Basic Concepts
In this section, we examine the basic NTFS data structure concepts. In the first subsection, we examine a design feature of large data structures that makes them more reliable. Next, we discuss the data structure for an MFT entry and an attribute header.
Fixup Values
Before we look at any specific NTFS data structure, we need to discuss a storage technique that is used for increased reliability. NTFS incorporates fixup values into data structures that are over one sector in length. With fixup values, the last two bytes of each sector in large data structures are replaced with a signature value when the data structure is written to disk. The signature is later used to verify the integrity of the data by verifying that all sectors have the same signature. Note that fixups are used only in data structures and not in sectors that contain file content.
The data structures that use fixups have header fields that identify the current 16-bit signature value and an array that contains the original values. When the data structure is written to disk, the signature value is incremented by one, the last two bytes of each sector are copied to the array, and the signature value is written to the last two bytes of each sector. When reading the data structure, the OS should verify that the last two bytes of each sector are equal to the signature value, and the original values are then replaced from the array. Figure 13.1 shows a data structure with its real values and then the version that is written to disk. In the second data structure, the last two bytes of each sector have been replaced with 0x0001.
Figure 13.1. A multi-sector data structure with its original values and then with the fixups applied to the last two bytes of each sector.
Fixups are used to detect damaged sectors and corrupt data structures. If only one sector of a multi-sector data structure was written, the fixup will be different from the signature, and the OS will know that the data are corrupt. When we dissect our example file system, we will need to first replace the signature values.
MFT Entries (File Records)
As already discussed in Chapters 11 and 12, the Master File Table (MFT) is the heart of NTFS and has an entry for every file and directory. MFT entries are a fixed size and contain only a few fields. To date, the entries have been 1,024 bytes in size, but the size is defined in the boot sector. Each MFT entry uses fixup values, so the on-disk version of the data structure has the last two bytes of each sector replaced by a fixup value. Refer to the previous section for an explanation of fixup values. The data structure fields for an MFT entry are given in Table 13.1.
|
Byte Range |
Description |
Essential |
|---|---|---|
|
03 |
Signature ("FILE") |
No |
|
45 |
Offset to fixup array |
Yes |
|
67 |
Number of entries in fixup array |
Yes |
|
815 |
$LogFile Sequence Number (LSN) |
No |
|
1617 |
Sequence value |
No |
|
1819 |
Link count |
No |
|
2021 |
Offset to first attribute |
Yes |
|
2223 |
Flags (in-use and directory) |
Yes |
|
2427 |
Used size of MFT entry |
Yes |
|
2831 |
Allocated size of MFT entry |
Yes |
|
3239 |
File reference to base record |
No |
|
4041 |
Next attribute id |
No |
|
421023 |
Attributes and fixup values |
Yes |
The standard signature value is "FILE," but some entries will also have "BAAD" if chkdsk found an error in it. The next two fields are for the fixup values, and the array is typically stored after byte 42. The offset values are relative to the start of the entry.
The LSN is used for the file system log (or journal), which was discussed in the "Application Category" section of Chapter 12. The log records when metadata updates are made to the file system so that a corrupt file system can be more quickly fixed.
The sequence value is incremented when the entry is either allocated or unallocated, determined by the OS. The link count shows how many directories have entries for this MFT entry. If hard links were created for the file, this number is incremented by one for each link.
We find the first attribute for the file using the offset value, which is relative to the start of the entry. All other attributes follow the first one, and we find them by advancing ahead using the size field in the attribute header. The end of file marker 0xffffffff exists after the last attribute. If a file needs more than one MFT entry, the additional ones will have the file reference of the base entry in their MFT entry.
The flags field has only two values. The 0x01 bit is set when the entry is in use, and 0x02 is set when the entry is for a directory.
Let us take a look at a raw MFT entry. To view the table, we will use icat from The Sleuth Kit (TSK) and view the $DATA attribute for the $MFT file, which is entry 0. Remember that we can specify any attribute in TSK by adding the attribute type ID following the MFT entry address. In this case, the $DATA attribute has a type of 128.
# icat f ntfs ntfs1.dd 0-128 | xxd 0000000: 4649 4c45 3000 0300 4ba7 6401 0000 0000 FILE0...K.d..... 0000016: 0100 0100 3800 0100 b801 0000 0004 0000 ....8........... 0000032: 0000 0000 0000 0000 0600 0000 0000 0000 ................ 0000048: 5800 0000 0000 0000 1000 0000 6000 0000 X...........`... [REMOVED] 0000496: 3101 b43a 0500 0000 ffff ffff 0000 5800 1..:..........X. 0000512: 0000 0000 0000 0000 0000 0000 0000 0000 ................ [REMOVED] 0001008: 0000 0000 0000 0000 0000 0000 0000 5800 ..............X.
