforce data security and quotas. In an abstract sense, there is no essential data in this attribute, but the application-level features of the file system require it to be there. Both of these attributes are always resident.
Every file has a $DATA attribute, which contains the file content. If the content is over roughly 700 bytes in size, it becomes non-resident and is saved in external clusters. When a file has more than one $DATA attribute, the additional attributes are sometimes referred to as alternate data streams (ADS). The default $DATA attribute that is created when a file is created does not have a name associated with it, but additional $DATA attributes must have one. Note that the attribute name is different from the type name. For example, $DATA is the name of the attribute type, and the attribute's name could be "fred." Some tools, including The Sleuth Kit (TSK), will assign the name "$Data" to the default $DATA attribute.
Every directory has an $INDEX_ROOT attribute that contains information about the files and subdirectories that are located in it. If the directory is large, $INDEX_ALLOCATION and $BITMAP attributes are also used to store information. To make things confusing, it is possible for a directory to have a $DATA attribute in addition to the $INDEX_ROOT attribute. In other words, a directory can store both file content and a list of its files and subdirectories. The $DATA attribute can store any content that an application or user wants to store there. The $INDEX_ROOT and $INDEX_ALLOCATION attributes for a directory typically have the name "$I30."
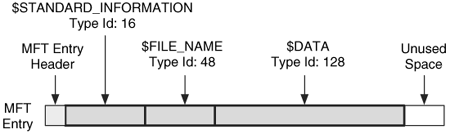
Figure 11.7 shows the example MFT entry that we previously used, and its attributes have been given names and types. It has the three standard file attributes. In this example, all the attributes are resident.
Figure 11.7. Our example MFT entry where the type names and identifiers have been added to the attributes.
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
