Clustered JMS
Even though a JMS server is pinned to a single WebLogic instance, WebLogic is able to provide a clustered implementation of JMS that offers scalability and load balancing at various levels of client access, as well as high-availability features to ensure that a pinned service such as the JMS server doesn't present a single point of failure to dependent JMS applications. WebLogic's JMS implementation is able to achieve this through a number of features:
- JMS clients can remain unaware of the exact locations of the JMS resources deployed to the cluster. The JNDI name of a JMS destination is made available to all servers in the cluster because it is bound in the cluster-wide JNDI tree. An external client need only use the JNDI name to look up the desired location, without consideration of which physical server hosts the destination. This provides cluster-wide, transparent access to the destinations.
- JMS connection factories can be targeted to all members of a cluster, even to those that do not host a JMS server. When a connection factory produces a connection, it automatically will target one of the servers hosting a connection factory using a load-balancing scheme. The servers that host these connections transparently route traffic through to the required destinations. This allows WebLogic to transparently load-balance remote JMS connections to the cluster, and also provide failover in the event of a server failure.
- WebLogic lets you configure multiple JMS destinations (queues and topics) as members of a distributed destination. What appears to be a single destination to a client actually is distributed across multiple JMS servers within a cluster. A producer or consumer is then able to send and receive messages using this distributed destination. WebLogic simply distributes the messaging load across the members of this distributed destination set. If a JMS destination becomes unavailable due to server failure, WebLogic diverts the traffic among the remaining available members of the distributed destination. Thus, distributed destinations contribute to load balancing and failover.
- WebLogic supports several load-balancing algorithms for distributing the load of incoming client JMS connections among the servers in the cluster, and also for distributing the messaging load between the members of a distributed destination. In addition, WebLogic is able to use various affinity-based heuristics to disable load balancing between the members of the distributed destination, and thus avoid extra network hops that may be needed to reach a member destination on another server in the cluster.
- Because WebLogic JMS is a "singleton" service in the cluster, it need not be enabled on all members of the cluster. Typically, it will be pinned to a single server in the cluster and then will be accessible to all JMS clients of that cluster. To ensure that the pinned JMS service is available even in the event of a failure, WebLogic lets you migrate a JMS server and all its destinations to another clustered server. For each JMS server, you can configure one or more migratable targets i.e., a preferred list of servers in the cluster to which the JMS server can be migrated.
The next section explores these concepts, and how they combine to form a powerful platform for building scalable, highly available JMS solutions.
8.5.1 JMS Connections and Connection Factories
JMS clients use connection factories to obtain connections to a JMS server. There is an important interplay between connections and connection factories when these objects are used in a clustered environment. When a JMS connection factory is targeted to multiple servers in the cluster, the following occurs:
- For external clients, the connection factory can provide support for load balancing and failover.
- The servers that host the connection factory provide connection routing.
These features form the bedrock of WebLogic's clustered JMS implementation. Distributed destinations provide the next level of load-balancing and failover support for JMS producers and consumers. We will return to connections and connection factories again, after examining distributed destinations.
8.5.1.1 Load balancing
When an external client creates a JMS connection using a connection factory for example, with the QueueConnectionFactory.createQueueConnection( ) method the connection factory uses a load-balancing strategy to decide which server in the cluster should host the JMS connection. In fact, a choice is made between the available servers in the cluster whenever a connection factory is looked up and whenever a JMS connection is created. For example, if a remote JMS client uses a connection factory that is targeted to two servers in a cluster, Server1 and Server2, then the JMS connections created by the client (or any other client using the same connection factory) will alternate between the two servers.
On the other hand, if a server-side application uses its local JNDI context to look up a connection factory that is targeted to the same server that hosts the application, the context factory will not load-balance any of the connection requests from the application. Instead, the application will use a local connection that simply routes all JMS requests through the local server. This optimization helps minimize the cost of making remote network calls.
You can configure the default load-balancing scheme for a cluster using the Administration Console. Select the cluster from the left pane and then adjust the value of the Default Load Algorithm from the General tab. The default load algorithm impacts all clustered remote resources (e.g., stateless session EJBs) and not just JMS connections. By default, WebLogic uses a round-robin scheme.
