Load-Balancing Schemes
The heart of WebLogic's load-balancing schemes lies in its clustered JNDI and RMI implementation, described in Chapter 4. As the overview pointed out, the replica-aware stubs maintained by the cluster allow calls to the RMI object to be routed to any of the servers in the cluster hosting that object. This scheme underlies WebLogic's support of load balancing for JDBC data sources, EJBs, and distributed JMS destinations, as all of these are implemented using RMI. The rest of this section describes these load-balancing schemes and some of the general conditions under which they will and won't be used.
14.3.1 Server-to-Server Routing
Both WebLogic 8.1 and 7.0 support several algorithms for balancing requests to clustered objects: round-robin, weight-based, random, and parameter-based routing. By default, WebLogic uses a round-robin policy for load balancing. An example of a server-to-server scenario was illustrated in Figure 14-1, where a JSP deployed to a presentation tier makes a call to an EJB or RMI object deployed to a separate object tier cluster. The algorithm used to choose between the servers in the object tier cluster depends on two factors:
- If the RMI object was compiled with a particular load-balancing scheme, that scheme will be used.
- If no scheme was explicitly configured, the default load-balancing scheme for the cluster will be used.
You can configure the default load-balancing scheme for the cluster by selecting the cluster in the Administration Console and picking a suitable load balancing scheme for the Default Load Algorithm setting in the Configuration/General tab. Let's look at these schemes in more detail.
14.3.1.1 Round-robin
When the round-robin algorithm is used, requests from a clustered stub are cycled through a list of WebLogic instances hosting the object. A specific order is chosen, and then each server is used in this order until the end of the list is reached, after which the cycle is repeated. A round-robin scheme is simple and predictable. However, this strategy does not react according to the varying loads on the servers. For example, if one server in the cluster is under heavy load, it still will continue to participate in the round-robining scheme like the other members in the cluster, so work may pile up on this server.
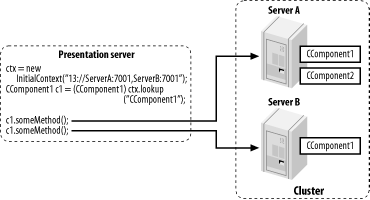
Figure 14-4 illustrates the round-robin scheme. A server in the presentation tier cluster makes a number of calls on some clusterable component c1 deployed to another cluster. Each method call is directed to one of the servers hosting the component, according to the load-balancing scheme that applies in the situation. Under the round-robin scheme, the method calls simply will alternate between the two servers, ServerA and ServerB.
Figure 14-4. Round-robin routing
14.3.1.2 Weight-based
When using the weight-based load-balancing scheme, the replica-aware stub distributes the requests based on a preassigned numeric weight for each server. You can choose a number between 1 and 100 for the Cluster Weight setting for each clustered server under the Configuration/Cluster tab in the right pane. The cluster weight determines what portion of the load a server will bear, relative to other members in the cluster. So, a server with weight 25 will take half as much load as the rest of the servers whose weights are 50. If all members of the cluster are assigned the same weights, they all bear an equal share of the load.
This load-balancing scheme is best suited for clusters with heterogeneous deployments, in which different EJBs are deployed to different sets of servers, or when the processing power of the machines in the cluster varies. You should consider several factors before assigning a weight for the server:
- The number of CPUs dedicated to the particular server
- The speed of the network cards that are used by the machine hosting the clustered server
- The number of nonclustered (pinned) objects or services running on a server
Remember, cluster weights provide only an indication of the "expected" load on a server. A weight-based scheme does not react and respond to the current loads on the cluster servers.
14.3.1.3 Random
The random load-balancing scheme distributes requests randomly across all members of the cluster. This scheme is recommended for homogenous clusters, in which components are deployed uniformly to all members of the cluster and the servers run on machines with similar configurations. A random load-balancing strategy can distribute loads evenly to all members of the cluster. The longer a WebLogic cluster remains alive, the closer the distribution is to the "mean." However, each request must incur a slight processing cost of generating a random number. In addition, a random distribution does not account for the differences in the configuration of the machines that are participating in the cluster, and so does not react to different loads on the cluster servers.
14.3.1.4 Parameter-based
Parameter-based routing lets you programmatically determine which server should be chosen to handle a method call on a clusterable RMI object. Unlike the other load-balancing schemes, this is not a general scheme that can be applied to any clusterable component. Rather, it is needed only when you want extreme control in routing RMI objects. This scheme is described in Chapter 4.
