File System Category
The file system category of data includes the general layout and size information of the file system. This section covers where the data are located in UFS and how they can be analyzed.
Overview
UFS has three types of data structures that store the file system category of data: the superblock, the cylinder group summary, and the group descriptor. The superblock is located in the beginning of the file system and contains the basic size and configuration information. The superblock references an area of the file system called the cylinder group summary area, which gives a summary of the cylinder group usage. Each cylinder group has a group descriptor data structure that provides details the group. We will now examine each of these data structures in more detail.
Superblock
The UFS superblock contains basic information, such as the size of each fragment and the number of fragments in each block. It is here that we will also learn how big each cylinder group is and where the various data structures are inside each group. With these values, we can determine the layout of the file system. The superblock also might contain a volume label and the time that the file system was last mounted. The UFS superblock plays the same role as the superblock in ExtX, but the layout and non-essential data are different.
The UFS superblock is located somewhere in the start of the file system. With removable media, it could start in the first sector. A UFS1 superblock is typically located 8 KB from the start of the file system, and a UFS2 superblock is typically located 64 KB from the start. It is also possible for the UFS2 superblock to exist at 256 KB from the start of the file system, but this is not the default. Backup copies of the superblock can be found in each of the cylinder groups.
UFS1 and UFS2 use slightly different data structures, but both are over 1 KB in size and contain nearly 100 fields. The difference between the UFS1 and UFS2 superblocks is that the UFS2 version includes 64-bit versions of the size and date fields, which were added to the end of the data structure. The unused 32-bit fields are ignored and not reused.
General bookkeeping information is also stored in the superblock, such as the total number of free inodes, fragments, and blocks. From the superblock, we can find the location of the cylinder group summary area. This area contains a table with an entry for each cylinder group and the entry documents the number of free blocks, fragments, and inodes. As we will later see, this information also exists in the group descriptor of each group.
The superblock contains disk geometry information that was used to most efficiently organize and optimize a file system. It also contains many variations of a single value so that the OS does not have to compute the variation every time. For example, the size of a block is given in both bytes and in fragments. Further, the bitwise mask and shift values are also given so that a byte address can be converted to its block address and vice versa. Theoretically, only one of these values needs to exist and the others can be calculated. Many of the fields are non-essential, and in this section I will focus on the essential data and the non-essential data that could contain evidence.
The details of the data structures can be found in Chapter 17. Both UFS1 and UFS2 superblocks are given with an example file system image.
Cylinder Group Descriptor
As previously stated, the file system is organized into cylinder groups. All the groups, except for maybe the last, are the same size, and each contains a group descriptor data structure that describes the group. The first group starts at the beginning of the file system, and the number of fragments in each group is given in the superblock. In addition to the group descriptor, each group also contains an inode table and a backup copy of the superblock.
The UFS group descriptor is much larger than its ExtX counter part, although much of it is non-essential data. The group descriptor is allocated a full block and has a combination of standard fields and a wide-open area that can be used for various tables. The standard fields provide bookkeeping information and describe how the latter part of the block is organized. Bookkeeping information exists to make the allocation of files more efficient, such as the location of the last allocated block, fragment, and inode. Summary information about the number of free blocks, fragments, and inodes is also given, but it should be the same as the values in the cylinder group summary area. The group descriptor also contains the time of the last write to the group.
The latter part of the group descriptor contains bitmaps for the inodes, blocks, and fragments in the group. It also contains tables that help find consecutive fragments and blocks of a given size. The starting location of each of these data structures is given as a byte offset that is relative to the start of the group descriptor, and the size of the data structure must typically be calculated. Figure 16.2 shows how a group descriptor could be laid out. The specific data structures and layout are given in the next chapter.
Figure 16.2. Layout of group descriptor with the standard fields and then bitmaps and other tables in a wide-open area.
With ExtX, we saw that the second block of each group always had a table of group descriptors. With UFS, the location of the group descriptor, inode table, and backup superblock is specific to each file system, and the offsets are given in the superblock. For example, the inode table could start 32 fragments from the start and the group descriptor 16 fragments from the start. UFS1 adds an additional twist because the offsets are relative to a base location that changes for each cylinder group. For example, if the inode table has an offset of 32 fragments, it could be 32 fragments from the start of group 0, 64 fragments from the start of group 1, and 96 fragments from the start of group 2. The reason the data are staggered is to reduce the impact of physical damage to a platter in older disks.
