Machines, Replication Groups, and Failover
We already have seen how WebLogic can replicate server-side session-state information to a secondary server, thereby enabling WebLogic to reconstruct the session state on the secondary server in the event of a failure. In order to guarantee high availability, it is sensible to ensure that WebLogic chooses the secondary server from one of the servers running on a different physical machine. By doing this, if a machine hosting multiple WebLogic instances fails, their secondary servers will run on different hardware and not be affected by the crash.
You can specify the set of servers in the cluster that should be considered for holding the replicated session state by assigning machine names to WebLogic instances. You can refine this scheme further by setting up replication groups. A replication group is just a list of preferred servers within the cluster that should be used as secondary servers.
14.7.1 Machine Names
To set up a new machine, click the Machines node in the left pane of the Administration Console, and select the "Configure a new Machine" option. Chapter 13 shows how the Node Manager configuration uses these machine definitions.
A machine name is a tag that can be associated with a number of WebLogic instances. By making these associations, you indicate which servers are running on which machines. WebLogic's clustering framework can use this information to determine the preferred secondary server. By default, the secondary server is chosen from a WebLogic instance running on a different machine. Suppose you've configured a cluster with four Managed Servers (S1...S4), and assigned machine names M1 to servers S1 and S2, and M2 to servers S3 and S4. If an HTTP session is initiated on server S1, and assuming you haven't configured any replication groups, by default the session is replicated on any of the servers running on machine M2 i.e., either S3 or S4. Similarly, if a client creates a stateful session EJB instance on server S4, the preferred secondary server for the EJB is chosen from one of the servers on machine M1 i.e., either S1 or S2.
To make this association between a machine and a WebLogic instance, select a machine from the left pane of the Administration Console and, in the Configuration/Servers tab, move the appropriate servers into the Chosen column. You also can assign a machine to a server by selecting the server from the left pane, and then choosing the Configuration/General tab. Use the Machine drop-down to choose the name of the machine on which the selected server runs.
If you run each WebLogic instance on its own hardware, you do not need to create machine names other than for the purposes of the Node Manager. Servers that are not associated with machines are treated as if they reside on different physical machines, which is exactly the behavior you want in these circumstances.
14.7.2 Replication Groups
Replication groups let you specify which servers in the cluster should be preferred to act as the secondary server. You need replication groups only if the default strategy for choosing a secondary server from a different machine doesn't meet your requirements.
This mechanism works by assigning a group name to each server. All of the servers that share the same group name are considered to be in the same replication group. For each server in the cluster, you can specify two group names: the replication group the server belongs to, and the replication group from which the secondary server preferably should be chosen. You can adjust these configuration settings from the Administration Console. Select a server from the left pane, and then choose the Configuration/Cluster tab to find the following options for setting up replication groups:
Replication Group
Use this attribute to specify the replication group to which this server belongs.
Preferred Secondary Group
Use this attribute to specify the name of the replication group that identifies the set of clustered instances that should be preferred for hosting replicas of the primary state created on this server.
In this way, you can precisely configure for each server the set of servers in the cluster from where its secondary server preferably should be chosen, and the set of servers for which this server is the preferred secondary server.
Suppose you've configured replication groups for all members of a WebLogic cluster. How, then, does WebLogic choose the secondary server for replicating the session state held on a server instance? Quite simply, WebLogic ranks the other servers in the cluster, and then chooses among the best-ranked servers. The rank is determined by giving priority first to members of the preferred replication group, and then to servers running on a different machine. Table 14-1 illustrates this ranking strategy.
|
Rank |
Server on different machine? |
Server member of preferred replication group? |
|---|---|---|
|
1 |
Yes |
Yes |
|
2 |
No |
Yes |
|
3 |
Yes |
No |
|
4 |
No |
No |
Figure 14-13 shows this ranking mechanism in action. Consider a cluster with six servers. Within this cluster, we defined two replication groups, Group 1 and Group 2. Servers A, B, and C are members of the replication group Group 1 and have their preferred secondary replication group set to Group 2. Servers X, Y, and Z are members of the replication group Group 2 and have their preferred secondary replication group set to Group 1. Furthermore, assume that the server instances A, B, and X are all running on the same physical machine, StarFire.
Figure 14-13. Example replication groups
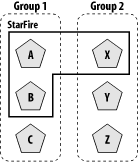
Now suppose that a client connects to Server A and creates its primary session state on that server. Then, based on the ranking strategy described earlier, we can deduce the following:
- The secondary server most likely will be chosen from servers Y or Z, as they are members of Server A's preferred secondary group (Group 2) and also reside on a different physical machine.
- Server X is the next most likely to be chosen as the secondary server because it too is a member of Server A's preferred replication group, even though it runs on the same physical machine.
