RAID
RAID stands for Redundant Arrays of Inexpensive Disks and is commonly used in high-performance systems or in critical systems. RAID was first proposed in the late 1980s as a method of using inexpensive disks to achieve performance and storage capacities similar to the expensive high-performance disks [Patterson, et al. 1988]. The main theory behind RAID is to use multiple disks instead of one in order to provide redundancy and improve disk performance. A hardware controller or software driver merges the multiple disks together, and the computer sees a large single volume.
RAID used to be found only in high-end servers but is now becoming more common on desktop systems. Microsoft Windows NT, 2000, and XP have the option to provide the user with some level of RAID. In this section, we will first describe the technology involved with RAID systems, and then we will discuss how to acquire or analyze a RAID system. A RAID volume can be partitioned using any of the methods shown in Chapter 5, "PC-based Partitions," and Chapter 6, "Server-based Partitions."
RAID Levels
There are multiple levels of RAID, and each level provides a different amount of reliability and performance improvements. In this section, we will cover how six of the different RAID levels work. A RAID volume is the volume created by the hardware or software that combines the hard disks.
RAID Level 0 volumes use two or more disks, and the data is striped across the disks in block-size chunks. When data are striped, consecutive blocks of the RAID volume are mapped to blocks on alternate disks. For example, if there are two disks, RAID block 0 is block 0 on disk 1, RAID block 1 is block 0 on disk 2, RAID block 2 is block 1 on disk 1, and RAID block 3 is block 1 on disk 2. This can be seen in Figure 7.1 where 'D0,' 'D1,' 'D2,' and 'D3' are blocks of data. A system would use this level of RAID for performance reasons and not redundancy because only one copy of the data exists.
Figure 7.1. A RAID Level 0 volume with two disks and data striped across them in block-sized chunks and a RAID Level 1 volume with two disks and data mirrored between them.
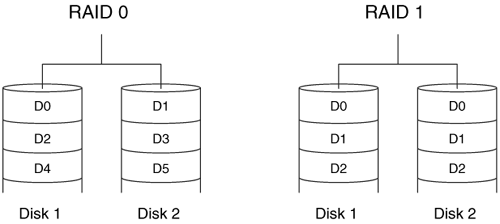
RAID Level 1 volumes use two or more disks and mirror the data. When data are written to one disk, they are also written to the other disk, and both disks contain the same allocated data. The two disks may contain different data in the sectors that are not used in the RAID volume. If there is a disk failure, the other disk can be used for recovery. For example, if we have two disks in a RAID Level 1 volume, RAID block 0 is block 0 on both disks 1 and 2, RAID block 1 is block 1 on both disks 1 and 2, etc. This also can be seen in Figure 7.1.
RAID Level 2 volumes are rare and use error-correcting codes to fix any incorrect data when it is read from the disks. The data are striped across many disks using bit-sized chunks, and additional disks contain the error-correcting code values.
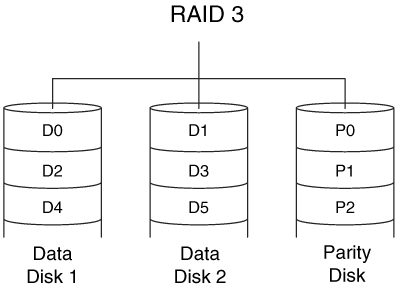
RAID Level 3 volumes require at least three disks and have a dedicated parity disk. The parity disk is used to recognize errors in the other two disks or to recreate the contents of a disk if it fails. An inefficient example of parity is traditional addition. If I have two values, 3 and 4, I can add them and my parity is 7. If at any time the two values do not add to 7, I know that there is an error. If one of the values is lost, I can recover it by subtracting the value that still exists from 7.
With RAID Level 3, the data are broken up into byte-sized chunks and striped, or alternated, across the data disks. A dedicated parity disk contains the values needed to duplicate the data to rebuild any data that is lost when one of the disks fails. This level is similar to what we saw with Level 0, except that the striping size is much smaller (bytes instead of blocks) and there is a dedicated parity disk. An example with two data disks and one parity disk can be found in Figure 7.2.
Figure 7.2. A RAID Level 3 volume with two data disks and one parity disk.