Cylinder groups are so named because they were aligned on cylinder boundaries. Older hard disks had the same number of sectors per track, which meant that the first sector of every group was on the same platter. To reduce the effect of a hard disk error, the administrative data are staggered so that not every copy of the superblock is on the same platter. Newer hard disks do not have the same number of sectors in each cylinder, so this is not an issue, and UFS2 no longer staggers the data.
The "base" location for each group is calculated using two values from the superblock. The superblock defines a cycle value c and a delta value d. The base increases by d for every group and returns to the beginning after c groups. For example, the base might increase by 32 fragments for every group and then start at an offset of 0 after 16 groups.
Figure 16.3 shows an example of a UFS1 and a UFS2 file system. The UFS1 file system has administrative data with a cycle of 3 and the UFS2 file system has the data at a constant offset for each group. The fragments before and after the administrative data can be used to store file content.
Figure 16.3. UFS1 with five groups and staggering administrative data and UFS2 with five groups and administrative data at a constant offset.
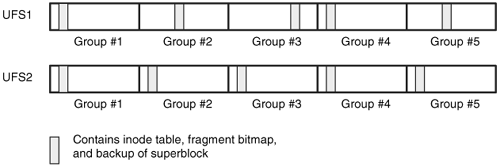
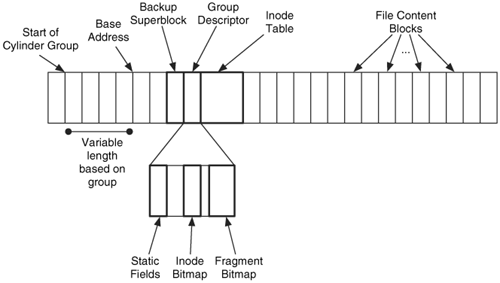
Figure 16.4 shows an example layout of a group. Its base address is located several blocks inside the group, and the backup superblock, group descriptor, and inode table all follow in consecutive order. Inside the group descriptor are bitmaps and the standard data structure fields. All other fragments are for file and directory content.
Figure 16.4. An example layout of a UFS1 cylinder group. The base address is a variable number of blocks from the start of the group, and the bitmaps are a static distance from the base.
Boot Code
If a UFS file system contains the OS kernel, it needs boot code. The boot code is located in the first sector of the file system and can continue until the superblock or disk label data structure. To fully understand the layout of UFS, it might be helpful to refer back to Chapter 6, "Server-based Partitions."
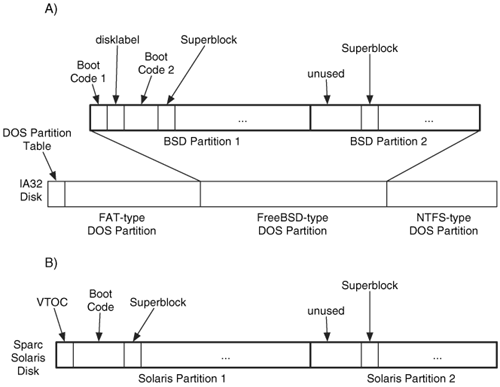
BSD and Solaris systems have their own partitioning systems. An IA32 (i.e., x86/i386) BSD system will have one DOS partition and one or more BSD partitions inside of it. The BSD partition locations are defined by the disk label structure, which is located in sector 1 of the DOS partition. The boot code is located in sector 0 and then in sectors 2 to 15. If the file system is UFS1, the superblock will be in sector 16, and if the file system is UFS2, the superblock will be in sector 128. If the file system is UFS2, the boot code might also occupy additional sectors.
An i386 Solaris system is similar where it will have two DOS partitions. One is small and contains only boot code. The other contains the file systems and has a Volume Table of Contents (VTOC) data structure in sector 0. A disk for a Sparc Solaris system has a VTOC in sector 0 of the disk and the boot code in sectors 1 to 15. Newer Sparc Solaris systems might use an EFI partition table instead of a VTOC.
File systems that do not contain boot code will not use the sectors before the superblock. Figure 16.5(A) shows an example IA32 FreeBSD disk and Figure 16.5(B) shows an example Sparc Solaris disk.
Figure 16.5. Examples of A) an IA32 system with three DOS partitions and two BSD partitions inside the FreeBSD partition and B) a Sparc Solaris disk with two Solaris partitions in it.
