Clusters and Replicated Persistence
Setting the persistence type to replicated enables WebLogic to replicate the session state in memory itself. Like the default memory persistence scheme, session data is stored in memory. Unlike the default memory persistence, this scheme works closely with the notion of primary and secondary servers in the cluster, as discussed later in Chapter 14. WebLogic creates the primary session state on the server that a client first connects to, and then transparently replicates the session-state information onto a secondary server instance. The process of copying session state from one server instance to another in the cluster is called in-memory replication. The replica is kept up-to-date so that the secondary server can take over when the original server instance that holds the session data fails.
In-memory session-state replication will work only for those object-valued attributes in the session that are Serializable objects. Changes to the session object will be replicated only if you use the setAttribute( ) and removeAttribute( ) methods on the HttpSession object. These methods ensure that any changes to the attributes of the session are mirrored onto the secondary server for the client. Remember that only nontransient attributes of an object in the session will be replicated to the secondary server. All transient attributes of the object will be ignored.
If you modify the state of an object stored in the session using another object reference, those changes will not be automatically replicated across. For instance, suppose you access a session attribute and modify its value as follows:
HttpSession session = request.getSession(false);
com.oreilly.user.AUser foo = (AUser) session.getAttribute("user");
foo.setName("Ali Cowan");
The changes to the AUser object will be replicated only if you subsequently invoke the setAttribute( ) method:
session.setAttribute("user", foo);
This means that changes to the session data are replicated only after explicit calls to either the setAttribute( ) or removeAttribute( ) methods on the HttpSession object.
2.7.1 Disadvantages of Session-State Replication
Even though session-state replication guarantees failover, there are a few downsides of which you should be aware. There is a slight cost of additional network traffic when the session data is actually replicated to the secondary server. Clearly, the demands on network resources will grow as the number of active sessions grows and as more server instances are added to the cluster. There is also the additional cost associated with serializing the session data every time an attribute is added.
The benefits of HTTP session failover are offset by overheads of additional network traffic due to session-state replication. In Chapter 14 and Chapter 15, we will look at how you can plan for network capacity and manage some of these issues.
2.7.2 Session Replication
Although Chapter 14 covers the use and configuration of clusters, we need to understand a little here in order to fully grasp replicated persistence. In essence, in-memory replicated persistence requires two things:
Redundancy
A secondary server that holds and maintains a copy of the session data
Failover
The ability to let the secondary server transparently take over when the primary server fails
Earlier, we saw that WebLogic handles session replication through its implementation of the setAttribute( ) and removeAttribute( ) methods on the HttpSession object. Now we investigate how the failover is handled transparently.
Transparent failover of session data can occur only when you access the WebLogic cluster through a web server fitted with a WebLogic proxy plug-in, a WebLogic instance equipped with the HttpClusterServlet, or load-balancing hardware supported by WebLogic.
2.7.3 Session Failover
For the software approach to work, you need to use either the HttpClusterServlet or a combination of HTTP servers with identically configured plug-ins. WebLogic currently supports proxy plug-ins for Apache, IIS, and NES. Even though we will talk about session failover using proxy plug-ins, the same discussion holds if you use WebLogic Server with an HttpClusterServlet.
Figure 2-1 illustrates how session replication works in a WebLogic cluster. The plug-in maintains a list of all active servers in the cluster. When a new session is created, the server that handles this request becomes the primary server (Server A in the diagram), and WebLogic will ensure that any future requests are routed to this same server. Thus, sessions are said to be "sticky."
Figure 2-1. Session replication in a cluster
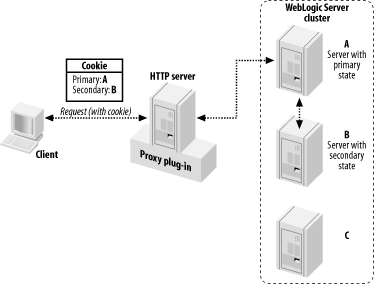
After a primary server has been selected, a secondary server is selected (perhaps using a preferred replication group, which is discussed later in Chapter 14). In our example, Server B is chosen to hold a copy of the session state held in Server A. From now on, all changes to the client's session state in Server A will be replicated to Server B. When the result page is sent back to the client, information is attached that identifies the primary and secondary locations. This information is attached in the form of a cookie or, if cookies are disabled, embedded using URL rewriting.
