Other Attribute Concepts
The previous section looked at the basic concepts that apply to all NTFS attributes. Although not every attribute is basic, and this section looks at the more advanced concepts. In particular, we look at what happens when a file has too many attributes and we look at ways that the contents of an attribute can be compressed and encrypted.
Base MFT Entries
A file can have up to 65,536 attributes (because of the 16-bit identifier), so it may need more than one MFT entry to store all the attribute headers (even non-resident attributes need their header to be in the MTF entry). When additional MFT entries are allocated to a file, the original MFT entry becomes the base MFT entry. The non-base entries will have the base entry's address in one of their MFT entry fields.
The base MFT entry will have an $ATTRIBUTE_LIST type attribute that contains a list with each of the file's attributes and the MFT address in which it can be found. The non-base MFT entries do not have the $FILE_NAME and $STANDARD_INFORMATION attributes in them. We will examine the $ATTRIBUTE_LIST attribute in the "Metadata Category" section of Chapter 12.
Sparse Attributes
NTFS can reduce the space needed by a file by saving some of the non-resident $DATA attribute values as sparse. A sparse attribute is one where clusters that contain all zeros are not written to disk. Instead, a special run is created for the zero clusters. Typically, a run contains the starting cluster location and the size, but a sparse run contains only the size and not a starting location. There is also a flag that indicates if an attribute is sparse.
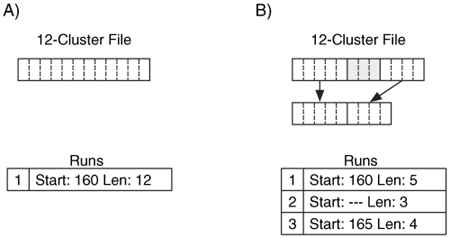
For example, consider a file that should occupy 12 clusters. The first five clusters are non-zero, the next three clusters contain zeros, and the last four clusters are non-zero. When stored as a normal attribute, one run of length 12 may be created for the file, as shown in Figure 11.8(A). When stored as a sparse attribute, three runs are created and only nine clusters are allocated, which can be seen in Figure 11.8(B).
Figure 11.8. A 12-cluster file that is stored in A) normal layout and B) sparse layout with a sparse run of three clusters.
Compressed Attributes
NTFS allows attributes to be written in a compressed format, although the actual algorithm is not given. Note that this is a file system-level compression and not an external application-level compression that can be achieved by using zip or gzip. Microsoft says that only the $DATA attribute should be compressed, and only when it is non-resident. NTFS uses both sparse runs and compressed data to reduce the amount of space needed. The attribute header flag identifies whether it is compressed, and the flags in the $STANDARD_INFORMATION and $FILE_NAME attribute also show if the file contains compressed attributes.
Before the attribute contents are compressed, the data are broken up into equal sized chunks called compression units. The size of the compression unit is given in the attribute header. There are three situations that can occur with each compression unit:
- All the clusters contain zeros, in which case a run of sparse data is made for the size of the compression unit and no disk space is allocated.
- When compressed, the resulting data needs the same number of clusters for storage (i.e., the data did not compress much). In this case, the compression unit is not compressed, and a run is made for the original data.
- When compressed, the resulting data uses fewer clusters. In this case, the data is compressed and stored in a run on the disk. A sparse run follows the compressed run to make the total run length equal to the number of clusters in a compression unit.
Let's look at a simple example to examine each of these scenarios. Assume that the compression unit size is 16 clusters and we have a $DATA attribute that is 64 clusters in length, as shown in Figure 11.9. We divide the content into four compression units and examine each. The first unit compresses to 16 clusters, so it is not compressed. The second unit is all zeros, so a sparse run of 16 clusters is made for it, and no clusters are allocated. The third unit compresses to 10 clusters, so the compressed data is written to disk in a run of 10 clusters, and a sparse run of six clusters is added to account for the compressed data. The final unit compresses to 16 clusters, so it is not compressed and a run of 16 clusters is created.