A common method of calculating the parity information is by using the "exclusive or" (XOR) operation. The XOR operator takes two one-bit inputs and generates a one-bit output using the rules found in Table 7.1. The XOR of two values larger than one bit can be calculated by independently applying the XOR rules to each set of bits.
|
Input 1 |
Input 2 |
Output |
|---|---|---|
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |
The XOR operator is useful because if you know any of the two of the input or output values, you can calculate the third value. This is similar to adding two numbers and then subtracting one to get the original. For example, let there be three data disks and one parity disk. The data disks have the values: 1011 0010, 1100 1111, and 1000 0001. The parity for these values would be calculated as follows:
(1011 0010 XOR 1100 1111) XOR 1000 0001 (0111 1101) XOR 1000 0001 1111 1100
The byte 1111 1100 would be written to the parity disk. If the second disk failed, its byte could be created as follows:
1111 1100 XOR (1011 0010 XOR 1000 0001) 1111 1100 XOR (0011 0011) 1100 1111
We have easily reconstructed the byte for the second disk.
RAID Level 4 volumes are similar to Level 3, except that the data is striped in block-sized chunks instead of byte-sized chunks. Level 4 uses two or more data disks and a dedicated parity disk, so its architecture is the same as shown in Figure 7.2.
RAID Level 5 volumes are similar to Level 4, but they remove the bottleneck associated with the parity disk. In Level 5, there is no dedicated parity disk, and all the disks contain both data and parity values on an alternating basis. For example, if there are three disks, RAID block 0 is block 0 of disk 1, RAID block 1 is in block 0 of disk 2, and the corresponding parity block is block 0 of disk 3. The next parity block will be block 1 of disk 2 and will contain the XOR of block 1 of disks 1 and 3. This can be seen in Figure 7.3.
Figure 7.3. A RAID Level 5 volume with three disks and distributed parity data.
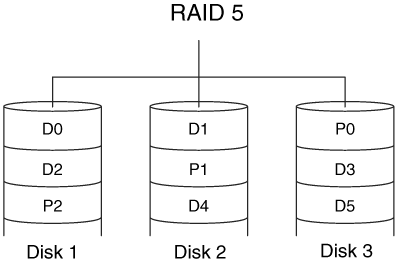
Level 5 is one of the more common forms of RAID and requires at least three disks. There are many other RAID levels that are not very common. They combine multiple RAID levels and make analysis even harder.
Hardware RAID
One method of creating a RAID volume is to use special hardware. This section will examine how this is done and how to acquire such a system.
Background
A hardware RAID implementation can come in two major forms: as a special controller that plugs into one of the buses or as a device that plugs into a normal disk controller, such as ATA, SCSI, or Firewire. In either case, the hard disks plug into a special piece of hardware and, in general, the computer sees only the RAID volume and not the individual disks. Figure 7.4 shows the connections between the disks, controller, and volume.
Figure 7.4. A hardware controller makes the disks look like one for the OS.
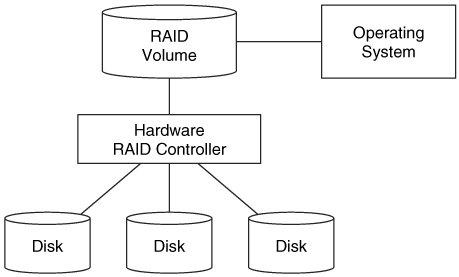
If a special RAID controller is being used, the computer probes for the controller when booting. With many IA32 systems, the BIOS for the RAID controller displays messages on the screen, and the user can enter a setup screen to configure the controller and disks. The OS needs hardware drivers for the RAID controller. Disks that are created with one controller typically cannot be used with another controller. If a special device is being used that goes in between the normal disk controller and the hard disks, no special drivers are needed.
Acquisition and Analysis
There are many types of RAID hardware implementations, so we will only provide some basic guidelines here. To analyze the RAID volume, it is easiest to acquire the final RAID volume as though it were a normal single disk and use the typical file system and partition analysis tools. One method of performing this is to boot the suspect system with a bootable Linux, or similar, CD that has drivers for the RAID controller. You can then use dd, or a similar command, to acquire the final RAID volume. Note that some RAID volumes are very large; therefore, you will need a large amount of disk space on which to store the image (or maybe your own RAID volume).
Different bootable Linux CDs have drivers for different RAID controllers, so check your favorite CDs and make a list of which controllers they support. You may need to make your own CD or bring several CDs with you so that you are prepared.
If you do not have the needed drivers for the RAID controller for an onsite acquisition, the individual disks and controller should be taken back to the lab. Not much has been published about the layout of data on the individual disks, so it could be difficult to merge the disks without the controller.