The interesting bit happens when there is a failure. As the plug-ins hold an active server list for the cluster, a plug-in will know whether the primary server for an incoming request is live. If the server is not live, the plug-in will examine the cookie for the location of the secondary server and automatically route the request to that server. The secondary server now becomes the primary server, and a new server is located and chosen as the secondary server. The session state then is replicated to the new secondary server, and a new cookie (which holds updated locations for the primary and secondary servers) is returned to the client.
In the special case of a cluster having only two server instances, if one server goes down, there will be no available secondary server. Then, if another server does come up at some later stage, it will automatically become the secondary for all the session data.
Introduction
Web Applications
- Web Applications
- Packaging and Deployment
- Configuring Web Applications
- Servlets and JSPs
- JSP Tag Libraries
- Session Tracking
- Session Persistence
- Clusters and Replicated Persistence
- Configuring a Simple Web Cluster
- Security Configuration
- Monitoring Web Applications
Managing the Web Server
- Managing the Web Server
- Configuring WebLogics HTTP Server
- Virtual Hosting
- HTTP Access Logs
- Understanding Proxies
- Web Server Plug-ins
Using JNDI and RMI
- Using JNDI and RMI
- Using WebLogics JNDI
- Using JNDI in a Clustered Environment
- Using WebLogics RMI
- Using WebLogics RMI over IIOP
JDBC
- JDBC
- Overview of JDBC Resources
- Configuring JDBC Connectivity
- WebLogics Wrapper Drivers
- Rowsets
- Clustering and JDBC Connections
Transactions
J2EE Connectors
- J2EE Connectors
- Assembling and Deploying Resource Adapters
- Configuring Resource Adapters
- WebLogic-Specific Configuration Options
- Using the Resource Adapter
- Monitoring Connections
JMS
- JMS
- Configuring JMS Resources
- Optimizing JMS Performance
- Controlling Message Delivery
- JMS Programming Issues
- Clustered JMS
- WebLogics Messaging Bridge
- Monitoring JMS
JavaMail
Using EJBs
- Using EJBs
- Getting Started
- Development Guidelines
- Managing WebLogics EJB Container
- Configuring Entity Beans
- EJBs and Transactions
- EJBs and Clustering
Using CMP and EJB QL
- Using CMP and EJB QL
- Building CMP Entity Beans
- Features of WebLogics CMP
- Container-Managed Relationships
- EJB QL
Packaging and Deployment
- Packaging and Deployment
- Packaging
- Deployment Tools
- Application Deployment
- WebLogics Classloading Framework
- Deployment Considerations
- Split Directory Development
Managing Domains
- Managing Domains
- Structure of a Domain
- Designing a Domain
- Creating Domains
- Domain Backups
- Handling System Failure
- Domain Network Configuration
- Node Manager
- The Server Life Cycle
- Monitoring a WebLogic Domain
Clustering
- Clustering
- An Overview of Clustering
- A Closer Look at the Frontend Tier
- Load-Balancing Schemes
- Using J2EE Services on the Object Tier
- Combined-Tier Architecture
- Securing a Clustered Solution
- Machines, Replication Groups, and Failover
- Network Configuration
- Monitoring Clusters
Performance, Monitoring, and Tuning
- Performance, Monitoring, and Tuning
- Tuning WebLogic Applications
- Tuning the Application Server
- Tuning the JVM
SSL
- SSL
- An Overview of SSL
- Configuring WebLogics SSL
- Programmatic SSL
- Mapping Certificates to WebLogic Users
Security
- Security
- The Java Security Manager
- Connection Filtering
- The Security Provider Architecture
- The Providers
- Configuring Trust Between Two Domains
- JAAS Authentication in a Client
- Creating a Custom Authentication Provider
- Creating an Identity Assertion Provider
XML
- XML
- JAXP
- Built-in Processors
- The XML Registry
- XML Application Scoping
- WebLogics Streaming API
- WebLogics XPath API
- Miscellaneous Extensions
Web Services
- Web Services
- Using the Web Services Framework
- Web Service Design Considerations
- Implementing the Backend Components
- Datatypes
- Implementing Clients
- Reliable SOAP Messaging
- SOAP Message Handlers
- Security
- UDDI
- Internationalization and Character Sets
JMX
- JMX
- The MBean Architecture
- Accessing MBean Servers
- Accessing MBeans
- Examples
- MBean Notifications
- Monitor MBeans
- Timer MBeans
Logging and Internationalization
- Logging and Internationalization
- The Logging Architecture
- Listening for Log Messages
- Generating Log Messages
SNMP
EAN: 2147483647
Pages: 187