8.5.1.2 Connection routing
It is surprising to note that connection load balancing does not involve the JMS servers at all. Connection factories can be targeted independently of the JMS servers. Furthermore, a JMS connection, which can route traffic to the appropriate JMS servers, will always be returned from a clustered server that hosts the connection factory, regardless of whether the server hosts a JMS server. All JMS traffic will be routed over this connection to the JMS server hosting the intended destinations. This routing is performed behind the scenes and is transparent to clients. However, it also may cause needless traffic.
Figure 8-2 shows an external client that (1) establishes a connection with a cluster, (2) looks up a connection factory, (3) creates a connection using the connection factory, and (4) then tries to access a destination Q1. Because the connection factory is targeted to the cluster, the connections it creates will be load-balanced over all the servers in the cluster. In the figure, the JMS connection has been created to Server 2. Because we want to interact with a destination that lives on Server 1, the connection will route all JMS traffic back to Server 1. Clearly, it would be far more efficient if the connection were returned from the same server that returned the connection factory. Later, we will see how your JMS traffic can avoid this unnecessary hop.
Figure 8-2. Unwanted connection routing
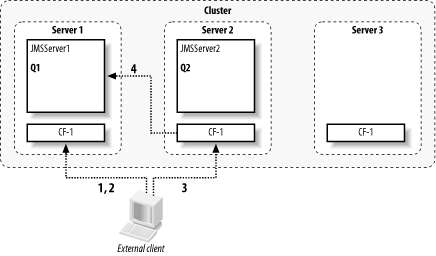
One advantage of the connection routing mechanism is that it provides scalability. If many hundreds of JMS clients are all trying to access the same destination and call on other server-side services, connection routing ensures that the work of maintaining the sockets to the clients is balanced between all of the members hosting connections, and not just the JMS server.
8.5.1.3 Failover
WebLogic's cluster-aware JMS connection factories enable JMS clients to fail over to another member of the cluster. Once a client has obtained a connection factory from one of the servers in the cluster, it will continue to work even if the server that hosts the client's JMS connection goes down. In other words, a JMS client can use the same connection factory instance to obtain a new JMS connection to another cluster member that also hosts the same factory. JMS clients can register an exception listener on the JMS connection to detect any connection failures, and then request a new connection from the connection factory. Because the connection factory maintains an internal list of available WebLogic instances that host the factory, it can dynamically select an alternative WebLogic instance for the JMS connection. All JMS requests are subsequently routed through this newly chosen server in the cluster.
8.5.1.4 Targeting for server-side applications
As we have just seen, the behavior of WebLogic's load-balancing and failover capabilities for a clustered JMS connection factory depends on whether the JMS application runs on a server within the cluster that hosts the JMS servers, or runs as an external JMS client. By judiciously targeting connection factories within a cluster, you can avoid unnecessary connection hops.
For a server-side application, you should ensure that the connection factory is targeted to all servers that host the JMS application, or more conveniently target the connection factory to the entire cluster. In this way, when the server-side application looks up a connection factory, it will be able to find one in its local JNDI tree. As a result, it will use a local connection factory and a local connection. This avoids any unnecessary routing of JMS requests through another server in the cluster.
The downside of not doing this is highlighted if you target the connection factory to only those servers in the cluster that host the JMS destinations needed by your server-side applications. The problem with this approach is that only these servers (the servers hosting the JMS servers) would handle all the connections and the work of routing JMS requests. Furthermore, if the JMS server were migrated to another server, you would have to target the connection factory to the new WebLogic instance.
8.5.1.5 Targeting for external applications
For external JMS clients, it is more optimal to target only the connection factory to the JMS server that hosts the desired destination. This avoids the unnecessary hops for JMS traffic, as illustrated earlier in Figure 8-2. If the client looks up a connection factory that is targeted to a server not hosting the desired destination, it may incur an extra network hop when it tries to interact with the JMS server. Note that if the connection factory is targeted to a subset of the servers in a cluster, external JMS clients still can use the cluster address to look up the JMS factory. All they need to know is the JNDI name of the connection factory. Later, we examine how server affinity can help JMS clients avoid extra network hops when clients need to interact with a distributed destination.
8.5.1.6 Affinity-based load-balancing algorithms
A round-robin-affinity strategy is useful in situations where external clients use a JMS connection factory that is targeted to multiple servers, and not just to the server that hosts the particular destination. If the external client already has established a JNDI context with a particular server in the cluster, the load balancer will favor the same server for the JMS connection factory, if it hosts the factory. In other words, the affinity-based schemes try to use existing connections, and create a new connection only if necessary. Clearly, it also reduces the number of sockets opened between the client and the cluster. Refer to Chapter 14 to learn how to enable affinity-based load balancing for the entire cluster.