Figure 11.9. An attribute with two compression units that do not compress, one unit that is sparse, and one unit that compresses to 10 clusters.
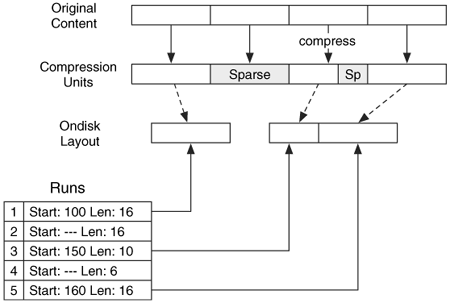
When the OS, or forensics tool, reads this attribute, it sees that the compression flag is set and organizes the runs into compression unit-sized chunks. The first run is the same size as a compression unit, so we know it is not compressed. The second run is the same size as a compression unit, and it is sparse, so we know that there are 16 clusters of zeros. The third and fourth runs combine to make a compression unit, and we see that it is only 10 clusters and needs to be uncompressed. The final run is a compression unit and it is not compressed.
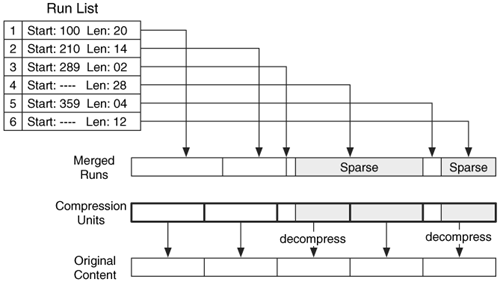
The last example was too simple, so I will present the more challenging file shown in Figure 11.10. The reason this is more complex is because the layout is not initially organized using compression units. To process this file, we need to first organize all the data in the six runs and then organize the data into compression units of 16 clusters. After merging the fragmented runs, we see that there is one run of content, one sparse run, more content, and another sparse run. The merged data are organized into compression units, and we see that the first two units have no sparse runs and are not compressed. The third and fifth units have a sparse run and are compressed. The fourth unit is sparse, and the corresponding data are all zeros.
Figure 11.10. A compressed attribute with fragmented runs that do not lie on compression unit boundaries.
Encrypted Attributes
NTFS provides the capability for attribute contents to be encrypted. This section gives an overview of how it is done and what exists on disk. In theory, any attribute could be encrypted, but Windows allows only $DATA attributes to be encrypted. When an attribute is encrypted, only the content is encrypted and the attribute header is not. A $LOGGED_UTILITY_STREAM attribute is created for the file, and it contains the keys needed to decrypt the data.
In Windows, a user can choose to encrypt a specific file or a directory. An encrypted directory does not have any encrypted data, but any file or directory that is created in the directory will be encrypted. An encrypted file or directory has a special flag set in the $STANDARD_INFORMATION attribute, and each attribute that is encrypted will have a special flag set in its attribute header.
Cryptography Basics
Before we get into how cryptography is implemented in NTFS, I will give a brief overview of basic cryptographic concepts. Encryption is a process that uses a cryptographic algorithm and a key to transform plaintext data to ciphertext data. Decryption is a process that uses a crypgraphic algorithm and a key to transform ciphertext data to plaintext data. If someone is shown the ciphertext data, they should not be able to determine the plaintext data without knowing the key.
There are two categories of cryptographic algorithms: symmetric and asymmetric. A symmetric algorithm uses the same key to encrypt and decrypt data. For example, the key "spot" could be used to encrypt the plaintext into ciphertext, and the same key could be used to decrypt the ciphertext into plaintext. Symmetric encryption is very fast, but it is difficult when sharing the ciphertext data. If we encrypt a file with symmetric encryption and want multiple people to access it, we need to either encrypt it with a key that everyone knows or make a copy of the file for each user and encrypt each with a key that is unique to that user. If we use one key for everyone, it is difficult to revoke access from a user without changing the key. If we encrypt it for every user, we waste a lot of space.