The RAID volume may not use all sectors on a disk and it is possible that the unused sectors contain hidden data. Therefore, acquiring the contents of each disk in addition to the RAID volume is the safest, although not always the easiest, solution. If you do not know the layout of the data, it could be difficult to identify the unused sectors of the disk. If you have specific keywords for which you are looking, the individual disks can be searched, in addition to searching the RAID volume.
Software RAID
RAID volumes also can be implemented in software. This section will examine how this is done and how to acquire a software RAID volume.
Background
With a software RAID, the operating system has special drivers that merge the individual disks. In this scenario, the OS sees the individual disks, but may show only the RAID volume to the user. The individual disks can typically be accessed through raw devices in UNIX system or through device objects in Microsoft Windows. Most operating systems now offer some levels of RAID, including Microsoft Windows NT, 2000, and XP; Apple OS X; Linux; Sun Solaris; HP-UX; and IBM AIX. Software RAID is not as efficient as hardware RAID because the CPU must be used to calculate the parity bits and split the data. We can see the connections in Figure 7.5.
Figure 7.5. With software RAID, the OS merges the disks and it has access to each disk.
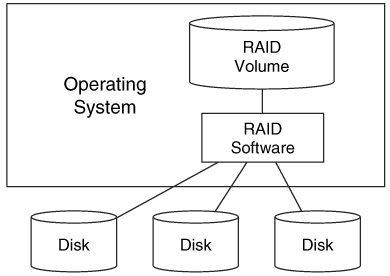
In Windows 2000 and XP, the Logical Disk Manager (LDM) controls the RAID volumes. The LDM requires that disks be formatted as dynamic disks, which are different from the DOS-based partitions that we previously saw in Chapter 5, "PC-Based Partitions." The LDM can create RAID level 0 (striping), RAID level 1 (mirroring), and RAID level 5 (striping with parity) volumes, although RAID levels 1 and 5 are available only with the server version of Windows. A dynamic disk can be used for more than one RAID volume, but that is unlikely if the system is using RAID for performance or redundancy reasons. All configuration information for the Windows RAID volume is stored on the disks and not on the local system. We will discuss LDM in much more detail later in the chapter when we discuss disk spanning.
In Linux, RAID is achieved with the multiple device (MD) kernel driver. The disks in a Linux RAID do not have to be formatted in any special way and can be normal DOS-partitioned disks. The configuration information is stored on the local system in a configuration file, /etc/raidtab by default. The resulting RAID volume gets a new device that can be mounted as a normal disk. The MD driver supports RAID Level 0 (striping), RAID Level 1 (mirroring), and RAID Level 5 (striping with parity). There is an optional "persistent superblock" option that places configuration information on the disk so that it can be used in other systems besides the original system (which makes offsite analysis easier).
Acquisition and Analysis
Analysis and acquisition of software RAID is similar to a hardware RAID. Based on current technology, the easiest scenario is to acquire the RAID volume so that the normal file system tools can be used. Unlike hardware RAID, there are some analysis tools that can merge the individual disks together.
With software RAID, you may not need the original software to recreate the RAID volume. For example, Linux has support for Windows Logical Disk Management (LDM) and may be able to properly merge the Windows disks. Not all Linux kernels ship with LDM enabled, but you can enable it by recompiling the kernel. If you are using Microsoft Windows to create the RAID volume, apply hardware write blockers to prevent overwriting data.
Let's look at a Windows LDM example with Linux. When you boot a Linux kernel with support for LDM, a device is created for each of the partitions in the RAID. You have to edit the /etc/raidtab file so that it describes the RAID setup and partitions. For example, the following is a configuration file for a Windows LDM RAID Level 0 (striping) with two partitions (/dev/hdb1 and /dev/hdd1) using 64KB blocks:
# cat /etc/raidtab raiddev /dev/md0 raid-level 0 nr-raid-disks 2 nr-spare-disks 0 persistent-superblock 0 chunk-size 64k device /dev/hdb1 raid-disk 0 device /dev/hdd1 raid-disk 1
Using this configuration file, the device /dev/md0 could be mounted read-only or imaged using dd. Test the process before an incident happens and make backup copies of real disks during an incident. We will cover the process of using Linux with Windows LDM in more detail in the "Disk Spanning" section. A similar process is used for making a Linux MD software RAID on the acquisition system. If you can copy the raidtab file from the original system, its contents can be used as a base to make the RAID volume on the acquisition system.