8.5.2 Distributed Destinations
In a clustered environment, you would like to be able to distribute the messaging load across several physical destinations hosted on separate JMS servers. WebLogic provides this capability through distributed destinations. A distributed destination is a cluster-specific destination representing one or more physical destinations, typically residing on different JMS servers in the cluster. These physical destinations also are referred to as the members of the distributed destination. Any messages that are sent to this distributed destination are distributed over the actual member destinations. If a JMS server that hosts one of the members of the distributed destination fails, the messages are load-balanced automatically between the remaining JMS destinations that are still alive.
Thus, a distributed destination is a transparent proxy to a number of physical destinations located on JMS servers within a cluster. It is through this proxy that WebLogic is able to provide support for load balancing and failover at the destination level in a clustered environment. Before we examine how to configure a distributed destination, let's take a closer look at the behavior of distributed queues and topics.
8.5.2.1 Using distributed queues
A distributed queue represents a set of physical JMS queues. JMS applications can treat a distributed queue like any ordinary JMS queue, so they can send, receive, and even browse a distributed queue easily. The member queues that comprise the distributed queue can be hosted by any JMS server within the same cluster. When a message is sent to a distributed queue, it is sent to exactly one of its member queues.
A distributed queue provides a great way of distributing the messaging load across physical JMS queues, and so too across consumers of these queues. Any messages that are sent to the distributed queue will end up on exactly one of the member queues, and the choice of the physical queue can be load-balanced. You also can configure a Forward Delay on a member queue so that any messages that arrive at a queue with no consumers are forwarded automatically to another queue that does have consumers. The default forward delay for a queue member is -1, which means that no forwarding occurs if messages arrive at a queue with no consumers.
Whenever a message is sent to a distributed queue, a decision is made as to which queue member will receive the message. Messages are never replicated because each message is sent to exactly one member queue. If a member queue becomes unavailable before a message is received, the message is unavailable until that queue member comes back online. Whenever a consumer registers its interest with a distributed queue, it actually binds to one of its member queues. A load-balancing decision is made when choosing a member from the distributed queue. Once a queue has been selected, the consumer is pinned to that member queue until it subsequently loses access. For instance, a consumer will receive a JMSException if the physical queue to which it was bound becomes unavailable. For synchronous receivers, the exception is returned directly to the JMS client, whereas an asynchronous receiver can register an exception listener with the JMS session, and thereby handle a ConsumerClosedException error. In this way, the consumers are always notified of a failure if the server hosting the queue member dies.
When a JMS client receives such an exception, it should close and re-create its queue receiver. The queue receiver then will be pinned to another available member of the distributed queue, if one exists. Here again, a load-balancing decision will help choose another available member from the distributed queue.
In the same way, if a JMS client attempts to browse a distributed queue, the queue browser is bound to one of the member queues at creation time. The queue browser then is pinned to that physical queue until it loses access. Any further calls to the queue browser will then raise a JMSException. A queue browser can browse only the physical queue to which it is pinned. Even though you've specified a distributed queue, the same queue browser cannot browse messages arriving from other queues in the distributed queue.
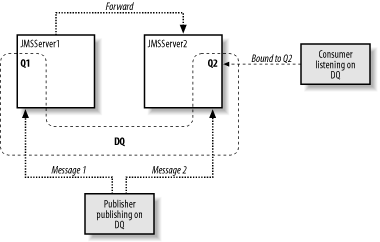
Figure 8-3 summarizes the behavior of distributed queues. Here, a distributed queue, DQ, consists of two member queues, Q1 and Q2. When a consumer is created for the distributed queue, WebLogic pins the consumer to a particular member queue, in this case, Q2. When a producer sends messages to the distributed queue, the messages are balanced across the member queues. Each message is sent to only a single queue member.