Asymmetric encryption uses one key for encryption and a different key for decryption. For example, the key "spot" could be used to encrypt the plaintext into ciphertext, and the key "felix" could be used to decrypt the ciphertext. The most common use of asymmetric encryption is where one of the keys is made public, such as "spot," and the other is kept private, such as "felix." Anyone can encrypt data with the public key, but it can be decrypted with only the private key. Obviously, a real situation would use keys that are much longer than "spot" and "felix." In fact, they are typically over 1,024-bits long.
NTFS Implementation
When an NTFS $DATA attribute is encrypted, its contents are encrypted with a symmetric algorithm called DESX. One random key is generated for each MFT entry with encrypted data, and it is called the file encryption key (FEK). If there are multiple $DATA attributes in the MFT entry, they are all encrypted with the same FEK.
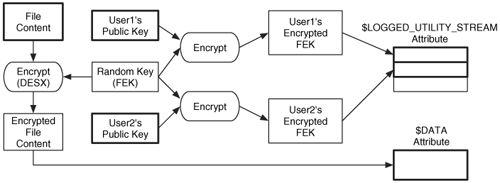
The FEK is stored in an encrypted state in the $LOGGED_UTILITY_STREAM attribute. The attribute contains a list of data decryption fields (DDF) and data recovery fields (DRF). A DDF is created for every user who has access to the file, and it contains the user's Security ID (SID), encryption information, and the FEK encrypted with the user's public key. A data recovery field is created for each method of data recovery, and it contains the FEK encrypted with a data recovery public key that is used when an administrator, or other authorized user, needs access to the data. We can see this process in Figure 11.11.
Figure 11.11. Encryption process starting with file content and public keys and ending with encrypted content and encrypted keys.
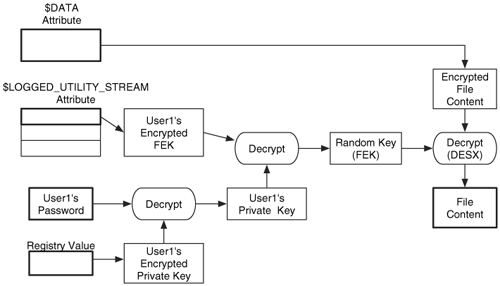
To decrypt a $DATA attribute, the $LOGGED_UTILITY_STREAM attribute is processed and the user's DDF entry is located. The user's private key is used to decrypt the FEK, and the FEK is used to decrypt the $DATA attribute. When access is revoked from a user, her key is removed from the list. A user's private key is stored in the Windows registry and encrypted with a symmetric algorithm that uses her login password as the key. Therefore, the user's password and the registry are needed to decrypt any encrypted files that are encountered during an investigation. This process is shown in Figure 11.12.
Figure 11.12. Decryption process starting with encrypted content, keys, and a user password, and ending with the decrypted content.
Several security tools can perform a brute force attack against a user's login password, and this can be used to decrypt the data. Unencrypted copies of file content might also exist in unallocated space if only some directories and files were encrypted. In fact, there is a small flaw in the NTFS design because it creates a temporary file named EFS0.TMP and it contains the plaintext version of the file being encrypted. After the OS finishes encrypting the original file, it deletes the temporary file, but the contents are not wiped. Therefore, a plaintext version of the file exists, and recovery tools might be able to recover the file if its MFT entry has not been reallocated. The swap space or page file might also provide copies of unencrypted data. It has been reported that if the administrator, domain controller, or other account that is configured as the recovery agent is compromised, any file can be decrypted because that account has access to all files [Microsoft 1999].
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
- Key #1: Delight Your Customers with Speed and Quality
- Key #2: Improve Your Processes
- When Companies Start Using Lean Six Sigma
- Making Improvements That Last: An Illustrated Guide to DMAIC and the Lean Six Sigma Toolkit
- The Experience of Making Improvements: What Its Like to Work on Lean Six Sigma Projects