14.3.2 Client-Server Routing
Both WebLogic 8.1 and 7.0 support the round-robin, weight-based, and random load-balancing schemes for external client applications that make connections into a cluster. External clients are at a disadvantage because the client eventually makes IP connections to each server in the cluster, as all of these schemes distribute the load across all available servers in the cluster.
WebLogic 8.1 can limit this promiscuous connection behavior for clients. A load-balancing scheme with server affinity attempts to always use connections to servers that are already established, instead of creating new ones. The three load-balancing schemes each have an affinity-based counterpart: round-robin affinity, weight-based affinity, and random affinity. If you set the default load algorithm for a cluster to round-robin affinity, for example, the round-robin scheme will still be used for load balancing server-to-server requests. However, server affinity will cause external clients to simply use servers to which they are already connected. This minimizes the number of IP sockets opened between clients and the clustered servers, but at the cost of eliminating load balancing.
Note that server affinity also affects the failover behavior. If a client is already connected to a server in a cluster and the server eventually fails, the client will either use an alternative connection to the cluster (if it exists) or create a new connection to another cluster member.
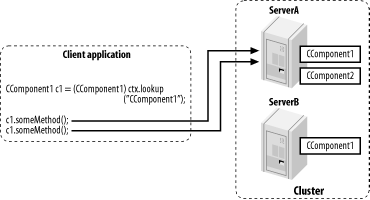
Figure 14-5 illustrates the impact of server affinity on client-server interactions. For instance, if the client has already set up a JNDI context with ServerA, server affinity ensures that subsequent calls to the clustered component are routed to the same server. Ultimately, the goal of server affinity is to reuse existing client connections to the cluster, whenever possible.
Figure 14-5. Client-server communication with server affinity load balancing
14.3.2.1 Server affinity for JNDI contexts
If a client or server creates a new context using a cluster address, by default the contexts are distributed on a round-robin basis among the available servers determined by the address. WebLogic lets you disable this round-robining by inducing the client to create the JNDI context on a server to which it is already connected. In other words, you can enable server affinity for client requests for a JNDI context. You need to supply the ENABLE_SERVER_AFFINITY property when creating the initial JNDI context:
Hashtable h = new Hashtable( ); h.put(Context.INITIAL_CONTEXT_FACTORY, "weblogic.jndi.WLInitialContextFactory"); h.put(Context.PROVIDER_URL, "t3://server1:7001,server2:7001"); h.put(weblogic.jndi.WLContext.ENABLE_SERVER_AFFINITY, "true"); Context ctx = new InitialContext(h);
This, combined with one of the affinity-based load-balancing schemes, ensures that all interaction between the client and the cluster is routed to the first server in the cluster to which the client connects.
14.3.3 Scenarios in Which Load Balancing Is Avoided
You should be aware of the optimizations that WebLogic uses to avoid load balancing. WebLogic employs two schemes:
- Collocation of objects
- Collocation of transactions
Suppose an EJB object makes a call to another EJB. If the second EJB is collocated on the same server as the first, then WebLogic automatically avoids the load-balancing logic even if both EJB objects have been deployed to the cluster. WebLogic decides it is more optimal to make the method call on a local replica of the second EJB object rather than forward the call to a remote replica on another server in the cluster.
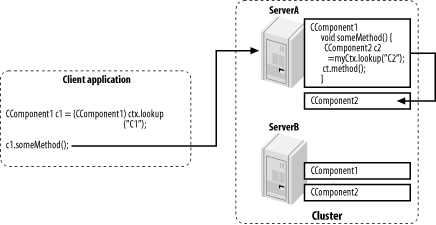
Figure 14-6 illustrates this collocation strategy. We have two clustered components (EJBs) CComponent1 and CComponent2 deployed to two members of a cluster ServerA and ServerB. Suppose a remote client creates a JNDI context and looks up an instance of CComponent1, and WebLogic returns a stub that defaults to ServerA. Suppose also that the method on CComponent1 looks up CComponent2. In this case, both of the JNDI contexts that are created (one on the client and one on the server) will use the address of the cluster. The collocation strategy then will ensure that the CComponent2 instance that is used will be returned from ServerA and not ServerB.
Figure 14-6. Collocation of objects
Of course, if another remote client comes along and creates a JNDI context using the same cluster address, the JNDI context would round-robin to ServerB and the same behavior is repeated there. The key point to remember is that WebLogic always tries to avoid load balancing. There is no way you can avoid this optimization, nor do you want to. Clearly, it always is cheaper to invoke a method on a local object than it is to make the same invocation on a remote object.