Figure 8-3. The behavior of publishers and consumers of a distributed queue
8.5.2.2 Using distributed topics
A distributed topic represents a set of physical topics. Overall, JMS applications can treat a distributed topic like any ordinary JMS topic, so they can publish and subscribe to a distributed topic. The fact that a distributed topic represents a number of physical topics on different JMS servers within a cluster remains transparent to your JMS applications. Any messages that are sent to a distributed topic are then sent to all members of that distributed topic, and hence to all its subscribers. So, unlike a distributed queue, any messages arriving at a distributed topic are copied multiple times, once for each subscriber. In addition, if a JMS application publishes a message to a member of a distributed topic, it is forwarded automatically to all of the other members of that distributed topic!
|

When a message is sent to a distributed topic, WebLogic tries to first forward the message to those member topics that use a persistent store, thereby minimizing potential message loss. If none of the member topics has a persistent messaging store, WebLogic still sends the message using the selected load-balancing algorithm. In fact, any message sent to a distributed topic is then sent to all member topics as follows:
- If the message is nonpersistent and some members of the distributed topic are not available, it is sent to only the available member topics.
- If the message is persistent and some members of the distributed topic are not available, it is stored and forwarded to those unavailable member topics when they become available. The message is persistently stored only if the available topic member(s) use a JMS store.
- Of course, if all the member topics are unreachable, the publisher receives a JMSException when it tries to send the message, regardless of the delivery mode.
In general, we recommend that all JMS servers participating in the distributed destination be configured to use persistent stores. As with distributed queues, a subscriber is pinned to a particular topic when it registers its interest with a distributed topic. A load-balancing decision is made to help choose the member topic to which the subscriber will be bound. The subscriber will remain pinned to the member topic until it loses access to the topic. Depending on whether the subscriber is synchronous or asynchronous, the JMS client can either handle the exception or register an exception listener with the JMS session.
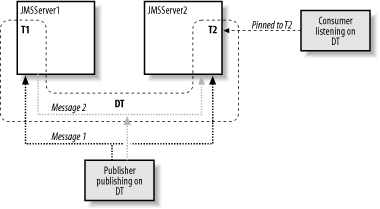
Figure 8-4 summarizes the behavior of distributed topics. A consumer subscribed to the distributed topic, and was subsequently pinned to a member topicin this case, T2. Messages published to the distributed topic then are delivered to all members of the distributed topic.
Figure 8-4. The behavior of publishers and consumers of a distributed topic
8.5.2.3 Creating a distributed destination
The configuration for a distributed destination takes place in the Services/JMS/Distributed Destinations node within the Administration Console. Here you can select the "Configure a new Distributed Topic" link to create a new distributed topic, or the "Configure a new Distributed Queue" link to create a new distributed queue.
For each distributed destination, you should configure the following settings:
Name
Use this setting to provide a unique name for the distributed topic/queue.
JNDI Name
Use this setting to provide a JNDI name for the distributed queue/topic in the cluster-wide JNDI tree. If the destination hasn't been assigned a JNDI name, your JMS clients still can access the distributed queue or topic using the createQueue( ) method on a QueueSession object, or the createTopic( ) method on a TopicSession object.
Load Balancing Policy
Use this setting to determine how producers will distribute their messages across the members of the distributed destination. The valid values for this setting are Round-Robin or Random.
Forward Delay
This setting applies to a distributed queue. Use it to determine the amount of time that a member queue with messages but no consumers will wait before forwarding its messages to other member queues that do have consumers.
Now you can use the Thresholds & Quotas tab to set the message quota limits, and use threshold settings for message paging and flow control, on all members of the distributed queue/topic. Note that these settings will apply only to those physical queues or topics that don't already use a JMS template.
Now that you've configured the distributed queue or topic, you need to create or supply the queues or topics that will belong to the distributed destination. WebLogic provides two ways to set up the members of the distributed destination:
- You can select the Configuration/Members tab to manually include existing physical queues or topics that will be members of the distributed destination. For each member queue or topic, you need only to provide a name, choose from one of the existing physical JMS destinations, and then assign a weight to the member.
- You can use the Auto-Deploy tab to automatically create the physical destinations on selected JMS servers within a cluster that must participate in the distributed destination. If you use this option, you can either choose a cluster and then select the WebLogic instances and the JMS servers that will host the distributed destination, or directly choose the WebLogic instances and JMS servers that will host the distributed destination. Member destinations will then be generated automatically on the selected JMS servers and added to the distributed destination. The names of these destinations will be generated automatically as well. For instance, if a distributed queue MyDQ is targeted to a JMS server called MyJMSServer, then the name for the member queue on that JMS server will be MyDQ@MyJMSServer-1. Once the member destinations have been generated, you can view or edit the list of members from the Configuration/Members tab.