Example Image
To close this section, I will run the fsstat tool from The Sleuth Kit (TSK) on the UFS1 image. We will be using this example image later in this chapter, and it is used for the manual analysis in the next chapter. The fsstat output is much larger that what is shown here because it details every cylinder group, but the relevant parts are shown.
# fsstat f openbsd openbsd.dd FILE SYSTEM INFORMATION ---------------------- File System Type: UFS 1 Last Written: Tue Aug 3 09:14:52 2004 Last Mount Point: /mnt METADATA INFORMATION ---------------------- Inode Range: 0 - 3839 Root Directory: 2 Num of Avail Inodes: 3813 Num of Directories: 4 CONTENT INFORMATION ---------------------- Fragment Range: 0 - 9999 Block Size: 8192 Fragment Size: 1024 Num of Avail Full Blocks: 1022 Num of Avail Fragments: 16 CYLINDER GROUP INFORMATION ---------------------- Number of Cylinder Groups: 2 Inodes per group: 1920 Fragments per group: 8064 Group 0: Last Written: Tue Aug 3 09:14:33 2004 Inode Range: 0 - 1919 Fragment Range: 0 - 8063 Boot Block: 0 - 7 Super Block: 8 - 15 Super Block: 16 - 23 Group Desc: 24 - 31 Inode Table: 32 - 271 Data Fragments: 272 - 8063 Global Summary (from the superblock summary area): Num of Dirs: 2 Num of Avail Blocks: 815 Num of Avail Inodes: 1912 Num of Avail Frags: 11 Local Summary (from the group descriptor): Num of Dirs: 2 Num of Avail Blocks: 815 Num of Avail Inodes: 1912 Num of Avail Frags: 11 Last Block Allocated: 392 Last Fragment Allocated: 272 Last Inode Allocated: 7 [REMOVED]
This output shows us the general information, such as block size, fragment size, and number of inodes. We also get a breakdown of each cylinder group with respect to what fragments are in each group and which resources were last allocated. This output merges the data from the superblock, the cylinder group summary area, and the group descriptors. For example, if we are given a block address, we can determine to which group it belongs. We also can identify where the inode table and group descriptor for each group are located. This is important for UFS1 where they are located at different offsets for each group.
Notice that there are two superblocks in the first group. The first one is because there is always a superblock in sector 16 (which is block 8 in this file system). The second one is because every cylinder group has a backup copy located at an offset of 16 fragments.
Analysis Techniques
Analysis of the file system category involves locating and processing the general file system information so that additional analysis techniques can be applied. With a UFS file system, the first step is to locate the superblock at one of the standard locations. Using the data in the superblock, we can find the locations of each cylinder group and data block. Backup copies of the superblock can be found in each cylinder group.
To locate the group descriptor for a specific group, we need to use the offset location given in the superblock and add it to the group's base address. The base address for a UFS2 group is the start of the group, but it staggers for a UFS1 cylinder group. The starting location can be calculated using the delta and cycle values in the superblock. We will use the group descriptor when determining the allocation status of the group's resources.
The last relevant data structure is located in the cylinder group summary area. Its address is given in the superblock, and it contains a table of usage information for each cylinder group. We can use this to get basic information about a group.
Analysis Considerations
The file system category of data will not typically include much evidence of an incident. With UFS, there is a lot of non-essential data in this category, and detecting hidden data is further complicated because the essential and non-essential data are intertwined. There also could be unused space at the end of the block allocated to a superblock, cylinder group summary area, or group descriptor. Compare the size of the file system with the size of the volume to find volume slack.
There is a lot of bookkeeping information in the superblock, group descriptors, and cylinder group summary area. If an incident occurred very recently, you might be able to draw conclusions about where files were deleted from and which file was last allocated. Having multiple copies of this data also allows them to be compared if tampering is suspected. Backup copies of the superblock can be found in each cylinder group. You can search for the backup copies using the data structure's signature value.
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
- Article 314 Outlet, Device, Pull, and Junction Boxes; Conduit Bodies; Fittings; and Handhole Enclosures
- Article 362 Electrical Nonmetallic Tubing Type ENT
- Article 398 Open Wiring on Insulators
- Article 500 Hazardous (Classified) Locations, Classes I, II, and III, Divisions 1 and 2
- Example No. D8 Motor Circuit Conductors, Overload Protection, and Short-Circuit and Ground-Fault Protection