- Server C is the next most likely to be chosen as the secondary server, as it resides on a different machine.
- Server B is the least likely to be chosen as the secondary server for Server A because it is neither a member of the preferred replication group, nor does it live on another machine.
This means that for Server B to be chosen as the secondary server, servers X, Y, Z, and C must be unavailable. Thus, you should remember that replication groups determine only which servers ought to be preferred over others when determining which server should act as the secondary. If there no members are available in the preferred replication group that can act as the secondary, WebLogic has no choice but to look outside the preferred group.
Introduction
Web Applications
- Web Applications
- Packaging and Deployment
- Configuring Web Applications
- Servlets and JSPs
- JSP Tag Libraries
- Session Tracking
- Session Persistence
- Clusters and Replicated Persistence
- Configuring a Simple Web Cluster
- Security Configuration
- Monitoring Web Applications
Managing the Web Server
- Managing the Web Server
- Configuring WebLogics HTTP Server
- Virtual Hosting
- HTTP Access Logs
- Understanding Proxies
- Web Server Plug-ins
Using JNDI and RMI
- Using JNDI and RMI
- Using WebLogics JNDI
- Using JNDI in a Clustered Environment
- Using WebLogics RMI
- Using WebLogics RMI over IIOP
JDBC
- JDBC
- Overview of JDBC Resources
- Configuring JDBC Connectivity
- WebLogics Wrapper Drivers
- Rowsets
- Clustering and JDBC Connections
Transactions
J2EE Connectors
- J2EE Connectors
- Assembling and Deploying Resource Adapters
- Configuring Resource Adapters
- WebLogic-Specific Configuration Options
- Using the Resource Adapter
- Monitoring Connections
JMS
- JMS
- Configuring JMS Resources
- Optimizing JMS Performance
- Controlling Message Delivery
- JMS Programming Issues
- Clustered JMS
- WebLogics Messaging Bridge
- Monitoring JMS
JavaMail
Using EJBs
- Using EJBs
- Getting Started
- Development Guidelines
- Managing WebLogics EJB Container
- Configuring Entity Beans
- EJBs and Transactions
- EJBs and Clustering
Using CMP and EJB QL
- Using CMP and EJB QL
- Building CMP Entity Beans
- Features of WebLogics CMP
- Container-Managed Relationships
- EJB QL
Packaging and Deployment
- Packaging and Deployment
- Packaging
- Deployment Tools
- Application Deployment
- WebLogics Classloading Framework
- Deployment Considerations
- Split Directory Development
Managing Domains
- Managing Domains
- Structure of a Domain
- Designing a Domain
- Creating Domains
- Domain Backups
- Handling System Failure
- Domain Network Configuration
- Node Manager
- The Server Life Cycle
- Monitoring a WebLogic Domain
Clustering
- Clustering
- An Overview of Clustering
- A Closer Look at the Frontend Tier
- Load-Balancing Schemes
- Using J2EE Services on the Object Tier
- Combined-Tier Architecture
- Securing a Clustered Solution
- Machines, Replication Groups, and Failover
- Network Configuration
- Monitoring Clusters
Performance, Monitoring, and Tuning
- Performance, Monitoring, and Tuning
- Tuning WebLogic Applications
- Tuning the Application Server
- Tuning the JVM
SSL
- SSL
- An Overview of SSL
- Configuring WebLogics SSL
- Programmatic SSL
- Mapping Certificates to WebLogic Users
Security
- Security
- The Java Security Manager
- Connection Filtering
- The Security Provider Architecture
- The Providers
- Configuring Trust Between Two Domains
- JAAS Authentication in a Client
- Creating a Custom Authentication Provider
- Creating an Identity Assertion Provider
XML
- XML
- JAXP
- Built-in Processors
- The XML Registry
- XML Application Scoping
- WebLogics Streaming API
- WebLogics XPath API
- Miscellaneous Extensions
Web Services
- Web Services
- Using the Web Services Framework
- Web Service Design Considerations
- Implementing the Backend Components
- Datatypes
- Implementing Clients
- Reliable SOAP Messaging
- SOAP Message Handlers
- Security
- UDDI
- Internationalization and Character Sets
JMX
- JMX
- The MBean Architecture
- Accessing MBean Servers
- Accessing MBeans
- Examples
- MBean Notifications
- Monitor MBeans
- Timer MBeans
Logging and Internationalization
- Logging and Internationalization
- The Logging Architecture
- Listening for Log Messages
- Generating Log Messages
SNMP
EAN: 2147483647
Pages: 187
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter VII Objective and Perceived Complexity and Their Impacts on Internet Communication
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter XII Web Design and E-Commerce
- Chapter XIV Product Catalog and Shopping Cart Effective Design