Note that the auto-deploy method is purely a convenience feature, allowing you to more easily generate the member destinations on various JMS servers.
8.5.2.4 Accessing a distributed destination
Suppose a distributed queue called MyDQ has two members, Queue1 and Queue2, each hosted by a separate JMS server within a cluster. You could access the distributed queue as follows:
Queue dQueue = myQueueSession.createQueue("MyDQ");
There is nothing special in this code we simply have located the distributed queue using its logical name. If the distributed queue is assigned the JNDI name jms/MyDQ, you could easily perform a JNDI lookup:
Queue dQueue = (Queue) ctx.lookup("jms/MyDQ");
This emphasizes the fact that distributed destinations largely are transparent to JMS clients. The actual member that is returned depends on the load-balancing algorithm and various heuristics that may apply at that time.
Sometimes it is necessary to access a particular member of a distributed destination. You can do this in one of the following ways:
- If the member destination is assigned a JNDI name, you can look up the destination using this JNDI name.
- Alternatively, you can access a member destination if you know the name of the distributed destination and the name of the JMS server that hosts the member destination. So, to access the physical member Q1 of the distributed queue DQ residing on server JMSServer1, as shown in Figure 8-3, you can look up the member queue as follows:
Queue queue = qSession.createQueue("JMSServer1/DQ");Similarly, to access the physical member topic T1 in Figure 8-4, which is targeted to a JMS server JMSServer1, you can access the member topic on that server as follows:
Topic topic = tSession.createQueue("JMSServer1/DT");An InvalidDestinationException is thrown if a member of the distributed destination does not exist on the requested server. Note that the second approach relies on a proprietary syntax for accessing a member of a distributed destination, and may not be supported by other JMS products.
8.5.2.5 Producer and consumer load balancing
Load balancing is somewhat different depending on whether the JMS client is a consumer or a producer. As a consumer, the choice of which member destination is used is made only once based on the load-balancing scheme set for the distributed destination. After the decision has been made, the consumer is bound to that physical member, and continues to receive messages from that member only, until the consumer or physical member fails. When the consumer subsequently reconnects to the distributed destination, a new physical member is chosen.
As a producer, however, the choice is made each time a message is sent to the distributed destination. However, if the message is to be delivered in a persistent mode, the producer will attempt to find a member destination that is equipped with a persistent JMS store. If none of the physical members has a persistent store, the message is sent to one of the member destinations chosen using the load-balancing scheme configured for the distributed destination. We recommend that you configure all member destinations with a persistent store.
In general, though, producers load-balance on every send( ) or publish( ) operation. You can prevent this behavior and instead configure the producers to make the choice only once, on the first call to send( ) or publish( ). To achieve this, select the connection factory that is being used by the producer from the Administration Console, and then disable the Load Balancing Enabled flag in the Configuration/General tab. Any producers created using this connection factory will be load-balanced only the first time a message is delivered to a distributed destination. All messages are then delivered to this member destination until the producer fails. When the producer subsequently reconnects and attempts to send a message to the distributed destination, a new physical member is chosen.
8.5.2.6 Load-balancing schemes
For any distributed destination, you can set the load-balancing algorithm to either round-robin or random distribution. Each physical destination within the distributed destination set can be assigned a weight. This weight is used as a measure of the destination's ability to handle the messaging load with respect to its peers within the distributed destination. The load-balancing algorithm, together with the destination weights, determine how the messaging load is distributed across the physical destinations.
A round-robin algorithm maintains an ordered list of the physical destinations, and the messaging load is distributed across these destinations one at a time. The list's order is determined by the order in which the destinations are defined within the domain's config.xml file. If the physical destinations have been assigned unequal weights, the member destinations will appear multiple times in the ordered list, depending on their weights. For example, if a distributed queue with two members, Q1 and Q2, have weights 2 and 3, respectively, the member queues will be ordered as follows: Q1, Q2, Q1, Q2, Q2. Effectively, WebLogic makes a number of passes over the same destination set, and then drops members as their weights fall below the number of passes. JMS clients who use the distributed queue will then be cycled through its member queues in this sequence.