The same optimizations motivate WebLogic to use transaction collocation. The cost of managing a distributed transaction in which all of the enlisted resources live on different machines is higher than if those objects were collocated on the server on which the transaction was initiated. By avoiding the overhead of network traffic, WebLogic is able to reduce the duration of distributed transactions. This effect also filters through to the objects enlisted in the distributed transaction because they too are locked for the duration of the transaction. Hence, if multiple cluster-aware objects are engaged in a distributed transaction, WebLogic tries to collocate the objects on the server on which the transaction was begun.
Introduction
Web Applications
- Web Applications
- Packaging and Deployment
- Configuring Web Applications
- Servlets and JSPs
- JSP Tag Libraries
- Session Tracking
- Session Persistence
- Clusters and Replicated Persistence
- Configuring a Simple Web Cluster
- Security Configuration
- Monitoring Web Applications
Managing the Web Server
- Managing the Web Server
- Configuring WebLogics HTTP Server
- Virtual Hosting
- HTTP Access Logs
- Understanding Proxies
- Web Server Plug-ins
Using JNDI and RMI
- Using JNDI and RMI
- Using WebLogics JNDI
- Using JNDI in a Clustered Environment
- Using WebLogics RMI
- Using WebLogics RMI over IIOP
JDBC
- JDBC
- Overview of JDBC Resources
- Configuring JDBC Connectivity
- WebLogics Wrapper Drivers
- Rowsets
- Clustering and JDBC Connections
Transactions
J2EE Connectors
- J2EE Connectors
- Assembling and Deploying Resource Adapters
- Configuring Resource Adapters
- WebLogic-Specific Configuration Options
- Using the Resource Adapter
- Monitoring Connections
JMS
- JMS
- Configuring JMS Resources
- Optimizing JMS Performance
- Controlling Message Delivery
- JMS Programming Issues
- Clustered JMS
- WebLogics Messaging Bridge
- Monitoring JMS
JavaMail
Using EJBs
- Using EJBs
- Getting Started
- Development Guidelines
- Managing WebLogics EJB Container
- Configuring Entity Beans
- EJBs and Transactions
- EJBs and Clustering
Using CMP and EJB QL
- Using CMP and EJB QL
- Building CMP Entity Beans
- Features of WebLogics CMP
- Container-Managed Relationships
- EJB QL
Packaging and Deployment
- Packaging and Deployment
- Packaging
- Deployment Tools
- Application Deployment
- WebLogics Classloading Framework
- Deployment Considerations
- Split Directory Development
Managing Domains
- Managing Domains
- Structure of a Domain
- Designing a Domain
- Creating Domains
- Domain Backups
- Handling System Failure
- Domain Network Configuration
- Node Manager
- The Server Life Cycle
- Monitoring a WebLogic Domain
Clustering
- Clustering
- An Overview of Clustering
- A Closer Look at the Frontend Tier
- Load-Balancing Schemes
- Using J2EE Services on the Object Tier
- Combined-Tier Architecture
- Securing a Clustered Solution
- Machines, Replication Groups, and Failover
- Network Configuration
- Monitoring Clusters
Performance, Monitoring, and Tuning
- Performance, Monitoring, and Tuning
- Tuning WebLogic Applications
- Tuning the Application Server
- Tuning the JVM
SSL
- SSL
- An Overview of SSL
- Configuring WebLogics SSL
- Programmatic SSL
- Mapping Certificates to WebLogic Users
Security
- Security
- The Java Security Manager
- Connection Filtering
- The Security Provider Architecture
- The Providers
- Configuring Trust Between Two Domains
- JAAS Authentication in a Client
- Creating a Custom Authentication Provider
- Creating an Identity Assertion Provider
XML
- XML
- JAXP
- Built-in Processors
- The XML Registry
- XML Application Scoping
- WebLogics Streaming API
- WebLogics XPath API
- Miscellaneous Extensions
Web Services
- Web Services
- Using the Web Services Framework
- Web Service Design Considerations
- Implementing the Backend Components
- Datatypes
- Implementing Clients
- Reliable SOAP Messaging
- SOAP Message Handlers
- Security
- UDDI
- Internationalization and Character Sets
JMX
- JMX
- The MBean Architecture
- Accessing MBean Servers
- Accessing MBeans
- Examples
- MBean Notifications
- Monitor MBeans
- Timer MBeans
Logging and Internationalization
- Logging and Internationalization
- The Logging Architecture
- Listening for Log Messages
- Generating Log Messages
SNMP
EAN: 2147483647
Pages: 187
