Data Analysis
In the previous section, I said we were going to search for digital evidence, which is a rather general statement because evidence can be found almost anywhere. In this section, I am going to narrow down the different places where we can search for digital evidence and identify which will be discussed later in this book. We will also discuss which data we can trust more than others.
Analysis Types
When analyzing digital data, we are looking at an object that has been designed by people. Further, the storage systems of most digital devices have been designed to be scalable and flexible, and they have a layered design. I will use this layered design to define the different analysis types [Carrier 2003a].
If we start at the bottom of the design layers, there are two independent analysis areas. One is based on storage devices and the other is based on communication devices. This book is going to focus on the analysis of storage devices, specifically non-volatile devices, such as hard disks. The analysis of communication systems, such as IP networks, is not covered in this book, but is elsewhere [Bejtlich 2005; Casey 2004; Mandia et al. 2003].
Figure 1.2 shows the different analysis areas. The bottom layer is Physical Storage Media Analysis and involves the analysis of the physical storage medium. Examples of physical store mediums include hard disks, memory chips, and CD-ROMs. Analysis of this area might involve reading magnetic data from in between tracks or other techniques that require a clean room. For this book, we are going to assume that we have a reliable method of reading data from the physical storage medium and so we have a stream 1s and 0s that were previously written to the storage device.
Figure 1.2. Layers of analysis based on the design of digital data. The bold boxes are covered in this book.
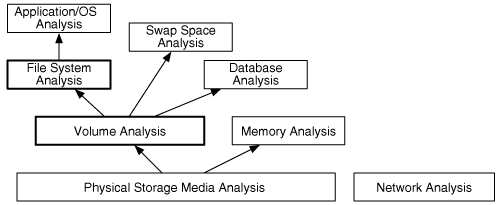
We now analyze the 1s and 0s from the physical medium. Memory is typically organized by processes and is out of the scope of this book. We will focus on non-volatile storage, such as hard disks and flash cards.
Storage devices that are used for non-volatile storage are typically organized into volumes. A volume is a collection of storage locations that a user or application can write to and read from. We will discuss volume analysis in Part 2 of the book, but there are two major concepts in this layer. One is partitioning, where we divide a single volume into multiple smaller volumes, and the other is assembly, where we combine multiple volumes into one larger volume, which may later be partitioned. Examples of this category include DOS partition tables, Apple partitions, and RAID arrays. Some media, such as floppy disks, do not have any data in this layer, and the entire disk is a volume. We will need to analyze data at the volume level to determine where the file system or other data are located and to determine where we may find hidden data.
Inside each volume can be any type of data, but the most common contents are file systems. Other volumes may contain a database or be used as a temporary swap space (similar to the Windows pagefile). Part 3 of the book focuses on file systems, which is a collection of data structures that allow an application to create, read, and write files. We analyze a file system to find files, to recover deleted files, and to find hidden data. The result of file system analysis could be file content, data fragments, and metadata associated with files.
To understand what is inside of a file, we need to jump to the application layer. The structure of each file is based on the application or OS that created the file. For example, from the file system perspective, a Windows registry file is no different from an HTML page because they are both files. Internally, they have very different structures and different tools are needed to analyze each. Application analysis is very important, and it is here where we would analyze configuration files to determine what programs were running or to determine what a JPEG picture is of. I do not discuss application analysis in this book because it requires multiple books of its own to cover in the same detail that file systems and volumes are covered. Refer to the general digital investigation books listed in the Preface for more information.
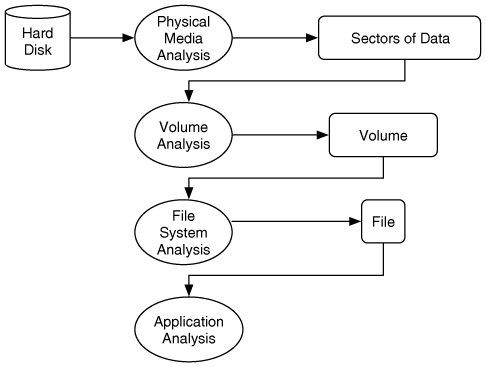
We can see the analysis process in Figure 1.3. This shows a disk that is analyzed to produce a stream of bytes, which are analyzed at the volume layer to produce volumes. The volumes are analyzed at the file system layer to produce a file. The file is then analyzed at the application layer.
Figure 1.3. Process of analyzing data at the physical level to the application level.
Essential and Nonessential Data
All data in the layers previously discussed have some structure, but not all structure is necessary for the layer to serve its core purpose. For example, the purpose of the file system layer is to organize an empty volume so that we can store data and later retrieve them. The file system is required to correlate a file name with file content. Therefore, the name is essential and the on-disk location of the file content is essential. We can see this in Figure 1.4 where we have a file named miracle.txt and its content is located at address 345. If either the name or the address were incorrect or missing, then the file content could not be read. For example, if the address were set to 344, then the file would have different content.
Figure 1.4. To find and read this file, it is essential for the name, size, and content location to be accurate, but it is not essential for the last accessed time to be accurate.
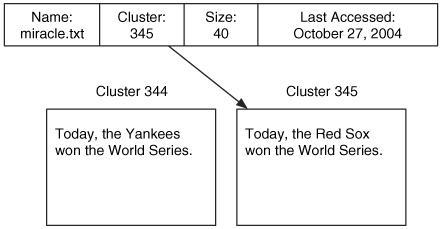
Figure 1.4 also shows that the file has a last accessed time. This value is not essential to the purpose of the file system, and if it were changed, missing, or incorrectly set, it would not affect the process of reading or writing file content.
In this book, I introduce the concept of essential and nonessential data because we can trust essential data but we may not be able to trust nonessential data. We can trust that the file content address in a file is accurate because otherwise the person who used the system would not have been able to read the data. The last access time may or may not be accurate. The OS may not have updated it after the last access, the user may have changed the time, or the OS clock could have been off by three hours, and the wrong time was stored.
Note that just because we trust the number for the content address does not mean that we trust the actual content at that address. For example, the address value in a deleted file may be accurate, but the data unit could have been reallocated and the content at that address is for a new file. Nonessential data may be correct most of the time, but you should try to find additional data sources to support them when they are used in an incident hypothesis (i.e., the correlation in the PICL guidelines). In Parts 2 and 3 of the book, I will identify which data are essential and which are not.
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