A random distribution algorithm uses the weights of the physical destinations to create a weighted random distribution for the set of destinations. The messaging load is then distributed according to this weighted random distribution. Note that in the short term, the messaging load on each destination may not be proportionate to its weight, but in the long term, the load distribution will tend toward the ideal weighted random distribution. If all the destinations are assigned equal weights, a purely random distribution will result. The random distribution needs to be recalculated whenever a member destination is added or removed from the distributed destination set. This computation, however, is inexpensive and shouldn't affect performance.
8.5.2.7 Load-balancing heuristics
As we have already seen, if a producer sends a message to a distributed destination in persistent mode, WebLogic doesn't just blindly choose a member destination from the set. Instead, it tries to find one that has a persistent store to ensure that the message is persisted. In fact, WebLogic relies on three other load-balancing heuristics when choosing a member of a distributed destination:
Transaction affinity
Multiple messages sent within the scope of a transacted session are routed to the same WebLogic instance, if possible. For instance, if a JMS session sends multiple messages to the same distributed destination, all of the messages are routed to the same physical destination. Similarly, if a session sends multiple messages to different distributed destinations, WebLogic tries to choose a set of physical destinations that are all hosted by the same WebLogic instance.
Server affinity
When a connection factory has server affinity enabled, WebLogic first attempts to load-balance consumers and producers across those member destinations that are hosted on the same WebLogic instance a client first connects to. To configure this, select a connection factory from the Administration Console, and then change the value of the Server Affinity Enabled flag in the Configuration/General tab. It is enabled by default on any connection factories that you create.
Queues with no consumers
When a producer sends messages to a distributed queue, member queues with no consumers are not considered in the load-balancing decision. In other words, only member queues with more than one consumer are considered for balancing the messaging load unless, of course, all member queues have no consumers. For consumers, however, it is the physical queues without consumers that are first considered for balancing the load. Only when all member queues have a consumer does the configured load-balancing algorithm start to apply.
All of these heuristics help improve the performance of JMS in a clustered environment. Transaction affinity tries to minimize network traffic when multiple messages are sent in a transaction by routing all traffic to the same WebLogic instance. Server affinity gives you the opportunity to prefer destinations collocated with the connection factory. These affinity-based heuristics obviously will decrease network traffic, but at the expense of unbalancing the load distribution. Finally, it clearly makes sense for member queues with no consumers to be considered for balancing the load of consumers first, rather than producers.
8.5.2.8 Targeting connection factories
The previous look at targeting connection factories to prevent unnecessary network hops didn't take distributed destinations into account. If you have a server-side application producing messages to a distributed destination, you may incur a wasteful network hop. Publishing to a distributed destination generally causes a load balance between the physical members of the destination. You can disable this load balancing and instead force the server-side application to use only the physical destinations collocated with it. This changes the behavior of the distributed destination (it no longer publishes to all physical members), but in return you save many network calls. To disable load balancing in this scenario, ensure that the connection factory used by the application has the Server Affinity option enabled. This makes it prefer physical destinations that are collocated on the same server instance. If you have a server-side application consuming messages from a distributed destination, you should ensure that the application is deployed to the same servers as the members of the distributed destination and the connection factories. In other words, collocate the consumer of a distributed destination with the members of the distributed destination. If you don't do this, WebLogic may route messages to the consumer through other servers.
As stated previously, an external client should have the connection factory it uses targeted to the servers hosting the destinations. If a distributed destination is being used, the same applies you should target the connection factory to each server hosting a member destination. For the same reasons as explained in the previous paragraph, an external client that produces to a distributed destination should usually enable Server Affinity to avoid unnecessary network hops.
8.5.3 Message-Driven Beans
Message-driven beans (MDBs) are the best way of concurrently handling messages arriving at a topic or queue. MDBs that listen to a nondistributed queue implement asynchronous, reliable delivery within a cluster. If the MDB becomes unavailable, the incoming messages collect at the queue and wait until the MDB comes up again. If the MDB listens to a nondistributed topic, any message arriving at the topic will be broadcast to all subscribers, including the MDB. If the MDB becomes unavailable, it will not receive the message, unless, of course, it has a durable subscription to the topic.
Some of the biggest issues surrounding MDBs include where to place them in the architecture and their interaction with distributed destinations.
8.5.3.1 Placement of MDBs
If the message bean responds to a physical JMS destination on a particular server in the cluster (i.e., nondistributed destination), you can deploy the associated MDB to the same WebLogic instance that hosts the destination. As a result, incoming messages can be delivered to the MDB without incurring any network traffic. Of course, if the application relies on a foreign JMS provider, it may not be possible to collocate the MDB with the foreign JMS server hosting the destination. Collocating MDBs and the destination will result in the best performance.