This output is in little-endian ordering, so we need to reverse the order of the numbers. We see the "FILE" signature, and bytes 4 and 5 show that the fixup array is located 48 bytes (0x0030) into the MFT entry. Bytes 6 to 7 show us that the array has three values in it. Bytes 16 to 17 show that the sequence value for this MFT entry is 1, which means that this is the first time this entry has been used. Bytes 18 to 19 show that the link count is 1, so we know it has only one name. Bytes 20 to 21 show that the first attribute is located at byte offset 56 (0x0038).
The flags in bytes 22 to 23 show that this entry is in use (0x0001). The base entry values in bytes 32 to 39 are 0, which shows that this is a base entry, and bytes 40 to 41 show that the next attribute ID to be assigned is 6. Therefore, we should expect that there are attributes with IDs 1 to 5.
The fixup array starts at byte 48. The first two bytes show the signature value, which is 0x0058. The next two-byte values are the original values that should be used to replace the signature value. We look at the last two bytes of each sector, bytes 510 to 511 and 1022 to 1023, and see that each has 0x0058. To process the entry, we replace those values with 0x0000, which are the values in the fixup array. Following the fixup array, the first attribute begins in byte 56. This file's attributes end at byte 504 with the end of file marker 0xffff ffff. The rest of the attribute entry is 0s.
If you want to view any MFT entry with TSK, you can use dd along with icat to skip ahead to the correct location. You can do this by setting the block size to 1024, which is the size of each MFT entry. For example, to see entry 1234 you would use
# icat -f ntfs ntfs1.dd 0 | dd bs=1024 skip=1234 count=1 | xxd
Attribute Header
An MFT entry is filled with attributes, and each attribute has the same header data structure, which we will now examine. As a reminder, Figure 13.2 shows a diagram of a typical file and the header locations. The data structure is slightly different for resident and non-resident attributes because non-resident attributes need to store the run information.
Figure 13.2. A typical file with the different header locations.
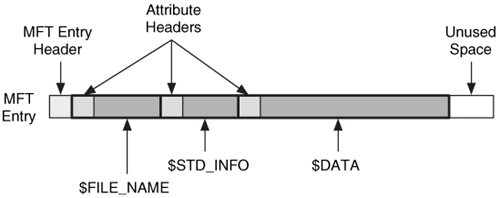
The first 16 bytes are the same for both types of attributes and contain the fields given in Table 13.2.
|
Byte Range |
Description |
Essential |
|---|---|---|
|
03 |
Attribute type identifier |
Yes |
|
47 |
Length of attribute |
Yes |
|
88 |
Non-resident flag |
Yes |
|
99 |
Length of name |
Yes |
|
1011 |
Offset to name |
Yes |
|
1213 |
Flags |
Yes |
|
1415 |
Attribute identifier |
Yes |
These values give the basic information about the attribute, including its type, size, and name location. The size is used to find the next attribute in the MFT entry, and if it is the last, 0xffff ffff will exist after it. The non-resident flag is set to 1 when the attribute is non-resident. The flag's value identifies if the attribute is compressed (0x0001), encrypted (0x4000), or sparse (0x8000). The attribute identifier is the number that is unique to this attribute for this MFT entry. The offset to the name is relative to the start of the attribute. A resident attribute has the fields shown in Table 13.3.
|
Byte Range |
Description |
Essential |
|---|---|---|
|
015 |
General header (see Table 13.2) |
Yes |
|
1619 |
Size of content |
Yes |
|
2021 |
Offset to content |
Yes |
These values simply give the size and location (relative to the start of the attribute) of the attribute content, also called a stream. Let us look at an example. When we previously dissected the MFT entry, we saw that attributes started in byte 56. I've taken the attribute from there and reset the offset numbers on the side of the output so that the attribute header offsets can be more easily determined.
0000000: 1000 0000 6000 0000 0000 1800 0000 0000 ....`........... 0000016: 4800 0000 1800 0000 305a 7a1f f63b c301 H.......0Zz..;..
This output shows the attribute type in the first four bytes as 16 (0x10), which is for $STANDARD_INFORMATION. Bytes 4 to 7 show that it has a size of 96 bytes (0x60). Byte 8 shows that this is a resident attribute (0x00), and byte 9 shows that it does not have a name (0x00). The flags and id values are set to 0 in bytes 12 to 13 and 14 to 15. Bytes 16 to 19 show that the attribute is 72 bytes (0x48) long, and bytes 20 and 21 show that it starts 24 bytes (0x18) from the start of the attribute. A quick sanity check shows that the 24 byte offset and 72 byte attribute length equal a total of 96 bytes, which is the reported length of the attribute.