EnCase from Guidance Software and ProDiscover from Technology Pathways can import the disks from a Windows RAID volume and analyze them as though they were a single volume. This is actually the better long-term method of analyzing the data because it provides access to data that may be hidden in the individual disks and would not be acquired by collecting only the RAID volume. There is always a risk, though, of using software, in either Linux or third-party tools, that does not use an official specification because it could have errors and not produce an accurate version of the original RAID volume.
General Analysis Comments
Investigating a system with a RAID volume can be difficult because they are not frequently encountered and not every implementation is the same. Be very careful when trying different acquisition techniques that you do not modify the original disks in the process. Use hardware write-blockers or the read-only jumper on the individual hard disks to prevent modifications. It may also be useful to make images of the individual disks before you make an image of the full RAID volume. The individual disk images may contain hidden data that are not in the final RAID volume. No cases involving hidden RAID data have been published, but it could be possible depending on whom you are investigating. It is also possible that the entire disk is not being used for the RAID. Some RAID systems use only part of the hard disk so that it is easier to replace the disk if it fails. For example, only 40GB of each individual disk in the RAID volume could be used, regardless if each individual disk is 40GB or 80GB. The unused area may contain data from a previous usage or be used to hide data.
Summary
This section has given an overview of RAID. RAID is common in high-end servers and is becoming more common in desktop systems that need performance or large amounts of disk space. The low-level details were not given because they vary by implementation and there is no single standard. More details will be given later in the "Disk Spanning" section because many systems incorporate software RAID in their volume management support.
The key concept for investigations is to practice acquiring RAID systems. If possible, it is easiest to acquire the full RAID volume at the scene and then perform analysis using standard tools. The problems with this approach are that it requires a very large disk to save the data to, and there could be data on the individual disks that are not shown in the final RAID volume. Therefore, it is safest to always acquire the individual disks as well.
Part I: Foundations
Digital Investigation Foundations
- Digital Investigation Foundations
- Digital Investigations and Evidence
- Digital Crime Scene Investigation Process
- Data Analysis
- Overview of Toolkits
- Summary
- Bibliography
Computer Foundations
Hard Disk Data Acquisition
- Hard Disk Data Acquisition
- Introduction
- Reading the Source Data
- Writing the Output Data
- A Case Study Using dd
- Summary
- Bibliography
Part II: Volume Analysis
Volume Analysis
PC-based Partitions
Server-based Partitions
Multiple Disk Volumes
Part III: File System Analysis
File System Analysis
- File System Analysis
- What is a File System?
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- Application-level Search Techniques
- Specific File Systems
- Summary
- Bibliography
FAT Concepts and Analysis
- FAT Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
FAT Data Structures
- FAT Data Structures
- Boot Sector
- FAT
- Directory Entries
- Long File Name Directory Entries
- Summary
- Bibliography
NTFS Concepts
- NTFS Concepts
- Introduction
- Everything is a File
- MFT Concepts
- MFT Entry Attribute Concepts
- Other Attribute Concepts
- Indexes
- Analysis Tools
- Summary
- Bibliography
NTFS Analysis
- NTFS Analysis
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
NTFS Data Structures
- NTFS Data Structures
- Basic Concepts
- Standard File Attributes
- Index Attributes and Data Structures
- File System Metadata Files
- Summary
- Bibliography
Ext2 and Ext3 Concepts and Analysis
- Ext2 and Ext3 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- Application Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
Ext2 and Ext3 Data Structures
- Ext2 and Ext3 Data Structures
- Superblock
- Group Descriptor Tables
- Block Bitmap
- Inodes
- Extended Attributes
- Directory Entry
- Symbolic Link
- Hash Trees
- Journal Data Structures
- Summary
- Bibliography
UFS1 and UFS2 Concepts and Analysis
- UFS1 and UFS2 Concepts and Analysis
- Introduction
- File System Category
- Content Category
- Metadata Category
- File Name Category
- The Big Picture
- Other Topics
- Summary
- Bibliography
UFS1 and UFS2 Data Structures
- UFS1 and UFS2 Data Structures
- UFS1 Superblock
- UFS2 Superblock
- Cylinder Group Summary
- UFS1 Group Descriptor
- UFS2 Group Descriptor
- Block and Fragment Bitmaps
- UFS1 Inodes
- UFS2 Inodes
- Directory Entries
Summary
Bibliography
Bibliography
EAN: 2147483647
Pages: 184