In a cluster scenario, you may have a distributed destination with its physical members distributed across the cluster. If you deploy an MDB to this cluster, which listens on the distributed destination, WebLogic will ensure that there is an MDB listening to each member of the distributed destination. So, in effect, you will have collocation of the destination and MDB, together with the load-balancing and failover capabilities of the distributed destination. This is ideal if there are high-performance and availability needs.
8.5.3.2 MDBs and distributed topics
MDBs that are configured to listen on a distributed topic will listen on each physical member of the topic. This may result in unnecessary processing if more than one physical member of the distributed topic is hosted on the same JMS server. If a message is sent to the distributed topic, it will be processed multiple times on the same server.
In essence, your applications will end up processing the same message twice! The better approach would be to simply set up the MDB to respond to one of the members of the distributed topic. That is, configure the MDB to listen to a particular physical member, and not to the distributed topic.
8.5.3.3 Delivery order
If an application uses an MDB to respond to messages arriving at a destination, it cannot assume that the MDB will receive the messages in the order in which they were produced. To receive messages in order, you need to limit the pool size to a single MDB, at the cost of concurrent handling:
1 1
Likewise, if the MDB is deployed in a clustered environment, you need to instead target it to only a single server within the cluster.
8.5.4 JMS Migration
Typically, your JMS servers will run on some subset of the servers in a cluster. To ensure that JMS servers can continue to service applications even after a failure, WebLogic provides a high-availability framework that lets you manually migrate a JMS server to another WebLogic instance in the cluster. All destinations hosted by the JMS server, including any members of distributed destination, also are migrated with the JMS server. This migration utilizes the same migration framework for pinned services in a clustered environment, as described in Chapter 14.
It may happen that a JMS server is migrated to a WebLogic instance that already hosts a JMS server. If both JMS servers host destinations that are members of the same distributed destination, that WebLogic instance must handle the messaging load of both physical destinations. This skews the results of load balancing configured for distributed destination by being less fair to that particular WebLogic instance. In such cases, you should migrate the failed JMS server back to its own WebLogic instance as soon as possible.
Before you can migrate a JMS server, you need to ensure the following:
- The JMS server is deployed on a WebLogic instance that belongs to a cluster.
- A migratable target has been assigned to the JMS server. To configure this, use the Targets/Migratable Targets tab to choose one or more preferred servers in the cluster to which the JMS server can be migrated.
Remember, a JMS server can only be migrated to another server in the same cluster to which it belongs.
8.5.4.1 Migrating a JMS server
A JMS server can be migrated either as a scheduled operation or in the event of a failure. Choose the server from which you want to migrate from the Administration Console. Then select a target server from the Control/JMS Migrate tab, and finally push the Migrate button. The JMS server, along with all of its destinations, will be migrated to the selected WebLogic instance.
Note that persistent stores are not migrated along with the JMS server. If the JMS server uses a persistent store, this store will need to be accessible to the JMS server in its new location. For JDBC stores, you simply need to ensure that the connection pool also is targeted to the new WebLogic instance. For file stores, you need to ensure that the JMS server at the new location also can access the file store. You can do this by employing either a hardware solution (e.g., a dual-ported SCSI disk), or a shared filesystem. Alternatively, you can copy the file store from the failed server to the new server at the same location under WebLogic's home directory.
To avoid any possible data consistencies, you also may have to migrate the transaction logs to the new server in the cluster. If the JMS server was migrated because of a server crash, it is important to make the transaction log files available at the new location before the server restarts. If you omit this step, any JMS operations invoked within the scope of the pending transaction may not complete as per expected semantics. Chapter 6 explains how to migrate the transaction recovery service onto another cluster member.
8.5.4.2 Migrating MDBs
Any MDBs configured to listen to a JMS destination can be migrated from a failed server to another server in the cluster. Even though an MDB doesn't have any migratable targets, it still can pick up the migratable targets configured for the JMS server to which it is deployed. So, to ensure proper migration of MDBs, you should ensure that the MDB is deployed to those JMS servers in the cluster that host the desired destinations. You can deploy the MDB either homogeneously to the entire cluster or to each migratable target configured for the JMS server hosting the destination. In other words, the list of target servers for the MDB should at least contain the JMS server's migratable target list. The migration is supported for both MDBs listening to JMS destinations, and for MDBs registered with distributed destinations.