Non-resident attributes have a different data structure because they need to be able to describe an arbitrary number of cluster runs. The attribute has the fields given in Table 13.4.
|
Byte Range |
Description |
Essential |
|---|---|---|
|
015 |
General header (see Table 13.2) |
Yes |
|
1623 |
Starting Virtual Cluster Number (VCN) of the runlist |
Yes |
|
2431 |
Ending VCN of the runlist |
Yes |
|
3233 |
Offset to the runlist |
Yes |
|
3435 |
Compression unit size |
Yes |
|
3639 |
Unused |
No |
|
4047 |
Allocated size of attribute content |
No |
|
4855 |
Actual size of attribute content |
Yes |
|
5663 |
Initialized size of attribute content |
No |
Recall that VCN is a different name for the logical file addresses that we defined in Chapter 8, "File System Analysis." The starting and ending VCN numbers are used when multiple MFT entries are needed to describe a single attribute. For example, if a $DATA attribute was very fragmented and its runs could not fit into a single MFT entry, it would allocate a second MFT entry. The second entry would contain a $DATA attribute with a starting VCN equal to the VCN after the ending VCN of the first entry. We will see an example of this in the "$ATTRIBUTE_LIST" section. The compression unit size value was described in Chapter 11 and is needed only for compressed attributes.
The offset to the data runlist is given relative to the start of the attribute. The format of a runlist is very efficient and slightly confusing. It has a variable length, but must be at least one byte. The first byte of the data structure is organized into the upper 4 bits and lower 4 bits (also known as nibbles). The four least significant bits contain the number of bytes in the run length field, which follows the header byte. The four most significant bits contain the number of bytes in the run offset field, which follows the length field. We can see an example of this in Figure 13.3. The first byte shows that the run length field is 1 byte and that the run offset field is 2 bytes.
Figure 13.3. The first byte in the run shows that the length field is 1 byte, and the offset field is 2 bytes.
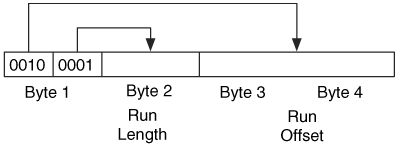
The values are in cluster-sized units, and the offset field is a signed value that is relative to the previous offset. For example, the offset of the first run in the attribute will be relative to the start of the file system, and the second run offset will be relative to the previous offset. A negative number will have its most significant bit set to 1, and if you are going to plug the value into a calculator to convert the value, you must add as many 1s as needed to make a full 32 or 64 bit number. For example, if the value is 0xf1, you need to enter 0xfffffff1 into a converter.
To look at a non-resident attribute, we return to the entry we previously analyzed and advance further in to look at the $DATA attribute. The attribute contents are shown here, and the offset values are relative to the start of the attribute:
0000000: 8000 0000 6000 0000 0100 4000 0000 0100 ....`.....@..... 0000016: 0000 0000 0000 0000 ef20 0000 0000 0000 ......... ...... 0000032: 4000 0000 0000 0000 00c0 8300 0000 0000 @............... 0000048: 00c0 8300 0000 0000 00c0 8300 0000 0000 ................ 0000064: 32c0 1eb5 3a05 2170 1b1f 2290 015f 7e31 2...:.!p..".._~1 0000080: 2076 ed00 2110 8700 00b0 6e82 4844 7e82 v..!.....n.HD~.
The first four bytes show that the attribute has a type of 128 (0x80), and the second set of four bytes show that its total size is 96 bytes (0x60). Byte 8 is 1, which shows that this is a non-resident attribute, and byte 9 is 0, which shows that the length of the attribute name is 0, and therefore this is the default $DATA attribute and not an ADS. The flags in bytes 12 to 13 are 0, which means that the attribute is not encrypted or compressed.
The non-resident information starts at byte 16, and bytes 16 to 23 show that the starting VCN for this set of runs is 0. The ending VCN for this set of runs is in bytes 24 to 31, and they are set to 8,431 (0x20ef). Bytes 32 to 33 show that the offset of the runlist is 64 bytes (0x0040) from the start. Bytes 40 to 47, 48 to 55, and 56 to 63 are for the allocated, actual, and initialized amount of space, and they are all set to the same value of 8,634,368 bytes (0x0083c000).
At byte 64, we finally get to the runlist. I will copy the relevant output again:
0000064: 32c0 1eb5 3a05 2170 1b1f
Recall that the first byte is organized into the upper and lower 4 bits, which show how large each of the other fields are. The lower 4 bits of byte 64 show that there are two bytes in the field for the run length and the upper 4 bits show that there are three bytes in the offset field. To determine the length of the run, we examine bytes 65 to 66, which give us 7,872 clusters (0x1ec0). The next three bytes, bytes 67 to 69, are used for the offset, which is cluster 342,709 (0x053ab5). Therefore, the first run starts at cluster 342,709 and extends for 7,872 clusters.
The data structure for the next run starts after the previous one, which is byte 70. There we see that the length field is 1 byte, and the offset field is 2 bytes. The length value is in byte 71, which is 112 (0x70). The offset value is in bytes 72 to 73, which is 7,963 (0x1f1b). The offset is signed and relative to the previous offset, so we add 7,963 to 342,709 and get 350,672. Therefore, the second run starts at cluster 350,672 and extends for 112 clusters. I will leave the rest of the runlist for you to decode.
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