Introduction
Web Applications
- Web Applications
- Packaging and Deployment
- Configuring Web Applications
- Servlets and JSPs
- JSP Tag Libraries
- Session Tracking
- Session Persistence
- Clusters and Replicated Persistence
- Configuring a Simple Web Cluster
- Security Configuration
- Monitoring Web Applications
Managing the Web Server
- Managing the Web Server
- Configuring WebLogics HTTP Server
- Virtual Hosting
- HTTP Access Logs
- Understanding Proxies
- Web Server Plug-ins
Using JNDI and RMI
- Using JNDI and RMI
- Using WebLogics JNDI
- Using JNDI in a Clustered Environment
- Using WebLogics RMI
- Using WebLogics RMI over IIOP
JDBC
- JDBC
- Overview of JDBC Resources
- Configuring JDBC Connectivity
- WebLogics Wrapper Drivers
- Rowsets
- Clustering and JDBC Connections
Transactions
J2EE Connectors
- J2EE Connectors
- Assembling and Deploying Resource Adapters
- Configuring Resource Adapters
- WebLogic-Specific Configuration Options
- Using the Resource Adapter
- Monitoring Connections
JMS
- JMS
- Configuring JMS Resources
- Optimizing JMS Performance
- Controlling Message Delivery
- JMS Programming Issues
- Clustered JMS
- WebLogics Messaging Bridge
- Monitoring JMS
JavaMail
Using EJBs
- Using EJBs
- Getting Started
- Development Guidelines
- Managing WebLogics EJB Container
- Configuring Entity Beans
- EJBs and Transactions
- EJBs and Clustering
Using CMP and EJB QL
- Using CMP and EJB QL
- Building CMP Entity Beans
- Features of WebLogics CMP
- Container-Managed Relationships
- EJB QL
Packaging and Deployment
- Packaging and Deployment
- Packaging
- Deployment Tools
- Application Deployment
- WebLogics Classloading Framework
- Deployment Considerations
- Split Directory Development
Managing Domains
- Managing Domains
- Structure of a Domain
- Designing a Domain
- Creating Domains
- Domain Backups
- Handling System Failure
- Domain Network Configuration
- Node Manager
- The Server Life Cycle
- Monitoring a WebLogic Domain
Clustering
- Clustering
- An Overview of Clustering
- A Closer Look at the Frontend Tier
- Load-Balancing Schemes
- Using J2EE Services on the Object Tier
- Combined-Tier Architecture
- Securing a Clustered Solution
- Machines, Replication Groups, and Failover
- Network Configuration
- Monitoring Clusters
Performance, Monitoring, and Tuning
- Performance, Monitoring, and Tuning
- Tuning WebLogic Applications
- Tuning the Application Server
- Tuning the JVM
SSL
- SSL
- An Overview of SSL
- Configuring WebLogics SSL
- Programmatic SSL
- Mapping Certificates to WebLogic Users
Security
- Security
- The Java Security Manager
- Connection Filtering
- The Security Provider Architecture
- The Providers
- Configuring Trust Between Two Domains
- JAAS Authentication in a Client
- Creating a Custom Authentication Provider
- Creating an Identity Assertion Provider
XML
- XML
- JAXP
- Built-in Processors
- The XML Registry
- XML Application Scoping
- WebLogics Streaming API
- WebLogics XPath API
- Miscellaneous Extensions
Web Services
- Web Services
- Using the Web Services Framework
- Web Service Design Considerations
- Implementing the Backend Components
- Datatypes
- Implementing Clients
- Reliable SOAP Messaging
- SOAP Message Handlers
- Security
- UDDI
- Internationalization and Character Sets
JMX
- JMX
- The MBean Architecture
- Accessing MBean Servers
- Accessing MBeans
- Examples
- MBean Notifications
- Monitor MBeans
- Timer MBeans
Logging and Internationalization
- Logging and Internationalization
- The Logging Architecture
- Listening for Log Messages
- Generating Log Messages
SNMP
EAN: 2147483647
Pages: 187
- Integration Strategies and Tactics for Information Technology Governance
- Assessing Business-IT Alignment Maturity
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control
- Governance in IT Outsourcing Partnerships
- Governance Structures for IT in the Health Care Industry
